****数据库报表系统
Shareplex for Oracle测试报告
易虹天地电脑技术服务(北京)有限公司
二○○四年八月

1 测试目标
本次测试的主要目的是验证Quest SharePlex for Oracle能够满足项目数据库复制的以下需求,为未来的产品选型和实施工作提供依据。 划线( )的部分为具有次优先级的部分;未标注的部分为应正常满足的部分。
1.1 复制功能
? 支持对异构环境的复制;
? 对源系统影响小,所选择方案不得明显增加原有主中心主机系统或数据库系统或? 网络带宽占用少,所需网络带宽有限,在有限传输带宽上保证复制工作延迟小。 ? ? 影响,需报表数据可以在主中心暂时存放,当系统恢复后,暂存数据可自动完整复制到报表中心,数据完整性一致性不被破坏;
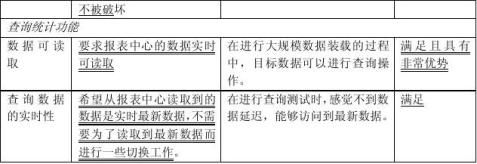
1.2 统计查询功能 ?
? 希望从报表中心读取到的数据是实时最新数据,不需要为了读取到最新数据而进
行一些切换工作;
- 2 -
1.3 测试环境
测试环境由以下两台主机构成:
ibm p670
dell 6600
? Primary System 1
Hardware:
IP:
OS:
Oracle:
Oracle SID
Shareplex ibm p670 10.1.3.20 aix 5.1 9.2.0.4 sptest 5.0
? Secondary System
Hardware:
IP:
OS:
Oracle:
Oracle SID
Shareplex dell 6600 10.1.1.65 redhat 2.1 9.2.0.4 sptest2 5.0
1.4 测试地点
测试工作安排在 太平人寿电脑部
1.5 人员安排
为了保证测试项目的成功,易虹天地电脑技术服务(北京)有限公司,都派出了专门的技术人员支持本次测试工作。项目各方参与人员密切配合、保证了测试工作的成功。相关人员安排如下:

- 3 -
1.6 测试安排
1.6.1 SharePlex解决方案介绍及讨论
所有参加测试人员及相关技术人员参与了SharePlex解决方案介绍及讨论工作。
? 由易虹工程师介绍SharePlex解决方案
? 对测试方案进行讨论和确认。就测试的目的、预期的结果达成共识。根据测试计
划的内容安排测试工作。
1.6.2 测试环境确认和准备
确认测试环境是否满足SharePlex的安装、配置和测试要求。根据check list的内容对Primary System和Secondary System进行全面检测。经过检测和比较,确认在安装前需要进行以下工作:
? 确认shareplex 安装目录,在本地磁盘上需要2GB空间以上,存储容灾队列 ? 将redo log文件放到本地磁盘,每个大小100M,数量3个,归档方式
? 在Primary System进行归档操作,归档日志放在本地磁盘
1.6.3 SharePlex产品安装
在测试机器上安装配置SharePlex for Oracle 5.0 。
1.6.4 实际测试
此次测试工作为SharePlex功能测试,不包含数据初始化同步。
1.6.5 实际环境报表方案讨论
针对需要报表的实际环境,讨论未来可能的配置方案:
? 讨论配置方案,论证方案的可行性。
? 检查系统环境,确定SharePlex是否满足需求
? 提出在维护工作中需要注意的问题。
- 4 -
1.6.6 测试报告
根据上述工作内容提交测试报告。
- 5 -
2 测试内容
2.1 复制功能测试
2.1.1 测试准备 2.1.1.1 建立测试表
由shareplex安装程序建立,作为源数据表,在除高可用性测试的其他所有测试环境中使用。

作为目标数据表,由shareplex安装程序建立,在除高可用性测试的其他所有测试环境中使用。

2.1.1.2 建立配置文件
datasource:o.sptest
splex.demo_src splex.demo_src weblogic72@o. sptest
主数据库实例名sptest
其中weblogic72是linux报表主机的主机名,报表数据库的实例名是sptest。
- 6 -
2.1.1.3 建立复制环境
主系统:SysA
报表系统:SysB
(1)启动SysA上的和SysB上的SharePlex
sp_cop &
(2)启动控制台
sp_ctrl
(3)在SysA中激活config文件
sp_ctrl>activate config testeglobal2
(4)检查SysA和SysB测试表中的记录
SQL>select * from splex.demo_src;
SQL>select * from splex.demo_src;
2.1.2 基本功能测试
2.1.2.1 测试目的
? 验证SharePlex可以复制所有的DML操作,如插入、修改、删除等等。
? 验证SharePlex可以支持很多DDL操作,如truncate,alter table。
2.1.2.2 测试步骤
(1)复制DML语句:在SysA上做INSERT、UPDATE和DELETE操作,检查SysB对应
的表。
SQL>Insert into splex.demo_src values (‘1’,’11’,’111’);
SQL>Update splex.demo_src set address = ‘22’ where name = ’1’;
SQL>Delete from splex.demo_src where name = ’1’;
(2)复制DDL语句:在SysA上做TRUNCATE TABLE操作,检查SysB对应的表。
SQL>Truncate splex.demo_src
SQL>alter table demo_src add(id number(10));
- 7 -
2.1.2.3 预期结果
? SharePlex可以复制所有的DML操作,如插入、修改、删除等等。
? SharePlex可以支持的DDL操作,如truncate,alter table。
2.1.2.4 实际结果及评价
达到预期结果。
2.1.3 性能测试
2.1.3.1 测试目的
验证SharePlex支持大量事务的复制操作。
2.1.3.2 测试步骤
? 先在SysA运行SQL语句A> 运行procedure,插入10万条记录
Commit;
? 验证在语句B运行后,SharePlex将数据复制到SysB。运行查询命令,记录数据行
数,确认数据已经成功复制而且复制行数相同。
select count(*) from demo_src;
2.1.3.3 预期结果
在Primary System中对SharePlex一个表进行大数据量插入,能够很快复制到Secondary System ,数据延迟非常小。
2.1.3.4 实际结果及评价 达到预期结果。在Primary System大量记录后,在Secondary System中马上可以查询到相关记录。感觉不到数据延迟。
- 8 -
2.1.4 查询功能测试
2.1.4.1 测试目的
验证在复制过程中,对目标数据库可以进行查询操作。
2.1.4.2 测试步骤
在SysA运行批量加载记录:在运行过程中在SysB上进行查询操作。
select count(*) from demo_src;
