应用统计学实验报告(spss软件分析)
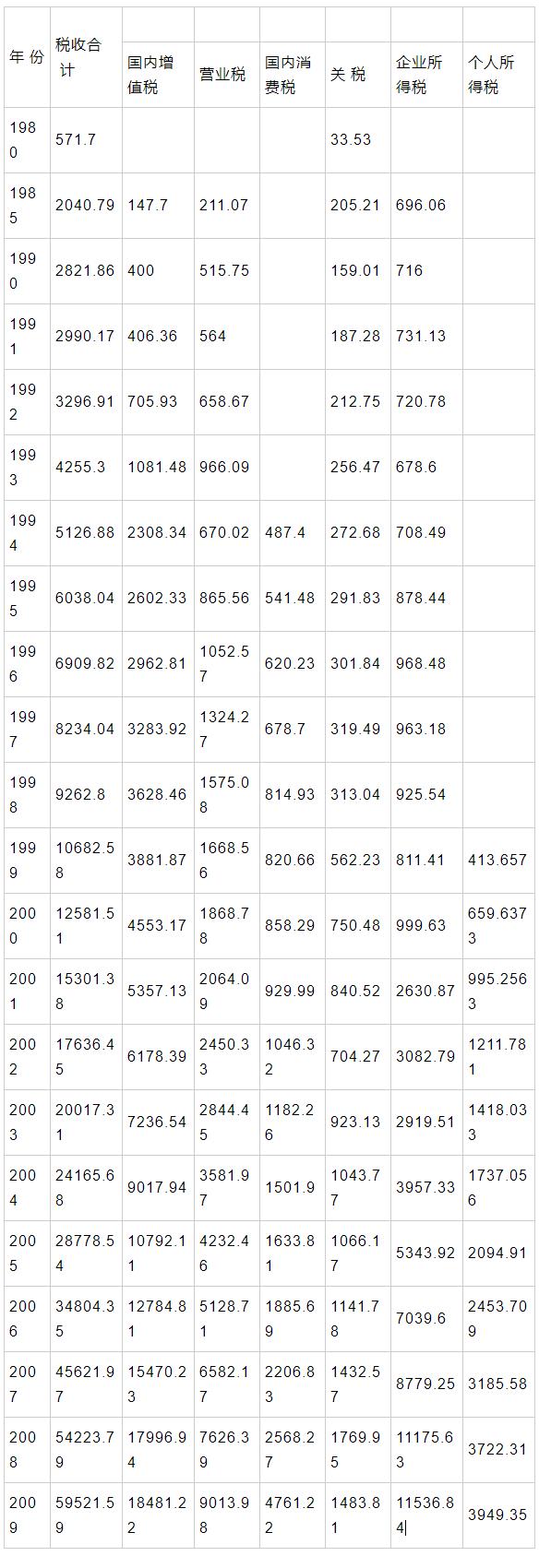
多元回归分析——各 项 税 收
数据来自《中国统计年鉴2010》
1.拟合优度检验 图a *强制进入策略

依据此表进行拟合优度检验。由于是此分析多元回归分析,方程有多个解释变量,因此参考调整的判定系数(Adjusted R Square),由上表:由于R2(1.000)等于1,因此认为拟合优度很高,被解释变量税收合计能被模型充分解释。
2.回归方程的显著性检验(F检验) 图b*强制进入策略
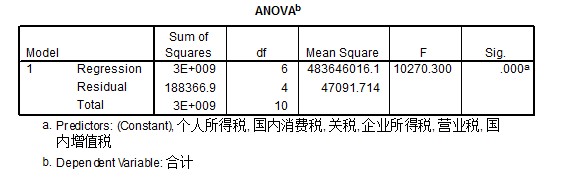
由此表进行回归方程的显著性检验。由表可知,F检验统计量的观测值为10270.300,对应的概率p值近似为0.。显著性水平a为0.05,由于概率p小于显著性水平a,应拒绝回归方程显著性检验的零假设,认为各回归系数与0存在显著性差异,不同时为0,被解释变量税收合计与解释变量全体的线性关系显著,可建立线性模型。
3.回归系数显著性检验(t检验) 图c*强制进入策略
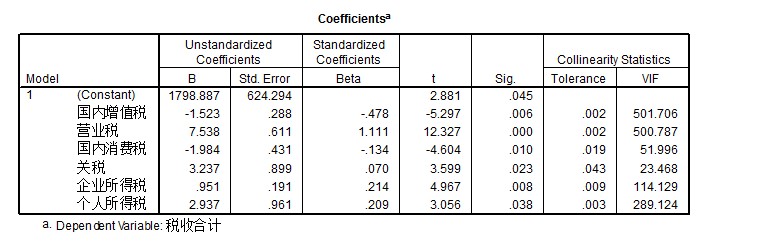
依据此表进行回归系数显著性检验。由表可知,如果显著性水平a为0.05,所有变量的回归系数显著性t检验的概率p值都小于显著水平a,因此这些偏回归系数与0有显著差异,它们与被解释变量税收合计的显性关系是较显著的,暂且全部保留在方程中。
4.多重共线性检测 图d*强制进入策略
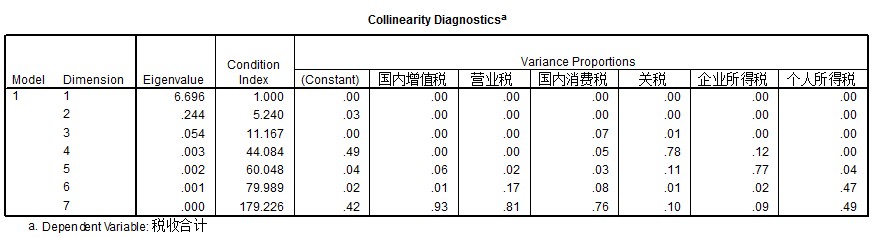
依据此表进行多重共线性检测。由图d可知,除1,2外,其余变量的条件指标均大于10,说明多重共线性严重;且由图c看出,所有变量的容忍度(Tolerance)都接近于0,方差膨胀因子(VIF)都远大于1,表示变量间的共线性很强,说明解释变量之间有严重的多重共线性。因此应重新建模,剔除一些相对不显著的解释变量。此处应用向前筛选策略,对变量进行选择,并进行残差分析和影响点检测。
5. 残差均值为0的正态分析 图1 *向前筛选策略
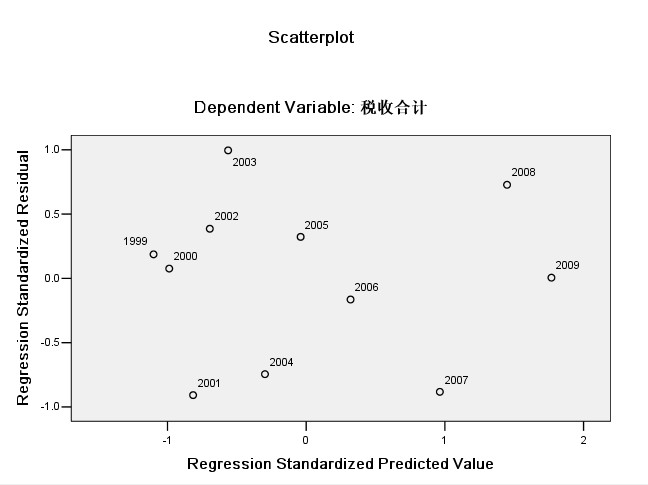
由图1可以看出,残差图中的点在纵坐标为0的上下随机散落着,残差的均值为0。
6.残差的独立性分析 图2 *向前筛选策略
