多元统计分析期中论文
统计学
为了研究亚洲国家的经济发展和文化教育水平,以便于对亚洲国家进行分类研究,这里我们对亚洲国家进行聚类分析。
背景:20##年,随著金融危机的基本结束,亚洲经济进入了稳步增长的时期。尽管20##年亚洲经济通向全面复苏的道路仍不平坦,但可望继续保持回升态势,总体形势将进一步改观。对这个时间各国的经济情况进行分析,了解各国在金融危机后的恢复状况和处理经济危机的差异。
一、 进行数据收集和整理
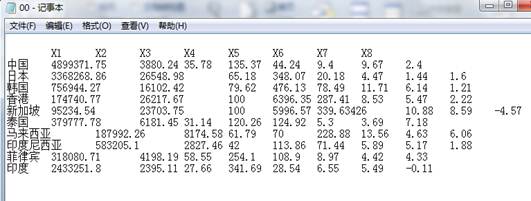
抽取中国、日本、韩国、香港、新加坡、泰国、马来西亚、印度尼西亚、菲律宾、印度这10个亚洲国家进行聚类分析:
X1:国民总收入
X2: 人均国民总收入
X3: 城市人口占总人口的比例
X4: 人口密度
X5:贸易(占GDP的比重)
X6:工业增加值年增长率
X7:服务业增加值年增长率
X8:农业增加值年增长率
实验原始数据如下(部分数据缺失用平均值代替)

二、 将数据复制粘贴到文本文档,命名为‘00’,存到我的文档下
三、 打开R软件,进行聚类分析
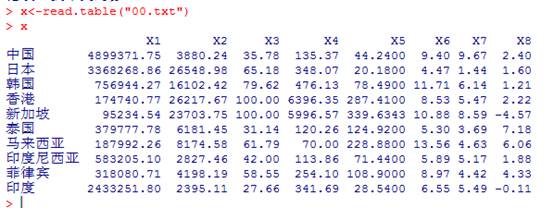
在命令框输入
x<-read.table("00.txt")
x
调用数据
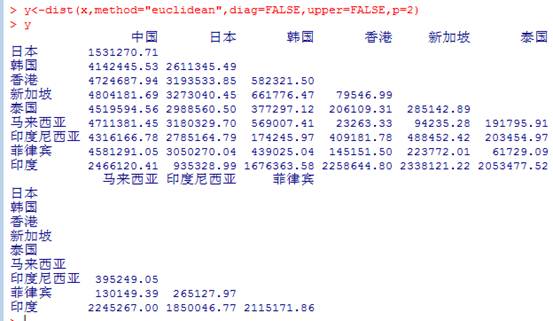
输入
y<-dist(x,method="euclidean",diag=FALSE,upper=FALSE,p=2)
y
计算距离
输入
m<-scale(x,center=TRUE,scale=TRUE)
m
进行距离的中心标准化

