图遍历的演示
题目:试设计一个程序,演示在连通和非连通的无向图上访问全部结点的操作
班级:07级计科院网络工程姓名:## 学号:## 完成日期:
一、需求分析
1、以邻接多重表为存储结构;
2、实现连通和非连通的无向图的深度优先和广度优先遍历;
3、要求利用栈实现无向图的广度和深度优先遍历;
4、以用户指定的结点为起点,分别输出每种遍历下的结点访问序列和生成树的边集;
5、用凹入表打印生成树;
6、求出从一个结点到另外一个结点,但不经过另外一个指定结点的所有简单路径;
6、本程序用C++语言编写,在TURBO C++ 3.0环境下通过。
二、概要设计
1、设定图的抽象数据类型:
ADT Graph{
数据对象V:V是具有相同特性的数据元素的集合,称为点集.
数据关系R:
R={VR}
VR={(v,w)|v,w属于V,(v,w)表示v和w之间存在的路径}
基本操作P:
CreatGraph(&G,V,VR)
初始条件:V是图的顶点集,VR是图中弧的集合.
操作结果:按V和VR是定义构造图G.
DestroyGraph(&G)
初始条件:图G存在
操作结果:销毁图G
LocateVex(G,u)
初始条件: 图G存在,u和G中顶点有相同的特征
操作结果:若图G中存在顶点u,则返回该顶点在图中的位置;否则返回其他信息
GetVex(G,v)
初始条件: 图G存在,v是G中顶点
操作结果:返回v的值
FirstAjvex(G,v)
初始条件: 图G存在,v是G中顶点
操作结果:返回v的第一个邻接顶点,若顶在图中没有邻接顶点,则返回为空
NextAjvex(G,v,w)
初始条件: 图G存在,v是G中顶点,w是v的邻接顶点
操作结果:返回v的下一个邻接顶点,若w是v的最后一个邻接顶点,则返回空
DeleteVexx(&G,v)
初始条件: 图G存在,v是G中顶点
操作结果:删除顶点v已经其相关的弧
DFSTraverse(G,visit())
初始条件: 图G存在,visit的顶点的应用函数
操作结果: 对图进行深度优先遍历,在遍历过程中对每个结点调用visit函数一次,一旦visit失败,则操作失败
BFSTraverse(G,visit())
初始条件: 图G存在,visit的顶点的应用函数
操作结果:对图进行广度优先遍历,在遍历过程中对每个结点调用visit函数一次,一旦visit失败,则操作失败
}ADT Graph
2、设定栈的抽象数据类型:
ADT Stack{
数据对象:D={ai | ai∈CharSet,i=1,2,……,n,n≥0}
数据关系:R1={ | ai-1,ai∈D,i=2,……,n}
基本操作:
InitStack(&S)
操作结果:构造一个空栈S。
DestroyStack(&S)
初始条件:栈S已存在。
操作结果:栈S被销毁。
Push(&S,e);
初始条件:栈S已存在。
操作结果:在栈S的栈顶插入新的栈顶元素e。
Pop(&S,e);
初始条件:栈S已存在。
操作结果:删除S的栈顶元素,并以e返回其值。
StackEmpty(S)
初始条件:栈S已存在。
操作结果:若S为空栈,则返回TRUE,否则返回FALSE。
}ADT Stack
3、设定队列的抽象数据类型:
ADT Queue{
数据对象:D={ai|ai属于Elemset,i=1,2….,n,n>=0}
数据关系:R1={|ai-1,ai属于D,i=1,2,…,n}
约定ai为端为队列头,an为队列尾
基本操作:
InitQueue(&Q)
操作结果:构造一个空队列Q
DestryoQueue(&Q)
初始条件:队列Q已存在。
操作结果:队列Q被销毁,不再存在。
EnQueue(&Q,e)
初始条件:队列Q已经存在
操作结果:插入元素e为Q的新的队尾元素
DeQueue(&Q,&E)
初始条件:Q为非空队列
操作结果:删除Q的队尾元素,并用e返回其值
QueueEmpty(Q)
初始条件:队列已经存在
操作结果:若队列为空,则返回TRUE,否则返回FLASE
}ADT Queue
4、本程序包含九个模块:
1)主程序模块
void main ()
{
手动构造一个图;
从文件导入一个图;
显示图的信息;
进行深度优先遍历图;
进行广度优先遍历图;
保存图到一个文件;
寻找路径;
销毁一个图;
};
2)手动构造一个图-自己输入图的顶点和边生成一个图;
3)从文件导入一个图;
4)显示图的信息-打印图的所有顶点和边;
