密码学
课程设计报告
一.古典密码算法... 3
1.1.实验内容... 3
1.2.实验目的... 3
1.3.需求分析... 3
1.4.程序流程图... 4
1.5.算法实现... 5
1.5.1 Playfair体制... 5
1.5.1.1算法描述... 5
1.5.1.2 核心代码解析... 5
1.5.1.3运行结果... 7
1.5.1.4 Playfair安全分析... 7
1.5.2 Vigenere体制... 8
1.5.2.1算法描述... 8
1.5.2.2核心代码解析... 8
1.5.2.3运行结果... 10
1.5.2.4 Vigenere安全分析... 10
1.5.3 Vernam体制... 11
1.5.3.1算法描述... 11
1.5.3.2核心代码解析... 12
1.5.3.3 运行结果... 13
1.5.3.4 Vernam安全分析... 13
二.分组密码算法DES. 14
2.1.实验内容... 14
2.2.实验目的... 14
2.3.需求分析... 14
2.4.DES算法描述... 15
2.5 DES算法流程... 17
2.6.DES核心代码分析... 17
2.7.DES运行结果... 20
2.8.DES安全分析... 20
三.大素数密码算法RSA. 22
3.1.实验内容... 22
3.2.实验目的... 22
3.3.需求分析... 22
3.4. 程序流程图... 23
3.5. 算法实现... 24
3.5.1 Miller-Rabin素性测试法... 24
3.5.1.1算法描述... 24
3.5.1.2核心代码分析... 25
3.5.1.3运行结果... 26
3.5.1.4 算法效率分析... 26
3.5.2 RSA算法实现... 27
3.5.2.1算法描述... 27
3.5.2.2 核心代码分析... 27
3.5.2.3运行结果... 29
3.5.2.4 RSA安全分析... 29
四.实验总结... 31
一.古典密码算法
1.1.实验内容:
用高级语言实现古典加密方法,多表古典加密方法主要有Playfair体制、Vigenere体制、Beaufor体制、Vernam体制和Hill体制,其中此实验本人运用了C++实现了Playfair体制、Vigenere体制、Vernam体制这三种多表古典加密方法。
1.2.实验目的:
掌握多表古典加密方法并分析多表古典加密方法各种体制的安全性。
1.3.需求分析:
古典密码系统已经初步体现出近代密码系统的雏形,加密方法逐渐复杂,其变化较小。虽然从近代密码学的观点来看,许多古典密码是不安全的,即是极易破译的,但我们不应当忘掉古典密码在历史上发挥的巨大作用。古典密码的代表密码体制主要有:单表代替密码、多表代替密码及转轮密码。Caser密码就是一种典型的单表加密体制;多表代替密码有Vigenere密码、Playfair体制、Vernam体制;著名的Enigma密码就是第二次世界大战中使用的转轮密码。古典密码的代表密码体制主要有:单表代替密码、多表代替密码及转轮密码。古典密码的加密方法一般是文字置换,使用手工或机械变换的方式实现。单表代换密码,指一旦密钥被选定,则每个明文字母对应的数字都被加密变换成对应的惟一数字,即对每个明文字母都用一个固定的明文字母表到密文字母表的确定映射。这种简单的一一对应关系,很容易被破译者用频率分析法进行破解。针对这种缺陷,人们提出多表代换密码,用一系列(两个以上)代换表依次对明文消息的字母进行代换。古典加密算法中很多算法的保密性是基于算法本身保密的,这一点与现代加密算法不同。正是由于算法本身保密,所以并不利于密码学的发展,密码学在古典密码学阶段发展是非常缓慢的。古典密码大都比较简单,这些加密方法是根据字母的统计特性和语言学知识加密的,在可用计算机进行密码分析的今天,很容易被破译。虽然现在很少采用,但研究这些密码算法的原理,对于理解、构造和分析现代密码是十分有益的。古典密码在整个密码体系中起着基础的作用,因此理解并熟练运用是进入这一学科的关键,也有助于进一步学习近代密码学。
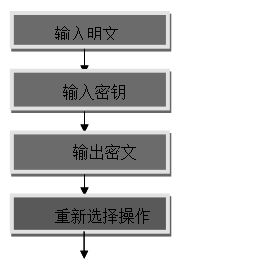
1.4.程序流程图:
因为下面所实现的三种体制程序个模块之间的联系都一样,所以这里就简化只做了一个流程图:

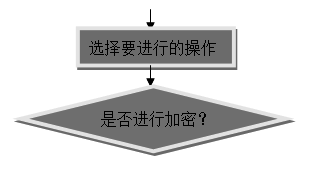
 N
N

Y
 N
N

 Y
Y





1.5.算法实现:
1.5.1 Playfair体制:
1.5.1.1算法描述:
Playfair密码出现于1854年,是最著名的多字母加密密码。Playfair算法使用关键词构造一个5×5的矩阵,其构造规则是按行依次写下关键词的字母(去除重复字母),然后按照字母表的顺序依次写下其余的字母,其中I和J算作同一个字母。Playfair加密过程如下:
首先,将明文按两个字母分组,假定一组中的明文字母分别为m1和m2,若m1与m2相同,则在重复的字母中间插入一个事先约定好的字母,若明文字母为奇数则在明文的末端添加一个实现事先约定好的字母。例如约定插入字母和补充字母均为X,则对明文CONNECTION的分组为CO NX NE CT IO NX。
其次,按照如下规则对明文组进行加密:
Ø 当m1、m2在同一行时,对应的密文c1、c2分别是紧靠m1、m2右边的字母。其中行的最后一个字母的密文是行的第一个字母。(解密时相反)
Ø 当m1、m2在同一列时,对应的密文c1、c2分别是紧靠m1、m2下方的字母。其中列的最后一个字母的密文是列的第一个字母。(解密时相反)
Ø 当m1、m2不在同一行也不在同一列时,对应的密文c1、c2分别是与m1同行且与m2同列的字母及与m2同行且与m1同列的字母。(解密时相同)
最后,将成生的密文组按次序排列即为最终的密文字母序列。
1.5.1.2 核心代码解析:
因为Playfair算法使用关键词构造一个5×5的矩阵,所以在编写代码的时候首先应该根据输入的密钥来填充矩阵。
