洛阳理工学院
课 程 设 计 说 明 书
课程名称 _________数据结构_______________
设计课题 ________哈夫曼编/译码器 _________
专 业 ______计算机科学与技术 _________
班 级 ________B12xxxx _____________
学 号 _______B12xxxxxxx________________
姓 名 ____ xxx ______________
完成日期 20##年6月14日

【问题描述】
打开一篇英文文章,统计该文章中每个字符出现的次数,然后以它们作为权值,设计一个哈夫曼编/译码系统。利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。这要求在发送端通过一个编码系统对待传输数据预先编码,在接收端将传来的数据进行译码(复原)。对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。试为这样的信息收发站编写一个哈夫曼码的编/译码系统。
【基本要求】
以每个字符出现的次数为权值,建立哈夫曼树,求出哈夫曼编码,对文件yuanwen中的正文进行编码,将结果存到文件yiwen中,再对文件yiwen中的代码进行译码,结果存到textfile中。一个完整的系统应具有以下功能:
(1) I:初始化(Initialization)。从终端读入字符集大小n,以及n个字符和n个权值,建立哈夫曼树,并将它存于文件hfmTree中。
(2) E:编码(Encoding)。利用已建好的哈夫曼树(如不在内存,则从文件hfmTree中读入),对文件ToBeTran中的正文进行编码,然后将结果存入文件CodeFile中。
(3) D:译码(Decoding)。利用已建好的哈夫曼树将文件CodeFile中的代码进行译码,结果存入文件Textfile中。
【测试数据】
用下表给出的字符集和频度的实际统计数据建立哈夫曼树,并实现以下英文的编码和译码:“I like playing football”。

【算法思想】
哈夫曼编\译码器的主要功能是先建立哈夫曼树,然后利用建好的哈夫曼树生成哈夫曼编码后进行译码 。
在数据通信中,经常需要将传送的文字转换成由二进制字符0、1组成的二进制串,称之为编码。构造一棵哈夫曼树,规定哈夫曼树中的左分之代表0,右分支代表1,则从根节点到每个叶子节点所经过的路径分支组成的0和1的序列便为该节点对应字符的编码,称之为哈夫曼编码。
最简单的二进制编码方式是等长编码。若采用不等长编码,让出现频率高的字符具有较短的编码,让出现频率低的字符具有较长的编码,这样可能缩短传送电文的总长度。哈夫曼树课用于构造使电文的编码总长最短的编码方案。
(1) 其主要流程图如图1-1所示。
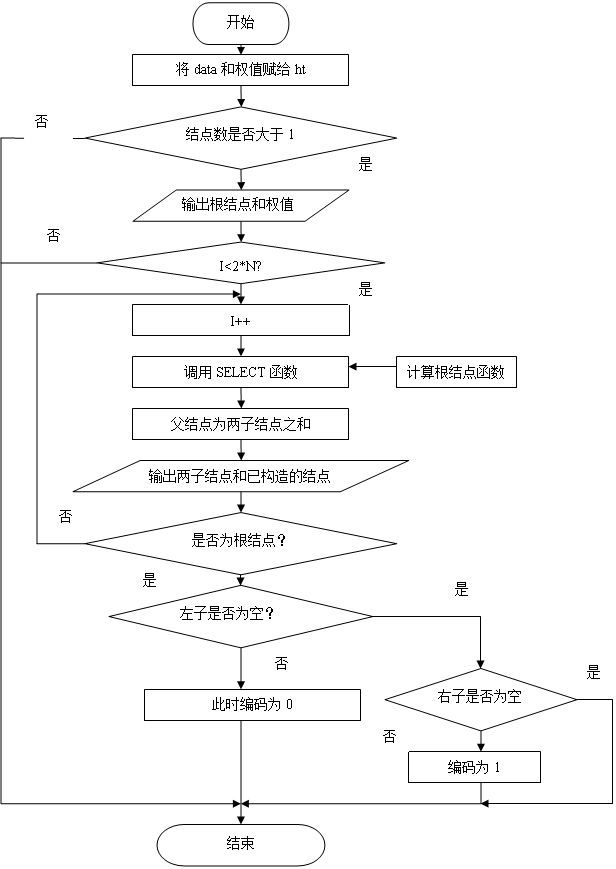
(2)设计包含的几个方面:① 赫夫曼树的建立
哈夫曼树的建立由赫夫曼算法的定义可知,初始森林中共有n棵只含有根结点的二叉树。算法的第二步是:将当前森林中的两棵根结点权值最小的二叉树,合并成一棵新的二叉树;每合并一次,森林中就减少一棵树,产生一个新结点。显然要进行n-1次合并,所以共产生n-1个新结点,它们都是具有两个孩子的分支结点。由此可知,最终求得的哈夫曼树中一共有2n-1个结点,其中n个结点是初始森林的n个孤立结点。并且赫夫曼树中没有度数为1的分支结点。我们可以利用一个大小为2n--1的一维数组来存储赫夫曼树中的结点。
② 哈夫曼编码
要求电文的哈夫曼编码,必须先定义哈夫曼编码类型,根据设计要求和实际需要定义的类型如下:
typedet struct {
char ch; // 存放编码的字符
char bits[N+1]; // 存放编码位串
int len; // 编码的长度
}CodeNode; // 编码结构体类型
③ 代码文件的译码
译码的基本思想是:读文件中编码,并与原先生成的哈夫曼编码表比较,遇到相等时,即取出其对应的字符存入一个新串中。
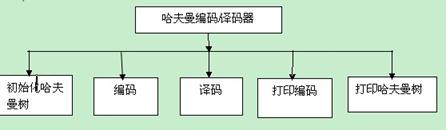
【模块划分】
1) 问题分析哈夫曼树的定义
1.哈夫曼树节点的数据类型定义为:
typedef struct{ //哈夫曼树的结构体
char ch;
int weight; //权值
int parent,lchild,rchild;
}htnode,*hfmtree;
2)所实现的功能函数如下
1、void hfmcoding(hfmtree &HT,hfmcode &HC,int n)初始化哈夫曼树,处理InputHuffman(Huffman Hfm)函数得到的数据,按照哈夫曼规则建立2叉树。此函数块调用了Select()函数。
2、void Select(hfmtree &HT,int a,int *p1,int *p2) //Select函数,选出HT树到a为止,权值最小且parent为0的2个节点