5)进行深度优先遍历图-打出遍历的结点序列和边集;
6)进行广度优先遍历图-打出遍历的结点序列和边集;
7)保存图到一个文件;
8)寻找从起点到终点,但中间不经过某点的所有简单路径;
9)销毁图。
三、详细设计
1、顶点,边和图类型
#define MAX_INFO 10 /* 相关信息字符串的最大长度+1 */
#define MAX_VERTEX_NUM 20 /* 图中顶点数的最大值*/
typedef char InfoType; /*相关信息类型*/
typedef char VertexType; /* 字符类型 */
typedef enum{unvisited,visited}VisitIf;
typedef struct EBox{
VisitIf mark; /* 访问标记 */
int ivex,jvex; /* 该边依附的两个顶点的位置 */
struct EBox *ilink,*jlink; /* 分别指向依附这两个顶点的下一条边 */
InfoType *info; /* 该边信息指针 */
}EBox;
typedef struct{
VertexType data;
EBox *firstedge; /* 指向第一条依附该顶点的边 */
}VexBox;
typedef struct{
VexBox adjmulist[MAX_VERTEX_NUM];
int vexnum,edgenum; /* 无向图的当前顶点数和边数 */
}AMLGraph;
图的基本操作如下:
int LocateVex(AMLGraph G,VertexType u);
// 查G和u有相同特征的顶点,若存在则返回该顶点在无向图中位置;否则返回-1。
VertexType& GetVex(AMLGraph G,int v);
//以v返回邻接多重表中序号为i的顶点。
int FirstAdjVex(AMLGraph G,VertexType v);
//返回v的第一个邻接顶点的序号。若顶点在G中没有邻接顶点,则返回-1。
int NextAdjVex(AMLGraph G,VertexType v,VertexType w);
//返回v的(相对于w的)下一个邻接顶点的序号若w是v的最后一个邻接点,则返回-1。
void CreateGraph(AMLGraph &G);
//采用邻接多重表存储结构,构造无向图G。
Status DeleteArc(AMLGraph &G,VertexType v,VertexType w);
//在G中删除边。
Status DeleteVex(AMLGraph &G,VertexType v);
//在G中删除顶点v及其相关的边。
void DestroyGraph(AMLGraph &G);
//销毁一个图
void Display(AMLGraph G);
//输出无向图的邻接多重表G。
void DFSTraverse(AMLGraph G,VertexType start,int(*visit)(VertexType));
//从start顶点起,(利用栈非递归)深度优先遍历图G。
void BFSTraverse(AMLGraph G,VertexType start,int(*Visit)(VertexType));
//从start顶点起,广度优先遍历图G。
void MarkUnvizited(AMLGraph G);
//置边的访问标记为未被访问。
其中部分操作的伪码算法如下:
void CreateGraph(AMLGraph &G)
{ /* 采用邻接多重表存储结构,构造无向图G */
DestroyGraph(G); /*如果图不空,先销毁它*/
输入无向图的顶点数G.vexnum;
输入无向图的边数G.edgenum;
输入顶点的信息IncInfo;
依次输入无向图的所有顶点;
for(k=0;k
{
读入两个顶点va、vb;
i=LocateVex(G,va); /* 一端 */
j=LocateVex(G,vb); /* 另一端 */
p=(EBox*)malloc(sizeof(EBox));
p->mark=unvisited; /* 设初值 */
p->ivex=i;
p->jvex=j;
p->info=NULL;
p->ilink=G.adjmulist[i].firstedge; /* 插在表头 */
