
课程名称:实验地点:
专业班级:
学生姓名:指导教师: 学号: 年 月 日
实验2:利用搜索引擎及网上免费资源检索相关课题的文献
目的:1.学会搜索引擎高级检索的技巧
2.学会网上免费资源的使用方法
内容:
1.自选检索课题。
2.分析检索课题,确定检索标识,编写提问式。
3.利用相关搜索引擎(建议使用Google学术高级搜索)及网上免费资源(建议使用中国科技论文在线)。
4. 在相关检索提问框中输入提问式实施检索,筛选命中文献,选择检索结果输出格式并输出结果。如有必要可反复修改检索提问式优化检索结果。
5.记录检索过程,完成检索报告并提交。
要求:
1.利用搜索引擎检索文献线索
检索课题(中文) :科技
搜索引擎名称:中国知网
检索年限 :2000-1-1——2013-4-1
检索策略(表达式):科技
命中文献数:837,414
选取其中1条文献题录:
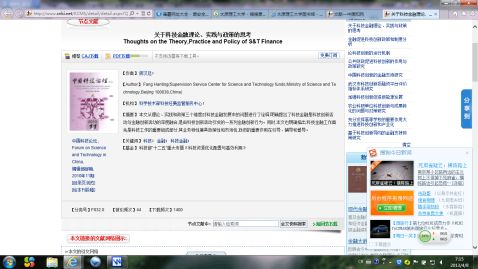
文献题名:关于科技金融理论、实践与政策的思考
作者姓名: 房汉廷
文献类型:论文
出处(出版物名称、年、卷、期或出版年、出版社):中国科技论坛 2010-11-05
被引用次数:44
2. 利用网上免费资源检索文献
检索课题(中文) :科技创新
网上免费资源名称:中国知网
检索年限 :2000-2013
检索策略(表达式):科技创新
命中文献数:116,342
选取其中1条文献题录:
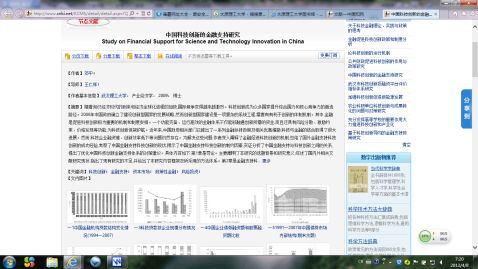
文献题名:中国科技创新的金融支持研究
作者姓名:邓平
出处(出版物名称、年、卷、期、页码范围):武汉理工大学
第二篇:信息检索实验报告
信息检索课程结业报告


 姓 名:
姓 名:

 学 号:
学 号:
 所学专业:
所学专业:
 报告题目:
报告题目:
 提交日期:
提交日期:
信息检索与web搜索
应用背景及概念
信息检索(Information Retrieval)是指信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术。狭义的信息检索就是信息检索过程的后半部分,即从信息集合中找出所需要的信息的过程,也就是我们常说的信息查寻(Information Search 或Information Seek)。
信息检索起源于图书馆的参考咨询和文摘索引工作,从19世纪下半叶首先开始发展,至20世纪40年代,索引和检索成已为图书馆独立的工具和用户服务项目。随着1946年世界上第一台电子计算机问世,计算机技术逐步走进信息检索领域,并与信息检索理论紧密结合起来;脱机批量情报检索系统、联机实时情报检索系统。
信息检索有广义和狭义的之分。广义的信息检索全称为“信息存储与检索”,是指将信息按一定的方式组织和存储起来,并根据用户的需要找出有关信息的过程。狭义的信息检索为“信息存储与检索”的后半部分,通常称为“信息查找”或“信息搜索”,是指从信息集合中找出用户所需要的有关信息的过程。狭义的信息检索包括3个方面的含义:了解用户的信息需求、信息检索的技术或方法、满足信息用户的需求。
搜索引擎(Search Engine,简称SE)是实现如下功能的一个系统:收集、整理和组织信息并为用户提供查询服务。面向WEB的SE是其中最典型的代表。三大特点:事先下载,事先组织,实时检索。
垂直搜索引擎:垂直搜索引擎为20##年后逐步兴起的一类搜索引擎。不同于通用的网页搜索引擎,垂直搜索专注于特定的搜索领域和搜索需求(例如:机票搜索、旅游搜索、生活搜索、小说搜索、视频搜索等等),在其特定的搜索领域有更好的用户体验。相比通用搜索动辄数千台检索服务器,垂直搜索需要的硬件成本低、用户需求特定、查询的方式多样。
Web检索的历史:
