一、实验题目
主成份分析实验
二、实验目的
通过本次实验对数据的处理,掌握主成份分析的原理,熟悉主成份分析在SPSS软件和R语言中的实现。
三、实验原理
四、实验数据
如下给出中国近年国民经济主要指标统计,用主成分分析法对这些指标提取主成份,写出提取的主成份与这些指标之间的表达式。
原始数据如下:

四、SPSS实验步骤
1、定义变量

②、输入数据
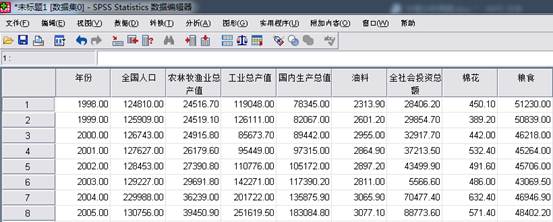
③在菜单栏中选择“分析”→“降维”→“因子分析”。
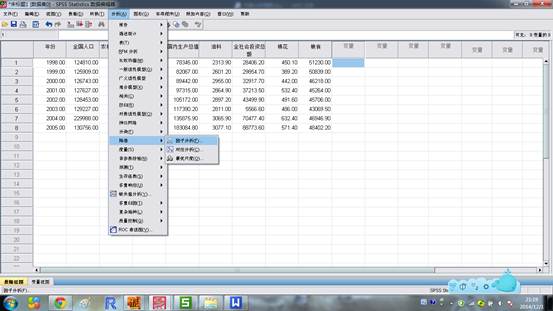
④、除了“年份”选项都选入变量列表。
⑤、单击“描述”→选中“原始分析结果”复选框→“度”设为线性;选中“系数”
⑥单击“抽取”,选中“未旋转的因子解”复选框。其余默认
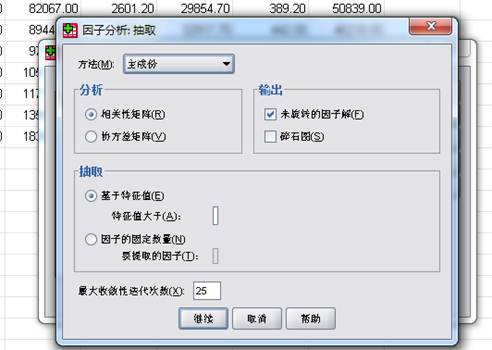
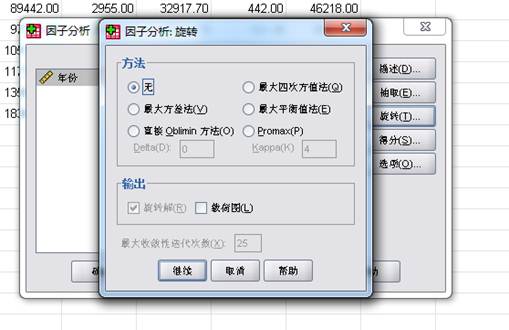
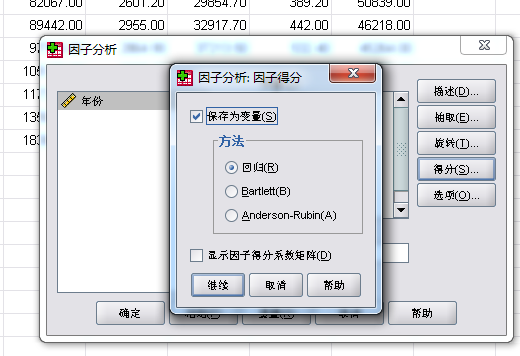
⑦、选中“得分”→“保存为变量”
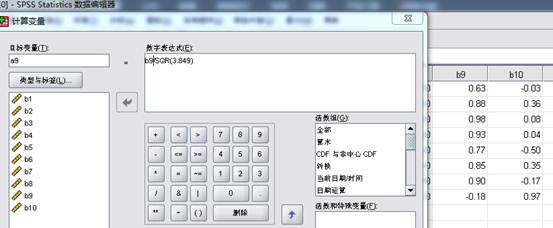
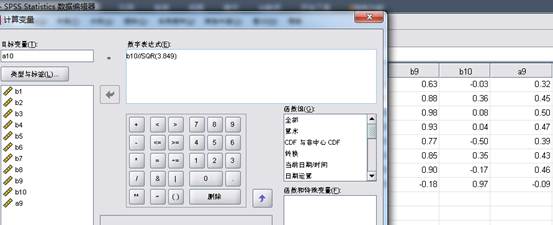
⑧、选中“转换”→“计算变量”,数字表达式中分别输入“a9=b9/SQR(3.849)”“a10=b10/SQR(1.808)”,由载荷矩阵得到主成份特征向量矩阵(a9 a10),(变量视图中改变增加的变量b9、b10、a9、a10的小数位数为3)
五、SPSS实验结果与分析
1、运行结果图如下所示:
2、spss结果分析:
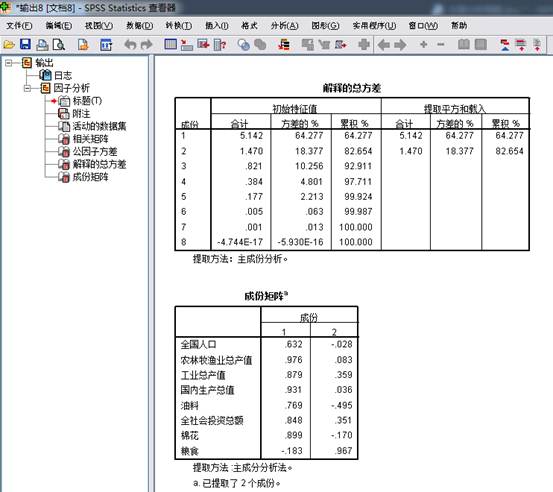
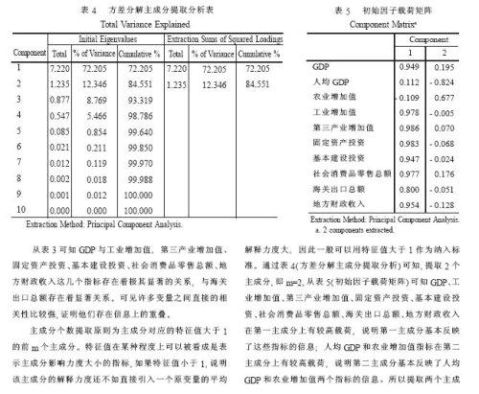
由成分矩阵可以得到各个变量的线性组合表达的主成份:
F1=0.322*全国人口+0.448*农林牧渔业总产值+0.497*工业总产值+0.475*国内生产总值+0.392*油料+0.432*全社会投资总额+0.458*棉花-0.093*粮食;
F2=-0.021*全国人口+0.267*农林牧渔业总产值+0.062*工业总产值+0.027*国内生产总值-0.368*油料+0.261*全社会投资总额-0.126*棉花+0.719*粮食。
在第一主成份中,除了粮食以外的变量的系数比较大,可以看成反映那些变量的综合指标;在第二主成份中,变量粮食的系数比较大,可以看成反映粮食的综合指标。主成分分析是一种矩阵变换,各个主成分并不一定有实际意义,本题目中的主成份含义不明确。
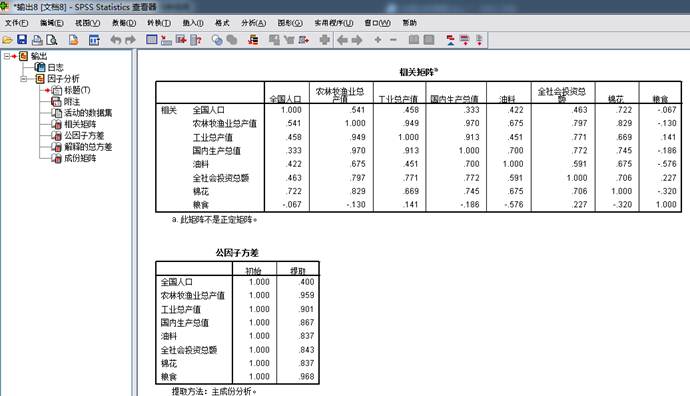
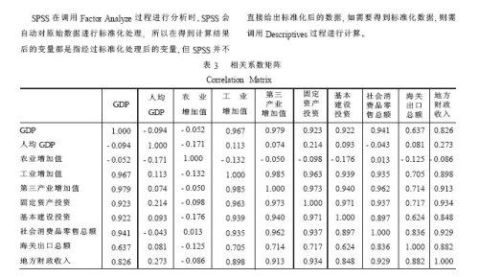
由系数相关矩阵,各个变量之间都有一定的相关关系,一些相关系数接近于1,适合用主成分分析。方差贡献率和累计贡献率得出,前两个进行主成分分析,足够代替原来的变量,几乎涵盖了原变量所有的信息。成分矩阵给出了主成份与标准化形式的变量之间的表达式。
数据窗口中,因子得分作为变量保存,
六、R语言实验结果与分析
①输入命令:
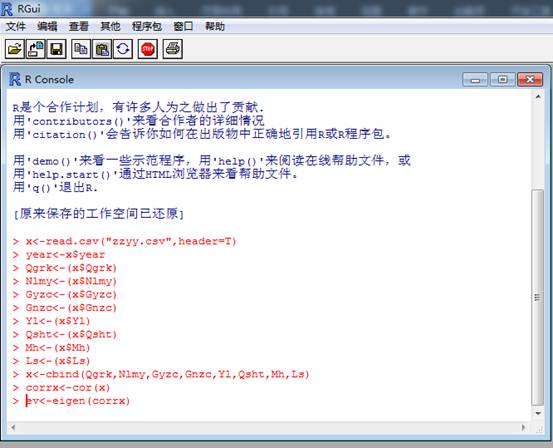
②输出结果如下:
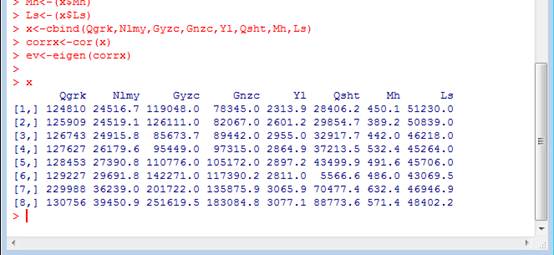
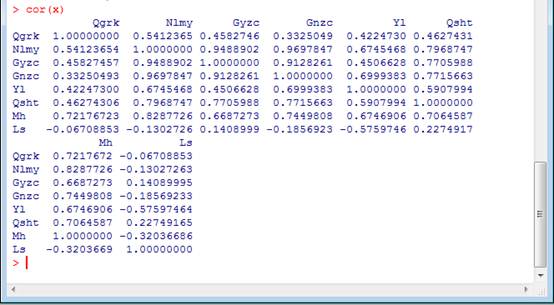
③主成分分析,求出x的相关系数矩阵
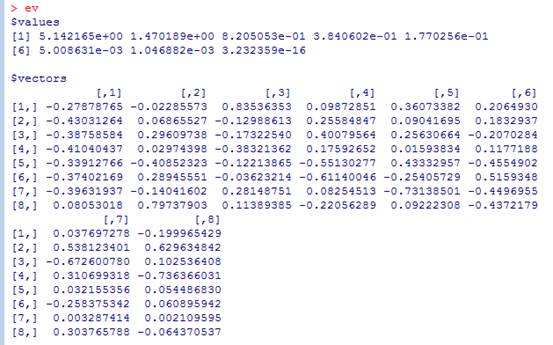
④第四步,求相关系数矩阵的特征值以及特征向量:
⑤特征值碎石图:
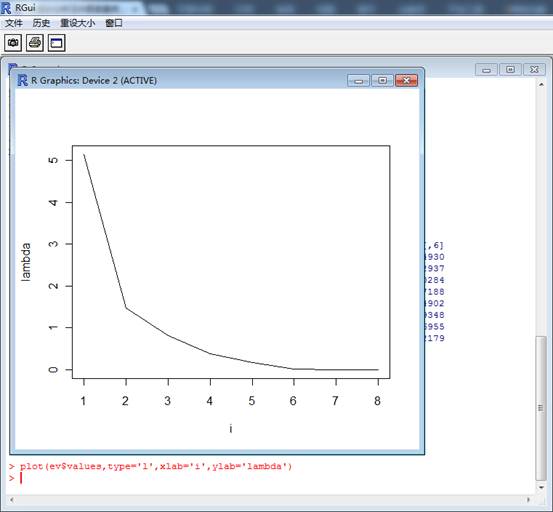