G.adjmulist[i].firstedge=p;
p->jlink=G.adjmulist[j].firstedge; /* 插在表头 */
G.adjmulist[j].firstedge=p;
}
}
void Display(AMLGraph G)
{ /* 输出无向图的邻接多重表G */
MarkUnvizited(G);
输出无向图的所有顶点;
for(i=0;i
{
p=G.adjmulist[i].firstedge;
while(p)
if(p->ivex==i) /* 边的i端与该顶点有关 */
{
if(!p->mark) /* 只输出一次 */
{
cout<jvex].data<
p->mark=visited;
}
p=p->ilink;
}
else /* 边的j端与该顶点有关 */
{
if(!p->mark) /* 只输出一次 */
{
cout<ivex].data<<'-'<
p->mark=visited;
}
p=p->jlink;
}
cout<
}
}
void DFSTraverse(AMLGraph G,VertexType start,int(*visit)(VertexType))
{ /*从start顶点起,深度优先遍历图G(非递归算法)*/
InitStack(S);
w=LocateVex(G,start); /*先确定起点start在无向图中的位置*/
for(v=0;v
Visited[v]=0; /*置初值 */
for(v=0;v
if(!Visited[(v+w)%G.vexnum])
{
Push(S,(v+w)%G.vexnum); /*未访问,就进栈*/
while(!StackEmpty(S))
{
Pop(S,u);
if(!Visited[u])
{
Visited[u]=1; /*未访问的标志设为访问状态,并输出它的值*/
visit(G.adjmulist[u].data);
for(w=FirstAdjVex(G,G.adjmulist[u].data);w>=0;
w=NextAdjVex(G,G.adjmulist[u].data,G.adjmulist[w].data))
if(!Visited[w])
Push(S,w);
}
}
}
DestroyStack(S); /*销毁栈,释放其空间*/
}
void BFSTraverse(AMLGraph G,VertexType start,int(*Visit)(VertexType))
{ /*从start顶点起,广度优先遍历图G*/
for(v=0;v
Visited[v]=0; /* 置初值 */
InitQueue(Q);
z=LocateVex(G,start); /*先确定起点start在无向图中的位置*/
for(v=0;v
if(!Visited[(v+z)%G.vexnum]) /* v尚未访问 */
{
Visited[(v+z)%G.vexnum]=1; /* 设置访问标志为TRUE(已访问) */
Visit(G.adjmulist[(v+z)%G.vexnum].data);
EnQueue(Q,(v+z)%G.vexnum);
while(!QueueEmpty(Q)) /* 队列不空 */
{
DeQueue(Q,u);
for(w=FirstAdjVex(G,G.adjmulist[u].data);w>=0;
w=NextAdjVex(G,G.adjmulist[u].data,G.adjmulist[w].data))
if(!Visited[w])
{
Visited[w]=1;
Visit(G.adjmulist[w].data);
EnQueue(Q,w);
}
}
}
DestroyQueue(Q); /*销毁队列,释放其占用空间*/
}
2、栈类型
#define STACK_INIT_SIZE 100 /* 存储空间初始分量*/
#define STACKINCREMENT 10 /* 存储空间分配增量*/
typedef int SElemType;
typedef struct{
SElemType *base;
SElemType *top; /*栈顶指针*/
int stacksize;
}SqStack;
栈的基本操作如下:
Status InitStack(SqStack &S);