1989年,伯纳斯·李在日内瓦欧洲离子物理研究所(CERN)开发计算机远程控制时首次提出了Web概念,并在1990年圣诞节前推出了第一个浏览器。 接下来的几年中,他设计出HTTP、URL和HTML的规范,使网络能够为普通大众所应用 。
Ted Nelson 在1965年提出了超文本的概念.超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络传输协议,超文本标注语言(HTML)。
1993, 早期的 web robots (spiders) 用于收集 URL: Wanderer、ALIWEB (Archie-Like Index of the WEB)、WWW Worm (indexed URL’s and titles for regex search)。
1994, Stanford 博士生 David Filo and Jerry Yang 开发手工划分主题层次的雅虎网站。
1994年初,WebCrawler是互联网上第一个支持搜索文件全部文字的全文搜索引擎,在它之前,用户只能通过URL和摘要搜索,摘要一般来自人工评论或程序自动取正文的前100个字。
Lycos(Carnegie Mellon University Center for Machine Translation Announces Lycos )是搜索引擎史上又一个重要的进步。除了相关性排序外,Lycos还提供了前缀匹配和字符相近限制,Lycos第一个在搜索结果中使用了网页自动摘要,而最大的优势还是它远胜过其它搜索引擎的数据量 。
DEC的AltaVista 是一个迟到者,1995年12月才登场亮相. AltaVista是第一个支持自然语言搜索的搜索引擎,AltaVista是第一个实现高级搜索语法的搜索引擎(如AND, OR, NOT等) 。
1995年博士生Larry Page开始学习搜索引擎设计,于1997年9月15日注册了google.com的域名,1997年底,开始提供Demo。1999年2月,Google完成了从Alpha版到Beta版的蜕变。Google公司则把1998年9月27日认作自己的生日。
Google在Pagerank、动态摘要、网页快照、多文档格式支持、地图股票词典寻人等集成搜索、多语言支持、用户界面等功能上的革新,象Altavista一样,再一次永远改变了搜索引擎的定义。主要的进步在于应用链接分析根据权威性对部分结果排序 。
北大天网 是国家“九五”重点科技攻关项目“中文编码和分布式中英文信息发现”的研究成果,由北大计算机系网络与分布式系统研究室开发,于1997年10月29日正式在CERNET上提供服务。
20##年1月,超链分析专利发明人、前Infoseek资深工程师李彦宏与好友徐勇(加州伯克利分校博士)在北京中关村创立了百度(Baidu)公司
20##年8月发布Baidu.com搜索引擎Beta版(此前Baidu只为其它门户网站搜狐新浪Tom等提供搜索引擎)。
20##年10月22日正式发布Baidu搜索引擎。Baidu虽然只提供中文搜索,但目前收录中文网页超过9000万,可能是最大的的中文数据库。
Web搜索引擎系统组成:
Web数据采集系统
网页预处理系统
索引检索系统
检索结果排序系统
Web检索所在现阶段的挑战:
数据的分布性:文档散落在数以百万计的不同服务器上,没有预先定义的拓扑结构相连。
不稳定的数据高比例:许多文档迅速地添加或删除 (e.g. dead links).
大规模:网络数据量的指数增长,由此引发了一系列难以处理的规模问题。
无结构和冗余信息:每个HTML页面没有统一的结构, 许多网络数据是重复的,将近 30% 的重复网页.
数据的质量: 许多内容没有经过编辑处理,数据可能是错误的,无效的。错误来源有录入错误,语法错误,OCR错误等。
异构数据:多媒体数据(images, video, VRML), 语言,字符集等.
