LL(1)分析程序
一、实验目的与任务
根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
二、实验内容与过程
程序输入/输出示例:
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:
(1)E->TG
(2)G->+TG
(3)G->ε
(4)T->FS
(5)S->*FS
(6)S->ε
(7)F->(E)
(8)F->i
三、实验结果及分析
输出的格式如下:
(1)LL(1)分析程序
(2)输入一以#结束的符号串(包括+—*/()i#):在此位置输入符号串
(3)输出过程如下:
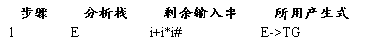
(4)输入符号串为非法符号串(或者为合法符号串)
四、源代码
char A[20];/*分析栈*/
char B[20];/*剩余串*/
char v1[20]={'i','+','*','(',')','#'};/*终结符 */
char v2[20]={'E','G','T','S','F'};/*非终结符 */
int j=0,b=0,top=0,l;/*L为输入串长度 */
typedef struct type/*产生式类型定义 */
{
char origin;/*大写字符 */
char array[5];/*产生式右边字符 */
int length;/*字符个数 */
}type;
type e,t,g,g1,s,s1,f,f1;/*结构体变量 */
type C[10][10];/*预测分析表 */
void print()/*输出分析栈 */
{
int a;/*指针*/
for(a=0;a<=top+1;a++)
printf("%c",A[a]);
printf("\t\t");
}/*print*/
void print1()/*输出剩余串*/
{
int j;
for(j=0;j<b;j++)/*输出对齐符*/
printf(" ");
for(j=b;j<=l;j++)
printf("%c",B[j]);
printf("\t\t\t");
}/*print1*/
void main()
{
int m,n,k=0,flag=0,finish=0;
char ch,x;
type cha;/*用来接受C[m][n]*/
/*把文法产生式赋值结构体*/
for(m=0;m<=4;m++)/*初始化分析表*/
for(n=0;n<=5;n++)
C[m][n].origin='N';/*全部赋为空*/
/*填充分析表*/
C[0][0]=e;C[0][3]=e;
C[1][1]=g;C[1][4]=g1;C[1][5]=g1;
C[2][0]=t;C[2][3]=t;
C[3][1]=s1;C[3][2]=s;C[3][4]=C[3][5]=s1;
C[4][0]=f1;C[4][3]=f;
printf("提示:本程序只能对由'i','+','*','(',')'构成的以'#'结束的字符串进行分析,\n");
printf("请输入要分析的字符串:");
do/*读入分析串*/
{
scanf("%c",&ch);
if ((ch!='i') &&(ch!='+') &&(ch!='*')&&(ch!='(')&&(ch!=')')&&(ch!='#'))
{
printf("输入串中有非法字符\n");
exit(1);
}
B[j]=ch;
j++;
}while(ch!='#');
l=j;/*分析串长度*/
ch=B[0];/*当前分析字符*/
A[top]='#'; A[++top]='E';/*'#','E'进栈*/
printf("步骤\t\t分析栈 \t\t剩余字符 \t\t所用产生式 \n");
do
{
x=A[top--];/*x为当前栈顶字符*/
printf("%d",k++);
printf("\t\t");
for(j=0;j<=5;j++)/*判断是否为终结符*/
if(x==v1[j])
{
flag=1;
break;
}
if(flag==1)/*如果是终结符*/
{
if(x=='#')
{
finish=1;/*结束标记*/
printf("acc!\n");/*接受 */
getchar();