2.1.4.3 预期结果
验证在Primary System中向Secondary System中进行复制时,可以对目标数据库进行查询操作。
2.1.4.4 实际结果及评价
达到预期效果。
2.1.5 可靠性测试
2.1.5.1 测试目的
? 验证在Secondary System 中SharePlex毁坏不影响复制功能。
? 验证在Primary System中SharePlex毁坏不影响复制功能。
? 验证在Primary System或Secondary System中SharePlex毁坏且此时复制事务已归
档至archive日志中不影响复制功能
? 验证当灾备系统网络中断,当网络恢复Shareplex不影响复制
2.1.5.2 测试步骤
(1)验证在SysB 中关闭SharePlex 进程,数据库和SysA中的SharePlex正常进行操作,
当SysB重新启动后,SharePlex能保证复制工作继续正常进行。
- 9 -
? 在SysB关闭shareplex
sp_ctrl>shutdown
? 在SysA插入数据
SQL>Insert into splex.demo_src values (‘2,’22’,’222’);
? 在SysA检查export队列
sp_ctrl>qstauts
? 在SysB 中检查表中的数据
SysB>select count(*) from demo_src;
? 在SysB启动SharePlex
SysB>startup
? Test the queues on both systems
SysA>qtatus
SysB>qstatus
? Test the table on Secondary System
SysB>select count(*) from demo_src;
(2)验证在SysA中SharePlex毁坏的情况下,当SharePlex重新启动后(事务记载在Redo Log文件中),可以继续进行复制工作。
? stop capture on SysA
SysA>stop capture
? DML on SysA
SysA> SQL>Insert into splex.demo_src values (‘3,’333’,’333’);
>commit
? start capture on SysA
SysA>start capture
? check the results on SysB
SysB>select count(*) from demo_src;
(3)验证在SysA中SharePlex毁坏的情况下,当SharePlex重新启动后(事务已经归档到Archive Log文件中),可以继续进行复制工作。
? stop capture on SysA
SysA>stop capture
- 10 -
? switch online redo log file
alter system switch logfile;
? DML on SysA
SysA> SQL>Insert into splex.demo_src values (‘3,’333’,’333’);
commit
? switch online redo log files until the DML operations enters into the archive log files alter system switch logfile; ( several times to make the current log be archived )
? start capture on SysA
SysA>start capture
? check the results on SysB
SysB>select count(*) from demo_src;
(4) 验证在SysA中SharePlex正常运行的情况下,当断开与灾备系统连接的网线,可以继续进行复制工作。
? shutdown SysB
? DML on SysA
SysA> SQL>Insert into splex.demo_src values (‘3,’333’,’333’);
>commit
restart Sysb
SysB>select count(*) from demo_src;
2.1.5.3 预期结果
? 验证在Secondary System 中SharePlex毁坏的情况下,在Primary System中插入数
据,当Secondary System 中SharePlex 进程重新启动后,数据可以继续复制到Secondary System。
? 验证在Primary System中SharePlex毁坏的情况下,当SharePlex重新启动后(事
务记载在Redo Log文件中),可以继续进行复制工作。
? 验证在Primary System中SharePlex毁坏的情况下,当SharePlex重新启动后(事
务已经归档到Archive Log文件中),,可以继续进行复制工作。
? 验证当灾备系统网络中断,当网络恢复Shareplex不影响复制
- 11 -
2.1.5.4 实际结果及评价
达到预期效果。在Primary System和Secondary System 停止SharePlex,当SharePlex重新启动后,复制工作可以自动继续进行。
3 测试结论
报表系统测试工作由易虹、太平人寿共同完成。 针对测试目标
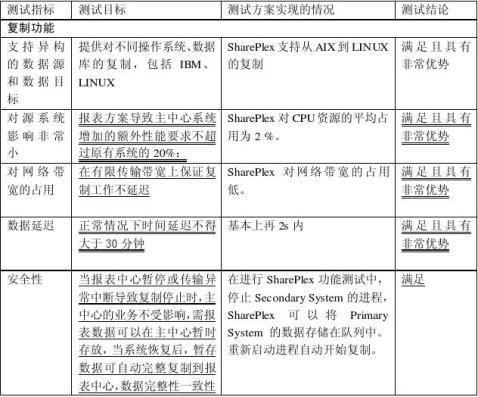
重要用 一般无标识
满足用 标识 不满足无标识
针对测试结论
- 12 -
- 13 -
第二篇:Oracle RAC 测试报告
技 术 文 件
技术文件名称:Oracle RAC测试报告 技术文件编号:
版 本:V1.0
共 19 页
(包括封面)
拟 制 审 核 会 签 标准化 批 准
深圳市中兴通讯股份有限公司

ORACLE RAC测试报告
目 录
1
2
2.1
2.2 测试目的 ............................................................................................................................... 2 术语、定义和缩略语 ........................................................................................................... 2 术语、定义 ............................................................................................................................. 2 缩略语 ..................................................................................................................................... 2 3
