分布式图形实验:机器学习框架以及云技术中的数据挖掘
摘要:
像MapReduce这类高级数据并行处理框架在对大规模数据处理系统的设计与实现进行简化的同时,并不能天然地或者高效的支持许多重要的数据挖掘和机器学习算法,在此基础上构建的机器学习系统往往是低效的。为填补这一空白,我们引入Graphlab,它实现了异步、动态的并行图计算模式,同时保证数据一致性,且在共享内存基础上具有很好的计算并行度。在本论文中,我们从Graphlab框架本身拓展到更具实际意义、更有挑战性的具有健壮数据一致性的分布式计算。
我们在图计算基础上扩展开发了流水线锁定和数据版本技术来减少网络拥塞和降低网络传输开销。同时,我们介绍了使用经典Chandy-Lamport快照算法实现的容错机制,并论证了可以在Graphlab框架基础上方便的实现。最后,我们评价了我们的分布式实现方案在亚马逊虚拟计算平台上的性能,并展示了相对于Hadoop的实现方案,亚马逊虚拟机群部署Graphlab系统会有1到2个数量级的性能提升。
1.介绍
伴随着机器学习和数据挖掘任务的规模增长、复杂度提升,急需一个能够在大规模集群上快速并行执行数据挖掘和机器学习任务的系统。同时,像亚马逊弹性计算云这样的云集算服务提供了在不具备实体集群情况下进行大规模节点计算的可能。不幸的是,设计、实现并且调试分布式机器学习和数据挖掘算法需要能够对云集群非常熟练的使用,这些对机器学习和数据挖掘专家们构成极其艰巨的挑战,因为这需要他们在实现复杂数据算法模型的同时能够处理并行竞争条件、死锁、分布式状态和通信协议等难题。
尽管如此,对大规模计算和数据存储的需求,已经驱使很多人就某些独立的算法模型,开发出新的并行分布式机器学习和数据挖掘系统(如引文2,14,15,30,35)。由于不同的研究团体重复性地解决相同的并行或者分布式计算问题,这些消耗时间和重复劳动的努力仅仅缓慢推动了这个领域的发展。因此,研究机器学习和数据挖掘的群体及组织需要一个高水平的面向很多机器学习和数据挖掘应用中都会遇到的异步、动态、图并行计算模式的,并且隐藏并行和分布式系统复杂设计逻辑的分布式系统模型。不幸的是,已经存在的高水平并行计算模式例如mapreduce,Dryad和Pregel都不能很好的支持满足这些苛刻的特制要求。为了帮助填补这一空白,我们介绍Graphlab计算模式,它在共享内存环境下,直接面向异步、动态和图并行计算。
在这篇文论中,我们将多核的Graphlab概念拓展到分布式环境下,并对分布式执行模型进行乐形式化的描述。我们在保证严格的一致性要求的基础上,探索出多种分布式执行模型的实现方式。为了实现这个目标,融入数据版本控制技术来间情网络拥堵,引入流水线分布式锁机制来降低网络传输开销。为了处理数据局部性和入口带来的挑战,我们引入原子图机制,以实现在分布式环境下的快速构建图数据结构。我们还通过经典的Chandy-Lamport快照算法为Graphlab框架增加容错机制,并证明了此机制在Graphlab概念中可以很容易被实现。
我们对我们在亚马逊弹性计算服务基础上使用C++优化实现的Graphlab系统进行乐综合性能分析。我们展示出在Graphlab框架上开发的应用程序性能相当于在Hadoop/mapreduce框架同等实现下的20-60倍,且能和使用MPI精心设计的实现相匹敌。我们的主要贡献如下:
一个机器学习和数据挖掘算法共性综述以及现有大数据框架的局限性。
一个修改过的可以部署在分布式环境下的Graphlab概念版本和执行模型。
两种可实现的新的分布式执行模型实施方案。
彩色引擎:使用图着色算法实现静态调度的高效、渐进、一致的执行。
加锁引擎:采用分布式流水线锁机制和延迟消除方法实现对动态、优先执行的支持。
通过两个快照方案实现容错。
在分布式Graphlab框架下实现三种高水准的机器学习算法。
对部署在拥有64个节点512个CPU的亚马逊弹性计算服务集群上的Graphlab系统进行大量评测,并和Hadoop、Pregel和MPI进行对比。