3、Encoding
编码功能:对输入字符进行编码
4、Decoding
译码功能: 利用已建好的哈夫曼树将文件codefile.txt中的代码进行译码,结果存入文件textfile.dat 中。
5.主函数的简要说明,主函数主要设计的是一个分支语句,让用户挑选所实现的功能。
使用链树存储,然后分别调用统计频数函数,排序函数,建立哈夫曼函数,编码函数,译码函数来实现功能。
3)系统功能模块图:
【数据结构】
(1)①哈夫曼树的存储结构描述为:
#define N 50 // 叶子结点数
#define M 2*N-1 // 哈夫曼树中结点总数
typedef struct {
int weight; // 叶子结点的权值
int lchild, rchild, parent; // 左右孩子及双亲指针
}HTNode; // 树中结点类型
typedef HTNode HuffmanTree[M+1];
②哈夫曼树的算法
void CreateHT(HTNode ht[],int n) //调用输入的数组ht[],和节点数n
{
int i,k,lnode,rnode;
int min1,min2;
for (i=0;i<2*n-1;i++)
ht[i].parent=ht[i].lchild=ht[i].rchild=-1; //所有结点的相关域置初值-1
for (i=n;i<2*n-1;i++) //构造哈夫曼树
{
min1=min2=32767; //int的范围是-32768—32767
lnode=rnode=-1; //lnode和rnode记录最小权值的两个结点位置
for (k=0;k<=i-1;k++)
{
if (ht[k].parent==-1) //只在尚未构造二叉树的结点中查找
{
if (ht[k].weight<min1) //若权值小于最小的左节点的权值
{
min2=min1;rnode=lnode;
min1=ht[k].weight;lnode=k;
}
else if (ht[k].weight<min2)
{
min2=ht[k].weight;rnode=k;
}
}
}
ht[lnode].parent=i;ht[rnode].parent=i; //两个最小节点的父节点是i
ht[i].weight=ht[lnode].weight+ht[rnode].weight; //两个最小节点的父节点权值为两个最小节点权值之和
ht[i].lchild=lnode;ht[i].rchild=rnode; //父节点的左节点和右节点
}
}
(2)哈夫曼编码
void CreateHCode(HTNode ht[],HCode hcd[],int n)
{
int i,f,c;
HCode hc;
for (i=0;i<n;i++) //根据哈夫曼树求哈夫曼编码
{
hc.start=n;c=i;
f=ht[i].parent;
while (f!=-1) //循序直到树根结点结束循环
{
if (ht[f].lchild==c) //处理左孩子结点
hc.cd[hc.start--]='0';
else //处理右孩子结点
hc.cd[hc.start--]='1';
c=f;f=ht[f].parent;
}
hc.start++; //start指向哈夫曼编码hc.cd[]中最开始字符
hcd[i]=hc;
}
}
void DispHCode(HTNode ht[],HCode hcd[],int n) //输出哈夫曼编码的列表
{
int i,k;
printf(" 输出哈夫曼编码:\n");
for (i=0;i<n;i++) //输出data中的所有数据,即A-Z
{
printf(" %c:\t",ht[i].data);
for (k=hcd[i].start;k<=n;k++) //输出所有data中数据的编码
{
printf("%c",hcd[i].cd[k]);
}
printf("\n");
}
}
void editHCode(HTNode ht[],HCode hcd[],int n) //编码函数
{
char string[MAXSIZE];
int i,j,k;
scanf("%s",string); //把要进行编码的字符串存入string数组中
printf("\n输出编码结果:\n");
for (i=0;string[i]!='#';i++) //#为终止标志
{
for (j=0;j<n;j++)
{
if(string[i]==ht[j].data) //循环查找与输入字符相同的编号,相同的就输出这个字符的编码
{
for (k=hcd[j].start;k<=n;k++)
{
printf("%c",hcd[j].cd[k]);
}
break; //输出完成后跳出当前for循环
}
}
}
}
(3)哈夫曼译码
void deHCode(HTNode ht[],HCode hcd[],int n) //译码函数
