实验报告
实验课程 应用回归分析 第 7 次实验 实验日期2012.12.6 指导教师 王振羽
班级 10统计 学号 1007402068 姓名 刘晓静 成绩
一、实验目的
掌握SPSS中找出并消除数据共线性方法.
掌握SPSS中的岭回归分析方法.
二、实验内容
1.在训练中氧气消耗能力问题的研究中,我们想要建立一个关系式,以便根据训练测试的数据来预报肺活量,而不必进行昂贵和笨重的氧气消耗测试。考察的因变量y为OXY(氧气消耗能力),自变量有x1(age,年龄)、x2(weight,体重)、x3(RunTime,1.5英里跑的时间)、x4(RstPulse, 休息时脉博)、x5(RunPulse,跑步时脉博)、x6(RunPulse, 跑步时最大脉博)。(数据在“回归人大数据12_学生.xls的第2题”中 ),利用统计软件计算
(1) 用方差扩大因子法分析数据的多重共线性;
(2) 用特征根法分析数据的多重共线性;
(3) 本题是否适用剔除变量的方法消除共线性,如果适用,进行变量剔除(要求写出回归方程,及主要的统计量);
(4) 对此问题作岭回归分析(写明你所用的确定k的原则);注: 要求写出回归方程,及主要的统计量。
三、实验结果与分析(包括运行结果及其数据分析、解释等)
(1) 用方差扩大因子法分析数据的多重共线性;
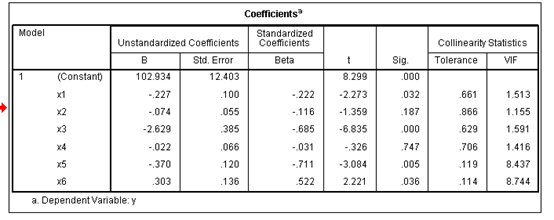
由上表可以看出,所有变量的方差扩大因子都不大,都小于10,由此可以看出该回归方程的多重共线性不严重,从方差扩大因子的平均数来度量多重共线性,方差扩大因子的平均数为=3.8并没有远远大于1。
综上可得出结论,用方差扩大因子法诊断该回归方程,并不存在多重共线性。
(2) 用特征根法分析数据的多重共线性;

从条件数看到,最大的条件数k7=196.786,说明自变量间存在严重的多重共线性,从表中第七行x5、x6的系数分别为0.91、0.98,说明x5、x6存在较强的多重共线性。
(3) 本题是否适用剔除变量的方法消除共线性,如果适用,进行变量剔除(要求写出回归方程,及主要的统计量);
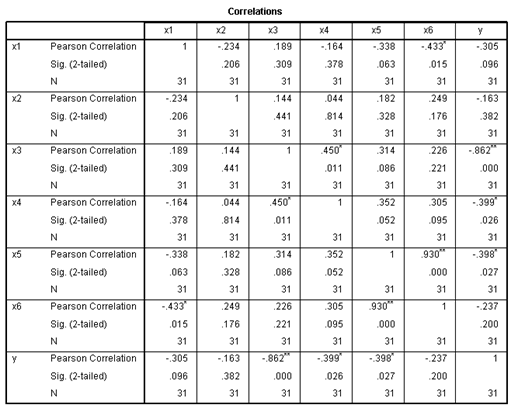
从上题特征值判定法中可以知道,x5、x6存在较强的多重共线性;从上表系数矩阵中可以看出,x5、x6的相关系数为0.93,即两个变量之间的相关性很大,其中x5为跑步时的脉搏,x6为跑步时的最大脉搏,其中跑步时的脉搏包含了x6跑步时的最大脉搏,即两个变量可去其一。
然而根据第一题中的方差扩大因子,可知所有变量的方差扩大因子都小于10,由此可知,该题不适用剔除变量的方法消除共线性。
若要用剔除变量的方法消除共线性。
可根据第一小题中的方差扩大因子,可得出x6的VIF最大=8.744,由此可知,剔出x6之后可得:
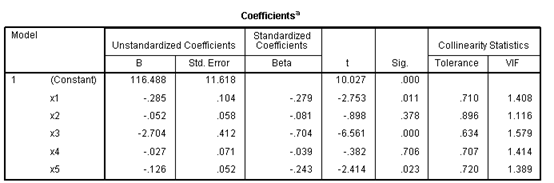
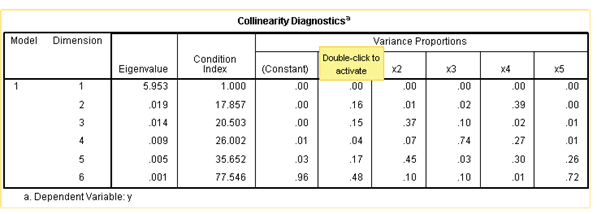
从第一张表中可以看出,所有变量的方差扩大因子都小于10,但变量x2、x4的显著性不高,p值分别是0.378、0.706都比0.05和0.1大。但从方差扩大因子法判断可知,该回归方程没有多重共线性,又从条件数可以得知,k6=77.546,位于10与100之间,说明存在较强的多重共线性。
但是在剔出一些不重要变量的方法中是根据方差扩大因子剔除变量的,然而,所有变量的VIF都很小,因此可得,该回归方程不适合用剔除变量的方法来消除多重共线性。
(4) 对此问题作岭回归分析(写明你所用的确定k的原则);注: 要求写出回归方程,及主要的统计量。

