<<SPSS统计分析软件>>
课程设计报告
班级:XXXXXXXXXXXX
学号:XXXXXXXX__
姓名:XXXXXX
20##年6月
私营企业中收入与利润的回归性分析
【摘要】本文以私营企业中不同行业的收入与利润之间的关系为实例,利用SPSS软件介绍线性回归分析法在实际生活中的应用。
关键字:线性回归分析 SPSS 私营企业
正文
引言
回归分析法是一种可以将复杂问题简化的数学方法。它是以相关远离为基础的,分析因变量与自变量的相关关系,用回归方程表示,根据自变量的数值变化,去预测因变量的方法。其主要内容和步骤是:首先根据理论和对问题的分析判断,将变量分为自变量和因变量;其次,设法找出合适的数学方程式描述变量间的关系;由于涉及到的变量具有不确定性行,接着还要对回归模型进行统计检验;统计检验通过后,最后是利用回归模型,根据自变量去顾及、预测因变量。
分析
下面通过具体的实例来说明。数据来源于20##年中国私营企业9个行业的收入与利润的统计

(1)在进行回归行分析之前,首先绘制散点图来分析利润总额和主营业务收入的关系,判断使用线性模型来研究这两个变量之间的关系是否合理。
步骤:打开spss软件,单击GraphsàScatter/Dot,选择Simple Scatter,单击Define,选择“利润总额”移入纵坐标下,“主营业务收入”移入横坐标下,单击OK,即可生成如下散点图。
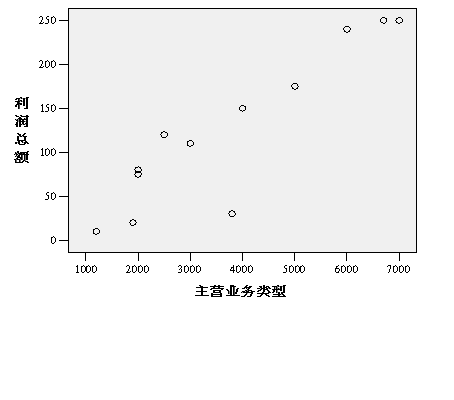
从图中来看,两个变量之间的线性关系是比较明显的,随着主营业务收入的增加,利润总额也相应增加,但是其变动程度也有所增加。所以采用线性方程来研究两者的关系是合适的。
(2)建立“利润总额”与“主营业务收入”的线性回归方程。
骤步:单击AnalyzeàRegressionàLinear,选择“利润总额”移入Dependent,“主营业务收入”移入Independent,单击Plots,选择SDRESID为纵变量,ZPRED为横坐标变量,选择Histogram和Normal probability plot,单击Continue,单击Save,选择standardized,residuals,cook’s和leverage values,单击continue,单击OK,即可输出结果。
利润总额对主营业务收入的一元线性回归输出结果

根据系数写出“利润总额”对“主营业务收入”的线性回归方程:^Yi=-24.819+0.040Xi,斜率系数的t统计量为6.937,对应的显著性水平Sig.<a=0.05,拒绝了自变量和因变量之间不存在线性关系的假设,也就是说自变量“主营业务收入”通过了参数的显著性检验。
回归模型方差分析表

从方差分析表中可以看出回归平方和ESS=70906.985,自由度df为1,残差平方和RSS=85641.661,其对应的自由度为11。F统计量对应的显著性水平Sig.=0.000<0.05,方程总体回归显著。

从图中看,拟合系数为0.828,说明自变量可解释因变量82.8%左右的方差变动,模型的拟合效果较好。

从以上带有正态曲线的直方图中可以看出,回归模型的标准化残差分布呈现“两头小,中间大”的趋势,近似接近正态分布。
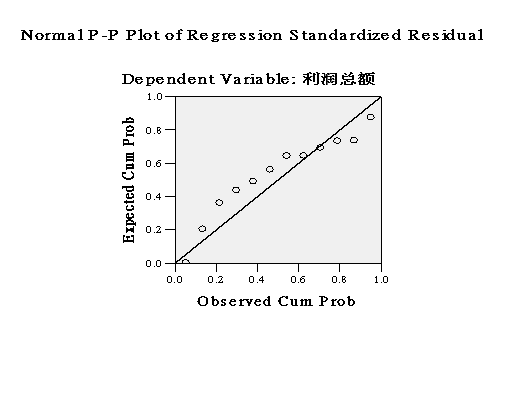
残差的P-P图也分布在过远点、倾斜角为45度的直线附近,进一步表明残差近似服从正态分布。
总结
由以上案例可以看出,工业企业的利润和主营业务收入之间存在较为明显的关系,一般来说,企业的主营业务收入越多,企业的利润也会越高。但是不同行业的收入与利润存在较为大的差异,所以用SPSS软件分析直观明了,为财务管理分析人员提供了方便。
第二篇:spss的数据分析报告
关于某公司474名职工综合状况的统计分析报告
一、数据介绍:
本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、。。。以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。
二、数据分析
1、 频数分析。基本的统计分析往往从频数分析开始。通过频数分析能够了解变量的取值状况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。
Statistics