4
4.1 测试环境描述 ....................................................................................................................... 2 测试过程描述 ....................................................................................................................... 3 性能测试 ................................................................................................................................. 3
两台B80组成的单、双节点RAC性能测试............................................................... 3
两台P630组成的单、双节点RAC性能测试 ............................................................. 3 两台B80和一台P630组成的三节点RAC性能测试 ................................................ 3 4.1.1 4.1.2 4.1.3
4.2 功能测试 ................................................................................................................................. 4
4.2.1 RMAN备份和恢复测试 .................................................................................................... 4
4.2.2 exp备份和imp恢复测试 .................................................................................................. 4
4.2.3
4.2.4
4.2.5 正常呼叫时,smap界面对数据的大批量查询和修改。 ............................................ 4 正常呼叫时,后台cron任务对数据的大批量查询和修改。 ..................................... 5 大事务测试 ..................................................................................................................... 5
4.2.6 load balance测试 ................................................................................................................ 5
4.2.7 connetc-time failover的测试 .............................................................................................. 6
4.2.8 TAF测试 ............................................................................................................................. 6
4.3 稳定性测试 ............................................................................................................................. 7
模拟呼叫,保持24小时 ............................................................................................... 7
网线异常对实例的影响 ................................................................................................. 7
第二实例启动对第一实例的影响 ............................................................................... 10
第二实例正常关闭对第一实例的影响 ....................................................................... 11
第二实例异常关闭对第一实例的影响 ....................................................................... 11 第二实例所在机器异常关闭对第一实例的影响 ....................................................... 15 4.3.1 4.3.2 4.4 4.4.1 4.4.2 4.4.3 4.4.4 第二节点对第一实例的影响 ................................................................................................ 10
5
5.1 测试总结 ............................................................................................................................. 17 测试中发现问题的说明........................................................................................................ 17 6
获得的技术支持 ................................................................................................................. 18
Oracle RAC测试报告
1 测试目的
测试目的,在于验证多节点RAC的可用性、稳定性,以及多节点RAC相对于普通的Oracle环境性能的提升情况
2 术语、定义和缩略语
2.1 术语、定义