2.MLDM的算法性能:
在论文的这一部分,我们将详细叙述Graphlab概念下的大规模分布式机器学习-数据挖掘系统所独有的关键特性,并解释其他的分布式框架为何不具备这些特性。这些特性和分布式框架列在表格1中。
图结构计算:很多机器学习-数据挖掘方面的研究进展将焦点聚集在对数据相关性的建模上。通过对数据相关性进行建模,我们能够从包含噪音的数据中抽取出更多有价值的信息。例如,与仅仅孤立的处理购物者数据相比,对相似购物者的相关性建模能够做出更好的推荐。不幸的是,类似于Mapreduce的分布式数据处理模型并不能通用性的适应相关性计算需求,而这又是很多更高级机器学习-数据挖掘算法所需要的。尽管,很多时候可以将相关性计算映射到Mapreduce计算模式中,但是结果的转换较难实现,且很可能引入较难解决的效率问题。
因此,我们最近逐渐推出了类似于Pregel的天然支持数据相关性计算的Graphlab。这些计算模式采用顶点为中心的计算模型,计算被作为核心在每个顶点上执行。例如,Pregel是一个大规模同步通信的框架,顶点间通过消息进行通信。另一方面,Graphlab则建立在有序共享内存基础上,每个顶点均可以读写相邻顶点的数据。Graphlab稳定的并行执行为效率提供保障。开发者在使用Graphalb时可以不用管新并行数据的转移,而将主要注意力放在算法各部分的执行顺序上,由此,Graphlab会让图并行算法在设计和实现上更为简单。
异步迭代计算:很多重要的机器学习-数据挖掘算法需要迭代更新大量的参数。由于底层采用图数据结构,顶点或者边上的参数更新依赖于相邻顶点或者边上的参数。同步型系统在更新参数时会使用上一迭代步骤得到的参数值作为输入,同时将参数更新到集群中的各个节点上,而同样情形下,异步型系统可以使用最新的参数作为输入更新参数值。因此,异步系统给很多算法带来客观的性能收益。例如,很多线性系统(很多机器学习-数据挖掘算法都是线性系统)已经被论证如果能够解决异步问题,性能将会有很大的提升。除此之外,还有很多例子(如置信传播、最大期望化、随即优化等)经验上都是异步执行大大优于同步执行。如图1,我们论证乐为什么Pagerank在异步计算模式下可以加速收敛。
同步计算带来高昂的性能损失,这是因为每一个步骤的执行时间都是由运行最慢的机器决定的。最慢机器的苦逼表现可能由很多因素导致,包括负载和网络的不稳定,硬件变化,一机多用(云主机中首要因素)。如果使用同步机算,这些还有其他服务不稳定的运行将导致非常严重的性能问题。
另外,就算图谱结构可以被均匀的分割到各个节点,运行时,多个节点聚合会产生出额外的不确定性。例如,在实际应用中,理论上的图谱会受到密律分布的特征影响,运行时间曲线产生很大的倾斜,甚至图谱被随机切分。此外,每个节点真实的运作会以问题的特定方式对数据进行依赖。
因为MapReduce和Dryad这些大规模数据处理框架在设计时并不支持迭代计算,近期出现的Mapreduce扩展版本-Spark和其他大数据并行处理框架开始支持迭代计算。然而,这些框架并不支持分布式异步计算。大规模同步型分布式计算框架(BSP)如Pregel、Picolo和BPGL都不天然的支持异步计算模式。另外一方面,基于共享内存的Graphlab被设计成为一种天然支持异步迭代算法的高性能框架。
动态计算:很多机器学习-数据挖掘算法迭代计算的收敛性是不平衡的。例如,在参数最优化的计算中,很多参数会在少量的迭代后收敛,同时剩下的参数会在后面较多的迭代步骤后慢慢收敛。在图一(b)中我们绘制了PageRank算法达到收敛前的需要的更新次数曲线。很让人惊讶,大量的顶点仅需要一次迭代便收敛了,同时仅有百分之三的顶点需要超过十次的迭代才能收敛。引文39中的张演示优先计算可以对包含PageRank在内的图算法进行进一步深入的收敛优化。如果我们总是平均的更新所有的参数,那么会让很多已经收敛了的参数上重复计算以致浪费大量时间。相反的,如果我们能够尽早的将计算聚集在那些较难收敛的参数上,那么我们很可能能够加速它们的收敛。在图一(c)种我们以经验论证了如何通过动态调度加快Loopy置信度传播算法(一种很常见的机器学习-数据挖掘算法)的收敛速度。