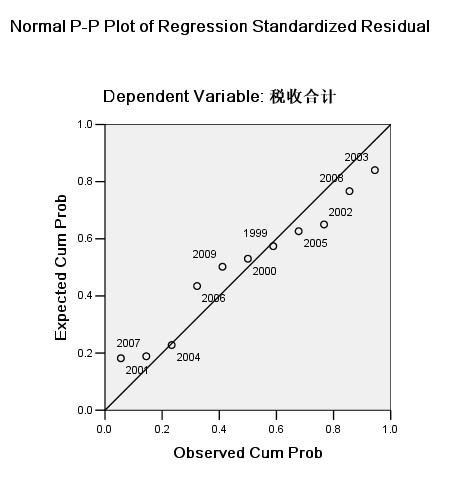
由图2可知,所有的观测值都接近于直线,表明标准化残差与正态分布不存在显著差异,即观测值符合正态分布,则残差满足了线性模型的前提要求。
7.DW分析 图3 *向前筛选策略
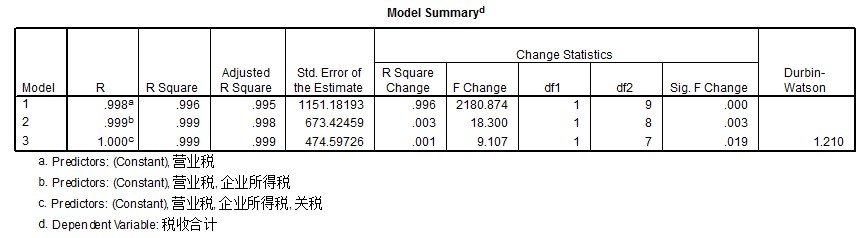
由图e可知,利用向前筛选策略共经过3步完成回归方程的建立,最终模型为第三个模型。依据解释变量对被解释变量税收合计的贡献强弱,依次选择保留营业税,企业所得税和关税,而其余变量(国内消费税,个人所得税,国内增值税)对税收合计的线性解释没有显著贡献,不应保留在模型中。方程的DW检验值为1.210,残差存在一定程度的正自相关。可能是一些与因变量相关的因素没有引入回归方程或回归模型不合适或滞后性周期性的影响。
图4 *向前筛选策略
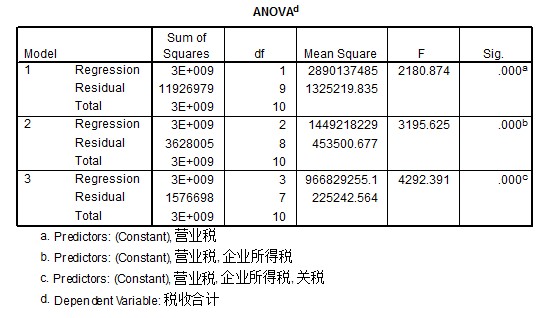
由图4可知,第三个方程是最终的方程。如果显著性水平a为0.05,由于回归方程显著性检验的概率p小于a,因此被解释变量税收合计与解释变量间的线性关系显著,建立线性模型是恰当的。
图5 *向前筛选策略

由图5所示,表中第四个模型是最终方程。由上面的分析知,营业税,企业所得税,国内消费税与税收合计的线性关系显著,它们应保留在模型中。最终的回归方程是:税收合计=-408.796+4.623营业税+1.033企业所得税+4.275国内消费税。
8.异差分析 图6 *向前筛选策略
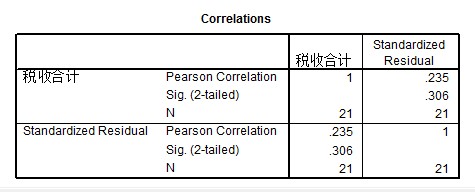
由图6可知,残差与预测值的Spearman等级相关系数为0.235,且因为p(0.306)>a(0.05)检验并不显著,因此认为异方差现象并不明显。
9. 检测样本的异常值和强影响点
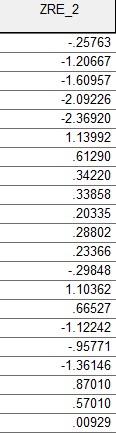
由上图数据编辑窗口中的异常值检验结果可知,所有的异常值的绝对值都小于3,所以在所有的观测值中,不存在异常值。
第二篇:统计学实验报告
实验目的:
1.熟悉SPSS相关分析的界面与操作;
2.熟悉SPSS回归分析的界面与操作;
3.准确解读SPSS相关和回归分析的输出结果。
实验设施设备:
硬件:计算机
软件: Excel,spss
实验过程(可附页):
习题8.2(P184)