//把密钥中的字母填入到矩阵中
for(int k=0;k<strlen(ch1);k++)
{
for(int t=0;t<25;t++)
{
if(ch1[k]==letters[t]&&flag[t]==0)
{
ch[i][j]=letters[t];
flag[t]=1;
if(j<4)j++;
else {i++;j=0;}
}
}
}
for( k=0;k<25;k++)//按字母表顺序把未用字母依次填入到矩阵中
{
if(flag[k]==0)
{
ch[i][j]=letters[k];
flag[k]=1;
if(j<4)j++;
else{i++;j=0;}
}
}
/*根据Playfair算法规则加密的重要部分当m1、m2在同一行时,对应的密文c1、c2分别是紧靠m1、m2右边的字母。其中行的最后一个字母的密文是行的第一个字母。(解密时相反)当m1、m2在同一列时,对应的密文c1、c2分别是紧靠m1、m2下方的字母。其中列的最后一个字母的密文是列的第一个字母。(解密时相反) 当m1、m2不在同一行也不在同一列时,对应的密文c1、c2分别是与m1同行且与m2同列的字母及与m2同行且与m1同列的字母。(解密时相同)*/
for(k=0;k<strlen(ch2);k+=2)
{
int m1,m2,n1,n2;
for(m1=0;m1<=4;m1++)
{for(n1=0;n1<=4;n1++)
{
if(ch2[k]==ch[m1][n1])break;
}
if(ch2[k]==ch[m1][n1])break;
}
for(m2=0;m2<=4;m2++)
{
for(n2=0;n2<=4;n2++)
{
if(ch2[k+1]==ch[m2][n2])break;
}
if(ch2[k+1]==ch[m2][n2])break;
}
m1=m1%5;
m2=m2%5;
if(n1>4){n1=n1%5;m1=m1+1;}
if(n2>4){n2=n2%5;m2=m2+1;}
if(m1==m2)
{
ch2[k]=ch[m1][(n1+1)%5];
ch2[k+1]=ch[m2][(n2+1)%5];
}
else
{
if(n1==n2)
{
ch2[k]=ch[(m1+1)%5][n1];
ch2[k+1]=ch[(m2+1)%5][n2];
}
else
{ch2[k]=ch[m1][n2];
ch2[k+1]=ch[m2][n1];
}
}
}
1.5.1.3运行结果:
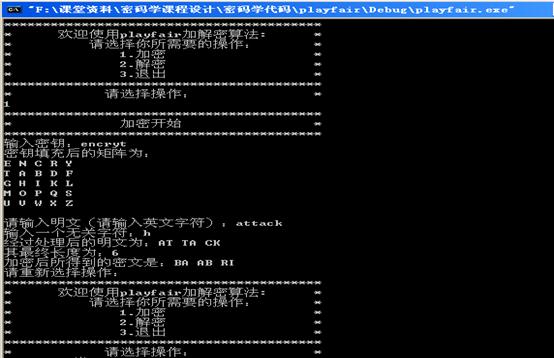
1.5.1.4 Playfair安全分析:
Playfair密码相对于简单的单表密码是一个巨大的进步。首先,因为有26个字母,故有26×26=676个字母对,因此对单个字母对进行判断要困难得多。而且,单个字母的相对频率比字母对的相对频率在统计规律上要好。这样利用频率分析字母对就更困难一些。因为这些原因,Playfair密码在很长一段时间内被认为是牢不可破的。第一次世界大战中英军就使用它作为陆军的战时加密体制,并且在第二次世界大战中,美军及其他一些盟国军队仍在大量使用。
PlayFair是对明文的每两个字母进行加密,而英语中各种连字(即两个字母的组合)已经被制成表格,且常用的连字如th、he、an、in、re、es等,及其变换(如er等),可以对密文出现的频率高的连字进行猜测,便能破解密文。此外,PlayFair密码存在另一弱点,每个明文字母在密文中仅对应5种可能的字母,除非使用的密钥很长,否则矩阵的剩余行是可以预测出来的。注意到这些,甚至可以仅用一段密文就可以攻破它。尽管Playfair密码被认为是较安全的,它仍然是相对容易攻破的,因为它的密文仍然完好地保留了明文语言的大部分结构特征。
1.5.2 Vigenere体制:
1.5.2.1算法描述:
Vigenere体制是 1586年由法国密码学家Blaise de Vigenere发明的,Vigenere密码是一种典型的多表替代密码。其密码表密码表是以字母表移位为基础把26个英文字母进行循环移位,排列在一起,形成26×26的方阵。当密钥的长度比明文短时,密钥可以周期性地重复使用,直至完成明文中每个字母的加密。利用26个英文字母构造Vigenere方阵,利用它可以方便地进行加密和解密,当用密钥字母对明文字母进行加密时,Vigenere方阵中的第行第列的字母就是相应的密文字母。
算法规律:将A~Z以0~25编号,那么加密过程就是,在代换表的第一行中找到消息字母,如“w”,然后向后移动d(即3)次,所得的字母就是密文了。如果数到末位,那么下一次移位就从头(即A)继续。也就是说,可以将A~Z看成一个环,加密过程就是找定消息字母后,将指针往环的某个特定方向移位,次数就是密钥字母所代表的数字,这其实是一个模26的过程,所以在算法之中要将字母对应到数字。
 Vigenere密码表
Vigenere密码表
Vigenere密码算法表示如下:
设密钥K= k0k1k2…kd,明文M= m0m1m2…mn
加密变换:ci=(mi+ki)mod26, i=0,1,2,,n
解密变换:mi=(ci-ki)mod26, i=0,1,2,,n
1.5.2.2核心代码解析:
根据Vigenere密码是以字母表移位为基础把26个英文字母进行循环移位,排列在一起,形成26×26的方阵。所以首先进行数字与字母对应。
//把行号字母对应到数字
Char v[N][N]={{'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P',
'Q','R','S','T','U','V','W','X','Y','Z'}};
int number(char x) {
char y='a';
for(int i=0;i<N;i++)
{
if(x==(y+i)) return i;
}
}
加密过程:给定一个密钥字母k和一个明文字母m,密文字母就是位于k所在的行与m所在的列的交叉点上的那个字母 .