一些近期推出的概念已经包含了动态计算的形式。例如,Pregel通过允许在每个计算步骤中跳过一些计算来允许一定限制的动态计算。其他的如Pearce和Graphlab则允许用户可以适应性的按照优先级进行计算。虽然Pregel和Graphlab都支持动态计算,但只有Graphlab允许带优先级的计算形式,同时具备动态地从邻接顶点获取全部信息的能力(3.2节将详细叙述)。在这篇文章中,我们放松一些引文24中描述的Graphlab最初的调度需求,以使分布式的FIFO队列和优先调度更有效率。
可串行化:因为我们知道所有的并行化执行都可以等化为串行执行,串行化能够消除很多同设计、实现和具体使用的并行算法(机器学习-数据挖掘)相关联的难题。此外,很多算法在并行化被允许的情况下可以得到加速收敛,甚至很多算法只有串行化才能保证正确性。例如,当允许并行竞争的时候,动态ALS算法(5.1节)是不稳定的。吉布斯采样,一个非常流行的机器学习-数据挖掘算法,要求串行化才能保证统计上正确性。
图表1:大规模计算框架对比图表。(a)引文38描述的Mapreduce的迭代扩展。(b)引文18提出的Dryad的迭代扩展。(c)Piccolo不提供保证一致性的机制,但是提出了一个允许用户同步写的弥补机制。
图1:(a)在16个处理器上构建了一个两千五百万个顶点和叁亿伍仟伍佰万条边的Web图后进行Pagerank算法实验产出的收敛比例图,纵轴为未收敛顶点数,采用指数刻度,横轴为所用时间。(b)分布式动态PageRank算法顶点更新的总次数。值得注意的是,多数顶点在一次迭代后就收敛了。(c)Loopy置信度传播算法在网页反作弊探测上的收敛比例。(d)在Netflix电影推荐问题上应用动态ALS算法,对比串行和非串行(有竞争的)执行。非串行执行表现出不稳定的收敛现象。
一个强制串行化计算的框架能够消除很多一致性引入的复杂度,这样能够让机器学习-数据挖掘专家把更多的注意力放在算法和模型的设计上。因为数据竞争会带来脏数据,在并行运行的程序中调试数学计算代码是一件非常困难的事情。很吃惊,很多异步框架例如Piccolo仅提供最初级的弥补数据竞争的机制。Graphlab支持宽范围的一致性环境,允许程序选择能够保证算法正确性的一致性级别。在第四部分,我们将介绍我们研发出的分布式环境下强制串行化的技术。
3. DIST. GRAPHLAB ABSTRACTION
Graphlab框架主要由三部分组成:数据图,更新函数和同步操作。(3.1节)图状数据表述用户可修改的程序状态,而且存储了易变的用户定义数据和经过编码的系数的相关性计算数据。(3.2节)更新函数表示用户计算和通过在被称作作用于的小范围重叠上下文中数据传输进行的数据图操作。(3.5节)最后,同步操作将同时创建全局聚合。为了在具体问题中使用Graphlab框架,我们将使用PageRank作为执行示例。
示例1,PageRank。PageRank算法递归定义了一个网页的排名值v,如下公式:
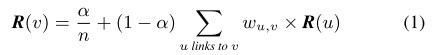
wu,v表示页面u链接到v的权重,R(u)代表页面u的Rank值,α 表示从页面u跳转到v的概率。PageRank算法迭代计算直到Rank值的变化小雨某个很小的阈值。
Graphlab框架存储程序状态为一个有向数据图。数据图G(V,E,D)是一个管理用户定义数据D的容器。这里我们说的数据是指模型参数、算法状态和统计数据。用户可以将特定的数据同图中的每个顶点v和边e(u到v)关联起来。然而,由于Graphlab框架不依赖边的方向,所以我们使用u?v表示u和v之间存在双向边。最后,图状数据是易变的。但同时图的结构是静态的,不会随着程序执行而改变。