//构造一个空栈S。
Status DestroyStack(SqStack &S);
//销毁栈S(无论空否均可)。
Status Push(SqStack &S,SElemType e);
//在S的栈顶插入新的栈顶元素e。
Status Pop(SqStack &S,SElemType &e);
//删除S的栈顶元素并以e带回其值。
Status StackEmpty(SqStack S);
//若S为空栈,则返回TRUE,否则返回FALSE。
3、队列类型
typedef int QelemType;
typedef struct QNode{
QElemType data;
struct QNode *next;
}QNode,*QueuePtr;
typedef struct{
QueuePtr front;
QueuePtr rear; /* 队头、队尾指针 */
}LinkQueue;
队列的基本操作如下:
Status InitQueue(LinkQueue &Q);
//构造一个空队列Q。
Status DestroyQueue(LinkQueue &Q);
//销毁队列Q(无论空否均可)。
Status QueueEmpty(LinkQueue Q);
//若Q为空队列,则返回1,否则返回-1。
Status EnQueue(LinkQueue &Q,QElemType e);
//插入元素e为Q的新的队尾元素。
Status DeQueue(LinkQueue &Q,QElemType &e);
//若队列不空,删除Q的队头元素,用e返回其值,并返回1,否则返回-1。
4、生成树类型:
typedef struct CSNode{
VertexType data;
struct CSNode *firstchild,*nextsibling;
}CSNode,*CSTree; /*树的二叉链表(孩子-兄弟)存储结构*/
生成树的操作:
void DFSTree(AMLGraph G,int v,CSTree &DT);
//从第v个顶点出发深度遍历图G,建立以DT为根的生成树。
void DFSForest(AMLGraph G,VertexType start,CSTree &DT);
//建立图G的深度优先生成森林的(最左)孩子(右)兄弟链表DT。
void PrintTraverse(CSTree T);
//打印图G的遍历生成树的边。
void PrintAllTraverse(CSTree T)
//打印图G的遍历生成森林的边。
void BFSTree(AMLGraph G,int v,CSTree &BT);
//从第v个顶点出发广度遍历图G,建立以BT为根的生成树。
void BFSForest(AMLGraph G,VertexType start,CSTree &BT);
//建立图G的广度优先生成森林的(最左)孩子(右)兄弟链表BT。
void PrintCSTree(CSTree T,int i);
//用凹入表方式打印一棵以孩子-兄弟链表为存储结构的树。
void PrintCSForest(CSTree T);
//用凹入表方式打印一棵以孩子-兄弟链表为存储结构的森林。
其中部分操作的伪码算法如下:
void DFSTree(AMLGraph G,int v,CSTree &DT)
{ /*从第v个顶点出发深度遍历图G,建立以DT为根的生成树*/
first=1;
Visited[v]=1;
for(w=FirstAdjVex(G,G.adjmulist[v].data);w>=0;
w=NextAdjVex(G,G.adjmulist[v].data,G.adjmulist[w].data))
if(!Visited[w])
{
p=(CSTree)malloc(sizeof(CSNode)); /*分配孩子结点*/
strcpy(p->data,G.adjmulist[w].data);
p->firstchild=NULL;
p->nextsibling=NULL;
if(first) /*w是v的第一个未被访问的邻接顶点是根的左孩子结点*/
{
DT->firstchild=p;
first=0;
}
else /*w是v的其他未被访问的邻接顶点是上一邻接顶点的右兄弟结点*/
q->nextsibling=p;