void encryption(string m,string k)//加密过程
{
cout<<"明文:";
cin>>m;
cout<<"密钥:";
cin>>k;
int mlen,klen;
mlen=m.length();
klen=k.length();
char *p,*q,*t;//明文,初始密钥,密钥串。把string换成char
p=new char[m.length()+1];
strcpy(p,m.c_str());
q=new char[k.length()+1];
strcpy(q,k.c_str());
t=new char[m.length()+1];
int j=0;
for(int i=0;i<mlen;i++)
{
t[i]=q[j];
j++;
j=j%klen;
}
解密过程:由密钥字母决定行,在该行中找到密文字母,密文字母所在列的列首对应的明文字母就是相应的明文
void disencryption(string c,string k)//解密过程
{
cout<<"密文:";
cin>>c;
cout<<"密钥:";
cin>>k;
int clen,klen;
clen=c.length();
klen=k.length();
char *p,*q,*t; //密文,初始密钥,密钥串。把string换成char
p=new char[c.length()+1];
strcpy(p,c.c_str());
q=new char[k.length()+1];
strcpy(q,k.c_str());
t=new char[c.length()+1];
int j=0;
for(int i=0;i<clen;i++)
{
t[i]=q[j];
j++;
j=j%klen;
}
1.5.2.3运行结果:
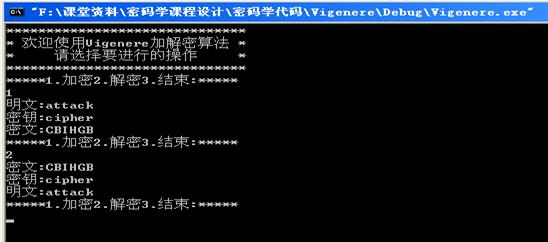
1.5.2.4 Vigenere安全分析:
维吉尼亚密码采用26张替换表依次对明文消息的字母进行替换。由于此密码变换中,明文的每个字母是按照密钥字的指示,选用不同的加同余密码替换而成的,因此,同一个字母在明文中的位置不同,对应的密文字母就不同。它克服了单表替换密码中明密文字母一一对应的弱点,能比较好的抵抗频率攻击法。但多表替换中各个字母的概率只是被做了置换,它不能够抵抗已知明文等攻击方法。这种密码的强度在于每个明文字母对应着多个密文字母,且每个密文字母使用惟一的密钥字母,因此字母出现的频率信息被隐藏了,不过并非所有的明文结构信息都隐藏了。Vigenère提出用一个所谓的“密钥自动生成系统”来将密钥词和明文自身连接来生成不重复的密钥词。即使采用这个方案,它也是易受攻击的。因为密钥和明文具有相同频率的分布特征,所以我们可以应用统计学的方法。例如,用“e”加密“e”,由英文字母的相关概率分析图如 (图1)可以估计出其发生的概率为(0.127)2≈0.016,而用“t”加密“t”发生的概率大概只有它的一半,等等。密码分析者利用这些规律能够成功地进行分析虽然破译Vigenère密码的技术并不复杂 。如果认为是用Vigenère密码加密的,破译能否取得进展将取决于能否判定密钥词的长度。洞察到这个事实很重要:如果两个相同的明文序列之间的距离是密钥词长度的整数倍,那么产生的密文序列也是相同的。
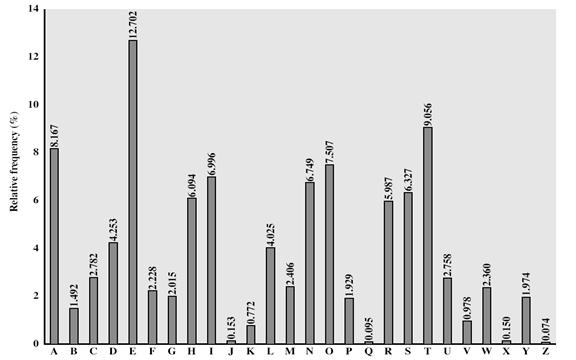
图1语言的统计特性
1.5.3 Vernam体制:
1.5.3.1算法描述:
序列 密 码 的思 想 起 源 于 20世 纪 20年 代 ,最早的二进 序 列密码 系 统是 Vernam密码 。Vernam密码将明文消息转化为二进制数字序列 ,密钥序列也为二进数字序列 ,加密是按明文序列和密钥序列逐位模 2相加进行 ,解密也是按 密文序列和密钥序列逐位模 2相加进行 。Vernam的算法实现一个简洁而又稳定的文件加密解密类。通过此类加密的数据是绝对无法在没有密钥的情况下被破解的。它的基本原理是,需要有一个需要加密的明文和一个随机生成的解密钥匙文件。然后使用这两个文件组合起来生成密文:(明文) 组合 (密钥) = 加密后的密文。使用Vernam加密算法,经其处理的密钥可以拥有与待加密文件大小相同的密钥长度,而且输出文件的大小相比待加密文件无任何改变(精确到字节)。换言之,密钥文件越大,加密强度越高!
Vernam密码算法:
1、 现代密码体制的萌芽是Vernam加密方法。
2、Vernam密码是美国电话电报公司的Gilbert Vernam在1917年为电报通信设计的一种非常方便的密码,它在近代计算机和通信系统设计中得到了广泛应用。
3、Vernam密码的明文、密钥和密文均用二元数字序列表示。这是一种使用异或方法进行加密解密的方法。
4、要编制Vernam密码,只需先把明文和密钥表示成二元序列,再把它们按位模2相加,就可得到密文。
5、而解密只需把密文和密钥的二元序列按位模2相加便可得到明文。
6、开始时使用一个定长的密钥序列,这样产生的密文能形成有规律的反复,易被破译;后来采用的密钥与明文同长,且密钥序列只用一次,称为“一次一密体制”。
1.5.3.2核心代码解析:
根据Vernam密码算法: Vernam密码的明文、密钥和密文均用二元数字序列表示,这就需要我们输入的字符要转换成二进制数字然后进行加解密计算。
void change(string &plain, vector<int>&number) //字母变数字
{
for (unsigned int i=0;i<plain.size();i++)
{
number.push_back(plain[i]-97); //a为0
}
}
要编制Vernam密码,只需先把明文和密钥表示成二元序列,再把它们按位模2相加,就可得到密文。
vector<int> encrypt_compute(vector<int> m,vector<int> k) //加密计算
{
vector<int> sum;
for(unsigned int i=0; i<m.size(); i++)
{
sum.push_back((m[i]+k[i])%26);
}
return sum;
}
解密只需把密文和密钥的二元序列按位模2相加便可得到明文。下面就是解密代码:
vector<int> discrypt_compute(vector<int> c,vector<int> k) //解密计算
{
vector<int> resum;
int temp;
for(unsigned int i=0; i<c.size(); i++)
{
temp = c[i]-k[i];
if(temp<0) temp+=26;
resum.push_back(temp);
}
return resum;
}
1.5.3.3 运行结果:
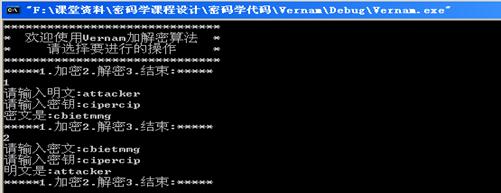
1.5.3.4 Vernam安全分析:
1917年工程师Gilbert Vernam首先引入了这种体制,其运算基于二进制数据而非字母。这种技术的本质在于构造密钥的方式。Vernam提出使用连续的磁带,其最终也将循环。所以事实上该体制是使用周期很大的循环密钥。尽管周期很长对于密码分析增添了相当大的难度,但是如果有足够的密文,使用已知或可能的明文序列,或者联合使用二者,该方案是可以被破解的。