示例2. 数据图来自互联网页图谱,每个顶点代表一个Web页面,每条边表示一个超链接。顶点数据Dv存储R(v),当前对PageRank值的估计,边 Du→v 存储着wu,v ,即有向链接的权重。
在Graphlab框架中,将计算以更新函数的形式进行编码。一个更新函数是一个无状态的程序,这个程序可以在一个顶点的范围内进行数据修改,也可以对其他顶点将要执行的更新函数进行调度。所谓v的作用域,指的是v中存储的数据和存储在所有邻接节点和邻接边中的数据,如图2(a)。Graphlab框架更新函数以顶点v和它的作用域Sv作为输入,返回数据Sv的一个新的版本和顶点集合T。
更新函数被执行完成后,被修改后的数据Sv会被更新到数据图中。被更新后的顶点u∈ T会按照将在3.3节中详细描述的执行语义,被申请执行更新函数f(u,Su)。
相比较引文25和19中采用的消息传递和数据流模型,Graphlab允许用户定义更新函数在邻接顶点和边上自由的完成数据的读取和修改。简单用户只需要编码,而不需要了解数据流动的方法。通过控制哪些顶点可以被返回加入到集合T并被执行,Graphlab更新函数能够高效的实现适应性计算。例如,一个更新函数可能只会在本身数据发生实质变化的时候才会返回它的邻接节点。
在动态计算的表现形式上,Pregel和Graphlab有着重要的不同。Graphlab将计算的调度和数据的移动分离开。因而,Graphlab更新函数可以访问邻接节点的数据,哪怕邻接节点没有调度执行这次更新。相反的,Pregel更新函数是消息初始化的,因此只能在消息中访问数据,表现能力受到限制。例如, 因为计算给定页面的PageRank值时需要所有的邻接页面,尽管一些邻接页面PR值没有发生变化,所以动态PageRank在Pregel很难被表示。因此,在Pregel中,向想临顶点发送数据的决定只能由接收顶点发起,而不能由发送顶点发起。然而,在Graphlab中,由于邻接顶点只负责调度,更新函数可以直接读取邻接顶点的数据,哪怕他们没有变化,所以可以很自然的表示拉取数据模型。
示例三。PageRank的更新函数计算相邻顶点排名值总和并提交作为当前顶点的排名值。这个算法是具有适应性的,只有当前顶点更新超过设定阈值时,邻居顶点才会被调度更新。
Graphlab执行模型,如算法2中展示,遵循一个简单的单循环语义。Graphlab框架的输入包括如数据图G = (V, E, D),一个更新函数,一个被执行的初始化了的顶点集合T。当T中海油顶点时,算法删除并执行一个顶点,并添加新的顶点到集合T。重复的顶点被忽略。最终在结算结束的时候,结果数据图和全局变量被返回给用户。
为了让分布式执行更加高效,我们放松了对共享内存Graphlab框架中执行顺序的要求,且允许Graphlab在运行时决定最好的顶点执行顺序。例如,RemoveNext(T) 可能选择返回能够使网络通信开销最小的顶点。Graphlab框架仅仅需要集合T中的所有顶点最终都能被执行,因为很多机器学习-数据挖掘算法能够通过优先级运行进行优化,Graphlab框架允许用户设计顶点集合T中顶点的优先级顺序。Graphlab运行时可能使用这些顶点优先级结合系统的目标优化顶点执行顺序。
通过允许多个处理器可以在同一个数据图中执行循环,同时删除或者执行不同的顶点,Graphlab框架是一个可以自动转换并行运行的丰富的串行模型。为了保证串行计算语义,我么必须保证重叠计算不同时运行。我们引入若干一致性模型,他们允许保证串行性的同时对并行运行进行优化。
Graphlab运行的时候需要确保串行执行。串行执行隐含着,当按照算法2进行运行时,必须相应的对更新函数进行串行调度,以在数据图中生成相同的数值。通过保证可串行性,Graphalb在分布式计算环境中简化了高度并行动态计算。