q=p;
DFSTree(G,w,q); /*从第w个顶点出发深度优先遍历图G,建立子生成树q*/
}
}
void BFSTree(AMLGraph G,int v,CSTree &BT)
{ /*从第v个顶点出发广度遍历图G,建立以BT为根的生成树*/
r=BT;
i=j=0;
Visited[v]=1;
InitQueue(Q);
EnQueue(Q,v); /*先把第一个顶点入队列*/
while(!QueueEmpty(Q))
{
first=1;
DeQueue(Q,u);
for(w=FirstAdjVex(G,G.adjmulist[u].data);w>=0;
w=NextAdjVex(G,G.adjmulist[u].data,G.adjmulist[w].data))
if(!Visited[w])
{
Visited[w]=1;
p=(CSTree)malloc(sizeof(CSNode));
strcpy(p->data,G.adjmulist[w].data);
p->firstchild=NULL;
p->nextsibling=NULL;
if(first) /*w是v的第一个未被访问的邻接顶点是根的左孩子结点*/
{
r->firstchild=p;
first=0;
}
else /*w是v的其他未被访问的邻接顶点是上一邻接顶点的右兄弟结点*/
q->nextsibling=p;
cur[i++]=p; /*用一个数组指针保存生成树的根*/
q=p;
EnQueue(Q,w);
}
r=cur[j++]; /*回朔到上一棵生成树的根*/
}
DestroyQueue(Q);
}
void PrintCSTree(CSTree T,int i)
{ /*用凹入表方式打印一棵以孩子-兄弟链表为存储结构的树*/
for(j=1;j<=i;j++)
cout<
cout<data<
for(p=T->firstchild;p;p=p->nextsibling)
PrintCSTree(p,i+1); /*打印子树*/
}
void PrintCSForest(CSTree T)
{ /*用凹入表方式打印一棵以孩子-兄弟链表为存储结构的森树*/
for(p=T;p;p=p->nextsibling)
{
cout<<"第 "<
PrintCSTree(p,0);
}
}
5、主程序和其他伪码算法
void main ()
{
显示菜单;
输入功能选择键;
switch(flag)
{
case 1:手动构造一个图;
case 2:从文件导入一个图;
case 3:显示图的信息;
case 4:进行深度优先遍历图;
case 5:进行广度优先遍历图;
case 6:保存图到一个文件;
case 7:寻找路径;
case 8:销毁图;
case 9:退出程序;
}
销毁图;
}
int Visited[MAX_VERTEX_NUM]; /*访问标志数组(全局量) */
void AllPath(AMLGraph G,VertexType start,VertexType nopass,VertexType end,int k)
{ /*寻找路径*/
Path[k]=start; /*加入当前路径中*/
l=LocateVex(G,nopass);
u=LocateVex(G,start);
Visited[u]=1;
if(start==end) /*找到了一条简单路径*/
{
cout<
for(i=1;Path[i];i++)
cout<<"->"<
cout<
}
else
for(w=FirstAdjVex(G,G.adjmulist[u].data);w>=0;
w=NextAdjVex(G,G.adjmulist[u].data,G.adjmulist[w].data))
{
if(w==l)
continue; /*如果找到那个不想经过的点,就绕过它,相当不执行后面的语句*/
if(!Visited[w])
{
temp=G.adjmulist[w].data;
AllPath(G,temp,nopass,end,k+1); /*继续寻找*/
}
}
Visited[u]=0;
Path[k]=0; /*回溯*/
}
void SaveGraph(AMLGraph G) /*保存图的信息*/
{
建立输出文件流对象outgraph;
