实验报告三
一、实验项目:均数间的比较
二、实验的目的:
运用SPSS软件进行均数间的比较。并能掌握运用SPSS软件的进行假设检验。
三、实验内容:
1、均值
2、单样本T检验
3、两独立样本T检验
4、配对样本T检验
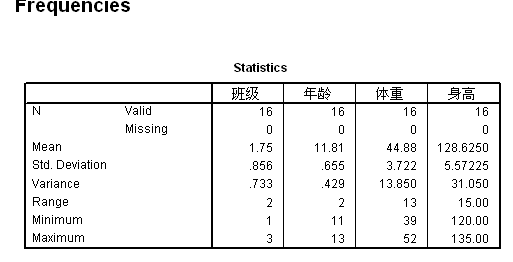
一、均值
1、均值表示一系列数据或统计总体的平均特征的值。
2、2010统计模拟实习资料\数据资料\数据集\第二章\2.12-城市空气质量分析\2.12-数据集\spss数据\兰州.sav


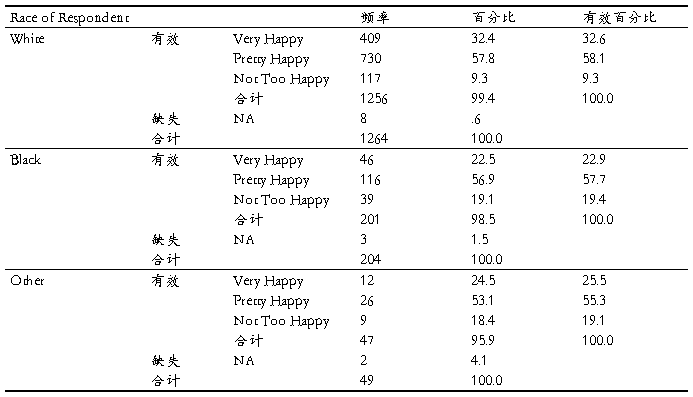
由上表可知,从20##-6-5到20##-10-3这2340天的污染指数均值为129.4462。
二、单样本T检验
1、单样本t检验是用样本均数代表的未知总体均数和已知总体均数进行比较,来观察此组样本与总体的差异性。
2、2010统计模拟实习资料\数据资料\数据集\第二章\2.12-城市空气质量分析\2.12-数据集\spss数据\兰州.sav


由spps软件分析兰州污染指数,原假设为污染指数=129.4462备择假设污染指数≠129.4462 ,由数据分析得p=0.000<0.05 故拒绝原假设,接受备择假设兰州污染指数不为129.4462。
三、两独立样本T检验
1、两独立样本T检验就是根据样本数据对两个样本来自的两独立总体的均值是否有显著差异进行推断。
2、案例数据资料\非参数检验(两独立样本-使用寿命).sav

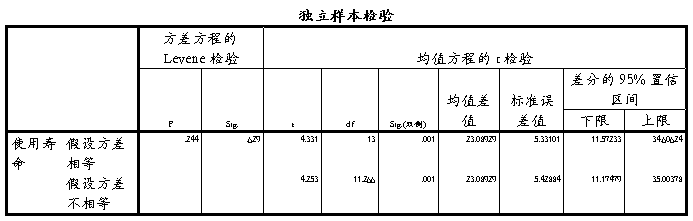
由spps软件分析独立检验两种工艺的使用寿命,原假设:甲、乙种工艺使用效果相同。备择选设:甲、乙种工艺使用效果不相同。由数据分析得F=0.244 故应假设方差相等成立。P=0.629>0.05 故接受原假设及甲、乙种工艺使用效果相同。
四、配对样本T检验
1、配对t检验是采用配对设计方法观察以下几种情形,1,两个同质受试对象分别接受两种不同的处理;2,同一受试对象接受两种不同的处理;3,同一受试对象处理前后。
…… …… 余下全文


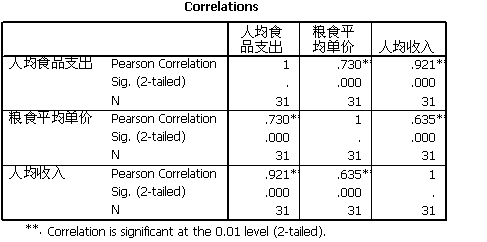
 b.在spssd的菜单栏中选择点击Analyze correlate Bivariate,
b.在spssd的菜单栏中选择点击Analyze correlate Bivariate,