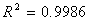西安郵電大学
《计量经济学》课内上机实验报告书

1、教材P54 11题
2、教材P91 10、11题
3、教材p135 7、8题
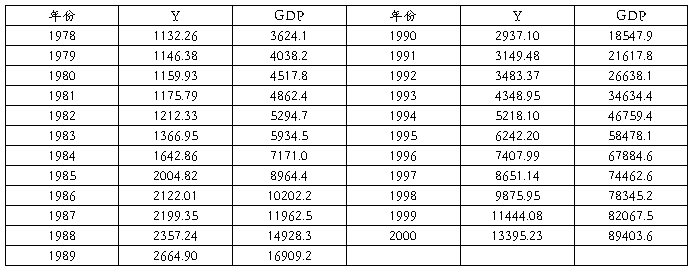
11、下表是中国1978-20##年的财政收入Y和国内生产总值(GDP)的统计资料。
单位:亿元
要求,以手工和运用EViews软件(或其他软件):
(1)作出散点图,建立财政收入随国内生产总值变化的一元线性回归模型,并解释斜率的经济意义;
(2)对所建立的回归模型进行检验;
(3)若20##年中国国内生产总值为105709亿元,求财政收入的预测值及预测区间。
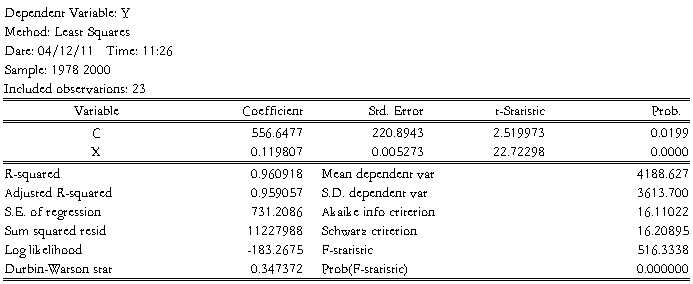

1.通过已知数据得到上面得散点图,财政收入随国内生产总值变化的一元线性回归方程:
?i=556.6477 + 0.119807Xi
(220.8943) (0.005273)
t=(2.519973) (22.72298)
r²=0.960918 F=516.3338 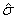 =731.2086
=731.2086
估计的解释变量的系数为0.119807,说明国内生产总值每增加一元,财政收入将增加0.119807元,符合经济理论。
2.(1)样本可决系数r²=0.960918,模拟拟合度较好。
(2)系数的显著性检验:给定α=0,05,查t分布表在自由度为n-2=21时的临界值为t0.025(21)=2.08因为t=2.519973> t0.025(21)=2.08, 国内生产总值对财政收入有显著性影响。
3.20##年的财政收入的预测值:?01=556.6477 + 0.119807*105709=13221.325863
20##年的财政收入的预测区间:在1-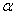 下,Y01的置信区间为:
下,Y01的置信区间为:
Y01
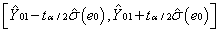 即:
即:
Y01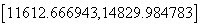
10、在一项对某社区家庭对某种消费品的消费需要调查中,得到下表所示的资料。
单位:元
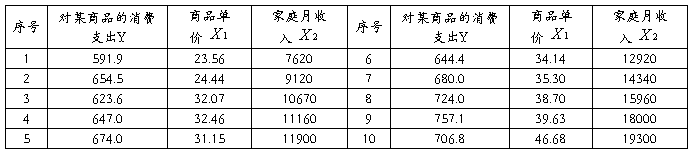
请用手工与软件两种方式对该社区家庭对该商品的消费需求支出作二元线性回归分析,其中手工方式要求以矩阵表达式进行运算。
(1)估计回归方程的参数及随机干扰项的方差²,计算R²及 ²。
²。
(2)对方程进行F检验,对参数进行t检验,并构造参数95%的置信区间。
(3)如果商品单价变为35元,则某一月收入为20000元的家庭的消费支出估计是多少?构造该估计值的95%的置信区间。
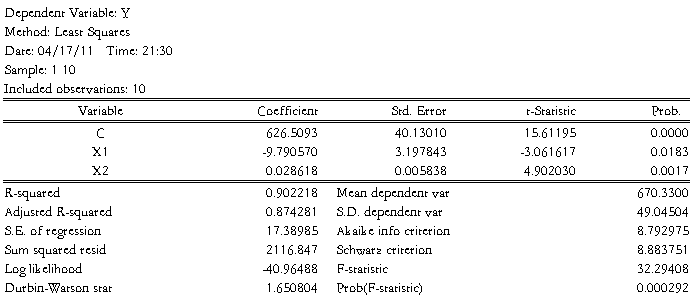
(1) 由上表可写如下回归分析结果:
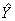 i=626.5093-9.790570
i=626.5093-9.790570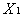 +0.028618
+0.028618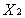
t=(15.61195) (-3.061617) ( 4.902030)
R²=0.902218 ²=0.874281 F=32.29408 =17.38985
 =3.197843
=3.197843 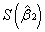 =0.005838
=0.005838
所以²=302.4068830225
(2) F检验:
提出检验的原假设和备择假设:

因为F=32.29408 对于给定的显著性水平=0.05,查表得临界值为:
F0,05(2,8)=4.46
由于F>4.46,所以拒绝原假设H0,说明回归方程显著,即商品单价、
家庭月收入联合起来对消费支出
有显著性线性影响。
T检验:
t1 = -3.061617 t2=4.902030
对于给定的显著性水平=0.05,查表得临界值为:
t0.025(8)=2.306
判断比较:|t1|=3.061617>2.306,所以否定原假设H0,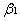 显著不为零,即商品单价对消费支出有显著的影响
显著不为零,即商品单价对消费支出有显著的影响
|t2|=4.902030>2.306,所以否定原假设H0, 显著不为零,即家庭月收入对消费支出有显著的影响
显著不为零,即家庭月收入对消费支出有显著的影响
的置信水平是95℅置信区间是:
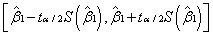 即:
即:

同理的置信水平是95℅置信区间是
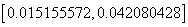
(3) 如果=35 =20000则:X=(1,35,20000)
Y0的置信水平是0.95的置信区间是:
0=626.5093-9.790570*35+0.028618*20000=856.19935
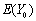 的置信水平是1-
的置信水平是1-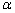 的预测区间为
的预测区间为

把相应的数据代入得的置信度为95%的预测区间为(768.2184 , 943.4604)
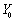 的置信水平是
的置信水平是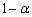 的预测区间为
的预测区间为
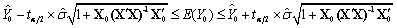
把相应的数据代入得的置信度为95%的预测区间为(759.0464 ,952.6324)
11、下表列出了中国20##年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y,资产合计K及职工人数L。
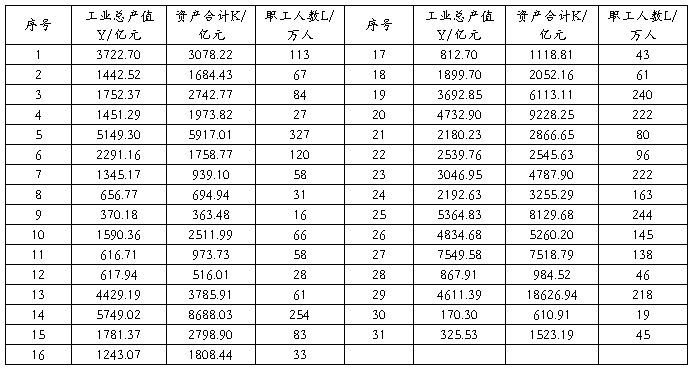
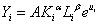 设定模型为:
设定模型为:
(1)利用上述资料,进行回归分析。
(2)回答:中国20##年的制造业总体呈现规模报酬不变状态吗?
利用Eviews的最小二乘法程序,得到如下输出结果:
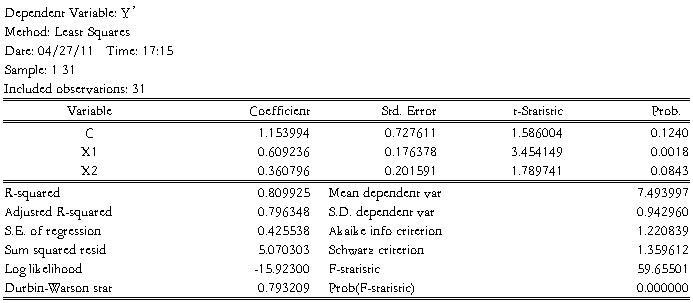
根据上述结果得到估计的回归方程为:
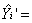 1.153994 + 0.609236X1I+0.360796X2I
1.153994 + 0.609236X1I+0.360796X2I
t=(1.586004) (3.454149) (1.789741)
R²=0.809925 F=59.65501 DW=0.793209
A=e^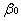
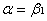

最终得到估计的生产函数为:
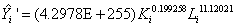
检验模型:
(1) 拟合优度检验:可决系数R²=0.809925 不是太高,修正的可决系数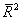 =0.796348也不是太高,表明模型拟合优度还好。
=0.796348也不是太高,表明模型拟合优度还好。
(2) F检验:
提出检验的原假设和备择假设:

计算出F统计量的值为:F=59.65501
对于给定的显著性水平α=0.05,查表的临界值为:
F0.05(2,28)=3.34
由于F>3.34,所以拒绝原假设H0,说明回归方程显著,即资产合计、职工人数联合起来对非国有企业的工业总产值有显著性线性影响。
(3) t检验:
提出检验的原假设为:
H0:βi=0,(i=1,2)
计算出的t统计量值为:
t1=2.431876 t2=3.069616
对于给定的显著性水平α=0.05,查表得临界值为:
t0.025(28)=2.0484
判断比较:
|t1|=2.431876>2.0484,所以否定H0,β1显著不为零,即认为资产合计对非国有企业的工业总产值有显著性影响。
|t2|=3.069616>2.0484,所以否定H0,β2显著不为零,即职工人数对非国有企业的工业总产值有显著性影响。
于是在建立模型时,K、L可以作为解释变量进入模型。
7、下表列出了20##年中国部分省市城镇居民每个家庭平均全年可支配收入(X)与消费性支出(Y)的统计数据。
单位:元
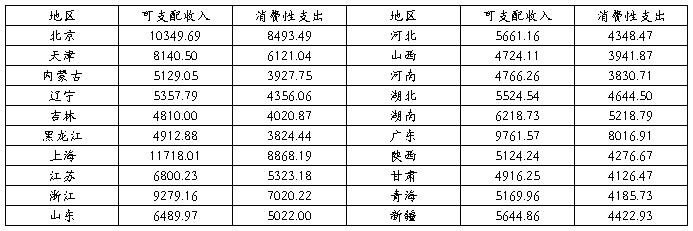
(1)试用OLS法建立居民人均消费支出与可支配收入的线性模型;
(2)检验模型是否存在异方差性;
(3)如果存在异方差性,试采用适当的方法估计模型对数。
解:
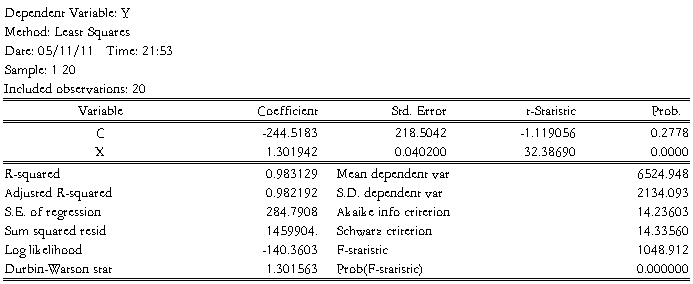
1) 估计结果为:
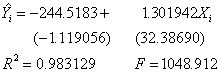
2)(一)图形法:
(1)生成参差平方序列:

(2)判断:由图可以看出,残差平方ei2对解释变量X的散点图主要分布在图形中横纵坐标的对角线上,大致看出残差平方ei2随X的变动呈增大的趋势,因此,模型很可能存在异方差。但是否确实存在异方差还应通过更进一步的检验。
(二)Goldfeld-Quanadt检验
(1)对变量取值排序(按递增或递减)。
(2)构造子样本区间,建立回归模型。在本例中,样本容量n=20,删除中间1/4的观测值,即6个观测值,余下部分平分得两个样本区间:1—7和14—20,它们的样本个数均是7个,即n1=n2=7
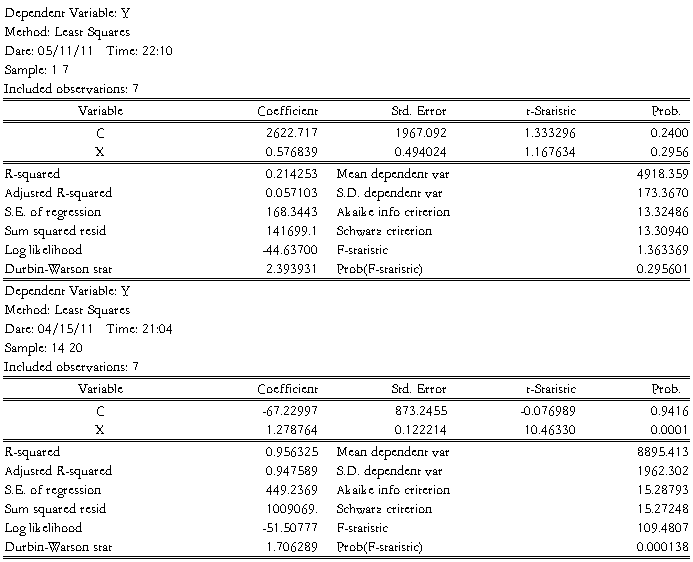
(3)求F统计量值。
基于表1和表2中残差平方和的
数据,即Sum squared resid的值。由表1计算得到
的残差平方和为 ,由表2计算得到的
,由表2计算得到的
残差平方和为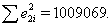 。
。
根据Goldfeld-Quanadt检验,F统计量为
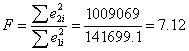
(4)判断
在 α=0,05 下,式中分子、分母的自由度均为6, 查F分布表得临界值为: 因为F=7.12> ,所以拒绝原假设,表明模型确实存在异方差
因为F=7.12> ,所以拒绝原假设,表明模型确实存在异方差
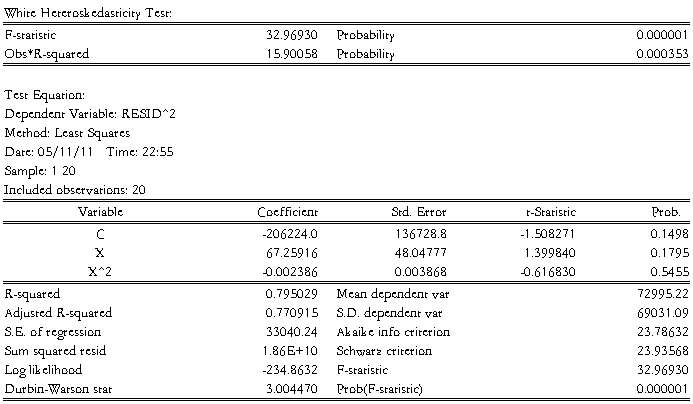
(三)White检验:
辅助函数为: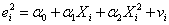
经估计出现White检验结果,见下表:

四、异方差的修正
加权最小二乘法(WLS)
所以选用权数: 
加权最小二乘的结果如下:
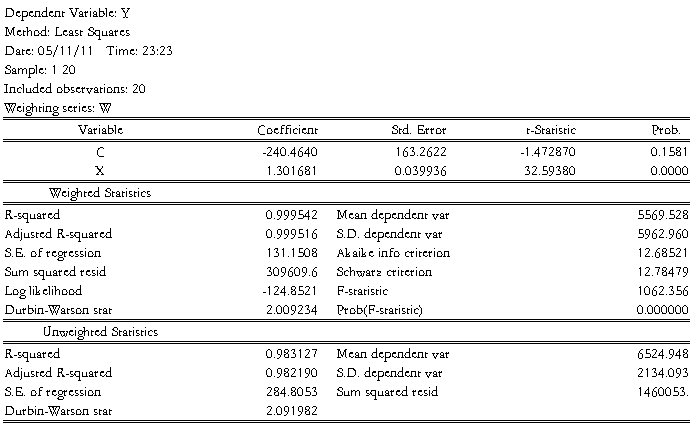
估计结果:
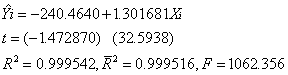
结论: 运用加权小二乘法消除了异方差性后,参数的t检验均显著,可决系数大幅提高,F检验也显著。
8、中国1980—20##年投资总额X与工业总产值Y的统计资料如下表所示。
单位:亿元
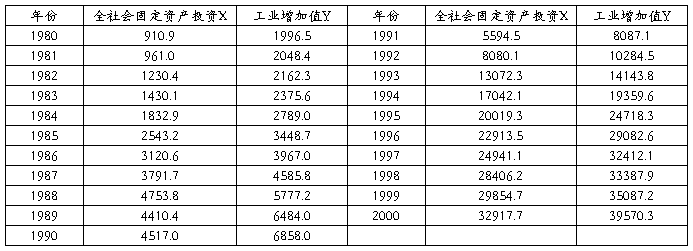
试问:
(1)当设定模型为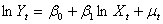 时,是否存在序列相关?
时,是否存在序列相关?
(2)若按一阶自相关假设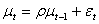 ,试用杜宾两步法和广义最小二乘法估计原模型。
,试用杜宾两步法和广义最小二乘法估计原模型。
(3)采用差分形式 与
与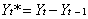 作为新数据,估计模型
作为新数据,估计模型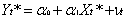 ,该模型是否存在序列相关?
,该模型是否存在序列相关?
解:(1)运用软件可得D.W.值为0.45,小于显著水平为5%下,样本容量为21的D.W.分布的下限临界值1.22,因此,可以判定模型存在一阶序列相关。
(2)按杜宾法估计的模型:

(2.95) (7.49) (6.04) (-1.16)