《数据仓库与数据挖掘》
实验报告册
20 - 20 学年 第 学期
班 级:
学 号:
姓 名:
目录
实验一 Microsoft SQL Server Analysis Services的使用................................. 3
实验二 使用WEKA进行分类与预测.............................................................................. 5
实验三 使用WEKA进行关联规则与聚类分析............................................................... 6
实验四 数据挖掘算法的程序实现................................................................................ 7
实验一 Microsoft SQL Server Analysis Services的使用
实验类型:验证性 实验学时:4
实验目的:
学习并掌握Analysis Services的操作,加深理解数据仓库中涉及的一些概念,如多维数据集,事实表,维表,星型模型,雪花模型,联机分析处理等。
实验内容:
在实验之前,先通读自学SQL SERVER自带的Analysis Manager概念与教程。按照自学教程的步骤,完成对FoodMart数据源的联机分析。建立、编辑多维数据集,进行OLAP操作,看懂OLAP的分析数据。
实验步骤:
1、 启动联机分析管理器:
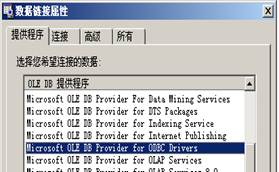
2、 建立系统数据源连接。

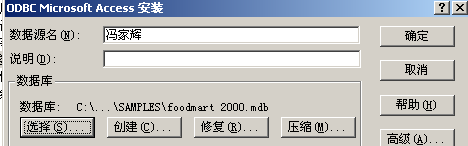
3、 建立数据库和数据源,多维数据集
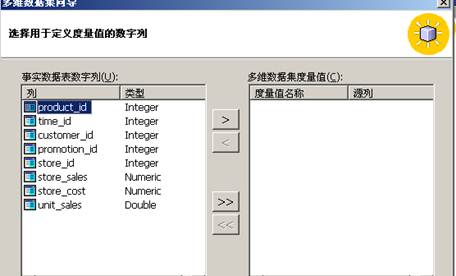
编辑多维数据集
4、 设计存储和处理多维数据集
5、 浏览多维数据集中的数据
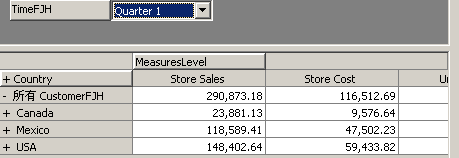
按时间筛选数据

实验小结:
实验二 使用WEKA进行分类与预测
实验类型:综合性 实验学时:4
实验目的:
掌握数据挖掘平台WEKA的使用。综合运用数据预处理、分类与预测的挖掘算法、结果的解释等知识进行数据挖掘。从而加深理解课程中的相关知识点。
实验内容:
阅读并理解WEKA的相关中英文资料,熟悉数据挖掘平台WEKA,针对实际数据,能够使用WEKA进行数据的预处理,能选择合适的分类与预测算法对数据进行分析,并能解释分析结果。
实验步骤:
1、在开始->程序->启动WEKA,进入Explorer界面,熟悉WEKA的界面功能。
2、选择数据集(实验中的数据可以从网络获取),如泰坦尼克号数据集,将要处理的数据集转换成WEKA能处理的格式,如 .ARFF格式。思考:如何将其它格式的数据文件(如.XLS)转换为.ARFF格式?
3、根据选择的数据挖掘算法,如果有必要,在Weka Explorer界面,Preprocess选项中,进行相应的数据预处理。要求:熟悉Preprocess界面中各个功能选项的含义,理解数据的特征。思考:在filter中,supervised和unsupervised的区别?
4、在Weka Explorer界面,单击Visualize选项,进入WEKA 的可视化页面,可以对当前的关系作二维散点图式的可视化浏览。要求: 熟悉Visualize界面中各个功能选项的含义,理解可视化图形的意义。
5、选择相应的分类与预测挖掘算法对数据集进行分析,进行算法参数的具体设置。如利用WEKA->Classifier->trees->J48 决策树算法,对泰坦尼克号数据集进行分析;如利用回归模型对连续数值进行预测。要求:对你选择的分类和预测算法思想分别进行介绍,熟悉classify界面的内容,对classifier中的参数含义分别进行介绍。思考:classifier->trees->J48算法与classifier->trees->id3算法的区别与联系。
6、对分析所获得的结果进行解释。如,根据决策树和分类规则尝试讨论泰坦尼克号幸存者的特征。理解评估分类和预测优劣的一些准则。
实验小结:
实验中遇到的问题及解决办法、心得、体会等等...