Vernam加密算法实际上是在(0,1)字母上运用Vigenere加密算法。这种方法的优点在于(mi + ki) mod 2运算非常容易实现。而且ci + ki≡mi mod 2,这里的加法都是不进位的二进制加法 在同一密钥下,Vernam密码只要找到一组和密码对应的明文便可破译。
之后,陆军情报军官Joseph Mauborgne提出了一种对Vernam密码的改进方案,从而达到了最完善的安全性。Mauborgne建议使用与消息一样长且无重复的随机密钥来加密消息,另外,密钥只对一个消息进行加解密,之后丢弃不用。每一条新消息都需要一个与其等长的新密钥。这就是著名的一次一密,它是不可攻破的。它产生的随机输出与明文没有任何统计关系。因为密文不包含明文的任何信息,所以无法可破。
因为给出任何长度与密文一样的明文,都存在着一个密钥产生这个明文。因此,如果你用穷举法搜索所有可能的密钥,就会得到大量可读、清楚的明文,但是没有办法确定哪一个才是真正所需的,因而这种密码是不可破的。
在实际中,一次一密提供完全的安全性存在两个基本难点:
(1). 产生大规模随机密钥有实际困难。任何经常使用的系统都需要建立在某个规则基础上的数百万个随机字符,提供这样规模的真正随机字符是相当艰巨的任务。
(2). 更令人担忧的是密钥的分配和保护。对每一条发送的消息,需要提供给发送方和接收方等长度的密钥。因此,存在庞大的密钥分配问题。
因为上面这些困难,一次一密实际很少使用,主要用于安全性要求很高的低带宽信道。
如能做到以下三点,则 Vernam密码是绝对不可破译的:
(1) 密钥是随机序列;
(2) 密钥的长度大于或等于明文的长度;
(3) 一个密钥只用一次;
二.分组密码算法DES
2.1.实验内容:
用高级语言实现实现DES加密和解密算法,DES是由初始变换、乘积变换和逆初始变换构成,乘积变换是DES算法的核心。首先用代码实现这几个变换,然后组合成DES加密算法。由于DES解密算法与加密算法相同只是子密钥使用次序不同,因此可简单地由加密算法实现解密算法。
2.2.实验目的:
掌握分组加密算法的设计与实现方法并对DES的安全性进行分析。
2.3.需求分析:
数据加密标准(DES,Data Encryption Standard)是一种使用密钥加密的块密码,它基于使用56位密钥的对称算法。美国国家标准局(NBS)于1973年向社会公开征集一种用于政府机构和商业部门的加密算法,经过评测,最终选择了IBM公司提出的一种加密算法。经过一段时间的试用,美国政府于1977年颁布DES。DES是分组密码的典型代表,也是第一个被公布出来的标准算法,曾被美国国家标准局(现为国家标准与技术研究所NIST)确定为联邦信息处理标准(FIPS PUB 46),使用广泛,特别使在金融领域,曾是对称密码体制事实上的世界标准。DES自从公布以来,已成为金融界及其他各种行业最广泛应用的对称密钥密码系统。DES是分组密码的典型代表,也是第一个被公布出来的标准算法。原来规定DES算法的使用期为10年,可能是DES尚未受到严重威胁,更主要是新的数据加密标准研制工作尚未完成,或意见尚未统一,所以当时的美国政府宣布延长它的使用期。因而DES超期服役到20##年。近三十年来,尽管计算机硬件及破解密码技术的发展日新月异,若撇开DES的密钥太短,易于被使用穷举密钥搜寻法找到密钥的攻击法不谈,直到进入20世纪90年代以后,以色列的密码学家Shamir等人提出一种“差分分析法”,以后日本人也提出了类似的方法,这才称得上对它有了攻击的方法。严格地说Shamir的“差分分析法”也只是理论上的价值。至少到目前为止是这样,比如后来的“线形逼迫法”,它是一种已知明文攻击,需要243≈4.398×1012个明、密文对,在这样苛刻的要求下,还要付出很大的代价才能解出一个密钥。不管是差分攻击还是线性攻击法,对于DES的安全性也仅仅只做到了“质疑”的地步,并未从根本上破解DES。也就是说,若是能用类似Triple-DES或是DESX的方式加长密钥长度,仍不失为一个安全的密码系统。
早在DES提出不久,就有人提出造一专用的装置来对付DES,其基本思想无非是借用硬件设备来实现对所有的密钥进行遍历搜索。由于电子技术的突飞猛进,专门设备的造价大大降低,速度有质的飞跃,对DES形成了实际的威胁。DES确实辉煌过,它的弱点在于专家们一开始就指出的,即密钥太短。美国政府已经征集评估和判定出了新的数据加密标准AES以取代DES对现代分组密码理论的发展和应用起了奠基性的作用,它的基本理论和设计思想仍有重要参考价值。
安全性是分组密码最重要的设计原则,它要求即使攻击者知道分组密码的内部结构,仍不能破译该密码,这也意味着,不存在针对该密码的某种攻击方法,其工作量小于穷密钥搜索。但是随着密码分析技术的发展,使得对于具有更多轮的分组密码的破译成为可能。
现如今,依靠Internet的分布式计算能力,用穷举密钥搜索攻击方法破译已成为可能。数据加密标准DES已经达到它的信任终点。但是作为一种Feistel加密算法的例子仍然有讨论的价值。
2.4.DES算法描述:
DES是一种分组密码,明文、密文和密钥的分组长度都是64位并且是面向二进制的密码算法。DES处理的明文分组长度为64位,密文分组长度也是64位,使用的密钥长度位56位(实际上函数要求一个64位的密钥作为输入,但其中用到的只有56位,另外8位可以用做奇偶校验位或者完全随意设置)。DES是对合运算,它的解密过程和加密相似,解密时使用与加密同样的算法,不过子密钥的使用次序要反过来。DES的整个体制时公开的,系统的安全性完全靠密钥的保密。
DES在算法结构上采用置换、代替、模2加等基本密码运算构成轮加密函数,对轮加密函数进行16次迭代。DES算法是对合算法,工程上实现比较容易。DES算法中除了S盒是非线性变换外,其余变换都是线性变换,因此DES算法的安全关键在于S盒,其本质是数据压缩,把6位的数据压缩为4位数据。此外,S盒和置换P相互结合,具有较强的抗差分攻击和抗线性攻击能力。DES的子密钥产生和使用能确保原密钥的各位的使用次数基本相等,这也使得DES的保密性得到进一步的增强。
DES算法的加密过程经过了三个阶段:
首先,64位的明文在一个初始置换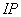 后,比特重排产生了经过置换的输入,明文组被分成右半部分和左半部分,每部分32位,以
后,比特重排产生了经过置换的输入,明文组被分成右半部分和左半部分,每部分32位,以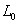 和
和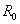 表示。
表示。
接下来的阶段是由对同一个函数进行16次循环组成的,16轮迭代称为乘积变换或函数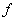 。这个函数本身既包含换位又包含代替函数,将数据和密钥结合起来,最后1轮的输出由64位组成,其左边和右边两个部分经过交换后得到预输出。
。这个函数本身既包含换位又包含代替函数,将数据和密钥结合起来,最后1轮的输出由64位组成,其左边和右边两个部分经过交换后得到预输出。
最后阶段,预输出通过一个逆初始置换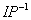 算法就生成了64位的密文结果。
算法就生成了64位的密文结果。
DES的加密过程可简单描述为三个阶段:
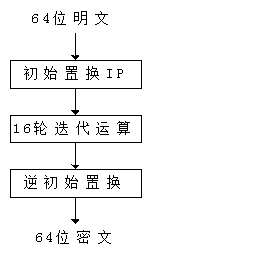