一个成功串行化的简单方法是确保同时执行的更新函数作用域不重叠。在引文24中,我们称它为完全的一致性模型,参见图2(b)。然而,完整的一致性限制了并行度的潜能,因为同时执行更新函数必须是在两个分离的顶点上(见图2(c))。然而,对于很多机器学习算法,更新函数不需要完全的对作用域内所有数据的读写访问。例如,PageRank更新公式1只需要读取边和相邻顶点。为了在保证串行性的同时提升并行度,Graphlab定义了边一致性模型。边一致性模型保证每次更新函数值近单独的读写访问自己的顶点和相邻边,而只读性访问邻接顶点,如图2(b)。因此,边一致性模型通过允许更新函数在松覆盖的作用域内安全并行运行来提升并行度。见图2(c)。最后,顶点一致性模型允许所有的更新函数可以并行的运行,提供最大程度的并行度。
在很多机器学习-数据挖掘算法中,在数据图中维护描述全局统计信息的数据是必需的。例如,很多统计推理算法需要追踪全局收敛预测器。为了满足这个需求,Graphlab框架定义了能够被更新函数读取但是需要同步操作写入的全局变量。同Pregel中的聚合想死,同步操作是一个定义在图中所有作用域上的相关的可交换求和。
不同于Pregel,同步操作引入了一个终结步骤。中介步骤用于支持类似于归一化的任务,这种任务在机器学习-数据挖掘算法中很常用。同样形成对比,Pregel在每个超级步后执行聚合操作,Graphlab同步操作持续在后台运行维持对全局变量的估计。
图2:(a)数据图和S1作用域。灰色的圆柱体表示用户定义的顶点和边数据,同时不规则的区域是包含顶点{1,2,3,4}的顶点1的作用域S1。对顶点1申请执行的更新函数能够读取和修改作用域S1内的所有数据(顶点数据D1,D2,D3,D4,边数据D1?2 , D1?3 , and D1?4 )。(b)各种一致性模型下,在顶点3执行的更新函数的读写权限。在完全一致性模型下,更新函数对整个作用域有完整的读写权限。在边一致性模型下,更新函数对邻接边数据仅有读取权限。最后,顶点一致性模型只对中心顶点数据有写权限。(c) 一致性和并行度之间的交换折中。黑色举行表示不能被重叠的写锁区域。更新函数可以在黑色顶点上并行执行。在更强的一致性模型下,仅有很少的函数可以同时运行。
因为每一个更新函数都可以访问全局变量,确保更新函数相关的同步操作的可串行化是昂贵的,而且普遍需要同步和中断所有计算。因为Graphlab更新函数有多种一致性级别,我们提供一致性或者非一致性同步计算选项。
结论
近期对于MLDM的实验进程已经强调了稀疏计算管理、异步运算、动态规划以及在大型MLDM问题中可串行的重要性。我们描述了分布式抽象形式不支持三种性能,为了提出这些内容,我们介绍了分布式图,一种书面图,平行式的分布式框架,这种框架的目标是那些MLDM应用中的重要指标。分布式图的拓展是通过改善这种执行模型、释放规划需求从而为离散环境共享离散共享抽象图的存储形式,并且提出了一种新的离散数据图、执行引擎、以及容错系统。
我们设计了一种离散式数据图形成了两段式分区形式,这种分区可以有效的加载平衡且离散的进入可变字符串的部署中。我们设计了两种图形实验:一种是彩色动力,它是部分同步的,并且假定了一种彩色徒弟存在性。另一种是锁定动力,它是一种完全异步的,支持常规图结构同时依赖一种特殊基于图形流水线的锁系统,用来隐藏网络中的潜在因素。最后,我们介绍了两种容错系统,一种是同步快照算法,一种异步快照算法。他们是基于能够快速应用常规图形实验基础的Chandy-Lamport算法。
我们在C++中执行了离散型图形实验并且评估了它在三种已达到最高水品的MLDM算法上运行了真实的数据。这种评估被执行在Amazon Ec上运行了高达512个在64HPC机器上的程序。我们演示了离散图胜过Hadoop20到60倍。同时可以与定制的MPI相媲美。
将来的工作包括扩展抽象概念以及运行时间来支持动态的进化图,以及扩展在数据图中存储的拓展。这些点将会是离散图形实验室能够持续存储并且在很多真实的应用中优化数据的计算时间。最后,我们相信动态异步平行图的评估将会是一个在大型机器学习和数据挖掘系统中的关键组成部分。因此将来这些技术在理论和应用中的实验将会帮助定义这个正在出现的大学习领域。