{
char code[MAXSIZE];
int i,j,l,k,m,x;
scanf("%s",code); //把要进行译码的字符串存入code数组中
while(code[0]!='#')
for (i=0;i<n;i++)
{
m=0; //m为想同编码个数的计数器
for (k=hcd[i].start,j=0;k<=n;k++,j++) //j为记录所存储这个字符的编码个数
{
if(code[j]==hcd[i].cd[k]) //当有相同编码时m值加1
m++;
}
if(m==j) //当输入的字符串与所存储的编码字符串个数相等时则输出这个的data数据
{
printf("%c",ht[i].data);
for(x=0;code[x-1]!='#';x++) //把已经使用过的code数组里的字符串删除
{
code[x]=code[x+j];
}
}
}
}
【测试情况】
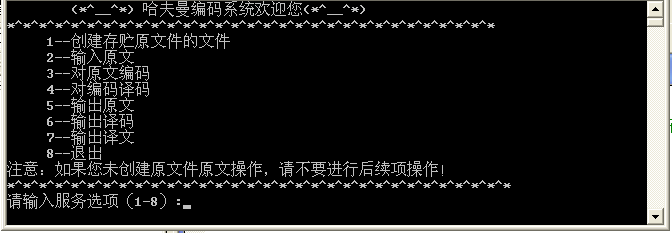
(1) 程序运行时,进入的主界面如图:
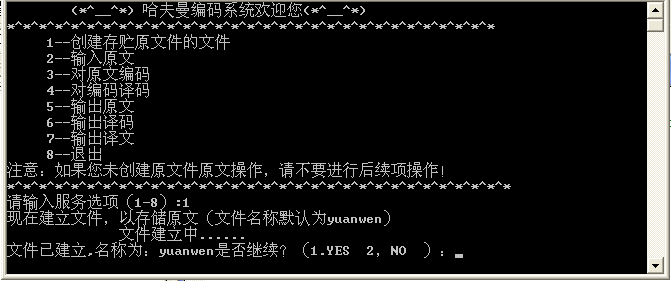
(2)选择1进入,创建名称为yuanwen的文件,如图:
(3)输入英语原文为 I like playing football ,如图所示:

(4)程序对原文进行编码运行输出结果,程序如图:

【心得】
在我自己课程设计中,就在编写好源代码后的调试中出现了不少的错误,遇到了很多麻烦及困难,我的调试及其中的错误和我最终找出错误,修改为正确的能够执行的程序中,通过分析,我学到了:
在定义头文件时可多不可少,即我们可多写些头文件,肯定不会出错,但是若没有定义所引用的相关头文件,必定调试不通过;
在执行译码操作时,不知什么原因,总是不能把要编译的二进制数与编译成的字符用连接号连接起来,而是按顺序直接放在一起,视觉效果不是很好。还有就是,很遗憾的是,我们的哈夫曼编码/译码器没有像老师要求的那样完成编一个文件的功能,这是我们设计的失败之处。
通过本次数据结构的课程设计,我学习了很多在上课没懂的知识,并对求哈夫曼树及哈夫曼编码/译码的算法有了更加深刻的了解,更巩固了课堂中学习有关于哈夫曼编码的知识
【源程序】
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define N 5000
#define m 128 //叶子结点个数,即字符总类数
#define M 2*m-1 //哈夫曼树的节点数
char CH[N]; //记录原文字符数组
char YW[N]; //记录译文字符数组
typedef char * Hcode[m+1]; //存放哈夫曼字符编码串的头指针的数组
typedef struct
{
char a;
int num;
}dangenode; //记录单个字符的类别和出现的次数
typedef struct
{
dangenode b[129];
int tag;
}jilunode; //统计原文出现的字符种类数
typedef struct node
{
int weight; //结点权值
int parent; //双亲下标
int Lchild; //左孩子结点的下标
int Rchild; //右孩子的下标
}htnode,hn[M];//静态三叉的哈夫曼树的定义
void jianliwenjian()
{
FILE *fp;
printf("现在建立文件,以存储原文(文件名称默认为yuanwen)\n");
printf(" 文件建立中......\n");
if((fp=fopen("yuanwen","wb"))==NULL) //建立文件
{
printf("Cannot open file\n");
exit(0);
}
printf("文件已建立,名称为:yuanwen");
fclose(fp); //关闭文件
}
void luruyuanwen() //原文输入完后,将其保存到文件yuanwen中
{
char ch;
FILE *fp;
if((fp=fopen("yuanwen","wb"))==NULL) //打开文件
{
printf("Cannot open file\n");
exit(0);
}
printf("请输入原文(结束标志为:^)\n");
do
{
ch=getchar();
fputc(ch,fp); //将字符保存到文件中
}while(ch!='^'); //判断结束
getchar(); //接收回车命令符
fclose(fp); //关闭文件
}
void min_2(hn ht,int n,int *tag1,int *tag2)//在建哈夫曼树的过程中,选择权值小的两
{ //个结点
int i,min,s;
min=N;
for(i=1;i<=n;i++)
if(ht[i].weight<min&&ht[i].parent==0)