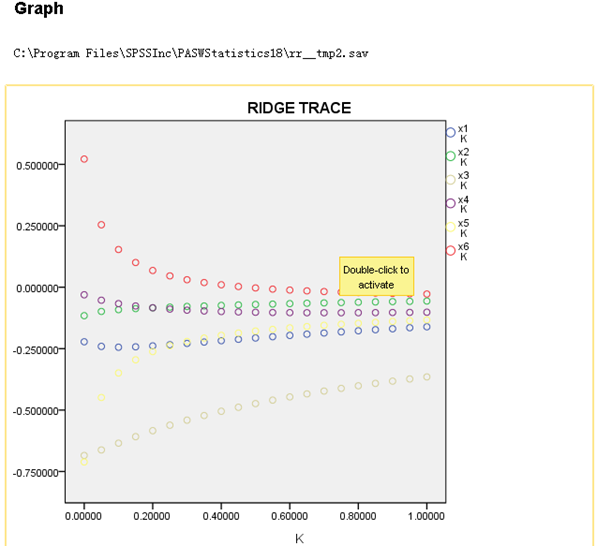
从表一中第一列为参数k,从表中数据可以得出:x6的岭回归系数在k很小时绝对值很大,且随着k的增大,绝对值趋于0,有数据可得,当k=0.5之时,x6的岭回归系数甚至改变符号变为负值,而x5的岭回归系数在k值很小时绝对值很大,但它的实际符号是负号,且随着k的变大,x5的岭回归系数趋于0,由岭迹可知,x5和x6的岭回归系数的和很稳定,且由相关系数表可知,x5和x6的相关系数为0.93,相关性很大,由此可知,两变量可合并成一个。
下面我们删除变量x6,把岭参数步长改为0.02,范围缩小到0.2,如下:
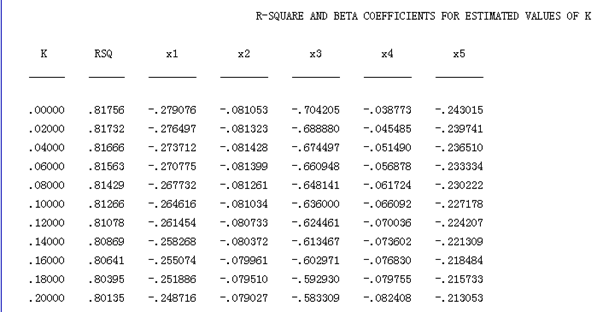

由岭参数和岭迹图可以看出,此时的各变量的岭参数基本稳定,我们选取k=0.1,此时决定系数=0.81,依然比较大,因此重新作岭回归有:

此时由上表数据可知,修正后复决定系数=0.81,对回归方程的拟合程度检验的F值为=21.69,P值=0.00000002,显著性高。
由此可得回归方程为:
未标准化岭回归方程:
标准化岭回归方程:
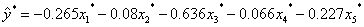
第二篇:实用回归分析实验报告[1]
东 北 大 学 秦 皇 岛 分 校 数 学 与 统 计 学 院
实 验 报 告