下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据
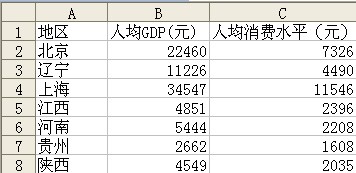
(1) 绘制散点图,并计算相关系数,说明二者之间的关系。
1、在Excel里输入数据。
2、点击【插入】,选择【图表】,选择【xy散点图】
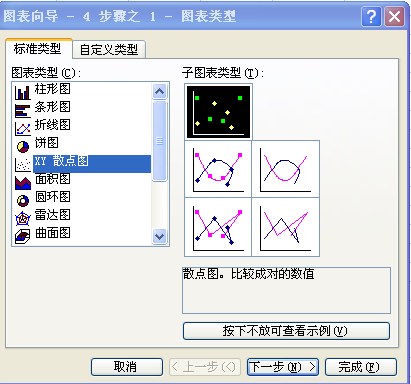
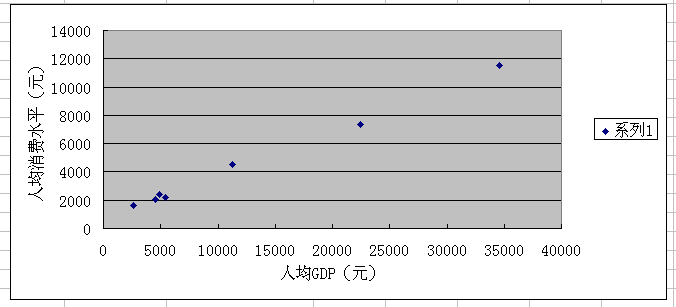
3、做出散点图,得到散点图如下图所示:
4、点击Excel中的【函数】——【CORRE L 】,将人均GDP数据选入Array1,将人均消费水平数据输入Array2.得到相关系数r=0.998127959.. 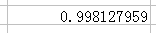

分析:从散点图可以看出,人均GDP和人均消费水平之间具有较强的正线性相关系。
有Excel中的【CORREL】函数计算的人均GDP和人均消费水平之间的相关系数为r=0.998127959.。由于相关系数为较大的正值,说明人均GDP和人均消费水平之间有较强的正线性相关关系,即人均GDP的增加,人均消费水平也随之增加。
(2) 以人均GDP作自变量,人均消费水平作因变量,利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。
1、选择【工具】下拉菜单,并选择【数据分析】选项。
2、在分析工具中选择【回归】,然后单击【确定】。
3、在对话框【Y值输入区域】方程内输入因变量y的数据区域(本例为“人均消费水平”);在【X值输入区域】方框内输入因变量x的数据区域(本例为“人均GDP”);在【置信度】选项中给出所需的数值(Excel的隐含值是95%);在【输出选项】中选择结果的输出位置,【残差】中选择所需的选项,单击【确定】。
输出结果如下:
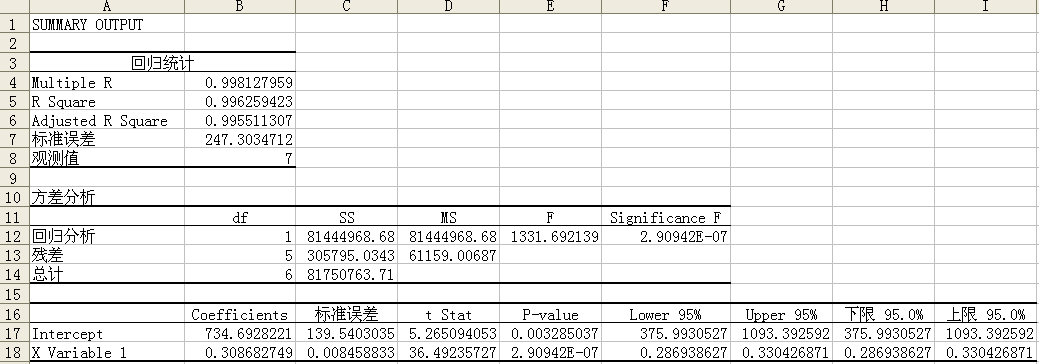
由上表可知,人均GDP与人均消费水平的估计方程为?=734.6928+0.3087x 。回归系数ß=0.3087表示:人均GDP每变动(增加或减少)1元,人均消费水平变动(增加或减少)0.3087元。
(3) 计算判定系数和估计标准误差,并解释其意义。