输入文件名fileName;
outgraph.open(fileName,ios::out);连接文件,指定打开方式
if(!outgraph) /*调用重载算符函数测试流*/
{
cerr<<"文件不能打开."<
abort();
}
向流插入数据;
outgraph.close(); /*关闭文件*/
}
void LoadGraph(AMLGraph &G)
{
建立输入文件流对象ingraph;
输入文件名fileName;
if(!ingraph)
{
cerr<<"文件不能打开."<
abort();
}
向流输出数据;
ingraph.close(); /*关闭文件*/
}
visit(VertexType v)
{ /*输出结点*/
cout<
return OK;
}
void message() /*菜单显示*/
{
cout<<"\n\t\t* * * * * * * * * * * * * * * * * * * *\n";
cout<<"\t\t\t1:手动构造一个图\t *\n";
cout<<"\t\t\t2:从文件导入一个图\t *\n";
cout<<"\t\t\t3:显示图的信息\t *\n";
cout<<"\t\t\t4:进行深度优先遍历图\t *\n";
cout<<"\t\t*\t5:进行广度优先遍历图\t *\n";
cout<<"\t\t*\t6:保存图到一个文件\t *\n";
cout<<"\t\t*\t7:寻找路径\t *\n";
cout<<"\t\t*\t8:销毁图\t *\n";
cout<<"\t\t*\t9:退出程序\t\t *\n";
cout<<"\t\t* * * * * * * * * * * * * * * * * * * *\n";
}
四、调试分析
1、本程序以邻接多重表为存储结构。这个程序涉及到图的生成和图的深度以及广度遍历,文件的保存和读取,还有栈和队列的操作,另外还有森林的生成和打印,路径的寻找。
2、本程序不仅可以进行连通无向图的遍历,还可以进行非连通图的遍历。为了方便显示和理解,现在暂且用一个大写字母表示一个顶点。边还可以附加信息,但为了方便操作,暂且不输入信息。已经先把图的相关信息保存在了文本文档里,所以要测试时直接从文件导入,可以减少用手输入的麻烦,同时也可以减少输入的错误。
3、由于构造图时,后输入的边是插在先输入的边的前面。所以在输入边时,可以按字母从大到小的顺序输入。那么显示图的时候就可以按字母从小到大的顺序显示。
4、程序定义了一个二倍顶点长的数组存放输入的边,以便程序可以把它保存到文件里。故耗费了一定的内存空间。
五、用户手册
1、本程序的运行环境DOS操作系统,GTraverse.exe
2、进入演示程序后即显示一个有功能选择的界面,如下:
3、选择操作1:程序就提示分别输入无向图的顶点数,边数,边的信息,顶点和边的值:
输入完成后,程序提示按任一键返回菜单:
4、选择操作2:程序提示输入一个存有图信息文件的路径去导入一个图:
如果导入成功,它会显示导入成功,并提示按任一键返回。
5、选择操作3:程序显示图的顶点和边的信息。
6、选择操作4:系统提示输入遍历图的起始点,程序运行后,首先显示深度优先遍历的访问结点序列和生成树的边集。然后再提示按任一键继续显示深度优先遍历的生成森林。
7、选择操作5:系统提示输入遍历图的起始点,程序运行后,首先显示广度优先遍历的访问结点序列和生成树的边集。然后再提示按任一键继续显示广度优先遍历的生成森林。
8、选择操作6:程序会提示输入要存放图信息的文件的路径:
9、选择操作7:程序会提示输入路径遍历的起点start,终点end,不想经过的点nopass。
10、选择操作8:销毁一个图。
11、选择操作9:退出程序。
六、测试结果
1、数据可以任意输入,但是顶点数不要太多,不然占用太多内存,会导致死机。
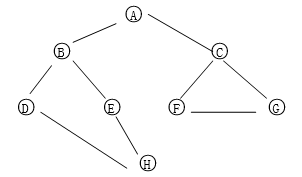
2、遍历一个连通的无向图,如遍历以下这个连通无向图:
1)选择操作1,分别进行以下操作:
请输入图的节点数 (EG. G.vexnum=10): 8
请输入图的边数 (EG. G.edgenum=4): 9
请输入8 个节点的表示值:
A
B
C
D
E
F
G
H
请输入有序的边(用空格作间隔):
F G
E H
D H
C G
C F
B E
B D
A C
A B
