武汉轻工大学
数学与计算机学院
《XML》
实验报告
专 业: 信息管理与信息系统
班 级: 1202班
学 号: 1205020204
姓 名: 黄鑫
指导老师: 林菁
2014年12月10日
实验四 层叠样式表CSS
一、实验目的
(1)了解并掌握CSS的基本语法及创作步骤
(2)了解并掌握XML文档中使用CSS的引入式方法
(3)了解并掌握XML文档中使用CSS的嵌入式方法
二、实验条件
包配置有windows记事本、写字板 或 XMLSpy开发环境的计算机设备。
三、实验原理及相关知识
CSS的基本语法以及在XML文档中引用CSS的方法。
四、实验内容
对以下XML进行CSS定义:
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<?xml-stylesheet type="text/css" href="person-comm.css"?>
<personslist>
<person>
<name>李 明</name>
<age>20</age>
<address>
<province>湖北省</province>
<city>武汉市</city>
<street>常青花园一路</street>
</address>
<tele>83969020</tele>
<e-mail>123@sina.com</e-mail>
</person>
<person>
<name>林 琳</name>
<age>21</age>
<address>
<province>湖北省</province>
<city>武汉市</city>
<street>金银湖马池路</street>
</address>
<tele>88888888</tele>
<e-mail>54310858@qq.com</e-mail>
</person>
</personslist>
利用CSS属性和相关使用规则,根据以上XML文件编写一个CSS文件,使其转换成一个HTML文件。该HTML文件通过浏览器打开的显示效果如图所示:

其CSS文件如下图:

五、思考题及其它
(1)CSS的基本作用是什么?
CSS(Cascading Style Sheet,可译为“层叠样式表”或“级联样式表”)是一组格式设置规则,用于控制Web页面的外观。通过使用CSS样式设置页面的格式,可将页面的内容与表现形式分离。页面内容存放在HTML文档中,而用于定义表现形式的CSS规则则存放在另一个文件中或HTML文档的某一部分,通常为文件头部分。将内容与表现形式分离,不仅可使维护站点的外观更加容易,而且还可以使HTML文档代码更加简练,缩短浏览器的加载时间。
(2)CSS中元素显示定义之间有嵌套关系吗?
实验五 可扩展样式单语言XSL
一、实验目的
掌握使用XSL显示XML文件的基本方法
二、实验条件
配置有windows记事本、写字板 或 XMLSpy 开发环境的计算机设备。
三、实验原理及相关知识
(1)XSL实际包含三方面的内容:XSLT,XPath以及XSL格式化对象
(2)XSLT中模板的定义
(3)XPath对XML文件片段进行查找、定位
(4)格式化对象将XSL转换结果进行显示
四、实验内容及步骤
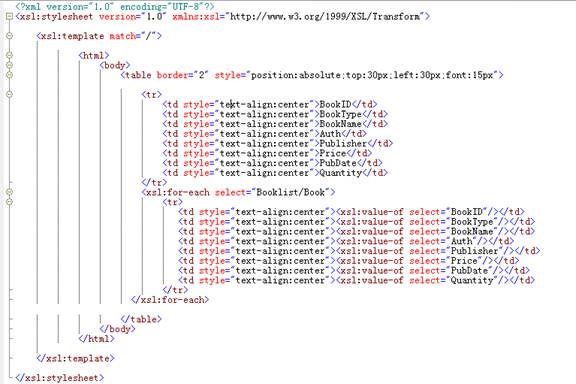
1、对以下“booklist.xml”进行XSL定义(设XSL文件名为“booklist.xsl”)
<?xml version="1.0" encoding="GB2312"?>
<Booklist>
<Book>
<BookID>000001</BookID>
<BookType>计算机</BookType>
<BookName>算法与数据结构</BookName>
<Auth>严蔚敏 陈文博</Auth>
<Publisher>清华大学出版社</Publisher>
<Price>24</Price>
<PubDate>20##-1-1</PubDate>
<Quantity>10</Quantity>
</Book>
<Book>
<BookID>000002</BookID>
<BookType>计算机</BookType>
<BookName>软件工程导轮</BookName>
<Auth>张海藩</Auth>
<Publisher>清华大学出版社</Publisher>
<Price>5.4</Price>
<PubDate>1987-6-1</PubDate>
<Quantity>5</Quantity>
</Book>
<Book>
<BookID>000003</BookID>
<BookType>计算机</BookType>
<BookName>XML/JSP网页编程教材</BookName>
<Auth>吴艾</Auth>
<Publisher>北京希望电子出版社</Publisher>
<Price>46</Price>
<PubDate>20##-7-1</PubDate>
<Quantity>15</Quantity>
</Book>
<Book>
<BookID>000012</BookID>
<BookType>工具</BookType>
<BookName>汉语成语字典</BookName>
<Auth>李一华 吕德申</Auth>
