LL1实验报告
08计算机3班
1.设计原理
所谓LL(1)分析法,就是指从左到右扫描输入串(源程序),同时采用最左推导,且对每次直接推导只需向前看一个输入符号,便可确定当前所应当选择的规则。实现LL(1)分析的程序又称为LL(1)分析程序或LL1(1)分析器。
我们知道一个文法要能进行LL(1)分析,那么这个文法应该满足:无二义性,无左递归,无左公因子。当文法满足条件后,再分别构造文法每个非终结符的FIRST和FOLLOW集合,然后根据FIRST和FOLLOW集合构造LL(1)分析表,最后利用分析表,根据LL(1)语法分析构造一个分析器。LL(1)的语法分析程序包含了三个部分,总控程序,预测分析表函数,先进先出的语法分析栈,本程序也是采用了同样的方法进行语法分析,该程序是采用了C++语言来编写,其逻辑结构图如下:
LL(1)预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前的输入符号a做哪种过程的。对于任何(X,a),总控程序每次都执行下述三种可能的动作之一:
(1)若X = a =‘#’,则宣布分析成功,停止分析过程。
(2)若X = a ‘#’,则把X从STACK栈顶弹出,让a指向下一个输入符号。
(3)若X是一个非终结符,则查看预测分析表M。若M[A,a]中存放着关于X的一个产生式,那么,首先把X弹出STACK栈顶,然后,把产生式的右部符号串按反序一一弹出STACK栈(若右部符号为ε,则不推什么东西进STACK栈)。若M[A,a]中存放着“出错标志”,则调用出错诊断程序ERROR。
事实上,LL(1)的分析是根据文法构造的,它反映了相应文法所定义的语言的固定特征,因此在LL(1)分析器中,实际上是以LL(1)分析表代替相应方法来进行分析的。
2.分析
LL ( 1) 分析表是一个二维表,它的表列符号是当前符号,包括文法所有的终结和自定义。
的句子结束符号#,它的表行符号是可能在文法符号栈SYN中出现的所有符号,包括所有的非终结符,所有出现在产生式右侧且不在首位置的终结符, 自定义的句子结束符号#表项。
为当前栈符号与当前符号匹配后,所要求的栈操作和输入操作。表项表明了文法的终结符与非终结符是否可能相遇。其中 , 栈操作包括两种,一是弹栈;二是弹栈后,将符号串ABc反转后压栈;输 入 操作 包 括 两 种 ,一 是 读 入下一符号,是保持当前符号不变。
具体的造算法为171。
(1 ) 设 A , B 为文法的非终结符,C为文法的终结符和非终结符组成的字符串,a为文法的终结符将所 有 产 生式分为四类:6)A->aB,则(A,a )项填写为(B调向后压栈,读入下一个字符):(ii)A->a; A->a,则将〔A, a)项填写为(弹栈,读入下一个字符):(iii)A->BC,则将(A,select(A->BC))项全部填写为(将BC调向后压栈,保持当前字符不读入):(iv)A->N,则将(A, follow(A))项全部填写为(弹栈,保持当前字符不读)。
(2) 对表行和表列的所有字符进行循环;
(3) 如果当前表行的字符是非终结符,它必有产生式,依据此产生式的类型,填写表项。
(4) 如果当前表列的字符不在此产生式的选择集合中,该项填写为Eror。
(5)对 (# ,#)项填写为OK;
(6) 对当前表行字符为终结符的,只有它与表列字符相同时,才填写为(弹栈,读入下一个字符),否则填入Eror。
3.流程图
数据结构
#include"iostream.h"
#include "stdio.h"
#include "malloc.h"
#include "conio.h"
struct Lchar{
char char_ch;
struct Lchar *next;
}Lchar,*p,*h,*temp,*top,*base;
char curchar;
char curtocmp;
int right;
int table[5][8]={{1,0,0,1,0,0},
{0,1,0,0,1,1},
{1,0,0,1,0,0},
{0,1,1,0,1,1},
{1,0,0,1,0,0}};
int i,j;
void push(char pchar)
{
temp=(struct Lchar*)malloc(sizeof(Lchar));
temp->char_ch=pchar;
temp->next=top;
top=temp;
}
void pop(void)
{
curtocmp=top->char_ch;