首先,对该公司的男女性别分布进行频数分析,结果如下:
Gender

上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。
其次对原有数据中的受教育程度进行频数分析,结果如下表 :
Educational Level (years)
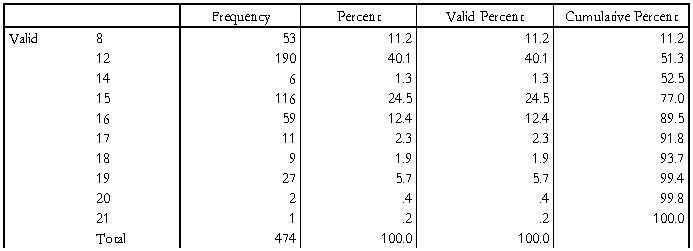
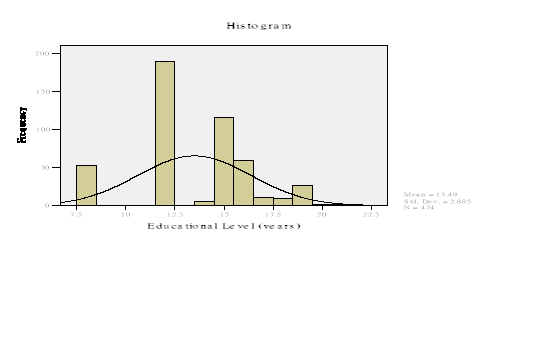 上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。
上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。
2、 描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的均值、标准差、片度峰度等数据,以进一步把我数据的集中趋势和离散趋势。
Descriptive Ststistics
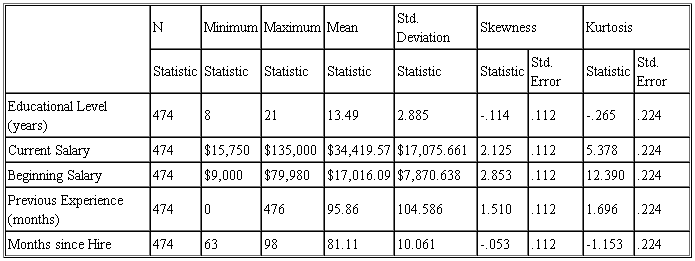
如表所示,以起始工资为例读取分析结果,474名职工的起始工资最小值为$9000,最大值为$79980,平均起始工资为$17016,标准差为$7870.638,偏度系数和峰度系数分别为2.853和12.390。其他数据依此读取,则该表表明474名职工的受教育水平、起始工资、现工资、先前工作经验、现在工作经验的详细分布状况。
3、 Exploratory data analysis。
(1) 交叉分析。
通过频数分析能够掌握单个变量的数据分布情况,但是在实际分析中,不仅要了解单个变量的分布特征,还要分析多个变量不同取值下的分布,掌握多个变量的联合分布特征,进而分析变量之间的相互影响和关系。就本数据而言,需要了解现工资与性别、年龄、受教育水平、起始工资、本单位工作经历、以前工作经历、职务等级的交叉分析。现以现工资与职务等级的列联表分析为例,读取数据(下面数据分析表为截取的一部分):
单因素分析用来研究一个控制变量的不同水平是否对观测变量产生了显著影响。下面我们把受教育水平和起始工资作为控制变量,现工资为观测变量,通过单因素方差分析方法研究受教育水平和起始工资对现工资的影响进行分析。分析结果如下:
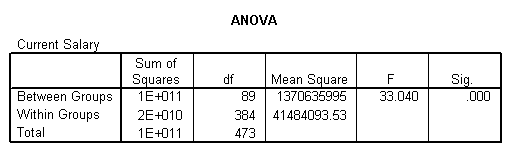
上表是起始工资对现工资的单因素方差分析结果。可以看出:F统计量的观测值为33.040,对应的概率P值近似等于0,如果显著性水平为0.05,由于概率值P小于显著性水平q,则应拒绝原假设,认为不同的起始工资对现工资产生了显著影响。
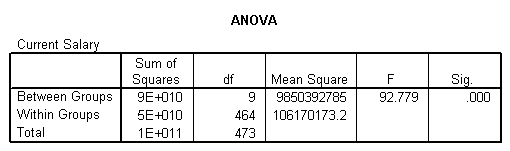
同理,上表是受教育水平对现工资影响的单因素分析结果,其结果亦为拒绝原假设,所以不同的受教育水平对现工资产生显著影响。
4、 相关分析。相关分析是分析客观事物之间关系的数量分析法,明确客观事物之间有怎
样的关系对理解和运用相关分析是极其重要的。
函数关系是指两事物之间的一种一一对应的关系,即当一个变量X取一定值时,另一个变量函数Y可以根据确定的函数取一定的值。另一种普遍存在的关系是统计关系。统计关系是指两事物之间的一种非一一对应的关系,即当一个变量X取一定值时,另一个变量Y无法根据确定的函数取一定的值。统计关系可分为线性关系和非线性关系。
事物之间的函数关系比较容易分析和测度,而事物之间的统计关系却不像函数关系那样直接,但确实普遍存在,并且有的关系强有的关系弱,程度各有差异。如何测度事物之间的统计关系的强弱是人们关注的问题。相关分析正是一种简单易行的测度事物之间统计关系的有效工具。
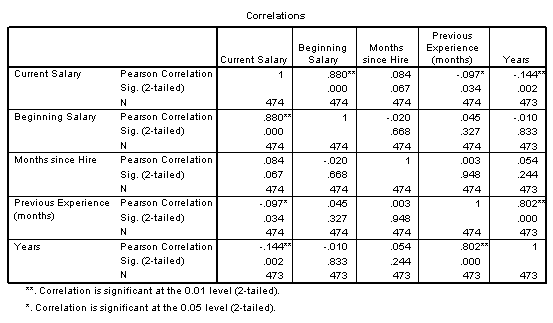 上表是对本次分析数据中,现工资、起始工资、本单位工作时间、以前工作时间、年龄五个变量间的相关分析,表中相关系数旁边有两个星号(**)的,表示显著性水平为0.01时,仍拒绝原假设。一个星号(*)表示显著性水平为0.05是仍拒绝原假设。先以现工资这一变量与其他变量的相关性为例分析,由上表可知,现工资与起始工资的相关性最大,相关系数为0.880,而与在本单位的工作时间相关性最小,相关系数为0.084。
上表是对本次分析数据中,现工资、起始工资、本单位工作时间、以前工作时间、年龄五个变量间的相关分析,表中相关系数旁边有两个星号(**)的,表示显著性水平为0.01时,仍拒绝原假设。一个星号(*)表示显著性水平为0.05是仍拒绝原假设。先以现工资这一变量与其他变量的相关性为例分析,由上表可知,现工资与起始工资的相关性最大,相关系数为0.880,而与在本单位的工作时间相关性最小,相关系数为0.084。
5、 参数检验。
首先对现工资的分布做正态性检验,结果如下:
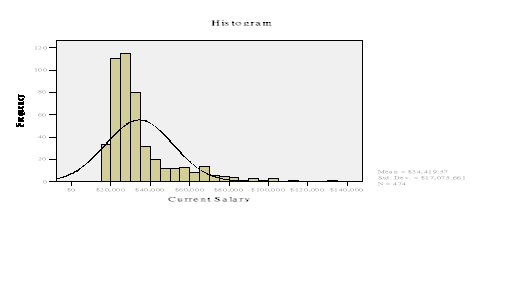
由上图可知,现工资的分布可近似看作符合正态分布,现推断现工资变量的平均值是否为$3,000,0,因此可采取单样本t检验来进行分析。分析如下:
One-Sample Statistics
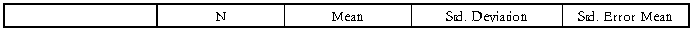
One-Sample Test