<Publisher>四川辞书出版社</Publisher>
<Price>12</Price>
<PubDate>1992-1-1</PubDate>
<Quantity>10</Quantity>
</Book>
<Book>
<BookID>000016</BookID>
<BookType>机械</BookType>
<BookName>机电控制工程</BookName>
<Auth>高钟毓 王永梁</Auth>
<Publisher>清华大学出版社</Publisher>
<Price>19.8</Price>
<PubDate>1994-9-1</PubDate>
<Quantity>19</Quantity>
</Book>
<Book>
<BookID>000018</BookID>
<BookType>工具</BookType>
<BookName>英华大字典</BookName>
<Auth>郑易里</Auth>
<Publisher>商务印书馆</Publisher>
<Price>18.5</Price>
<PubDate>1984-11-1</PubDate>
<Quantity>2</Quantity>
</Book>
</Booklist>
(1)书写XSL定义头部
<?xml version="1.0" encoding="GB2312"?>
(3)编写根节点匹配模板(注意xsl:stylesheet元素是必须要的)
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<table border="2" style="position:absolute;top:30px;left:30px;font:15px">
<tr>
<td style="text-align:center">BookID</td>
<td style="text-align:center">BookType</td>
<td style="text-align:center">BookName</td>
<td style="text-align:center">Auth</td>
<td style="text-align:center">Publisher</td>
<td style="text-align:center">Price</td>
<td style="text-align:center">PubDate</td>
<td style="text-align:center">Quantity</td>
</tr>
[…………]
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
如下图:
(4)编写XPath节点booklist/book的匹配模板(添加在[…………]处)
<xsl:for-each select="Booklist/Book">
<tr>
<td style="text-align:center"><xsl:value-of select="BookID"/></td>
<td style="text-align:center"><xsl:value-of select="BookType"/></td>
<td style="text-align:center"><xsl:value-of select="BookName"/></td>
<td style="text-align:center"><xsl:value-of select="Auth"/></td>
<td style="text-align:center"><xsl:value-of select="Publisher"/></td>
<td style="text-align:center"><xsl:value-of select="Price"/></td>
<td style="text-align:center"><xsl:value-of select="PubDate"/></td>
<td style="text-align:center"><xsl:value-of select="Quantity"/></td>
</tr>
</xsl:for-each>
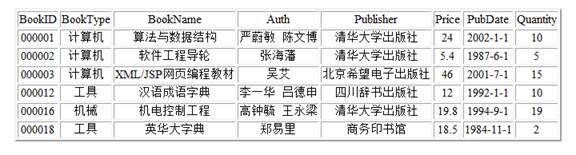
(5)在IE中打开带有XSL定义的“booklist.xml”,观察文件显示结果(带XSL定义的XML文件头部如下所示)。
<?xml version="1.0" encoding="GB2312"?>
<?xml-stylesheet type="text/xsl" href="booklist.xsl"?>
(6)修改上述代码,不用<xsl:for-each>语句实现相同的显示结果。
(7)根据“booklist.xml”,编写“bookinfoquery.xsl”,要求能够以表格方式输出BookName的值是以“算法”开头的图书的所有信息。
提示:判断BookName元素的值是否以算法开头可以用starts-with函数,如下:starts-with(BookName,'算法')
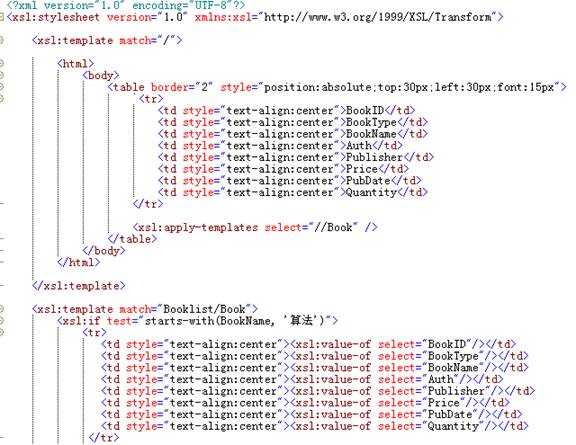

2、教材P121习题7.