{
min=ht[i].weight;
*tag1=i; //记录权值最小的结点下标
}
min=N;
for(i=1;i<=n;i++)
if(ht[i].weight<min&&ht[i].parent==0&&i!=*tag1)
{
min=ht[i].weight;
*tag2=i;
}
if(ht[*tag1].weight==ht[*tag2].weight&&ht[*tag2].Lchild!=0)
{
s=(*tag1); //如果结点权值相同,先出现的放在哈夫曼树的左边
(*tag1)=(*tag2);
(*tag2)=s;
}
}
void chuangjian(jilunode * jilu,hn ht) //建立哈夫曼树、以及对原
{
FILE *fp;//文字符的类别和数量统计
int i=-1,j,s=0,tag1,tag2;
// s=0;
// i=-1;
//char ch;
if((fp=fopen("yuanwen","rb"))==NULL) //以只读的方式打开文件
{
printf("Cannot open file\n");
exit(0);
}
while(!feof(fp)) //判断文件指示标志是否移动到了文件尾处
{
char ch;
ch=fgetc(fp);
if(ch!='^') //判断字符是否是结束标志
{
++i;
CH[i]=ch;
for(j=1;j<=jilu->tag;j++)
{
if(CH[i]==jilu->b[j].a)
{
jilu->b[j].num++;
break;
}
}
if(j-1==jilu->tag&&CH[i]!=jilu->b[j-1].a)
{
jilu->tag++;
jilu->b[jilu->tag].a=CH[i];
jilu->b[jilu->tag].num=1;
}
}
}
jilu->tag--;
fclose(fp); //关闭文件
printf("原文中的各字符统计状况如下:\n");
printf("*^*^*^*^*^*^*^*^**^*^*^**^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*\n");
for(i=1;i<=jilu->tag;i++)
{
s++;
printf("'%c'的个数为:%d ",jilu->b[i].a,jilu->b[i].num);
if(s%4==0) //每行放四个数据
printf("\n");
}
printf("\n");
for(i=1;i<=2*(jilu->tag)-1;i++)
{
if(i<=jilu->tag)
{
ht[i].weight=jilu->b[i].num; //初始化叶子结点权值
ht[i].Lchild=0; //初始化叶子结点左孩子
ht[i].parent=0; //初始化叶子结点父母
ht[i].Rchild=0; //初始化叶子结点右孩子
}
else
{
ht[i].Lchild=0; //初始化非叶子结点左孩子
ht[i].parent=0; //初始化非叶子结点父母
ht[i].Rchild=0; //初始化非叶子结点右孩子
ht[i].weight=0; //初始化非叶子结点权值
}
}
for(i=jilu->tag+1;i<=2*(jilu->tag)-1;i++)
{
min_2(ht,i-1,&tag1,&tag2); // 需找权值小的两个父母为0的结点
ht[tag1].parent=i;
ht[tag2].parent=i;
ht[i].Lchild=tag1;
ht[i].Rchild=tag2;
ht[i].weight=ht[tag1].weight+ht[tag2].weight;
}
}
void bianma(jilunode * jilu,hn ht,Hcode hc,int n) //哈夫曼树建完后,对叶
{ //子结点逐个编码
char * cd;
int start,i,p,c;
cd=(char *)malloc((n+1)*sizeof(char)); //申请存储字符的临时空间
cd[n-1]='\0'; //加结束标志
for(i=1;i<=n;i++)
{
start=n-1;
c=i;
p=ht[i].parent;
while(p!=0)
{
--start;
if(ht[p].Lchild==c)
cd[start]='1'; //结点在左边置1
if(ht[p].Rchild==c)
cd[start]='0'; //结点在右边置0
c=p;
p=ht[p].parent;
}
printf("%c的编码为:%s\n",jilu->b[i].a,&cd[start]);
hc[i]=(char *)malloc((n-start)*sizeof(char)); //为字符数组分配空间