无。
2.2 缩略语
本文件应用了以下缩略语:
RAC Real Application Cluster
Caps Call per Second
Oracle公司数据库集群软件 智能网名词,指每秒处理的呼叫数
3 测试环境描述
本次测试,由4台IBM小型机(2台B80、2台P630)搭建了一个内部网络,组成4节点的RAC环境,网络内的各个节点通过10/100M网卡相互访问,包括RAC节点间的heart beat信息;RAC数据库以裸设备方式建在共享磁阵上,各节点通过光纤交换机访问磁阵;呼叫测试时,各节点上的智能网应用,则通过光纤交换机与模拟呼叫仪进行通讯。
硬件信息:
小型机:IBM B80 2台,每台2颗450M主频的POWER3 CPU 和1G内存
小型机:IBM P630 2台,每台 2颗1.2G主频的POWER4 CPU;2G内存
存储:StorageTek的D240磁阵,6块72G的硬盘,其中4块做RAID 0+1,2块为HOT SPARE 光纤交换机:2台,型号为IBM 3534-F08
模拟呼叫仪:INET、MGTS
软件信息:
操作系统:IBM AIX 5.2 补丁级别 02
双机软件:IBM HACMP V5.1 补丁级别04
RAC版本:Oracle 9.2.0.5.0
智能网平台版本:V3.50.05.06_0_2004/08/23 业务版本:IIN-GSM_PPSV2.01.01@V3.50
Oracle RAC测试报告
4 测试过程描述
本次RAC的测试,主要是分成三个阶段,第一是RAC的性能测试,第二个阶段,则主要是针对在性能测试中发现问题的处理,第三个阶段是RAC的功能测试、稳定性测试。
4.1 性能测试
由于受到模拟呼叫仪处理能力的限制,在性能测试过程中,4节点的RAC中并没有所有节点都同时使用的情况,大部分情况是启动其中的2个instance,相当于两节点的RAC。测试前提:
1. 智能网应用与Oracle的instance同时在同一台主机上运行
2. 智能网的数据库连接为指定连到本机的instance,没有做load balance和failover
3. 测试时业务表s1cardinf的记录数为32万
4. 双节点时测试时,每个节点上的应用分别处理不同的号段,无交叉现象
4.1.1 两台B80组成的单、双节点RAC性能测试
测试目的:
测试在B80上,两节点的RAC相对于单机方式的性能提高情况
测试步骤:
1. 启动一台机器上的oracle instance和智能网应用
2. 根据应用的处理情况逐步提供呼叫仪的呼叫数,直到应用无法及时处理
3. 同时启动两台机器上的oracle instance和智能网应用
4. 根据应用的处理情况逐步提供呼叫仪的呼叫数,直到应用无法及时处理
测试结果:
单实例方式下,应用的最大呼叫处理能力可达到140caps,此时CPU达到100%, 而应用出现消息积压的情况;双节点方式下,每个节点应用的最大处理能力为140caps。
4.1.2 两台P630组成的单、双节点RAC性能测试
测试目的:
测试在P630上,两节点的RAC相对于单机方式的性能提高情况
测试步骤:
1. 动一台机器上的oracle instance和智能网应用
2. 根据应用的处理情况逐步提供呼叫仪的呼叫数,直到应用无法及时处理
3. 同时启动两台机器上的oracle instance和智能网应用
4. 根据应用的处理情况逐步提供呼叫仪的呼叫数,直到应用无法及时处理
测试结果:
单实例方式下,应用的最大呼叫处理能力可达到210caps,此时CPU达到100%, 而应用出现消息积压的情况;双节点方式下,每个节点应用的最大处理能力为210caps。
4.1.3 两台B80和一台P630组成的三节点RAC性能测试
测试目的:
测试三节点的RAC的性能情况
测试步骤:
1. 同时启动两台B90和一台P630上的oracle instance和智能网应用
2. 根据应用的处理情况逐步提供呼叫仪的呼叫数,直到应用无法及时处理
Oracle RAC测试报告
测试结果:
最终的处理结果是两台B80上的最大呼叫能力为140caps,当时CPU为100%,出 现消息积压情况;而受制于呼叫仪的处理能力,P630上达到160caps,而cpu占有率为 81%,消息处理正常。
4.2 功能测试
4.2.1 RMAN备份和恢复测试
测试目的:
测试RMAN的备份
测试步骤:
1. 使用rman,执行语句,进行整个数据库的备份
2. 使用rman,执行语句,备份归档日志
测试结果:
按照预期的结果,生成了备份文件。
测试目的:
测试RMAN的恢复
测试步骤:
1. 使用dd破坏控制文件的设备/dev/rrcontrol1,使用RMAN恢复
2. 删除表空间zxin_data,利用之前的备份,使用RMAN恢复
测试结果:
对于删除control file的测试,恢复失败,因为使用的是rman nocatalog 进行的备份,在nocatalog方式下,备份信息是存放在control file中的,现在control file损坏,无法通过rman进行恢复;oracle建议在使用nocatalog方式备份时需将control file和spfile单独使用操作系统命令进行备份。后者的表空间恢复正常。
4.2.2 exp备份和imp恢复测试
测试目的:
验证exp/imp 进行数据库的备份和恢复
测试步骤:
1. 使用exp进行整库备份
2. 删除用户zxin,使用imp恢复
3. 删除表空间zxin_data,使用imp恢复
测试结果:
exp备份正常,恢复测试同样没有问题。
4.2.3 正常呼叫时,smap界面对数据的大批量查询和修改。
测试前提:
节点zxin1和zxin2上正常处理呼叫,呼叫量均为100caps
测试步骤:
1. 查询某卡号段的信息
2. 另外同时通过sqlplus,按照卡号段查询s1cardinf信息
测试结果:
Oracle RAC测试报告
由于只使用了一个smap界面程序操作,因此看不出影响。
4.2.4 正常呼叫时,后台cron任务对数据的大批量查询和修改。
测试前提:
节点zxin1和zxin2上正常处理呼叫,呼叫量均为100caps
测试步骤:
1. 利用shell通过sqlplus,按照卡号段循环查询s1cardinf信息
2. 通过sqlplus修改s1cardinf信息,按照卡号段循环update s1cardinf信息 测试结果:
后台对同一个表的连续的大数据查询、修改,对呼叫影响很大,查询时cpu占有率上升了5%,如有多个同时运行的话,消息处理积压的现象将会非常明显。
4.2.5 大事务测试
测试目的:
测试在异常情况下数据的一致性、完整性
测试步骤:
在节点zxin1和zxin2上同时运行同一事务批量修改数据,数据有交叉 测试结果:
多次测试,数据更新正常。
测试步骤:
1. 在节点zxin1和zxin2上同时运行同一事务,在zxin2回滚事务
2. 在节点zxin1和zxin2上同时运行同一事务,在zxin2 kill该session
测试结果:
测试结果正常,未见数据异常。
测试步骤:
在节点zxin1和zxin2上同时运行模拟程序,通过sqlplus连到数据库,批量更新数据,然后退出重连;此过程循环一晚
测试结果:
根据处理的日志看,操作正常。
4.2.6 load balance测试
测试目的:
验证oracle的负载均衡功能
测试前提:
1. 在zxin1、zxin2上启动实例
2. 修改zxin2上tnsnames.ora,启用load balance
测试步骤:
1. 在zxin2上运行zxstart,建立SDF连接
2. 利用测试程序,每隔几秒通过sqlplus建立10个连接
测试结果:
zxstart多次测试的结果,12个SDF连接基本是平均分布,有时则是5个在zxin1
Oracle RAC测试报告
上,7个在zxin2上;而手工建立的sqlplus连接,则是完全平均分布的。
4.2.7 connetc-time failover的测试
测试目的:
验证在客户端连接时的failover功能
测试前提:
1. 启动zxin1、zxin2上的实例
2. 关闭zxin2的listener,zxin1机器上的listener正常
3. 实例zxin2上的tnsnames.ora中配置Address List=
(ADDRESS = (PROTOCOL = TCP)(HOST = zxin2)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = zxin1)(PORT = 1521))
测试步骤:
1. 在zxin2上启动zxstart
2. 利用测试程序,在zxin2上每隔几秒通过sqlplus建立10个连接
测试结果:
两种方式下,数据库连接都在zxin1实例上
4.2.8 TAF测试
测试目的:
验证Transparent Application Failover功能及切换时间
测试前提:
1. 实例zxin1、zxin2正常运行,listener正常
2. 实例zxin2启用Failover功能
3. 主机zxin1、zxin2上的时间一致
测试步骤:
1. Zxin2上运行zxstart,启动平台程序
2. 启动模拟程序,不停通过sqlplus连接zxin2,记录无法连接zxin2实例的时间
3. 通过正常、异常关闭zxin2实例,异常关闭zxin2主机进行测试
4. 在zxin1上查看v$session中各SDF连接及logon_time
测试结果:
zxin2实例在正常、异常关闭或者zxin2主机被异常关闭之后,所有连到实例zxin2的数据库连接自动切换到了zxin1,但是数据库连接的切换时间每次都不太一样,从8秒到59秒不等,维持在1分钟之内。
测试目的:
测试正常呼叫情况下TAF的切换时间
测试前提:
1. 实例zxin1、zxin2正常运行,listener正常
2. 实例zxin2启用Failover功能
3. 主机zxin1、zxin2上的时间一致
测试步骤:
1. zxin2上运行zxstart,启动平台程序,有100caps的呼叫处理
2. 启动模拟程序,不停通过sqlplus连接zxin2,记录无法连接zxin2实例的时间
3. 通过正常、异常关闭zxin2实例,异常关闭zxin2主机进行测试
Oracle RAC测试报告
4. 在zxin1上查看v$session中各SDF连接及logon_time
测试结果:
zxin2实例在正常、异常关闭或者zxin2主机被异常关闭之后,所有连到实例zxin2的数据库连接自动切换到了zxin1,而且切换时间非常快,很多情况下都在1-2秒左右,没有超过10秒的,可能跟呼叫有关,在有操作的情况下,zxin1实例能够更快的获取zxin2实例down的情况,从而更快的切换。
4.3 稳定性测试
4.3.1 模拟呼叫,保持24小时
测试目的:
测试RAC在长时间的呼叫处理下是否正常
测试步骤:
1. 在节点zxin1、zxin2上启动数据库
2. 在节点zxin1、zxin2上分别启动平台程序,接受呼叫
3. 模拟呼叫仪接入,模拟100caps的呼叫量,连续呼叫24小时
测试结果:
系统运行正常,数据库访问正常,业务处理正常。
4.3.2 网线异常对实例的影响
测试目的:
测试公网ip异常对RAC的影响
测试步骤:
1. 实例zxin1、zxin2启动,在zxin2上启动平台程序
2. 使用ifconfig en1 192.1.1.102 delete 删除public ip
3. 拔掉zxin2上public网线
测试结果:
zxin2上建立的到数据库实例zxin2的SDF连接,进行failover,切换到zxin1上,客户端无法以zx192_1_1_102这个connect string连到实例zxin2。待到重新加入ip 或者插上网线之后,恢复正常。
测试步骤:
测试私网ip异常对RAC的影响
测试步骤:
1. 实例zxin1、zxin2启动,在zxin2上启动平台程序
2. 使用ifconfig en0 10.1.1.102 delete 删除private ip
3. 拔掉zxin2上用于RAC节点间通讯的private网线
测试结果:
无论是删除ip还是拔掉网线,对于Oracle来说,效果一样。以其中一次测试的过程为例:大概在11:03拔掉网线,然后在oracle日志显示,在实例zxin1、zxin2分别在11:09 和11:08:45进行Communication recofiguration,zxin1等待split-brain resolution;10分钟之后,11:19分,实例zxin2 down下来,zxin1实例恢复正常。在多次测试的结果中,发现在拔掉网线到实例进行communication重组之间、和实例等待split-brain resolution的过程中,除了有一次能够通过访问zxin1而不能访问zxin2外,其他几次都无法通过sqlplus访问
Oracle RAC测试报告
zxin1、zxin2,而且这两个阶段的时间都固定为5分钟跟10分钟。
后来,发现第二个阶段等待split-brain的时间跟数据库中参数的设置有关,修改参数_imr_splitbrain_res_wait为60秒后,等待时间由10分钟缩短为1分钟;但是,comminucation重组之前的超时判断无法缩短,可能跟tcp有关,修改了rto_high等几个参数设置后,时间依然为5分钟左右,没有改变。下附oracle日志
alert_zxin1.log:
Fri Nov 19 11:09:00 2004
Communications reconfiguration: instance 1
Waiting for clusterware split-brain resolution
Fri Nov 19 11:09:30 2004
Trace dumping is performing id=[41119110900]
Fri Nov 19 11:19:02 2004
Evicting instance 2 from cluster
Fri Nov 19 11:19:06 2004
Reconfiguration started
List of nodes: 0,
Fri Nov 19 11:19:06 2004
Reconfiguration started
List of nodes: 0,
Nested/batched reconfiguration detected.