DES的解密算法与加密算法共用相同的算法过程,即使用相同的方法完成加密和解密,两者的不同之处仅在于解密时子密钥Ki的使用顺序与加密时相反。
相对应的DES的解密过程由于DES的运算是对合运算,所以解密和加密可共用同一个运算,只是子密钥的使用的顺序不同。解密过程可用如下的数学公式表示:
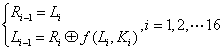
2.5 DES算法流程:

图(1) DES算法的整体结构图
图(2) DES算法的迭代过程图
2.6.DES核心代码分析:
下面根据具体情况确定要执行哪种置换,前面已经定义了所要用到的几种置换:
IP变换,IP-1变换,f变换,扩展变换,P变换以及S盒结构。
void keyfc(char *In) //获取密钥函数
此函数的功能是由64比特的密钥产生16个子密钥ki。首先将密钥字节组key[8]转换为64比特的位组,然后进行密钥变换置换后得到56比特的密钥,把变换后的密钥等分成两部分,之后进行循环左移运算
void DES(char Out[8],char In[8],bool MS)//加密核心程序,ms=0时加密,反之解密
{
bool MW[64],tmp[32],PMW[64]; //注意指针
bool kzmw[48],keytem[48],ss[32];
int hang,lie;
ByteToBit(PMW,In,64);
for(int j=0;j<64;j++)
{
MW[j]=PMW[ip[j]-1]; //初始置换
}
bool *Li=&MW[0],*Ri=&MW[32];
for(int i=0;i<48;i++) //右明文扩展置换
kzmw[i]=Ri[ei[i]-1]; //注意指针
//扩展置换表,作用是将32比特的输入扩展为48比特
t static char ei[] = { //扩展置换
32, 1, 2, 3, 4, 5,
4, 5, 6, 7, 8, 9,
8, 9, 10, 11, 12, 13,
12, 13, 14, 15, 16, 17,
16, 17, 18, 19, 20, 21,
20, 21, 22, 23, 24, 25,
24, 25, 26, 27, 28, 29,
28, 29, 30, 31, 32, 1};
//加密阶段的初始置换IP
const static char ip[] = { //IP初始置换
58, 50, 42, 34, 26, 18, 10, 2,
60, 52, 44, 36, 28, 20, 12, 4,
62, 54, 46, 38, 30, 22, 14, 6,
64, 56, 48, 40, 32, 24, 16, 8,
57, 49, 41, 33, 25, 17, 9, 1,
59, 51, 43, 35, 27, 19, 11, 3,
61, 53, 45, 37, 29, 21, 13, 5,
63, 55, 47, 39, 31, 23, 15, 7
};
xor()此函数的功能是进行异或运算,异或运算是按位作不进位加法运算。
void Xor(bool *InA,const bool *InB,int len) //按位异或
{
for(int i=0;i<len;i++)
InA[i]^=InB[i];
}
ByteToBit()此函数的功能是将输入的字节组转换为位组。
void ByteToBit(bool *Out,char *In,int bits) //字节到位的转换
{
int i;
for(i=0;i<bits;i++)
Out[i]=(In[i/8]>>(i%8))&1;
}
BitToByte()此函数的功能是将位组转换字节组。
void BitToByte(char *Out,bool *In,int bits) //位到字节转换
{
for(int i=0;i<bits/8;i++)
Out[i]=0;
for(i=0;i<bits;i++)
Out[i/8]|=In[i]<<(i%8); //"|="组合了位操作符和赋值操作符的功能
}
加密过程最后阶段预输出通过一个逆初始置换算法就生成了64位的密文结果。
const static char fp[] = { //IP逆初始置换
40, 8, 48, 16, 56, 24, 64, 32,
39, 7, 47, 15, 55, 23, 63, 31,
38, 6, 46, 14, 54, 22, 62, 30,
37, 5, 45, 13, 53, 21, 61, 29,
36, 4, 44, 12, 52, 20, 60, 28,
35, 3, 43, 11, 51, 19, 59, 27,
34, 2, 42, 10, 50, 18, 58, 26,
33, 1, 41, 9, 49, 17, 57, 25
};
此主函数贯穿整个函数。首先是初设密钥,然后调用密钥设置函数和DES算法的运行函数,最后得出密文以及解密后的文字。
void main()
{
char Ki[8],jm[8],final[8];
int i0;
cout<<"请输入密钥(8字节):"<<endl;
for(i0=0;i0<8;i0++)
cin>>Ki[i0];
keyfc(Ki);
cout<<"请输入明文:"<<endl;
for(i0=0;i0<8;i0++)
cin>>jm[i0];
DES(final,jm,0); //加密
for(i0=0;i0<8;i0++)
cout<<final[i0];
cout<<endl;
DES(jm,final,1); //解密
for(i0=0;i0<8;i0++)
cout<<jm[i0];
cout<<endl;
}
具体代码和注释在代码中都有详细介绍。
2.7.DES运行结果:
2.8.DES安全分析:
DES算法具有极高安全性,最初,除了用穷举搜索法对DES算法进行攻击外,并没有发现更有效的办法。而56位长的密钥的穷举空间为256,这意味着如果一台计算机的速度是每一秒种检测一百万个密钥,则它搜索完全部密钥就需要将近2285年的时间,可见,这是难以实现的,当然,随着科学技术的发展,当出现超高速计算机后,我们可考虑把DES密钥的长度再增长一些,以此来达到更高的保密程度。
DES在总体上应该说是极其成功的,但在安全上也有其不足之处:
(1)密钥太短:IBM原来的Lucifer算法的密钥长度是128位,而DES采用的是56位,这显然太短了。1998年7月17日美国EEF(Electronic Frontier Founation)宣布,他们用一台价值25万美元的改装计算机,只用了56个小时就穷举出一个DES密钥。1999年EFF将该穷举速度提高到24小时。
(2)存在互补对称性:将密钥的每一位取反。用原来的密钥加密已知明文得到密文分组,那么用此密钥的补密钥加密此明文的补便可得到密文分组的补。这表明,对DES的选择明文攻击仅需要测试一半的密钥,从而穷举攻击的工作量也就减半。
除了上述两点之外,DES的半公开性也是人们对DES颇有微辞的地方。
在DES算法作为一个标准时,曾出现过许多的批评,其中之一就是针对S盒的。DES里的所有计算,除去S盒全是线性的,也就是说,计算两个输出的异或与先将两个对应输入异或再计算其输出是相同的。作为非线性部件,S盒针对密码体制的安全性至关重要。在算法提出时,就有人怀疑S盒隐藏了“陷门”。而美国国家安全局能够轻易的解密消息,同时还能宣称DES算法是“安全”的。当然无法否认这一猜测,然而到目前为止,并没有任何证据证明DES里的确存在陷门。