strcpy(hc[i],&cd[start]);//将临时空间中的编码复制到字符数组中
}
free(cd); //释放临时空间
}
void bianmabaocun(Hcode hc,jilunode * jilu) //将原文以编码的形式保存到
{ //文件yiwen中
int i,j;
FILE *fp;
if((fp=fopen("yiwen","wb"))==NULL) //以写的方式打开文件
{
printf("Cannot open file\n");
exit(0); //文件打开失败退出
}
for(i=0;i<=N&&CH[i]!='^';i++)
{
for(j=1;j<=jilu->tag;j++)
if(CH[i]==jilu->b[j].a)
{
fputs(hc[j],fp); //将文件中的字符输出到字符数组中
printf("%s",hc[j]);
}
}
fclose(fp); //关闭文件
}
void yiwen(Hcode hc,jilunode * jilu) //读取yiwen中的编码,并将其翻译
{ //为原文存放到字符数组YW[N]中
int tag1,tag2,i,j,s=0;
FILE *fp; //文件指针
char *c;
if((fp=fopen("yiwen","rb"))==NULL) //以只读的方式打开文件
{
printf("cannot open file\n");
exit(0);
}
while(!feof(fp))
{
tag1=1; //结束for循环的辅助标志
tag2=1; //结束for循环的辅助标志
c=(char *)malloc(200*sizeof(char));
for(i=0;i<200&&tag1;i++)
{
c[i]=fgetc(fp); //将文件中的字符输出到数组中
c[i+1]='\0'; //加结束标志
for(j=1;(j<=jilu->tag)&&tag2;j++)
{
if(strcmp(hc[j],c)==0) //将编码与原文字符匹配
{
YW[s]=jilu->b[j].a; //匹配成功后将字符保存到数组YW中
tag1=0;
s++;
free(c); //释放临时字符存储空间
tag2=0;
}
}
}
}
YW[s]='\0';
}
void baocunyiwen() //将翻译的译文保存到文件textfile中
{
int i;
FILE *fp;
if((fp=fopen("textfile","wb"))==NULL)
{
printf("Cannot open file\n");
exit(0);
}
for(i=0;YW[i]!='\0';i++)
{
fputc(YW[i],fp); //将数组中的字符保存到文件中
putchar(YW[i]);
}
fclose(fp); //关闭文件
}
void duquyiwen() //从文件textfile中读取译文
{
char ch;
FILE *fp;
if((fp=fopen("textfile","rb"))==NULL) //以只读的方式打开文件
{
printf("cannot open file\n");
exit(0);
}
while(!feof(fp))
{
ch=fgetc(fp); //将文件中的字符赋给字符变量ch
printf("%c",ch); //输出字符
}
fclose(fp); //关闭文件
}
void duquyuanwen() //从文件yuanwen中读取原文
{
char ch;
FILE *fp;
if((fp=fopen("yuanwen","rb"))==NULL) //以只读的方式打开文件
{
printf("cannot open file\n");
exit(0);
}
while(!feof(fp))
{
ch=fgetc(fp); //将文件中的字符赋给字符变量ch
printf("%c",ch); //输出字符
}
fclose(fp); //关闭文件
}
void duqubianma() //从文件yiwen中读取原文
{
char ch;
FILE *fp;
if((fp=fopen("yiwen","rb"))==NULL)
{
printf("cannot open file\n");
exit(0);
}
while(!feof(fp))
{
ch=fgetc(fp); //将文件中的字符赋给字符变量ch
printf("%c",ch); //输出字符
}
fclose(fp); //关闭文件
}
void main()
{
int a,c,tep=1;
hn humtree; //定义用三叉链表方式实现的哈夫曼树
Hcode hc; //定义存放哈夫曼字符编码串的头指针的数组
jilunode ji; //定义存放字符种类数量的栈
jilunode *jilu;
jilu=&ji; //取指针