Global Resource Directory frozen
one node partition
Communication channels reestablished
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
Resources and enqueues cleaned out
Resources remastered 732
861 GCS shadows traversed, 0 cancelled, 0 closed
418 GCS resources traversed, 0 cancelled
set master node info
Submitted all remote-enqueue requests
Update rdomain variables
Dwn-cvts replayed, VALBLKs dubious
All grantable enqueues granted
861 GCS shadows traversed, 0 replayed, 0 unopened
Submitted all GCS remote-cache requests
0 write requests issued in 861 GCS resources
0 PIs marked suspect, 0 flush PI msgs
Fri Nov 19 11:19:07 2004
Reconfiguration complete
Post SMON to start 1st pass IR
Fri Nov 19 11:19:07 2004
Instance recovery: looking for dead threads
Fri Nov 19 11:19:07 2004
Oracle RAC测试报告
Beginning instance recovery of 1 threads
Fri Nov 19 11:19:07 2004
Started redo scan
Fri Nov 19 11:19:07 2004
Completed redo scan
246 redo blocks read, 42 data blocks need recovery
Fri Nov 19 11:19:07 2004
Started recovery at
Thread 2: logseq 1032, block 3, scn 0.0
Recovery of Online Redo Log: Thread 2 Group 4 Seq 1032 Reading mem 0 Mem# 0 errs 0: /dev/rredolog2_2
Fri Nov 19 11:19:07 2004
Completed redo application
Fri Nov 19 11:19:07 2004
Ended recovery at
Thread 2: logseq 1032, block 249, scn 0.533566592
13 data blocks read, 42 data blocks written, 246 redo blocks read Ending instance recovery of 1 threads
SMON: about to recover undo segment 11
SMON: mark undo segment 11 as available
SMON: about to recover undo segment 12
SMON: mark undo segment 12 as available
SMON: about to recover undo segment 13
SMON: mark undo segment 13 as available
SMON: about to recover undo segment 14
SMON: mark undo segment 14 as available
SMON: about to recover undo segment 15
SMON: mark undo segment 15 as available
SMON: about to recover undo segment 16
SMON: mark undo segment 16 as available
SMON: about to recover undo segment 17
SMON: mark undo segment 17 as available
SMON: about to recover undo segment 18
SMON: mark undo segment 18 as available
SMON: about to recover undo segment 19
SMON: mark undo segment 19 as available
SMON: about to recover undo segment 20
SMON: mark undo segment 20 as available
alert_zxin2.log
Fri Nov 19 11:08:45 2004
Communications reconfiguration: instance 0
Fri Nov 19 11:09:02 2004
Waiting for clusterware split-brain resolution
Oracle RAC测试报告
Fri Nov 19 11:09:15 2004
Trace dumping is performing id=[41119110845]
Fri Nov 19 11:19:02 2004
Errors in file /oracle/admin/zxin/bdump/zxin2_lmon_479324.trc:
ORA-29740: evicted by member 1, group incarnation 3
Fri Nov 19 11:19:02 2004
LMON: terminating instance due to error 29740
Instance terminated by LMON, pid = 479324
4.4 第二节点对第一实例的影响
4.4.1 第二实例启动对第一实例的影响
测试前提:
zxin1上oracle 实例和平台程序已经启动,无呼叫接入
测试步骤:
正常启动zxin2上的实例(startup)
测试结果:
第二实例的启动,对于第一实例的影响仅在重组的时候,重组时间基本上在1秒之内;智能网应用日志zxcom.log内,未发现sdf异常记录。日志如alert_zxin1.log所示:
Fri Nov 11 19:24:09 2004
Reconfiguration started
List of nodes: 0,1,
Global Resource Directory frozen
Communication channels reestablished
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
Resources and enqueues cleaned out
Resources remastered 942
1394 GCS shadows traversed, 0 cancelled, 58 closed
1336 GCS resources traversed, 0 cancelled
39342 GCS resources on freelist, 39981 on array, 39981 allocated
set master node info
Submitted all remote-enqueue requests
Update rdomain variables
Dwn-cvts replayed, VALBLKs dubious
All grantable enqueues granted
1394 GCS shadows traversed, 697 replayed, 58 unopened
Submitted all GCS remote-cache requests
0 write requests issued in 639 GCS resources
0 PIs marked suspect, 0 flush PI msgs
Fri Nov 11 19:24:10 2004
Reconfiguration complete
Post SMON to start 1st pass IR
Fri Nov 11 19:24:10 2004
Oracle RAC测试报告
Instance recovery: looking for dead threads
Instance recovery: lock domain invalid but no dead threads
测试前提:
zxin1上oracle 实例和平台程序已经启动,正常呼叫,100caps
测试步骤:
启动zxin2上的oracle实例(startup)
测试结果:
在zxin1进行呼叫处理的情况下,zxin2实例的启动,对于实例zxin1没有太大影响,重组时间1秒内完成,从呼叫仪那边看,在重组的过程中,有从10到80不等的呼叫断开,受到影响
4.4.2 第二实例正常关闭对第一实例的影响
测试前提:
1. zxin1上oracle 实例和平台程序已经启动,无呼叫接入
2. zxin2上oracle 实例和平台程序已经启动,无呼叫接入
测试步骤:
正常关闭zxin2上的实例(shutdown immediate)
测试结果:
第二实例的正常关闭,对于第一实例的影响仅在重组的时候,时间在1秒之内
测试前提:
1. zxin1上oracle 实例和平台程序已经启动,正常呼叫,100caps
2. zxin2上oracle 实例已启动
测试步骤:
正常关闭zxin2上的实例(shutdown immediate)
测试结果:
在zxin1进行呼叫处理的情况下,zxin2实例的正常关闭,对于实例zxin1没有太大影响,重组时间1秒内完成,从呼叫仪那边看,有80以内的呼叫断开,受到影响
4.4.3 第二实例异常关闭对第一实例的影响