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:fo="http://www.w3.org/1999/XSL/Format">
<xsl:template match="/">
<html>
<body><center>
<h2>个人简历</h2>
<table border="2">
<tr>
<th colspan="2">求职目标</th>
<th colspan="7">个人信息</th>
<th colspan="2">特长</th>
</tr>
<tr>
<th>职位</th>
<th>公司</th>
<th>姓名</th>
<th>性别</th>
<th>年龄</th>
<th>专业</th>
<th>毕业学校</th>
<th>学历</th>
<th>电话</th>
<th>变成语言</th>
<th>英语等级</th>
</tr>
<tr>
<xsl:for-each select="//求职目标">
<td><xsl:value-of select="职位"/></td>
<td><xsl:value-of select="公司"/></td>
</xsl:for-each>
<xsl:for-each select="//个人信息">
<td><xsl:value-of select="姓名"/></td>
<td><xsl:value-of select="性别"/></td>
<td><xsl:value-of select="年龄"/></td>
<td><xsl:value-of select="专业"/></td>
<td><xsl:value-of select="毕业学校"/></td>
<td><xsl:value-of select="学历"/></td>
<td><xsl:value-of select="电话"/></td>
</xsl:for-each>
<xsl:for-each select="//特长">
<td><xsl:value-of select="编程语言"/></td>
<td><xsl:value-of select="英语等级"/></td>
</xsl:for-each>
</tr>
</table></center>
</body>
</html>
</xsl:template>
</xsl:stylesheet>

五、思考题及其它
针对“booklist.xsl”,简述XSLT的执行过程。
第二篇:信号与系统实验四实验报告
实验四 时域抽样与频域抽样
一、实验目的
加深理解连续时间信号的离散化过程中的数学概念和物理概念,掌握时域抽样定理的基本内容。掌握由抽样序列重建原连续信号的基本原理与实现方法,理解其工程概念。加深理解频谱离散化过程中的数学概念和物理概念,掌握频域抽样定理的基本内容。
二、实验原理
时域抽样定理给出了连续信号抽样过程中信号不失真的约束条件:对于基带信号,信号抽样频率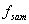 大于等于2倍的信号最高频率
大于等于2倍的信号最高频率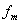 ,即
,即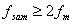 。
。
时域抽样是把连续信号x(t)变成适于数字系统处理的离散信号x[k] ;信号重建是将离散信号x[k]转换为连续时间信号x(t)。
非周期离散信号的频谱是连续的周期谱。计算机在分析离散信号的频谱时,必须将其连续频谱离散化。频域抽样定理给出了连续频谱抽样过程中信号不失真的约束条件。
三.实验内容
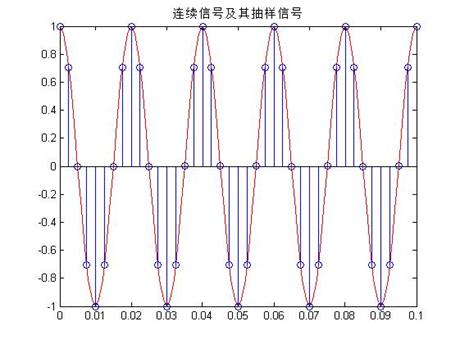