2) 选择操作3,输出图的信息如下:
这个图有 8 叶子:
A B C D E F G H
这个图有 9 边:
A-B A-C
B-D B-E
C-F C-G
D-H
E-H
F-G
3)选择操作4,输入遍历起点,如A(也可以输入B,C……)
*****深度优先遍历图的结果*****
深度优先遍历的访问结点序列:
A C G F B E H D
深度优先遍历生成树的边集:
A-B B-D D-H H-E A-C C-F F-G
深度优先遍历的生成森林:
第1个树:
A
B
D
H
E
C
F
G
4)选择操作5,输入遍历起点,如A(也可以输入B,C……)
*****广度优先遍历图的结果*****
广度优先遍历的访问结点序列:
A B C D E F G H
广度优先遍历生成树的边集:
A-B B-D D-H B-E A-C C-F C-G
广度优先遍历的生成森林:
第1个树:
A
B
D
H
E
C
F
G
5) 选择操作7,输入以下信息:
请输入第一个结点: A
请输入最后一个结点: H
请输入您不想通过的结点: D
所有的路径从 A 结点到 H 结点和不想通过 D 结点的是:
A->B->E->H
3、选择操作8销毁图,好继续下一个测试。
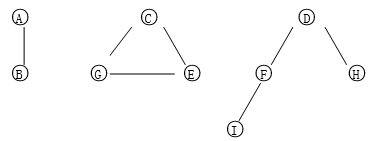
4、遍历一个非连通的无向图,如遍历以下这个非连通无向图:
1)选择操作1,分别进行以下操作:
请输入图的节点数 (EG. G.vexnum=10): 9
请输入图的边数 (EG. G.edgenum=4):8
请输入9 个节点的表示值:
A
B
C
D
E
F
G
H
I
请输入有序的边(用空格作间隔):
F I
D H
D F
C G
C E
A B
2)选择操作3,输出图的信息如下:
这个图有 9 叶子:
A B C D E F G H I
这个图有 7 边:
A-B
C-E C-G
D-F D-H
E-G
F-I
3)选择操作4,输入遍历起点,如A(也可以输入B,C……)
*****深度优先遍历图的结果*****
深度优先遍历的访问结点序列:
A B C G E D H F I
深度优先遍历生成树的边集:
A-B C-E E-G D-F F-I D-H
深度优先遍历的生成森林:
第1个树:
A
B
第2个树:
C
E
G
第3个树:
D
F
I
H
4) 选择操作5,输入遍历起点,如A(也可以输入B,C……)
*****广度优先遍历图的结果*****
广度优先遍历的访问结点序列:
A B C E G D F H I
广度优先遍历生成树的边集:
A-B C-E C-G D-F F-I D-H
广度优先遍历的生成森林:
第1个树:
A
B
第2个树:
C
E
G
第3个树:
D
F
I
H
5) 选择操作7,输入以下信息:
请输入第一个结点:C
请输入最后一个结点: E
请输入您不想通过的结点: G
所有的路径从 C 结点到 E 结点和不想通过 G 结点的是:
C->E
七、附录
源程序文件名清单:
GTraverse.cpp //主程序
GTraverse.exe //可执行文件
GTraverse.OBJ //目标源文件
1.txt //存有连通图信息的文本文档
2.txt //存有非连通图信息的文本文档
八、心得体会
这道题的完成逐步地增加了许多功能。把本来只能遍历连通图的功能上,改进为可以遍历非连通图,接着再改造为可以输出边集,后来又增加了打印生成树的功能,最后还增加了文件的保存和读取,路径的遍历。最难得是,把原来用C语言编写的程序改为用C++语言编写,虽然编写C++语言水平有限,但这个程序只是用到C++那些比较基础和简单的知识,所以对我来说,困难还不是很大。
通过这道设计题,使我更深刻的理解数据结构及其重要作用,对数据结构有了一个新的认识,深刻的认识到数据结构对于我们学习计算机的重要性和其深远但是意义.同时,通过这次课程设计,也加强我的动手能力和思维能力,可以将自己所学的知识用于实践,这不仅对自己是一次锻炼机会,而且让自己有一种成就感和自豪感,觉得自己终于可以做出一点有用的东西了。说来也奇怪,虽然连续两个通宵,但自己在设计这个程序时,却不会觉得累,也不会觉得困,这几天平均每天是睡不到六个小时,想必是自己对编写程序的兴趣和投入,使得自己顿时间觉得非常有力量。
不过,我觉得自己编写程序的一些思路算法和水平还非常有限。所以以后自己还得在C语言和其他语言上下苦功夫。