一、实验目的:
1. 建立一元线性回归模型;
2. 对模型估计结果进行检验;
3. 利用模型进行预测分析.
二、实验内容(习题): P63 习题3.9 (9)小题不做
解:将数据录入spss可得到下面三个表:

表1
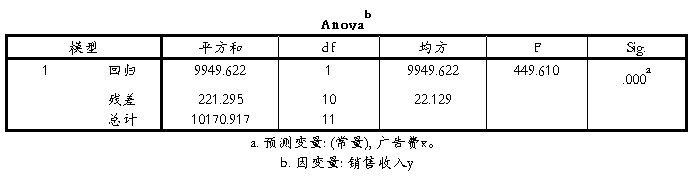
表2

表3
(1)画出散点图;

(2)y与x大致呈线性关系吗?
从散点图可以看出样本数据点大致都分别落在一条直线附近,说明变量x与y之间有明显的线性关系。
(3)用最小二乘法估计出回归模型;
 i=1,2,3...... 其中:
i=1,2,3...... 其中: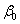 ,
,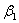 是任意实数。
是任意实数。
 ,
,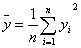
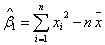
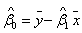
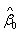 ,
,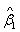 为,的最小二乘估计。从表3可以得出
为,的最小二乘估计。从表3可以得出 为9.508,为9.747,于是回归模型为:
为9.508,为9.747,于是回归模型为:
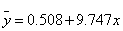
(4)求回归标准差 ;
;
由公式
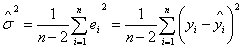
可以计算出回归标准差。从表1可以看出回归标准差为4.704。
(5)给出与的置信水平为95%的区间估计;
从表3可以看出的置信水平为95%的区间估计为(2.696,16.319),的置信水平为95%的区间估计为(8.723,10.771)。
(6)计算x与y的决定系数;
x与y的决定系数:
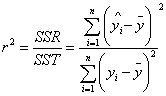
从表1可以看出决定系数为0.978。
(7)对方程作方差分析;
从ANOVA方差分析表中看出,F=449.610,显著性sig约为0.000,说明y对x的线性回归高度显著, 这与相关系数的检验结果是一致的。
(8)作回归系数的显著性检验;
原假设H0: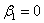 ,对立假设H1:
,对立假设H1: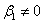 。
。
构造t统计量:
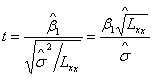 ,
,
t统计量遵从自由度为n-2的t 分布。给定显著性水平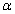 ,双侧检验的临界值为
,双侧检验的临界值为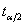 。当
。当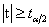 时拒绝 原假设H0:,认为显著不为零,因变量y对自变量x的一元线性回归成立;当
时拒绝 原假设H0:,认为显著不为零,因变量y对自变量x的一元线性回归成立;当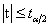 时不 拒绝原假设H0:,认为显著为零,因变量y对自变量x的一元线性回归不成立。
时不 拒绝原假设H0:,认为显著为零,因变量y对自变量x的一元线性回归不成立。
从表3看出回归系数检验的t值=21.204,显著性约为零,与F检验和相关系数r的检验结果一致。
(10)当广告费用为4.2万元时,销售收入将达到多少?并给出置信区间95%的置信区间。
为了给出心智y0的置信区间,需要先求出 估计值的分布。
估计值的分布。
通过计算可以得到其分布为: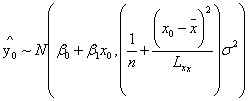 .
.
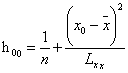
为新值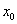 的杠杆值,则上式简记为
的杠杆值,则上式简记为
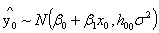 .
.
进而可知统计量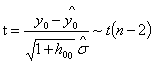 ,可得
,可得
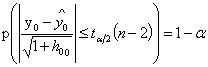
当样本容量n较大,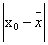 较小时,
较小时,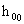 接近零,
接近零,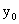 的置信区间为95%的置信区间近似为
的置信区间为95%的置信区间近似为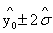 。
。
用spss算出点估计值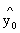 以及置信区间为95%的置信区间为:
以及置信区间为95%的置信区间为:
点估计值:50.45(亿元)
单个新值:(39.39,61.50)