事实上,后来表明DES里的S盒是被设计成能够防止某些类型的攻击的。在20世纪90年代初,Biham与Shamir发现差分分析时,美国国家安全局就已承认某些未公布的S盒设计原则正是为了使得差分密码分析变得不可行。事实上,差分密码分析在DES最初被研发时就已成为IBM的研究者所知,但这种方法却被保留了将近20年,直到Biham与Shamir又独立地发现了这种攻击。
对DES算法最中肯的批评是,密钥太短。DES算法中只用到64位密钥中的其中56位,第8、16、24、......64位8个位并未参与DES运算,而是用作奇偶校验。在所有的密钥空间中有极少量的弱密钥,如全0和全F的密钥等,在选择时应尽量避免。这一点,向我们提出了一个应用上的要求,即DES的安全性是基于除了8,16,24,......64位外的其余56位的组合变化256才得以保证的。因此,在实际应用中,我们应避开使用第8,16,24,......64位作为有效数据位,而使用其它的56位作为有效数据位,才能保证DES算法安全可靠地发挥作用。如果不了解这一点,把密钥Key的8,16,24,..... .64位作为有效数据使用,将不能保证DES加密数据的安全性,对运用DES来达到保密作用的系统产生数据被破译的危险,这正是DES算法在应用上的误区,留下了被人攻击、被人破译的极大隐患。总之,DES密钥太短,超期服役的时间也太长。新的攻击手段不断出现,DES以面临实实在在的威胁。直接的威胁还是在于专用设备,由于芯片的速度越来越快,造价越来越便宜,导致专用设备的造价也大大的降低。
DES算法除了差分密码分析另外两种最重要的密码攻击是穷尽密钥搜索和线性密码分析。对DES算法而言,线性攻击更有效。在1994年,一个实际的线性密码分析由其发明者Matsui提出。这是一个使用243对明文-密文,又用了40天来找到密钥。这个密码分析并未对DES的安全性产生实际影响,由于这个攻击需要数目极大的明-密文对,在现实世界中一个敌手很难积攒下用同一密钥加密的如此众多的明-密文对。
虽然DES加密算法已经过时,但它的基本理论和设计思想仍有重要参考价值。
三.大素数密码算法RSA
3.1.实验内容:
用高级语言实现Solovay-Strassen素性测试法或Miller-Rabin素性测试法并且要求用代码实现RSA的加解密过程。
3.2.实验目的:
进一步掌握大素数分解的一般原理和实现方法,并且对RSA加密算法的安全性进行分析了解。
3.3.需求分析:
当前最著名、应用最广泛的公钥系统RSA是在1978年由美国麻省理工学院(MIT)的Rivest、Shamir和Adleman在题为《获得数字签名和公开钥密码系统的方法》的论文中提出的。RSA系统是公钥系统的最具有典型意义的方法,大多数使用公钥密码进行加密和数字签名的产品和标准使用的都是RSA算法。它是一个基于数论的非对称(公开钥)密码体制,是一种分组密码体制。其名称来自于三个发明者的姓名首字母。 它的安全性是基于大整数素因子分解的困难性,而大整数因子分解问题是数学上的著名难题,至今没有有效的方法予以解决,因此可以确保RSA算法的安全性。素数问题是一个使很多数学家着迷的问题。素数就是一个除了l和它自身以外不能被其它数整除的数。素数的一个基本问题是如何有效地确定一个数是否是一个素数,即素性测试问题。
素性测试问题不仅在数学上是一个有挑战性的问题,而且在实际应用中也是非常重要的。在现代密码系统中,大素数的判别和寻找对一些加密系统的建立起着关键作用。很多公钥密码算法都用到素数,特别是160位(二进制)以上的大素数。RSA的公共模数就是两个5 12位以上的大素数的乘积;由此可见对大数进行的素性判断的重要性。判定一个整数是否是素数,最为简单的想法是直接利用素数的定义,用比要判断的整数小的素数去一一试除,如果能整除被检测的数的话,那就能确定无疑为合数了.但是对于大素数来说,由于计算量太大,根本无法实现以用于具体应用。所以科学家们根据素数判断的理论发明了许多新的算法,提高了判断一个大数是否是一个大素数的效率。由于素数在正整数序列中分布不规则,无法用公式直接计算出一个指定长度的大素数,所以当前采用的方法是随机产生一个大整数,再对其做素性检测.常见的素性检测法有 MillerRabin 检测、 Solovay - Strassen 检测法和 Lehman 检测法.目前,提高素数生成速度的方法是用 100 以内的小素数首先进行筛选这是因为判断大整数能否被小素数整除的时间要比各种概率测试法短得多,一般说来,这种筛选可以排除大整数不是素数 769毛的可能性;之后再进行 5 次 MillerRabin 检测,那么这个大数不是素数的概率就会降到1/1 000 以下,这样就加快了大素数生成的速度.
RSA算法是第一个既能用于数据加密也能用于数字签名的算法,因此它为公用网络上信息的加密和鉴别提供了一种基本的方法。虽然自1978年提出以来,RSA的安全性一直未能得到理论上的证明,但它经历了各种攻击,至今(20##年)未被完全攻破。随着越来越多的商业应用和标准化工作,RSA已经成为最具代表性的公钥加密技术。VISA、MasterCard、IBM、Microsoft等公司协力制定的安全电子交易标准(Secure Electronic Transactions,SET)就采用了标准RSA算法,这使得RSA在我们的生活中几乎无处不在。网上交易加密连接、网上银行身份验证、各种信用卡使用的数字证书、智能移动电话和存储卡的验证功能芯片等,大多数使用RSA技术。
3.4. 程序流程图:
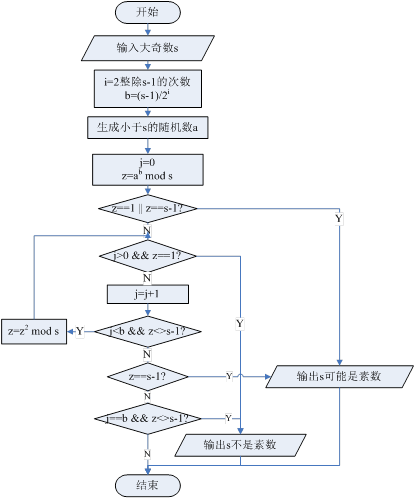
Rabin Miller素数检验算法流程图
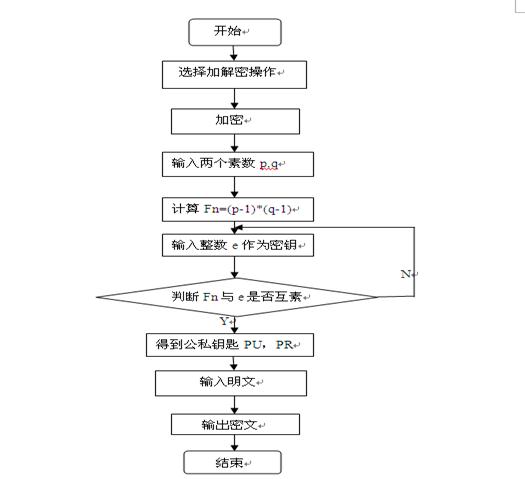
RSA的加密流程图
3.5. 算法实现:
3.5.1 Miller-Rabin素性测试法
3.5.1.1算法描述:
Miller-Rabin算法是基于Gary Miller的部分象法,由Michael Rabin发展。更多的人叫它“测试”,因为通过Miller-Rabin测试的并不一定就是素数,非素数通过测试的概率是1/4。Rabin Miller算法是一个概率算法,一轮 Rabin Miller 算法的最坏情况时间复杂度为(1+O(1))log2 (n)(以模n 乘 法为基本操作)。如果以单精度乘法操作作为时间复杂度的衡量,则一轮优化的 Rabin Miller算法的最坏情况时间复杂度为O(log32(n))。从时间复杂度来看Miller-Rabin算法的性能是很好的。在实际应用中,Rabin Miller算法的实际执行速度也很快。Miller-Rabin是随机算法结果的正确率约为 75%,所以应该多次调用该函数,使正确概率提高为1-(1/4)^p。
二次探测定理 如果p是一个素数,0<x<p,则方程x^2≡1(mod p)的解为x=1,p-1.根据费马定理和二次探测定理到Miller-Rabin算法的一般步骤:
0、先计算出m、j,使得n-1=m*2^j,其中m是正奇数,j是非负整数
1、随机取一个b,2<=b
2、计算z=b^m mod n
3、如果z==1,通过测试,返回
4、令i=1
5、如果z=n-1,通过测试,返回
6、如果i==j,非素数,结束
7、z=z^2 mod n,i=i+1
8、循环到5.