if(top->char_ch!='#')
top=top->next;
}
void doforpush(int t)
{
switch(t)
{
case 0:push('A');push('T');break;
case 5:push('A');push('T');break;
case 11:push('A');push('T');push('+');break;
case 20:push('B');push('F');break;
case 23:push('B');push('F');break;
case 32:push('B');push('F');push('*');break;
case 40:push('i');break;
case 43:push(')');push('E');push('(');
}
}
void changchartoint()
{
switch(curtocmp)
{
case 'A':i=1;break;
case 'B':i=3;break;
case 'E':i=0;break;
case 'T':i=2;break;
case 'F':i=4;
}
switch(curchar)
{
case 'i':j=0;break;
case '+':j=1;break;
case '*':j=2;break;
case '(':j=3;break;
case ')':j=4;break;
case '#':j=5;
}
}
void dosome(void)
{
int t;
for(;;)
{
pop();
curchar=h->char_ch;
printf("\n%c\t%c",curchar,curtocmp);
if(curtocmp=='#' && curchar=='#')
break;
if(curtocmp=='A'||curtocmp=='B'||curtocmp=='E'||curtocmp=='T'||curtocmp=='F')
{
if(curtocmp!='#')
{
changchartoint();
if(table[i][j])
{
t=10*i+j;
doforpush(t);
continue;
}
else
{
right=0;
break;
}
}
else
if(curtocmp!=curchar)
{
right=0;
break;
}
else
break;
}
else
if(curtocmp!=curchar)
{
right=0;
break;
}
else
{
h=h->next;
continue;
}
}
}
void main(void)
{
char ch;
cout<<"* 文件名称: 语法分析"<
cout<<" "<
cout<<"/* 程序相关说明 */"<
cout<<"---------------------------------------------------------------------"<
cout<<"-/* A=E’ B=T’ */"<
cout<<"-* 目 的: 对输入LL(1)文法字符串,本程序能自动判断所给字符串是 -"<
cout<<"-* 否为所给文法的句子,并能给出分析过程。 -"<
cout<<"-*-------------------------------------------------------------------"<
cout<<"表达式文法为:"<
cout<<" E->E+T|T"<
cout<<" T->T*F|F"<
cout<<" F->(E)|i"<
cout<<"请在下行输入要分析的串(#号结束):"<
right=1;
base=(struct Lchar*)malloc(sizeof(Lchar));
base->next=NULL;
base->char_ch='#';
temp=(struct Lchar*)malloc(sizeof(Lchar));
temp->next=base;
temp->char_ch='E';
top=temp;
h=(struct Lchar*)malloc(sizeof(Lchar));
h->next=NULL;
p=h;
do{
ch=getch();
putch(ch);
if(ch=='i'||ch=='+'||ch=='-'||ch=='*'||ch=='/'||ch=='('||ch==')'||ch=='#')
{
temp=(struct Lchar*)malloc(sizeof(Lchar));