Web检索的基本过程:
网页爬行下来
预处理:网页去重,正文提取,分词等
建立索引
接受用户请求,检索词串的处理,查询重构
找到满足要求的列表
根据连接和文本中的词进行排序输出
信息采集:
信息采集是指为出版的生产在信息资源方面做准备的工作,包括对信息的收集和处理。它是选题策划的直接基础和重要依据。信息采集工作最后一个步骤的延伸,成选题策划的开端。信息采集系统:信息采集系统以网络信息挖掘引擎为基础构建而成,它可以在最短的时间内,帮您把最新的信息从不同的Internet站点上采集下来,并在进行分类和统一格式后,第一时间之内把信息及时发布到自己的站点上去。从而提高信息及时性和节省或减少工作量。网络爬虫,是一种自动获取网页内容的程序,是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。
倒排索引:
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
倒排文件(倒排索引),索引对象是文档或者文档集合中的单词等,用来存储这些单词在一个文档或者一组文档中的存储位置,是对文档或者文档集合的一种最常用的索引机制。
建立倒排索引目的:
对文档或文档集合建立索引,以加快检索速度
倒排文档(或倒排索引)是一种最常用的索引机制
倒排文档的索引对象是文档或文档集合中的单词等。例如,有些书往往在最后提供的索引(单词—页码列表对),就可以看成是一种倒排索引
倒排索引的组成:
倒排文档一般由两部分组成:词汇表(vocabulary)和记录表(posting list)
词汇表是文本或文本集合中所包含的所有不同单词的集合。
对于词汇表中的每一个单词,其在文本中出现的位置或者其出现的文本编号构成一个列表,所有这些列表的集合就称为记录表。
相关工具
1 ltp-Java版分词工具
1.1文件
_irlas.dll, _wsd.dll : 分词工具所需要的动态链接库,放在java工程的根目录下。
nlptools.jar : jar文件。
resource : 分词所需要的资源,需放在放在java工程的根目录下。
1.2 使用方法
下面将列出在实验过程中可能使用到的类:
1) edu.hit.irlab.nlp.splitsentences.SplitSentences
将中文文本按照有分割意义的标点符号(如句号)分开,以句子的序列方式返回。输入为中文文本,输出为中文句子的序列。例如:
SplitSentences sentenceSplit = new SplitSentences();
List<String> sentences = sentenceSplit.getSentences(text);
sentences是对text分句之后的句子集合。
2) edu.hit.irlab.nlp.irlas.IRLAS
分词以及词性标注,使用方法如下:
irlas = new IRLAS();
irlas.loadResource(); //调用分词方法前必须先加载资源
Vector<String> words = new Vector<String>(); //用来存储分词结果
Vector<String> posTags = new Vector<String>(); //用来存储词性标注结果,标点符号的词性是“wp”。
irlas.wordSegment(sentence, words, posTags); //调用分词以及词性标注方法