测试前提:
1. zxin1上oracle 实例和平台程序已经启动,无呼叫接入
2. zxin2上oracle 实例和平台程序已经启动,无呼叫接入
测试步骤:
异常关闭zxin2上的实例(shutdown abort)
测试结果:
第二实例的异常关闭后,第一实例进行资源重组和实例恢复,总时间在1秒左右 日志如alert_zxin1.log所示:
Thu Nov 11 19:42:26 2004
Reconfiguration started
List of nodes: 0,
Global Resource Directory frozen
Oracle RAC测试报告
one node partition
Communication channels reestablished
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
Resources and enqueues cleaned out
Resources remastered 917
1215 GCS shadows traversed, 0 cancelled, 53 closed
609 GCS resources traversed, 0 cancelled
39406 GCS resources on freelist, 39981 on array, 39981 allocated set master node info
Submitted all remote-enqueue requests
Update rdomain variables
Dwn-cvts replayed, VALBLKs dubious
All grantable enqueues granted
1215 GCS shadows traversed, 0 replayed, 53 unopened
Submitted all GCS remote-cache requests
0 write requests issued in 1162 GCS resources
0 PIs marked suspect, 0 flush PI msgs
Thu Nov 11 19:42:26 2004
Reconfiguration complete
Post SMON to start 1st pass IR
Thu Nov 11 19:42:26 2004
Instance recovery: looking for dead threads
Thu Nov 11 19:42:26 2004
Beginning instance recovery of 1 threads
Thu Nov 11 19:42:26 2004
Started redo scan
Thu Nov 11 19:42:26 2004
Completed redo scan
114 redo blocks read, 51 data blocks need recovery
Thu Nov 11 19:42:26 2004
Started recovery at
Thread 2: logseq 961, block 528, scn 0.505813790
Recovery of Online Redo Log: Thread 2 Group 3 Seq 961 Reading mem 0 Mem# 0 errs 0: /dev/rredolog2_1
Thu Nov 11 19:42:26 2004
Completed redo application
Thu Nov 11 19:42:26 2004
Ended recovery at
Thread 2: logseq 961, block 642, scn 0.505834045
51 data blocks read, 51 data blocks written, 114 redo blocks read Ending instance recovery of 1 threads
SMON: about to recover undo segment 11
SMON: mark undo segment 11 as available
Oracle RAC测试报告
SMON: about to recover undo segment 12
SMON: mark undo segment 12 as available
SMON: about to recover undo segment 13
SMON: mark undo segment 13 as available
SMON: about to recover undo segment 14
SMON: mark undo segment 14 as available
SMON: about to recover undo segment 15
SMON: mark undo segment 15 as available
SMON: about to recover undo segment 16
SMON: mark undo segment 16 as available
SMON: about to recover undo segment 17
SMON: mark undo segment 17 as available
SMON: about to recover undo segment 18
SMON: mark undo segment 18 as available
SMON: about to recover undo segment 19
SMON: mark undo segment 19 as available
SMON: about to recover undo segment 20
SMON: mark undo segment 20 as available
测试前提:
1. zxin1上oracle 实例和平台程序已经启动,正常呼叫,100caps
2. zxin2上oracle 实例已启动,无呼叫接入
测试步骤:
异常关闭zxin2上的实例(shutdown abort)
测试结果:
zxin2实例异常关闭后,zxin1实例进行资源重组(Reconfiguration)和实例恢复(Instance Recovery),总时间在5秒左右,从呼叫仪看受到影响的现有呼叫在100个左右(同时有可能导致的呼叫无法接入的情况,在呼叫仪无法统计得到),附alert_zxin1.log
Wed Nov 17 19:03:16 2004
Reconfiguration started
List of nodes: 0,
Global Resource Directory frozen
one node partition
Communication channels reestablished
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
Resources and enqueues cleaned out
Resources remastered 3331
22065 GCS shadows traversed, 0 cancelled, 1203 closed
10217 GCS resources traversed, 0 cancelled
29798 GCS resources on freelist, 39981 on array, 39981 allocated
set master node info
Submitted all remote-enqueue requests
Update rdomain variables
Oracle RAC测试报告
Dwn-cvts replayed, VALBLKs dubious
All grantable enqueues granted
22065 GCS shadows traversed, 0 replayed, 1203 unopened
Submitted all GCS remote-cache requests
0 write requests issued in 20862 GCS resources
1 PIs marked suspect, 0 flush PI msgs
Wed Nov 17 19:03:17 2004
Reconfiguration complete
Post SMON to start 1st pass IR
Wed Nov 17 19:03:17 2004
Instance recovery: looking for dead threads
Wed Nov 17 19:03:17 2004
Beginning instance recovery of 1 threads
Wed Nov 17 19:03:17 2004
Started redo scan
Wed Nov 17 19:03:19 2004
Completed redo scan
90 redo blocks read, 44 data blocks need recovery
Wed Nov 17 19:03:21 2004
Started recovery at
Thread 2: logseq 981, block 209, scn 0.506867082
Recovery of Online Redo Log: Thread 2 Group 3 Seq 981 Reading mem 0 Mem# 0 errs 0: /dev/rredolog2_1
Wed Nov 17 19:03:21 2004
Completed redo application
Wed Nov 17 19:03:21 2004
Ended recovery at
Thread 2: logseq 981, block 299, scn 0.506895910
44 data blocks read, 50 data blocks written, 90 redo blocks read Ending instance recovery of 1 threads
SMON: about to recover undo segment 11