getchar();
exit(1);
}/*if*/
if(x==ch)
{
print();
print1();
printf("%c匹配\n",ch);
ch=B[++b];/*下一个输入字符*/
flag=0;/*恢复标记*/
}/*if*/
else/*出错处理*/
{
print();
print1();
printf("%c出错\n",ch);/*输出出错终结符*/
exit(1);
}/*else*/
}/*if*/
else/*非终结符处理*/
{
for(j=0;j<=4;j++)
if(x==v2[j])
{
m=j;/*行号*/
break;
}
for(j=0;j<=5;j++)
if(ch==v1[j])
{
n=j;/*列号*/
break;
}
cha=C[m][n];
if(cha.origin!='N')/*判断是否为空*/
{
print();
print1();
printf("%c->",cha.origin);/*输出产生式*/
for(j=0;j<cha.length;j++)
printf("%c",cha.array[j]);
printf("\n");
for(j=(cha.length-1);j>=0;j--)/*产生式逆序入栈*/
A[++top]=cha.array[j];
if(A[top]=='^')/*为空则不进栈*/
top--;
}/*if*/
else/*出错处理*/
{
print();
print1();
printf("%c出错\n",x);/*输出出错非终结符*/
exit(1);
}/*else*/
}/*else*/
}while(finish==0);
}/*main*/
五、实验截图
当输入:i+i*i#
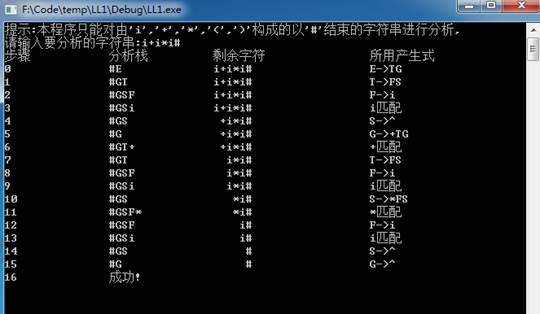
图1
当输入(i++)*(++i)#
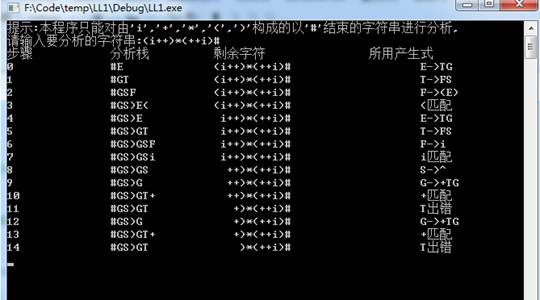
图2
第二篇:LL1语法分析实验报告
LL(1)语法分析
一, 实验名称:
实现LL分析。
二, 实验要求:
Ø 输入任意文法
Ø 消除左递归
Ø 消除左因子
Ø 测试任意输入语句是否合法
Ø 数据结构描述
Ø 算法说明
Ø 输出first集合
Ø输出follow集合
Ø输出LL(1)表
三. 设计原理及算法描述
所谓LL(1)分析法,就是指从左到右扫描输入串(源程序),同时采用最左推导,且对每次直接推导只需向前看一个输入符号,便可确定当前所应当选择的规则。实现LL(1)分析的程序又称为LL(1)分析程序或LL1(1)分析器。
一个文法要能进行LL(1)分析,那么这个文法应该满足:无二义性,无左递归,无左公因子。当文法满足条件后,再分别构造文法每个非终结符的FIRST和FOLLOW集合,然后根据FIRST和FOLLOW集合构造LL(1)分析表,最后利用分析表,根据LL(1)语法分析构造一个分析器。LL(1)的语法分析程序包含了三个部分,总控程序,预测分析表函数,先进先出的语法分析栈,本程序也是采用了同样的方法进行语法分析,该程序是采用了C语言来编写,其逻辑结构图如下:

LL(1)预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前的输入符号a做哪种过程的。对于任何(X,a),总控程序每次都执行下述三种可能的动作之一:
(1)若X = a =‘#’,则宣布分析成功,停止分析过程。
(2)若X = a ‘#’,则把X从STACK栈顶弹出,让a指向下一个输入符号。
(3)若X是一个非终结符,则查看预测分析表M。若M[A,a]中存放着关于X的一个产生式,那么,首先把X弹出STACK栈顶,然后,把产生式的右部符号串按反序一一弹出STACK栈(若右部符号为ε,则不推什么东西进STACK栈)。若M[A,a]中存放着“出错标志”,则调用出错诊断程序ERROR。
事实上,LL(1)的分析是根据文法构造的,它反映了相应文法所定义的语言的固定特征,因此在LL(1)分析器中,实际上是以LL(1)分析表代替相应方法来进行分析的。
2.构造LL(1)分析表
考查文法G[E]:
E→E+T | T
T→T*F | F
F→( E ) | i | x | y
我们容易看出此文法没有左公因子也没有二义性,但却存在两个直接左递归,这里我们利用引入新非终结符的方法来消除它使方法满足要求,即:
对形如:U→Ux|y的产生式(其中x,y V+ ,y不以U开头),引入一个新的非终结符U’后,可以等价地改写成为:
U→yU’
U’→x U’|ε
显然改写后,U和U’都不是左递归的非终结符。因此文法G[E]按上述方法消去左递归后可等价地写成:
E→TP
P→+TP | ε
T→FQ
Q→*FQ | ε
F→( E ) | i | x | y
在构造LL(1)预测分析表之前,首先要构造该文法的每个非终结符的FIRST和FOLLOW集合,按照下面描述的算法来构造这两个集合。
①FIRST集合的构造算法:
(1)若X∈VT,则FIRST(X)={X}。
(2)若X∈VN,且有产生式X→a……,则把a加入到FIRST(X)中;若X→ε也是一条产生式,则把ε也加到FIRST(X)中。
(3)若X→Y……是一个产生式且Y∈VN,则把FIRST(Y)中的所有非ε-元素都加到FIRST(X)中;若X→Y1Y2…Yk是一个产生式,Y1,…,Yi-1都是非终结符,而且,对于任何j,1≤j≤i-1,FIRST(Yj)都含有ε(即Y1…Yi-1* ε),则把FIRST(Yj)中的所有非ε-元素都加到FIRST(X)中;特别是,若所有的FIRST(Yj)均含有ε,j=1,2,…,k,则把ε加到FIRST(X)中。
连续使用上面的规则,直至每个集合FIRST不再增大为止。
②FOLLOW集合的构造算法:
(1)对于文法的开始符号S,置#于FOLLOW(S)中;
(2)若A→αBβ是一个产生式,则把FIRST(β)| {ε}加至FOLLOW(B)中;
(3)若A→αB是一个产生式,或A→αBβ是一个产生式而β ε(即ε∈FIRST(β)),则把FOLLOW(A)加至FOLLOW(B)中。
连续使用上面的规则,直至每个集合FOLLOW不再增大为止。
现在来构造G[E]的LL(1)预测分析表。预测分析表M[A, a]是如下形式的一个矩阵。A为非终结符,a是终结符或‘#’。矩阵元素 M[A, a]中存放这一条关于A的产生式,指出当A面临输入符号a是所应采用的规则。M[A, a]也可能存放一条“出错标志”,指出当A根本不该面临输入符号a。
4.利用分析表进行预测分析
带预测分析的PDA
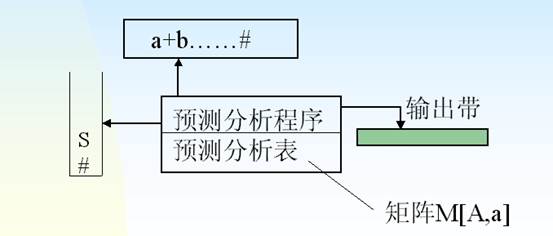
1)总程序的算法描述如下:
BEGIN
首先把‘#’然后把文法开始符号推进STACK栈;
把第一个输入符号读进a;
FLAG:=TRUE;
WHILE FLAG DO
BEGIN
把栈顶符号出栈到X中;
IF XÎVT THEN
IF X =a THEN 把下一输入符号读进a
ELSE ERROR
ELSE IF X= ‘#’ THEN
IF X=a THEN FLAG:=FALSE
ELSE ERROR
ELSE IF M[A, a]={X®x1x2…xk} THEN
把xk, xk–1,…, x1依次进栈
/*若x1, x2 …xk=e,则不进栈*/
ELSE ERROR
END OF WHILE;
STOP /*分析成功,过程结束*/
END
四.主要数据结构描述
1. char termin[50]; /*终结符号*/
char non_ter[50]; /*非终结符号*/
char v[50]; /*所有符号*/
char left[50]; /*左部*/
char right[50][50]; /*右部*/
char first[50][50],follow[50][50]; /*各产生式右部的FIRST和左部的FOLLOW集合*/
int M[20][20]; /*二维数组存储分析表*/
栈T用来存放产生式的右边
Str数组存放要分析的句子串
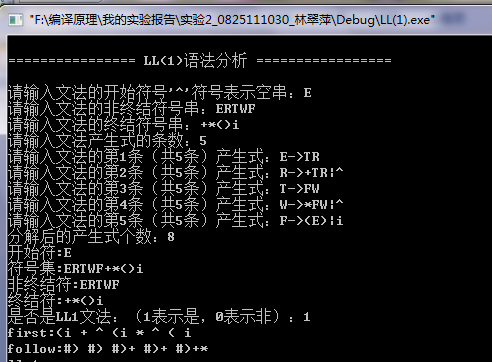
五. 运行结果:
ERTWF#
+*()i#
测试文法G[E]:
1 E -> TR
2 R -> +TR|^
3 T -> FW
4 W -> * FW|^
5 F -> (E)|i
分析例句:i*(i)# , i+i#

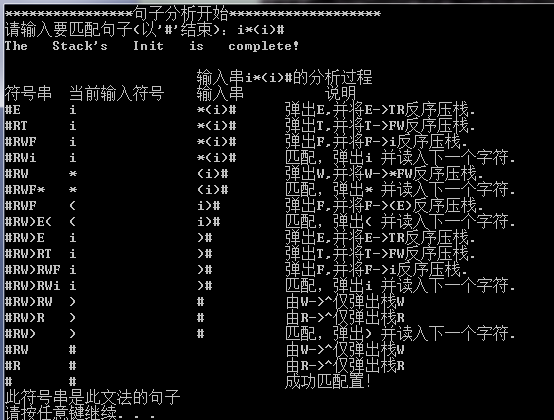
六.结果分析
以上两个试验从较大呈度上说明了程序运行的正确性及稳定性,当然,对程序本身还有待进行更进一步的严格测试。