3.5.1.2核心代码解析:
pow_self()使用此函数进行指数运算这是Miller-Rabin算法的比较重要的一步。
//指数运算
int pow_self(int di,int mi,int mod)
{
int temp;
int i;
temp=1;
for(i=1;i<=mi;i++)
{
temp=(temp*di)%mod;
}
return temp;
}
计算z=a^m mod p是Miller-Rabin算法,如果z==1,通过测试,返回
z=pow_self(a,m,r); //z=pow(a,m) mod p
对于b进行赋值使b是能整除n-1的2的最大幂
while(m%2==0)
{
b=b+1;
m=m/2;} //b是能整除n-1的2的最大幂
3.5.1.3运行结果:

3.5.1.4 算法效率分析:
对于大数的素 性判断,目前Miller-Rabin算法应用最广泛。一般底数仍然是随机选取,但当待测数不太大时,选择测试底数就有一些技巧了。比如,如果被测数小于 4 759 123 141,那么只需要测试三个底数2, 7和61就足够了。当然,你测试的越多,正确的范围肯定也越大。如果你每次都用前7个素数(2, 3, 5, 7, 11, 13和17)进行测试,所有不超过341 550 071 728 320的数都是正确的。如果选用2, 3, 7, 61和24251作为底数,那么10^16内唯一的强伪素数为46 856 248 255 981。这样的一些结论使得Miller-Rabin算法在OI中非常实用。通常认为,Miller-Rabin素性测试的正确率可以令人接受,随机选取 k个底数进行测试算法的失误率大概为4^(-k)。
Miller-Rabin算法是一个RP算法。RP是时间复杂度的一种,主要 针对判定性问题。一个算法是RP算法表明它可以在多项式的时间里完成,对于答案为否定的情形能够准确做出判断,但同时它也有可能把对的判成错的(错误概率 不能超过1/2)。RP算法是基于随机化的,因此多次运行该算法可以降低错误率。还有其它的素性测试算法也是概率型的,比如Solovay- Strassen算法。另外一些素性测试算法则需要预先知道一些辅助信息(比如n-1的质因子),或者需要待测数满足一些条件(比如待测数必须是2^n- 1的形式)。前几年AKS算法轰动世界,它是第一个多项式的、确定的、无需其它条件的素性判断算法。当时一篇论文发表出来,题目就叫PRIMES is in P,然后整个世界都疯了,我们班有几个MM那天还来了初潮。算法主要基于下面的事实:n是一个素数当且仅当(x-a)^n≡(x^n-a) (mod n)。注意这个x是多项式中的未知数,等式两边各是一个多项式。举个例子来说,当a=1时命题等价于如下结论:当n是素数时,杨辉三角的第n+1行除两头 的1以外其它的数都能被n整除。
3.5.2 RSA算法实现:
3.5.2.1算法描述:
RSA公钥算法是由美国麻省理工学院(MIT)的Rivest,Shamir 和Adleman 在1978年提出的。由于RSA密码,既可用于加密,又可用于数字签名,安全、易懂,因此RSA方案是惟一被广泛接受并实现的通用公开密钥密码算法,许多国家标准化组织,如ISO,ITU和SWIFT等都已接受RSA作为标准。Internet网的E-Mail保密系统GPG以及国际VISA和MASTER组织的电子商务协议(SET协议)中都将RSA密码作为传送会话密钥和数字签名的标准。RSA公钥算法的数学基础是初等数论的Euler定理,其安全性建立在大整数因子分解的困难性之上。
RSA密码体制的明文空间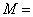 密文空间
密文空间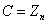 整数,其算法描述如下:
整数,其算法描述如下:
(1)密钥的生成
首先,选择两个互异的大素数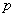 和
和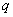 (保密),计算
(保密),计算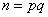 (公开),
(公开),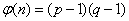 (保密),选择一个随机整数
(保密),选择一个随机整数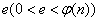 ,满足
,满足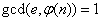 (公开)。计算
(公开)。计算 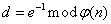 (保密)。确定:公钥
(保密)。确定:公钥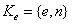 ,私钥
,私钥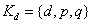 ,即
,即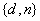 。
。
(2)加密
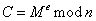
(3)解密
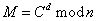
3.5.2.2 核心代码分析:
这是代码主要的函数如下图:
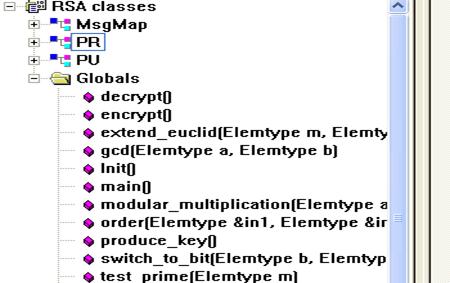
// PU为产生的公钥
struct PU {
Elemtype e;
Elemtype n;
} pu;
//PR为产生私钥
struct PR {
Elemtype d;
Elemtype n;
} pr;
// test_prime函数为判定输入的数是否为素数这是RSA代码最基本的部分,
bool test_prime(Elemtype m) {
if (m <= 1) {
return false;
}
else if (m == 2) {
return true;
}
else {
for(int i=2; i<=sqrt(m); i++) {
if((m % i) == 0) {
return false;
break;
}
}
return true;
}
}
下面是判定输入的密钥e是否与Fn互素
while((gcd(fn,e)!=1)) {
cout<<"e is error,try again!";
cout<<"input e :";
cin>>e;
}