SMON: mark undo segment 11 as available
SMON: about to recover undo segment 12
SMON: mark undo segment 12 as available
SMON: about to recover undo segment 13
SMON: mark undo segment 13 as available
SMON: about to recover undo segment 14
SMON: mark undo segment 14 as available
SMON: about to recover undo segment 15
SMON: mark undo segment 15 as available
SMON: about to recover undo segment 16
SMON: mark undo segment 16 as available
SMON: about to recover undo segment 17
SMON: mark undo segment 17 as available
Oracle RAC测试报告
SMON: about to recover undo segment 18
SMON: mark undo segment 18 as available
SMON: about to recover undo segment 19
SMON: mark undo segment 19 as available
SMON: about to recover undo segment 20
SMON: mark undo segment 20 as available
4.4.4 第二实例所在机器异常关闭对第一实例的影响
测试前提:
1. zxin1上oracle 实例和平台程序已经启动,无呼叫接入
2. zxin2上oracle 实例和平台程序已经启动,无呼叫接入
测试步骤:
重启机器zxin2(shutdown –Fr)
测试结果:
主机zxin2重启,同实例zxin2的shutdown abort类似,实例zxin1进行资源重组和实例恢复,总时间在1秒左右
测试前提:
1. zxin1上oracle 实例和平台程序已经启动,正常呼叫,100caps
2. zxin2上oracle 实例已经启动
测试步骤:
重启机器zxin2(shutdown –Fr)
测试结果:
主机zxin2重启,实例zxin1进行资源重组和实例恢复,总时间在2秒左右,受到影响的呼叫数目为50个左右。附alert_zxin1.log日志:
Wed Nov 17 19:44:40 2004
Reconfiguration started
List of nodes: 0,
Global Resource Directory frozen
one node partition
Communication channels reestablished
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
Resources and enqueues cleaned out
Resources remastered 2389
1683 GCS shadows traversed, 0 cancelled, 0 closed
814 GCS resources traversed, 0 cancelled
39185 GCS resources on freelist, 39981 on array, 39981 allocated
set master node info
Submitted all remote-enqueue requests
Update rdomain variables
Dwn-cvts replayed, VALBLKs dubious
All grantable enqueues granted
Oracle RAC测试报告
1683 GCS shadows traversed, 0 replayed, 0 unopened
Submitted all GCS remote-cache requests
0 write requests issued in 1683 GCS resources
1 PIs marked suspect, 0 flush PI msgs
Wed Nov 17 19:44:41 2004
Reconfiguration complete
Post SMON to start 1st pass IR
Wed Nov 17 19:44:41 2004
Instance recovery: looking for dead threads
Wed Nov 17 19:44:41 2004
Beginning instance recovery of 1 threads
Wed Nov 17 19:44:41 2004
Started redo scan
Wed Nov 17 19:44:41 2004
Completed redo scan
383 redo blocks read, 51 data blocks need recovery
Wed Nov 17 19:44:41 2004
Started recovery at
Thread 2: logseq 983, block 2, scn 0.506963590
Recovery of Online Redo Log: Thread 2 Group 3 Seq 983 Reading mem 0 Mem# 0 errs 0: /dev/rredolog2_1
Wed Nov 17 19:44:41 2004
Completed redo application
Wed Nov 17 19:44:41 2004
Ended recovery at
Thread 2: logseq 983, block 385, scn 0.507063592
23 data blocks read, 51 data blocks written, 383 redo blocks read Ending instance recovery of 1 threads
SMON: about to recover undo segment 11
SMON: mark undo segment 11 as available
SMON: about to recover undo segment 12
SMON: mark undo segment 12 as available
SMON: about to recover undo segment 13
SMON: mark undo segment 13 as available
SMON: about to recover undo segment 14
SMON: mark undo segment 14 as available
SMON: about to recover undo segment 15
SMON: mark undo segment 15 as available
SMON: about to recover undo segment 16
SMON: mark undo segment 16 as available
SMON: about to recover undo segment 17
SMON: mark undo segment 17 as available
SMON: about to recover undo segment 18
SMON: mark undo segment 18 as available
Oracle RAC测试报告
SMON: about to recover undo segment 19
SMON: mark undo segment 19 as available
SMON: about to recover undo segment 20
SMON: mark undo segment 20 as available
5 测试总结
相对于智能网双机热备的应用模式,RAC能够充分利用硬件配置,提高系统的处理能力,在相同条件下,RAC的处理能力比现有模式下的处理能力提高了1倍;这是我们最看重的一点。但是,RAC在实现了较高并行处理能力的同时,也增加了系统安装、管理方面的复杂度,希望在稳定性方面能够做得更好。
5.1 测试中发现问题的说明
1. Wait io的问题
现象:
3节点的RAC中,实例正常运行,应用正常运行,此刻,若某一节点异常宕
机,然后重新加入RAC的时候,会导致其他节点wait io的居高不下
结论:
这个问题困扰我们的这次测试很久了,先后有oracle、IBM的工程师来处理定
位问题所在,目前还没有结论。鉴于这种情况,我们认为在AIX5.2、HA5.1和Oracle 9i环境下的多节点RAC不可用。
出问题的环境配置为:
操作系统AIX5.2 补丁02,HA版本5.1补丁04,Oracle 9.2.0.5(或者9.2.0.1) 而在如下配置的环境下,第三个实例根本无法启动,出现IO错误
操作系统AIX5.2 补丁04,HA版本5.1补丁05,Oracle 9.2.0.5
2. 修改时间的问题
现象:
RAC中,修改某一节点的系统时间,可能会导致RAC中某一实例异常宕掉
结论:
Oracle工程师建议在RAC环境下,建尽量不要修改系统时间,如果需要的话,
修改的时间跨度不能太大。
3. 私网网线异常的问题(这是个新问题)
现象:
两节点的RAC,拔掉用于节点通讯的private 网线,或者删除private ip,导致
在较长时间内(目前基本上是固定在15分钟),无法通过sqlplus访问数据库。 结论:
按理拔掉private网线时,应该系统自动剔除某一实例,保证其他节点的正常
访问,而不能导致所有实例都无法访问,这是一个问题;再一个就是出现这种情况的时间比较长,如果每次都导致系统无法访问15分钟的话,将会是很严重的一次事故了。希望能够尽量缩短这个时间。
Oracle RAC测试报告
6 获得的技术支持
测试过程中,得到了以下工程师的大力支持,表示感谢。 IBM工程师:丁杰、涂能光
Oracle工程师:段起阳、杨长水、丁雪峰、周灏宇 STK工程师:林国坚