jilu->tag=0; //字符种类数标志初始化
while(tep)
{
printf(" (*^__^*) 哈夫曼编码系统欢迎您(*^__^*) \n");
printf("*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*\n");
printf(" 1--创建存贮原文件的文件\n");
printf(" 2--输入原文\n");
printf(" 3--对原文编码\n");
printf(" 4--对编码译码\n");
printf(" 5--输出原文\n");
printf(" 6--输出译码\n");
printf(" 7--输出译文\n");
printf(" 8--退出\n");
printf("注意:如果您未创建原文件原文操作,请不要进行后续项操作!\n");
printf("*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*\n");
printf("请输入服务选项(1-8):");
scanf("%d",&a);
getchar();
switch(a)
{
case 1:
jianliwenjian(); //建立存储字符的文件
printf("是否继续?(1.YES 2,NO ):");
scanf("%d",&c);
if(c==1)tep=1;
else
tep=0;
system("cls");
break;
case 2:
system("cls");
luruyuanwen(); //将原文录入到文件中
printf("\n注意:原文件将保存在名称为yuanwen的文件中!\n");
printf("是否继续?(1.YES 2,NO ):");
scanf("%d",&c);
if(c==1)tep=1;
else
tep=0;
system("cls");
break;
case 3:
chuangjian(jilu,humtree); //创建哈夫曼树
printf("\n各字符编码结果为:\n");
bianma(jilu,humtree,hc,jilu->tag); //对哈夫曼树的叶子结点编码
printf("原文的编码为:\n");
printf("*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*\n");
bianmabaocun(hc,jilu); //保存编码
printf("\n*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*^*\n");
printf("\n注意:原文的编码将保存在以名称为yiwen的文件中!\n");
printf("是否继续?(1.YES 2,NO ):");
scanf("%d",&c);
if(c==1)tep=1;
else
tep=0;
system("cls");
break;
case 4:
system("cls");
printf("编码对应的译文为:\n");
yiwen(hc,jilu); //对编码译码
baocunyiwen(); //保存译文
printf("\n注意:译文将保存在以名称为textfile的文件中!\n");
printf("是否继续?(1.YES 2,NO ):");
scanf("%d",&c);
getchar();
if(c==1)tep=1;
else
tep=0;
system("cls");
break;
case 5:
system("cls");
printf("原文为:\n");
duquyuanwen(); //从文件中读取原文
printf("\n是否继续?(1.YES 2,NO ):");
scanf("%d",&c);
getchar();
if(c==1)tep=1;
else
tep=0;
system("cls");
break;
case 6:
system("cls");
printf("原文的编码为:\n");
duqubianma(); //从文件中读取编码
printf("\n是否继续?(1.YES 2,NO ):");
scanf("%d",&c);
getchar();
if(c==1)tep=1;
else
tep=0;
system("cls");
break;
case 7:
system("cls");
printf("编码的译文为:\n");
duquyiwen(); //从文件中读取译文
printf("\n是否继续?(1.YES 2,NO ):");
scanf("%d",&c);
getchar();
if(c==1)tep=1;
else
tep=0;
system("cls");
break;
case 8:
printf("谢谢使用!");
tep=0;
break;
default:
system("cls");
printf("选择错误!\n");
}
}
}