输入
n<-hclust(y,method="single")
n
使用最短距离法进行聚类分析

输入plot(n),得到聚类图
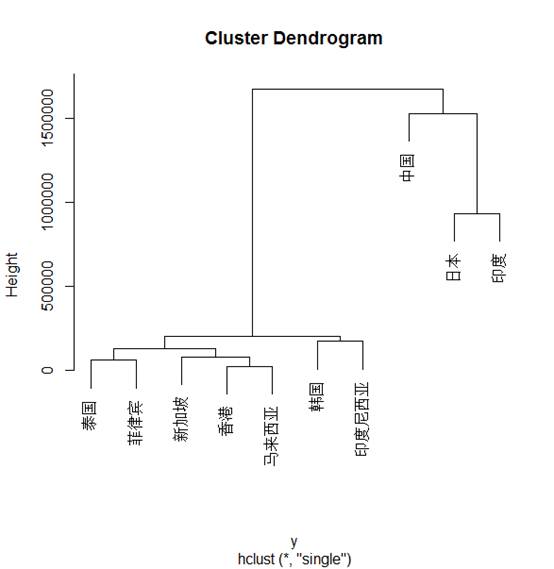
我们再次进行聚类,使用最长距离法

得到聚类图
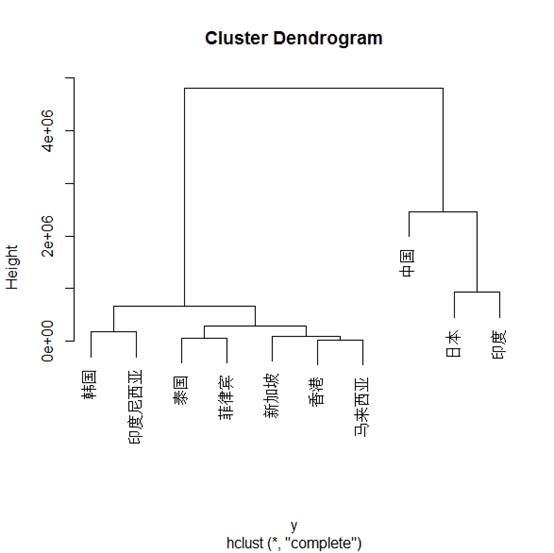
下面是使用类平均法得到的聚类图
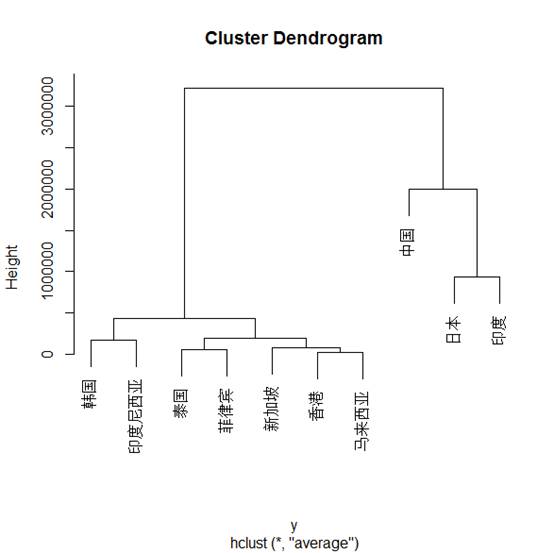
四、 结果分析
这是在1997亚洲金融危机两年后是个国家的经济状况,所有的聚类方法都得到了相同的结果——韩国、印度尼西亚、泰国、菲律宾、新加坡、香港、马来西亚为一类,中国、日本、印度为一类。
由这个分类可以看出金融风暴以后,中国收到的影响较小,日本和印度也很快的恢复了经济。但同时也暴露出了韩国、泰国、马来西亚等国家在处理经济危机的宏观政策上的不足。
第二篇:SPSS上机实验报告 聚类分析
 四川理工学院
四川理工学院
SPSS上机实验报告
课程名称:SPSS统计分析高级教程
专业班级:20##级统计2班
姓 名:雷鹏程
学 号:12071050109
指导教师:林旭东
实验日期: 20##年12月31日
实验名称:聚类分析-层次聚类法
一、实验案例
根据中、美、法等7个国家的裁判和未经过严格训练的体育爱好者对300次体操表演给出的评分的差异将他们分为适当的若干类,并对结果加以解释现希望根据,具体的数据见文件judges.sav。
二、实验预分析流程图

三、实验目的
3.1、掌握利用SPSS层次聚类法、K-均值法。
3.2、解释运行结果。
3.3、得出最终的实验结论
四、实验操作步骤和结果描述
4.1初步分析:
(1)选择“ ”→“
”→“ ” →“
” →“ ”菜单项。
”菜单项。
(2)将8个指标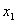 ~
~ 选人“
选人“ ”列表框。
”列表框。
(3)在“聚类”选项组中选择“ ”。
”。
(4)在“ ”中选中“
”中选中“ ”,点击“
”,点击“ ”。
”。
(4)点击“ok”。
得到如下表1:
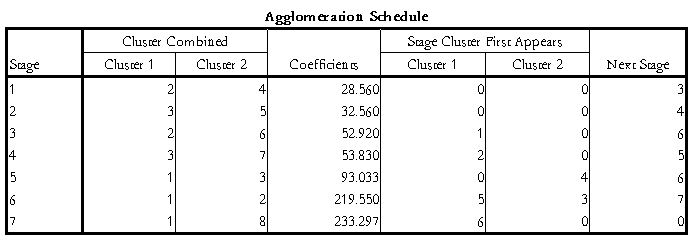
表1聚类表
* * * * * * * * * * * * * * * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * * * * * * * * * * * * * * *
Dendrogram using Average Linkage (Between Groups)
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25
Label Num +---------+---------+---------+---------+---------+
法官2 2 ─┬───┐
法官4 4 ─┘ ├─────────────────────────────────────────┐
法官6 6 ─────┘ │
法官3 3 ─┬─────┐ ├─┐
法官5 5 ─┘ ├───────┐ │ │
法官7 7 ───────┘ ├───────────────────────────────┘ │
法官1 1 ───────────────┘ │
法官8 8 ─────────────────────────────────────────────────┘
图1聚类树状图