⑥结果分析:相关系数的特征值前两个都大于一,远大于其余的特征值,因此有第一主成分和第二主成份,F1=0.279*全国人口+0.430*农林牧渔业总产值+0.388*工业总产值+0.410*国内生产总值+0.339*油料+0.374*全社会投资总额+0.396*棉花-0.080*粮食;
F2=-0.023*全国人口+0.069*农林牧渔业总产值+0.296*工业总产值+0.03*国内生产总值-0.409*油料+0.289*全社会投资总额-0.14*棉花+0.797*粮食。
⑦R语言程序运行结果与spss运行结果的比较
同样第一主成分不包含粮食,第二主成份中粮食占主要影响,主成份表达式接近,误差很小。
第二篇:怎样用SPSS进行主成分分析
怎样用SPSS进行主成分分析
怎样用SPSS进行主成分分析
一、基本概念与原理
主成分分析(principal component analysis)
将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法。又称主分量分析。在实际课题中,为了全面分析问题,往往提出很多与此有关的变量(或因素),因为每个变量都在不同程度上反映这个课题的某些信息。但是,在用统计分析方法研究这个多变量的课题时,变量个数太多就会增加课题的复杂性。人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间是有一定的相关关系的,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。主成分分析首先是由K.皮尔森对非随机变量引入的,尔后H.霍特林将此方法推广到随机向量的情形。信息的大小通常用离差平方和或方差来衡量。
(1)主成分分析的原理及基本思想。
原理:设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中可以取出几个较少的总和变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上处理降维的一种方法。