temp->next=NULL;
temp->char_ch=ch;
h->next=temp;
h=h->next;
}
else
{
temp=p->next;
printf("\nInput a wrong char!Input again:\n");
for(;;)
{
if (temp!=NULL)
printf("%c",temp->char_ch);
else
break;
temp=temp->next;
}
}
}while(ch!='#');
p=p->next;
h=p;
dosome();
if(right)
printf("\n成功!\n");
else
printf("\n错误!\n");
getch();
}
截图:
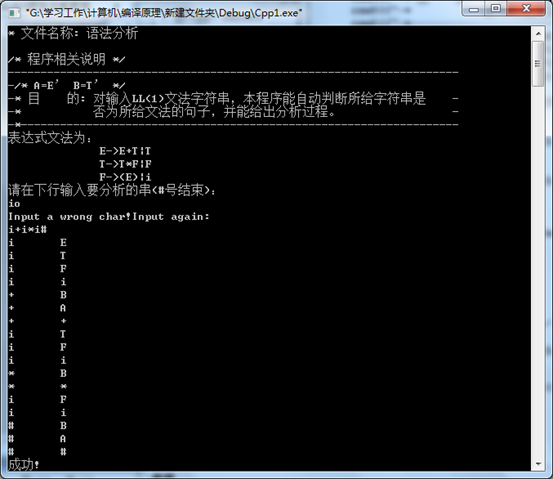
预测分析程序
一、预测分析器的结构
预测分析表是一个M[A,a]形式的矩阵。其中,A为非终结符,a是终结符或‘#’(注意,‘#’不是文法的终结符,我们总把它当成输入串的结束符。虽然它不是文法的一部分,但假定它的存在将有助于简化分析算法的描述)。矩阵元素M[A,a]中存放着一条关于A的产生式,指出当A面临输入符号a时所应采用的候选。M[A,a]中也可能存放一个“出错标志”,指出A根本不该面临输入符号a。
栈STACK 用于存放文法符号。分析开始时,栈底先放一个‘#’,然后,放进文法开始符号。同时,假定输入串之后也总有一个‘#’,标志输入串结束。
用于存放文法符号。分析开始时,栈底先放一个‘#’,然后,放进文法开始符号。同时,假定输入串之后也总有一个‘#’,标志输入串结束。
预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前的输入符号a行事的。对于任何(X,a),总控程序每次都执行下述三种可能的动作之一:
(1)若X=a=‘#’,则宣布分析成功,停止分析过程。
(2)若X=a ¹‘#’,则把X从STACK栈顶逐出,让a指向下一个输入符号。
(3)若X是一个非终结符,则查看分析表M。若M[A,a]中存放着关于X的一个产生式,那么,首先把X逐出STACK栈顶,然后,把产生式的右部符号串按反序一一推进STACK栈(若右部符号为e,则意味不推什么东西进栈)。在把产生式的右部符号推进栈的同时应做这个产生式相应的语义动作(目前暂且不管)。若M[A,a]中存放着“出错标志”,则调用出错诊察程序ERROR。
预测分析器的结构如图所示
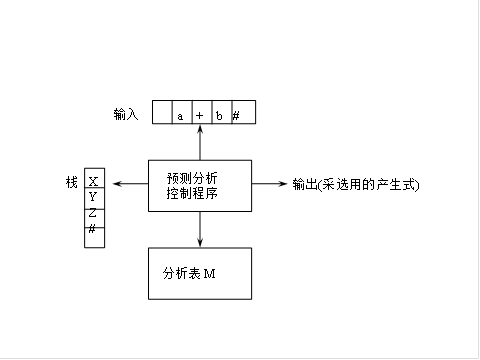
图 1 预测分析器的结构
二、预测分析控制程序
预测分析控制程序的描述:
置ip指向ω#的第一个符号
repeat
令X是栈顶符号, a是ip所指向的符号;
if X 是一个终结符号或# then
if X=a then
把X从栈中弹出,并且更新ip
else error()
else /*X是非终结符号*/
if M[X,a]=X®Y1Y2.. .. Yk then begin
把X从栈中弹出;
把 Yk,Yk-1,.. ..,Y1压入栈中, 即Y1在顶上;
输出产生式 X®Y1Y2.. .. Yk
end
else error()
until X=# /*栈为空*/
表1 字符串i + i * i的分析过程
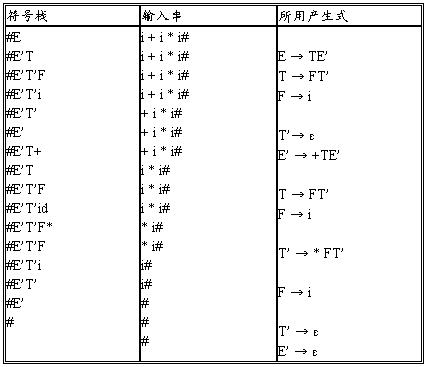
若文法G的分析表不含多重定义入口,则称其为LL(1)文法。
三、一个文法是LL(1)文法充分必要条件
一个文法G是LL(1)的,当且仅当对于G的每一个非终结符A的任何两个不同产生式A→α½β,下面的条件成立:
(1)FIRST(α)∩FIRST(β)=f;
(2)假若β*Þ e,那么,FIRST(α)∩FOLLOW(A)=f。
LL(1)文法是无二义的.
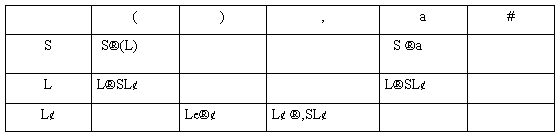
例1 考虑文法G[S]
S→(L) | a
L→L,S | S
消除左递归后的文法为 G’[S]
S→(L) | a
L→SL¢
L¢→,SL¢ | e
构造FIRST 和FOLLOW集合
FIRST(S) = { (, a}
FIRST(L)= { (, a}
FIRST(L¢) = {, , e }
FOLLOW(S) = { #, ) }
FOLLOW(L) = { ) }
FOLLOW(L¢) = { ) }
构造文法的LL(1) 分析表
表2 LL(1) 分析表