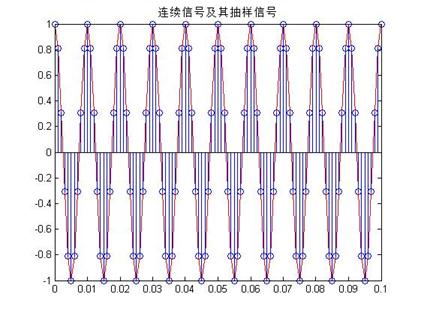
1. 为了观察连续信号时域抽样时抽样频率对抽样过程的影响,在[0,0.1]区间上以50Hz的抽样频率对下列3个信号分别进行抽样,试画出抽样后序列的波形,并分析产生不同波形的原因,提出改进措施。
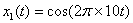
答: 函数代码为:
t0 = 0:0.001:0.1;
x0 =cos(2*pi*10*t0);
plot(t0,x0,'r')
hold on
Fs =50;
t=0:1/Fs:0.1;
x=cos(2*pi*10*t);
stem(t,x);
hold off
title('连续信号及其抽样信号')
函数图像为:
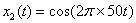
同理,函数图像为: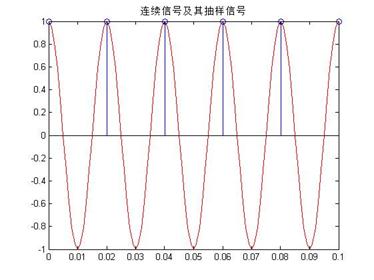
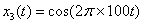
同理,函数图像为:
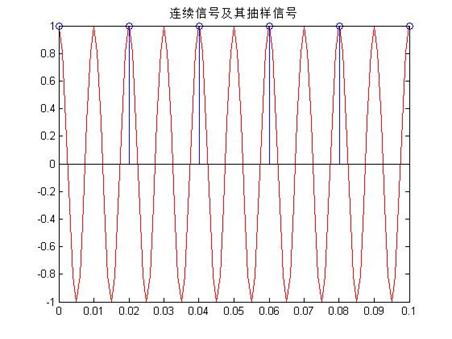
由以上的三图可知,第一个图的离散序列,基本可以显示出原来信号,可以通过低通滤波恢复,因为信号的频率为20HZ,而采样频率为50>2*20,故可以恢复,但是第二个和第三个信号的评论分别为50和100HZ,因此理论上是不能够恢复的,需要增大采样频率,
解决的方案为,第二个信号的采样频率改为400HZ,而第三个的采样频率改为1000HZ,这样可以很好的采样,如下图所示:
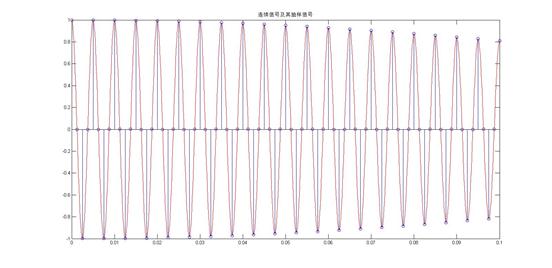
2. 产生幅度调制信号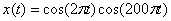 ,推导其频率特性,确定抽样频率,并绘制波形。
,推导其频率特性,确定抽样频率,并绘制波形。
此信号的最高频率为202HZ,因此我们将采样频率设置为800,具体的函数代码如下:
t0 = 0:0.0001:0.1;
x0 =cos(2*pi*200.*t0).*cos(2*pi.*t0);
plot(t0,x0,'r')
hold on
Fs = 800;
t=0:1/Fs:0.1;
x =cos(2*pi*200.*t).*cos(2*pi.*t);
stem(t,x);
hold off
title('连续信号及其抽样信号')
3. 对连续信号 进行抽样以得到离散序列,并进行重建。
进行抽样以得到离散序列,并进行重建。
(1) 生成信号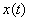 ,时间t=0:0.001:4,画出的波形。
,时间t=0:0.001:4,画出的波形。
生成信号的代码和截图如下:
t0 = 0:0.001:1;
x0 =cos(2*pi*2*t0);
plot(t0,x0,'r')
hold on
Fs = 10;
t=0:1/Fs:1;
x=cos(2*pi*2*t);
stem(t,x);
hold off
title('连续信号及其抽样信号')
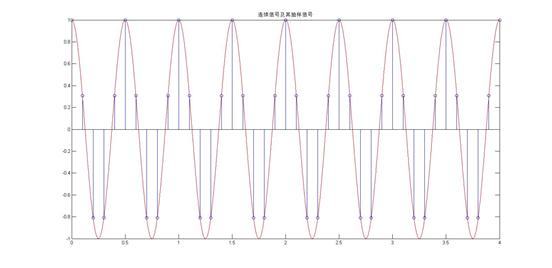
(2) 以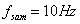 对信号进行抽样,画出在
对信号进行抽样,画出在 范围内的抽样序列x[k];利用抽样内插函数
范围内的抽样序列x[k];利用抽样内插函数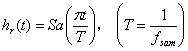 恢复连续时间信号,画出重建信号
恢复连续时间信号,画出重建信号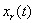 的波形。与是否相同,为什么?