图2聚类冰柱图
结果解释:由表1的聚类表可得,“Cluster Combined”列给出了在某一步骤中哪些对象会参与合并,可见第一步是变量2和变量4合并,第二步是变量3和变量5进行合并。以此类推,知道所有8个变量全部合并为一类。而在“Coefficients”列中是给出每一聚类步骤的系数,也就是表示被合并的两个类别之间的距离大小。随后的“Stage Cluster First Appears”列表示参与合并的对象最早在第几步出现,“0”表示该对象第一次出现在聚类过程中。
由树状图可以知道“体育爱好者(法官8)”首先被单独分出来,显然职业和非职业的评分水平就是不一样。职业裁判很明显的分为了两组,“美国、法国、韩国(法官2、4、6)”为一组;而“俄罗斯、中国、罗马尼亚、意大利(法官1、3、5、7)” 为一组,而且根据冰柱图也能得到树状图一样的结论。下面需要考虑结果的合理性,由树状图可以看出“体育爱好者”与“职业裁判”之间的评分的差异很小,这不符合一般的实际常理,所以需要对聚类的结果进行改进,下面是聚类的进阶分析。
4.2进阶分析:
4.2.1进阶预分析:
由上述的分析,考虑到本案例是进行变量的聚类,而变量之间距离的定义习惯用“Pearson”相关系数,所以聚类距离采用“Pearson相关系数”聚类。操作步骤如下:
(1)在“ ”对话框中选择“
”对话框中选择“ ”,点击“”。
”,点击“”。
(2)点击“ok”。
得到下表2:

表2“Pearson相关系数”距离计算法下的聚类表
* * * * * * * * * * * * * * * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * * * * * * * * * * * * * * *
Dendrogram using Average Linkage (Between Groups)
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25
Label Num +---------+---------+---------+---------+---------+
法官2 2 ─┬─┐
法官4 4 ─┘ ├─┐
法官6 6 ───┘ ├───┐
法官1 1 ─────┘ ├───────────────────────────────────────┐
法官3 3 ─┬─┐ │ │
法官7 7 ─┘ ├─────┘ │
法官5 5 ───┘ │
法官8 8 ─────────────────────────────────────────────────┘
图3“Pearson相关系数”距离计算法下的树状图

图4“Pearson相关系数”距离计算法下的冰柱图
结果解释:由图3树状图可得,“体育爱好者”仍然为一组,职业裁判也还是分为两组,然而这次“俄罗斯、罗马尼亚、中国”裁判为一组,然而另一组则由“美国、法国、意大利、韩国”裁判构成。由树状图这次看出来职业裁判和非职业的裁判之间的差异变大了,这样就符合现实的实际的情况了。在实际生活中肯定职业裁判的的评分肯定比非职业的评分更具有一定的权威性,所以这是比较合理的聚类情况,职业裁判得到分类也是合理的。
五、 实验总结
本次实验通过对案例预分析后,选定了解决案例的模型,通过在实验中步步对模型的优化与检验,找到了案例的最优的结果,对案例的问题进行了回答与解释。并且在本次SPSS上机实验让我对这门软件有了较深刻的认识,SPSS是一款菜单式的软件,操作简便,易于理,利用将有助于提高工作效率。利用SPSS进行统计分析,变量和数据是必不可少的。数据输入后通常需要对数据进行进一步的处理,其中最有价值的是数据的预处理以及问题预处理。