表一直接给出了判定系数(R Square,R²),R²=0.9963=99.63% 。其实际意义是:在人均消费水平取值的总变差中,有99.63%可以由人均消费水平与人均GDP之间的线性关系来解释,可见回归方程的拟合程度较高。
表一直接给出了标准误差,Sе=247.3035。其实际意义是:根据人均GDP来预测人均消费水平时,平均的预测误差为247.3035元。
(4) 检验回归方程线性关系的显著性(a=0.05)
1、 提出假设:H0;β1=0(两个变量之间的线性关系不显著)
H1;β1≠0(两个变量之间的线性关系显著)
2、 计算检验统计量F,表一直接给出了F值,F=1331.6921。
3、 做出决策。表一直接给出了P值,Significance F=2.90942E-07
(5) 如果某地区的人均GDP为5000元,预测其人均消费水平。
由上面计算可得回归方程为?=734.6928+0.3087x,可知人均消费水平?=734.6928+0.3087*5000=2278.1928
(6) 求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
1、在SPSS中输入原始数据。

2、选择AnalyzeRegression-linear。
3、在主对话框将人均消费水平选入Dependent,将人均GDP选入Independent。
4、点击Save。在Prediction Values 下选中 Unstandardized;在Predicted Values 下选中Mean和Individual;在Confidence Interval 中选95%的置信水平;在Residual 下选中Unstandardized和Standardized ;点击 Continue 回到主对话框。点击Ok。得如图所示:
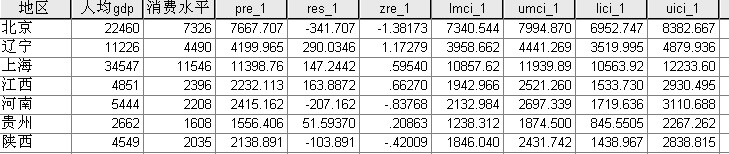
结论:当人均GDP为4851元是,从图中可以看出人均消费水平95%的置信区间为(1942.966,2521.260)预测区间为(1533.730,2930.495)
实验心得(可附页):
通过实验我又一次加深了对回归方程的理解,了解了回归方程中各个系数的分析判定。了解了回归方程在实际生活中的应用。
同时也知道了自己的不足,在接下来的学习中会更努力认真复习统计学的相关知识,提高自己的数据分析和处理能力。
实验效果(指导老师填写):