的波形。与是否相同,为什么?
答,抽样以及恢复的函数代码和截图为:
t0 = 0:0.001:1;
x0 =cos(2*pi*2*t0);
plot(t0,x0,'r')
hold on
Fs = 10;
t=0:1/Fs:1;
x=cos(2*pi*2*t);
stem(t,x);
hold on
t1=0:0.01:1;
h=sin(pi*t1*0.1)/(0.1*pi*t1);
y=conv(x,h);
plot(t,y,'g');
hold off
title('连续信号及其抽样信号及其抽样信号')
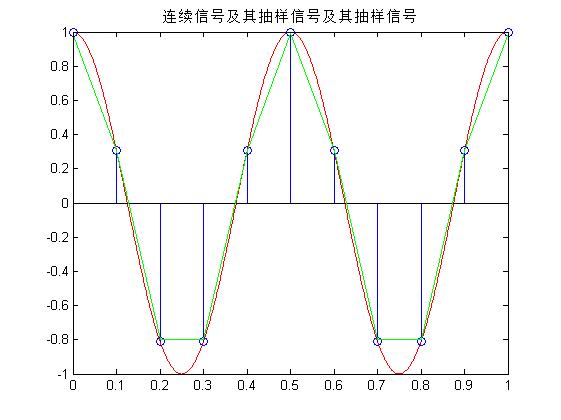
(3) 将抽样频率改为 ,重做(2)。
,重做(2)。
抽样以及恢复的函数代码和截图为:
t0 = 0:0.001:1;
x0 =cos(2*pi*2*t0);
plot(t0,x0,'r')
hold on
Fs = 3;
t=0:1/Fs:1;
x=cos(2*pi*2*t);
stem(t,x);
hold on
t1=0:0.01:1;
h=sin(pi*t1*0.1)/(0.1*pi*t1);
y=conv(x,h);
plot(t,y,'g');
hold off
title('连续信号及其抽样信号及其抽样信号')
与很明显不相同相同,因为用sa函数来恢复信号,本来就不是理想低通滤波恢复,而是将取得的点用直线连接起来,因此肯定有偏差,当Fs>4HZ时,就比如第一个图,恢复出来的信号还有原来信号的形状,失真不是很大,但是当Fs=3HZ时,失真就很明显了。
4. 已知序列x[k]={1,3,2,-5;k=0, 1, 2, 3}, 分别取N=2,3,4,5对其频谱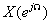 进行抽样,再由频率抽样点恢复时域序列,观察时域序列是否存在混叠,有何规律?
进行抽样,再由频率抽样点恢复时域序列,观察时域序列是否存在混叠,有何规律?