基本思想:主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标。最经典的做法就是用F1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即Var(F1)越大,表示F1包含的信息越多。因此在所有的线性组合中选取的F1应该是方差最大的,故称F1为第一主成分。如果第一主成分不足以代表原来P个指标的信息,再考虑选取F2即选第二个线性组合,为了有效地反映原来
信息,F1已有的信息就不需要再出现再F2中,用数学语言表达就是要求Cov(F1, F2)=0,则称F2为第二主成分,依此类推可以构造出第三、第四,……,第P个主成分。
(2)步骤
Fp=a1mZX1+a2mZX2+……+apmZXp
其中a1i, a2i, ……,api(i=1,……,m)为X的协方差阵Σ的特征值多对应的特征向量,ZX1, ZX2, ……, ZXp是原始变量经过标准化处理的值,因为在实际应用中,往往存在指标的量纲不同,所以在计算之前须先消除量纲的影响,而将原始数据标准化,本文所采用的数据就存在量纲影响[注:本文指的数据标准化是指Z标准化]。
A=(aij)p×m=(a1,a2,…am,),Rai=λiai,R为相关系数矩阵,λi、ai是相应的特征值和单位特征向量,λ1≥λ2≥…≥λp≥0 。
进行主成分分析主要步骤如下:
1. 指标数据标准化(SPSS软件自动执行);
2. 指标之间的相关性判定;
3. 确定主成分个数m;
4. 主成分Fi表达式;
5. 主成分Fi命名;
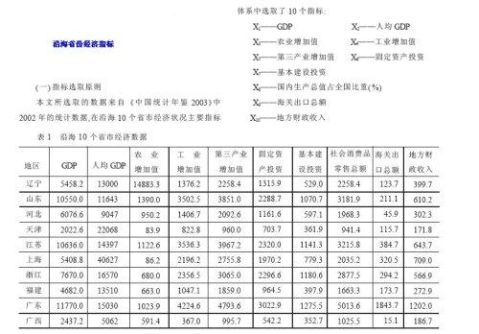
二、以沿海10 个省市经济综合指标为例
三、用SPSS进行详细的主成分分析步骤


发评论
以上网友发言只代表其个人观点,不代表新浪网的观点或立场。
原文网址: .cn/s/blog_3e8dd9070100emos.html