由One-Sample Statistics可知,474名职工的现工资平均值为¥34,419.57,标准差为$17,075.661,均值标准误差为$784.311。图表One-Sample Test中,第二列是t统计量的观测值为5.635;第三列是自由度为473(n-1);第四列是t统计量观测值的双尾概率值;第五列是样本均值和检验值的差;第六列和第七列是总体均值与原假设值差的95%的置信区间为($2,878.40 , 5,960.73)。该问题的t值等于5.635对应的临界置信水平为0,远远小于设置的0.05,因此拒绝原假设,表明该公司的474名职工的现工资与$3,000,0存在显著差异。
6、 非参数检验。对本数据中的年龄做正态分布检验,结果如下:
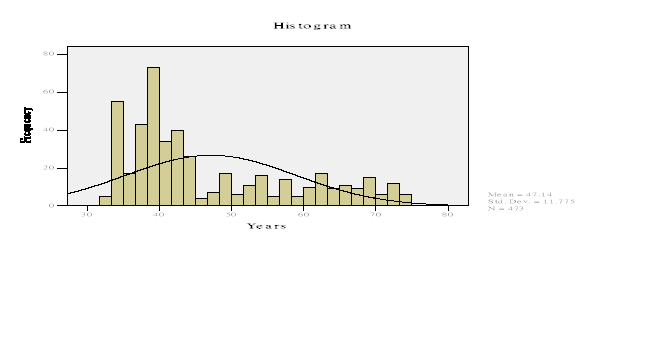
由上图两图可知,474名职工的年龄分布并不完全符合正态分布,所以现推断其职工年龄的平均数在40-45岁之间,可对其采用非参数检验的方法进行检验。检验结果如下:
Chi-Square Test
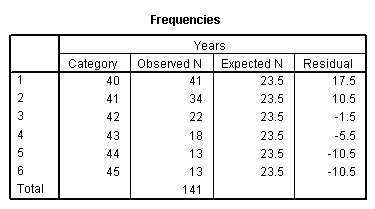

上面的第一个表为卡方检验的频率表,输出有关频率统计。从表中可知,职工年龄为40岁的有41名,期望值为23.5,残差为17.5,其余读取方式相同。第二个表是卡方检验统计表,显示检验的卡方值,自由度和渐进显著性水平分别是28.489、5、0。因为显著性水平0小于0.05,因此拒绝原假设,即474名职工的平均年龄不在40到45岁之间。