答:抽样和时域恢复的函数代码和截图(分别取N=2,3,4,5时)如下:
其中蓝线是频域的频谱图,红色冲击串是抽样信号图抽样信号,绿色的序列式恢复出来的信号:
x=[1,3,2,-5]; L=3; N=256;
omega=[0:N-1]*2*pi/N;
X0=1+3*exp(-j*omega)+2*exp(-2*j*omega)-5*exp(-3*j*omega);
plot(omega./pi,abs(X0));
xlabel('Omega/PI');
hold on
N=6;
omegam=[0:N-1]*2*pi/N;
Xk=1+3*exp(-j*omegam)+2*exp(-2*j*omegam)-5*exp(-3*j*omegam);
stem(omegam./pi,abs(Xk),'r','o');
hold on
x1=ifft(Xk);
stem(0:length(x1)-1,x1,'g');
hold off
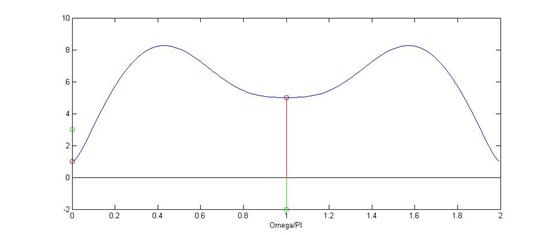
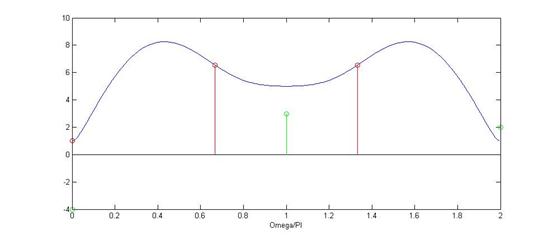
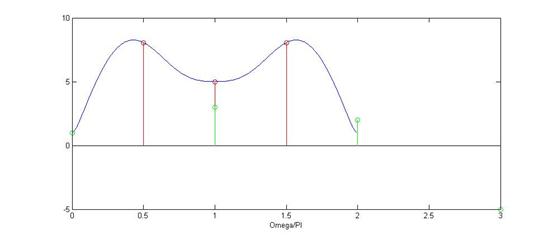
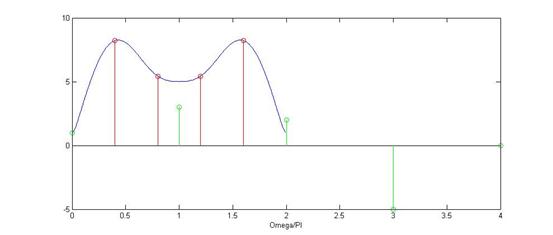
由上面的截图可知,当N<4时,会出现频谱混叠,以至于恢复出来的序列与原来的序列不同,而当N>=4时,恢复出来的信号序列就与原来的序列完全相同。
四. 实验思考题
1. 将语音信号转换为数字信号时,抽样频率一般应是多少?
答:因为人的声音频率为300HZ—3400HZ,根据来奎斯特采样定理可知,采样频率必须要大于等于2倍3400HZ,所以抽样频率一般采用8KHZ
2在时域抽样过程中,会出现哪些误差?如何克服或改善?
f 选取不当或低通滤波器的截止特性不够陡直,都会引起误差,克服误差的方法是,采取频率较高的抽样频率,和选取适当的低通滤波器。
3在实际应用中,为何一般选取抽样频率³(3~5)?
因为实际应用中,不存在理想的低通滤波器,事实上,我们的滤波器的上升沿和下降沿不可能这么陡峭,会有一定的平缓多度区,而这个过渡区就等效于我们的低通滤波器的带宽减少了,实际上我们用的最好的滤波器也只能是梯形的,实际运用中还会出现很多偏差,而增大采样频率很明显很高减少误差,同时奈科斯特定理要求的是理想情况下要大于2fm,而太大的采样频率会要求更多的空间来存储,不经济,因而³(3~5)经济合理。
4简述带通信号抽样和欠抽样的原理?
一个连续带通信号受限于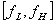 ,其信号带宽为
,其信号带宽为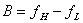 ,且有
,且有
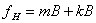 (1)
(1)
其中,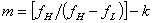 ,
,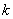 为不超过
为不超过 的最大正整数,由此可知,必有
的最大正整数,由此可知,必有 。
。
则最低不失真取样频率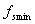 为
为
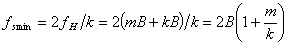
当抽样频率大于fsmin时,抽样不失真,当抽样频率小于fsmin时样值序列的频谱各个谱块重叠产生失真。