// 函数modular_multiplication是快速模幂算法
Elemtype modular_multiplication(Elemtype a, Elemtype b, Elemtype n) {
Elemtype f = 1;
Elemtype bin[32];
switch_to_bit(b,bin);
for(int i=31; i>=0; i--) {
f = (f * f) % n;
if(bin[i] == 1) {
f = (f * a) % n;
}
}
return f;
}
//函数encrypt是为明文加密
void encrypt() {
if(flag == 0) {
cout<<"setkey first:"<<endl;
produce_key();
}
cout<<"input m:";
cin>>m;
c = modular_multiplication(m,pu.e,pu.n);
cout<<"c is:"<<c<<endl;
}
// /函数decrypt是对产生的明文解密
void decrypt() {
if(flag == 0) {
cout<<"setkey first:"<<endl;
produce_key();
}
cout<<"input c:";
cin>>c;
m = modular_multiplication(c,pr.d,pr.n);
cout<<"m is:"<<m<<endl;
}
3.5.2.3运行结果:

明文为:131 密钥为:113 两个素数为:23和29 输出的密文为:508
下面输入密文就解密出了明文。
3.5.2.4 RSA安全分析:
自公钥加密问世以来,学者们提出了许多种公钥加密方法,它们的安全性都是基于复杂的数学难题.当前最著名、应用最广泛的公钥系统RSA,它的安全性是基于大整数素因子分解的困难性,而大整数因子分解问题是数学上的著名难题,至今没有有效的方法予以解决.目前三种攻击RSA算法的可能的方法旧1:(1)强行攻击:这包含对所有的私有密钥都进行尝试,即遍历法进行搜索;(2)数学攻击:有几种方法,实际上都等效于对两个素数乘积的因子分解;(3)定时攻击:这依赖于解密算法的运行时间.
RSA的安全性依赖于大数分解,但是否等同于大数分解一直未能得到理论上的证明,因为没有证明破解 RSA就一定需要作大数分解。实际上,人们推测RSA的安全性依赖于大整数的因式分解问题,但谁也没有在数学上证明从c和e计算m需要对n进行因式分解。可以想象可能会有完全不同的方式去分析RSA。然而,如果这种方法能让密码解析员推导出d,则它也可以用作大整数因式分解的新方法。最难以令人置信的是,有些RSA变体已经被证明与因式分解同样困难。甚至从RSA加密的密文中恢复出某些特定的位也与解密整个消息同样困难。另外,对RSA的具体实现存在一些针对协议而不是针对基本算法的攻击方法。假设存在一种无须分解大数的算法,那它肯定可以修改成为大数分解算法。目前, RSA 的一些变种算法已被证明等价于大数分解。不管怎样,分解n是最显然的攻击方法。现在,人们已能分解多个十进制位的大素数。因此,模数n 必须选大一些,因具体适用情况而定。RSA公钥加密算法是第一个既能用于数据加密也能用于数字签名的算法。它易于理解和操作,也十分流行。算法的名字以发明者的姓氏首字母命名:Ron Rivest, Adi Shamir 和Leonard Adleman。虽然自1978年提出以来,RSA的安全性一直未能得到理论上的证明,但它经历了各种攻击,至今(20##年)未被完全攻破。随着越来越多的商业应用和标准化工作,RSA已经成为最具代表性的公钥加密技术。VISA、MasterCard、IBM、Microsoft等公司协力制定的安全电子交易标准(Secure Electronic Transactions,SET)就采用了标准RSA算法,这使得RSA在人们的生活中几乎无处不在。网上交易加密连接、网上银行身份验证、各种信用卡使用的数字证书、智能移动电话和存储卡的验证功能芯片等,大多数使用RSA技术。
RSA系统是第一个将安全性植基于因子分解的系统。很明显地,在公开密钥(e,N)中,若N能被因子分解,则在模N中所有元素价的最小公倍数(即所谓陷门)T=φ(N)=(p-1)(q-1)即无从隐藏。使得解密密钥d不再是秘密,进而整个RSA系统即不安全。虽然迄今人们尚无法“证明”,破解RSA系统等于因子分解。但一般“相信”RSA系统的安全性,等价于因子分解。即:若能分解因子N,即攻破RSA系统;
若能攻破RSA系统,即分解因子N(相信,但未证明)因此,在使用RSA系统时,对于公开密钥N的选择非常重要。必须使得公开N后,任何人无法从N得到T。此外,对于公开密钥e与解密密钥d,亦需有所限制。否则在使用上可能会导致RSA系统被攻破,或应用在密码协议上不安全。
? 经过分析,我们知道RSA系统安全性与系统的参数有很大关系,X.931标准对此提出以下几点:
? ?如果公钥e是奇数,e应与p-1,q-1互质;
? ?如果公钥e是偶数,e必须与(p-1)/2,(q-1)/2互质,且poq mod 8不成立;
? ?模数的长应该为1024+256x,x=0,1? ? ? ? ? ? ;
? ?质数p,q应通过质数检测,使出错的概率小于 ;
? ?p-1,q-1,p+1,q+1应有大质数因子;
? ?gcd(p-1,q-1)应该小;
? ?p/q不应靠近两个小整数比值,且 ;
? ?|p-q|应有大质数因子。
当今公钥加密更广泛应用于互联网身份认证,将公钥加密算法RSA进行蒙哥马利改进。通过对幂模运算的改进,简化,提高RSA加密效率。幂模运算是RSA的速度瓶颈,在全过程中都有使用。蒙哥马利算法是其中一种。影响模乘运算速度关键在于模运算,模运算其实是除法运算,除运算相对与加减乘运算要费时的多。因此,如果在模乘运算中不用除法或尽量少用除法将大大提高RSA处理的速度。1985年,Peter Montgomery发现了一种只要乘法和数的位移就可以实现模乘运算的灵巧算法,这就是著名的蒙哥马利模乘算法。
四.实验总结
通过本次课程设计,我对密码学原理有了更深入的理解,特别是通过编程实现各种密码算法,对DES和RSA密码算法以及各种古典密码体制的理解更加深刻,由于本课程在我们学习了密码学之后对于原理的掌握并不难,不过要通过高级程序来实现加解密过程就比较难点。在编程的过程中遇到了很多问题,通过反复地分析与调试,将它们一一解决,锻炼了自己的分析问题和解决问题的能力。同时,通过实际编写密码分析程序,也极大地激发了我对密码学的兴趣,希望在以后的学习中不断地积累和丰富密码学的相关理论与技术。