使用该文件可以将文件里的文本自动变成一个一个关键词,并且统计出此关键词出自哪个文档,建立哈希表进行存储,再存储在txt文件中。
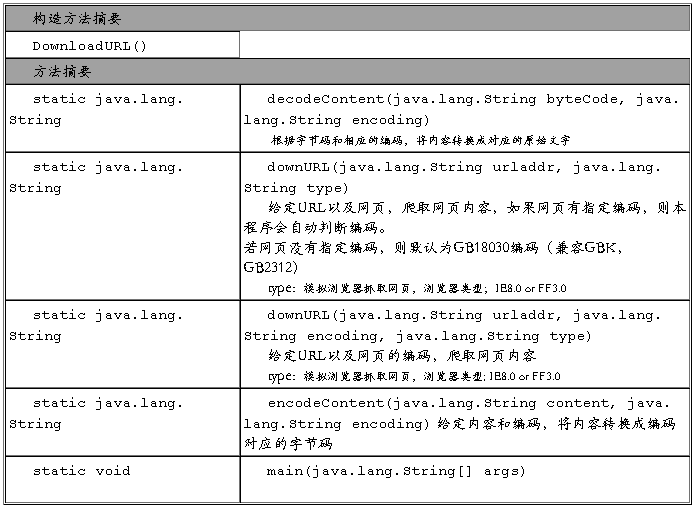
2 DownloadURL类
edu.hit.irlab.util.web.DownloadURL类封装在nlptools中,包含一些常见的web操作,如下载网页、判断编码格式等。
请特别注意:Google的检索结果在本程序发送的FF的head的情况下,没有编码信息。 所以在爬Google的检索结果的时候请务必手动指定使用UTF-8编码。
表格 1 DownloadURL类的方法介绍
下面是一个下载“news.baidu.com”网页的例子:
//模拟IE8,以gb2312的编码格式下载“news.baidu.com”的内容。
String content = DownloadURL.downURL(“news.baidu.com”, “gb2312”, "IE8.0") ;
正文提取算法:
将网页源代码中的HTML格式信息删除,每行仅保留文本内容,即文本行。接下来,正文内容块的抽取可以被看成一个优化问题,即计算行 和
和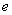 ,用于最大化低于行和高于行的非文本字符数,以及在行和行之间的行文本字符数,相应的就是最大化对应的目标函数,如公式所示。
,用于最大化低于行和高于行的非文本字符数,以及在行和行之间的行文本字符数,相应的就是最大化对应的目标函数,如公式所示。

其中,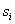 是原始网页源代码中行
是原始网页源代码中行 的总字符数,
的总字符数,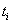 是剔除HTML标签后行的的文本字符数,
是剔除HTML标签后行的的文本字符数, 为网页源代码总行数,编号从0到
为网页源代码总行数,编号从0到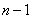 。
。
算法不需要针对特定网页书写正则表达式,不需要解析HTML以建立DOM结构,不被病态的HTML标签所累,可以高效、准确地定位网页正文内容块。
实验相关流程
1. 基本流程和模块大致如下图所示:

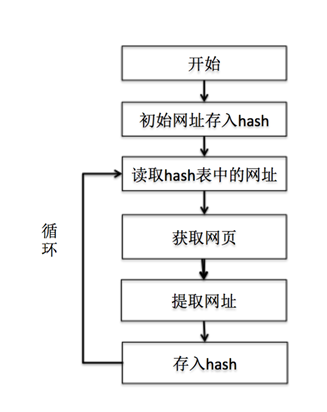
2. 爬取网页的基本流程如下图所示:
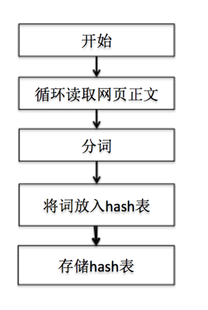
3. 倒排索引的建立流程如下图所示:
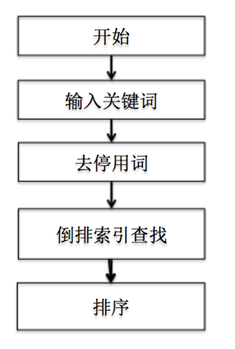
4. 搜索过程流程如下图所示:
实验结果及分析:
1. 爬取网页的结果如下:
初始网址:http://news.baidu.com
第一次爬取得到的网址保存到本地文件test0.txt中:
然后循环读取第一次爬取到的网址继续爬取网址得到第二次爬取到的网址,保存在本地文件test1.txt中:
考虑到时间和大小等因素,实验只爬取了两层网址即停止。
2. 提取正文:
由于保存网址时使用哈希表存取,再写入本地文件,哈希表中使用网址作为key值,所以不会出现重复网址,即实现了网址去重,所以提取正文时只需循环读取本地文件中保存的网址,用上面提到的正文提取方法提取正文即可,提取到的正文按顺序写入本地文件夹urlc中,文件中第一行为网页的网址,后面为网页正文,如下图所示:
本实验共提取了683篇正文:
3. 建立倒排索引:
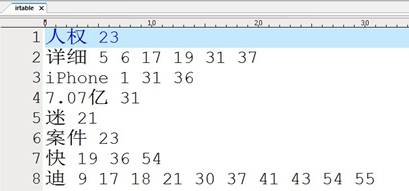
利用分词工具将提取到的正文分词,即使用分词工具将urlc文件夹中的文件内容分词,然后建立倒排索引,将建立好的倒排索引保存到本地文件irtable中:
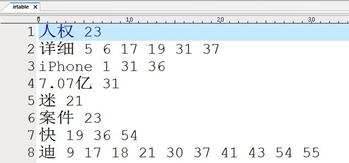
文件中第一项为关键词,后面为关键词出现的文档序号,由于文档中第一行为网址,所以根据文档序号即可以得到改关键词出现在哪一个网页中。如果该关键词在正文中多次出现,那么改文档号也会在改关键词key对应的value中多次出现,这样在搜索过程中即可根据该词在文档中出现的频率对输出结果排序,出现频率高的网页会在前面显示,出现频率低的网页会在后面显示。
4. 搜索:
例如我们搜索“我在南海的回忆”,首先根据停用词表会去除“在”、“的”这些对搜索没有意义的词汇:

经过去除停用词之后分词结果为:

然后根据倒排索引搜索,并根据出现频率排序,得到的结果如下:
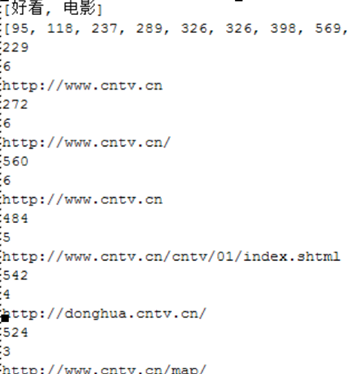
这3个词在第264篇文档中共出现了13次,网址为http://www.yuecheng.com/,
在第284篇文档中出现了12次,网址为http://news.cntv.cn/china/20120327/123486.shtml , 所以第264的网址排在了第284的前面。这里需要注意的是,第264篇文档并以一定就是urlc文件夹中名为con264.txt这篇文档,从网址我们可以看出:

网址并非http://www.yuecheng.com/。
因为在读取文件时,其读取顺序跟文件在文件夹中的排列顺序并不是完全一致的。
结论:
实验爬取网页使用的广度优先爬取,爬取了两层网页,并对爬取到的网页进行了正文提取,得到了623篇文档,对其进行了倒排索引的建立,实现了搜索功能。
对搜索结果根据在正文中出现的频率进行了排序。
5. 不足:
没有实现多线程进行网页爬取,使得系统比较缓慢,并且没有完成对多网页的去重处理,不能对重复网页进行甄别,使得存储大量的重复网页占用大量资源,并且没有考虑出度和入度,对网页进行等级划分,对于排序的权威性没有进行考虑,使得排序结果并不是十分智能;没有进行同义词扩展,使得很多信息都是不全面的,影响搜索结果。
并且整个系统都是根据命令行进行操控的,应该加入图形界面,并且都是存储在文本中,没有惊醒日志的记录,最好能够连接数据库,这样就能更加节约空间而且有数据的日志备份。
6. 存在问题
项目开展过程中,出现的主要问题是在爬取网页时遇到的编码问题,开始采用网上提供的爬取工具虽然可以爬取网页,但在爬取到的网页中有一部分存在乱码。于是到网上找了一些资料,获取网页编码后进行转码存储,最后虽然还是有一些问题,但在乱码率上已经有了大大的改观。
7. 感谢
最后要感谢秦老师这学期为我们讲授信息检索这么课程,让我对信息检索的认识有了很大的提高,并且是自己喜爱上了信息检索这个方向,对搜索引擎产生了很大的兴趣,提高了对研究生阶段的能力,感觉真的学到了很多宝贵的知识,了解很多前沿技术。在这个项目过程中我们遇到了很多的问题,通过师兄和同学的悉心指导,自己查找资料和与同学相互交流,解决了很多技术上的难点,并且不仅提高了自己的动手能力还对java语言有了更深入的了解。