思考题
给出数据挖掘中分类与预测成功应用的案例,并简要介绍。
实验三 使用WEKA进行关联规则与聚类分析
实验类型:综合性 实验学时:4
实验目的:
掌握数据挖掘平台WEKA的使用。综合运用数据预处理、关联规则与聚类的挖掘算法、结果的解释等知识进行数据挖掘。从而加深理解课程中的相关知识点。
实验内容:
阅读并理解WEKA的相关中英文资料,熟悉数据挖掘平台WEKA,针对实际数据,能够使用WEKA进行数据的预处理,了解属性选择,能选择合适的关联规则与聚类算法对数据进行分析,并能解释分析结果。
实验步骤:
1、在开始->程序->启动WEKA,进入Explorer界面,熟悉WEKA的界面功能。
2、选择数据集(实验中的数据可以从网络获取),将要处理的数据集转换成WEKA能处理的格式,如 .ARFF格式。根据选择的数据挖掘算法,如果有必要,在Weka Explorer界面,Preprocess选项中,进行相应的数据预处理。
3、在Weka Explorer界面,单击Select attributes选项,进入WEKA 的属性选择页面。要求: 了解该界面中主要功能选项的含义,理解该界面的功能。
5、在Weka Explorer界面,单击Associate选项,进入WEKA 的关联规则页面。选择一个关联规则算法对数据集进行分析,进行算法参数的具体设置。要求:对你选择的关联规则算法思想进行介绍,熟悉Associate界面的内容,对Associate中的参数含义分别进行介绍。理解用来衡量规则的关联程度的几个度量指标。理解并解释分析所获得的结果。
6、在Weka Explorer界面,单击Cluster选项,进入WEKA 的聚类页面。选择一个聚类算法(如K均值)对数据集进行分析,进行算法参数的具体设置。要求:对你选择的聚类算法思想进行介绍,熟悉Cluster界面的内容,对Cluster中的参数含义进行介绍。理解并解释分析所获得的结果。
实验小结:
实验中遇到的问题及解决办法、心得、体会等等...
思考题
给出数据挖掘中关联规则与聚类成功应用的一些案例,并简要介绍。
实验四 数据挖掘算法的程序实现
实验类型:设计性 实验学时:4
实验目的:
运用数据挖掘、程序设计等相关知识,选择一个数据挖掘的常用算法进行程序设计实现。加深对数据挖掘算法基本原理、详细执行过程和具体应用情况的理解。
实验内容:
采用任何一种自己熟悉的编程语言,完成算法的程序设计,并在每个程序设计语句后面进行详细的注释。能够运用实现的算法来解决某个具体的问题,得到并解释程序运行的结果。
推荐的算法:
1 关联规则:Apriori算法
2 分类与预测:ID3, C4.5, KNN, BP,
3 聚类:k-means
实验步骤:
1. 提前预习,选择算法,理解原理。
2. 针对具体问题,选择熟悉的编程平台,进行算法的程序实现,尽量在每个程序语句后面进行详细注释。
3. 自己选择某个数据集,应用实现的算法得到结果并解释。
实验小结:
实验中遇到的问题及解决办法、心得、体会等等...
第二篇:实验报告
《数据仓库与数据挖掘》
实验报告册
20 09 - 20 10 学年 第 二 学期
班 级: T773-2
学 号: 20070730206
姓 名: 王江波
授课教师: 杨丽华 实验教师: 杨丽华
实验学时: 16 实验组号: 1
信息管理系
目录
实验一 Microsoft SQL Server Analysis Services的使用... 3
实验二 使用WEKA进行分类与预测... 5
实验三 使用WEKA进行关联规则与聚类分析... 6
实验四 数据挖掘算法的程序实现... 7
实验一 Microsoft SQL Server Analysis Services的使用
实验类型:验证性 实验学时:4
实验目的:
学习并掌握Analysis Services的操作,加深理解数据仓库中涉及的一些概念,如多维数据集,事实表,维表,星型模型,雪花模型,联机分析处理等。
实验内容:
在实验之前,先通读自学SQL SERVER自带的Analysis Manager概念与教程。按照自学教程的步骤,完成对FoodMart数据源的联机分析。建立、编辑多维数据集,进行OLAP操作,看懂OLAP的分析数据。
实验步骤:
1、启动联机分析管理器:开始->程序->Microsoft SQL Server->Analysis Manager。
2、按照 Analysis Service的自学教程完成对FoodMart数据源的联机分析。
3、在开始-设置-控制面板-管理工具-数据源(ODBC),数据源管理器中设置和源数据的连接,“数据源名”为T7730206 王江波。
4、在开始-设置-控制面板-管理工具-服务-MSSQLServerOLAPService, 启动该项服务。
在Analysis Manager中,单击服务器名称,即可建立与 Analysis Servers 的连接;否则,在Analysis Servers 上单击右键,注册服务器,在服务器名称中输入本地计算机的名字 pc08。本地计算机的名字可右击:我的电脑,选择属性,网络标志,里面有本地计算机的名字。建立新的数据库,数据库名与数据源名相同 ,为T7730206 王江波。在你所建立的数据库中,单击“新数据源”,和早期在 ODBC 数据源管理器中建立的数据源连接。
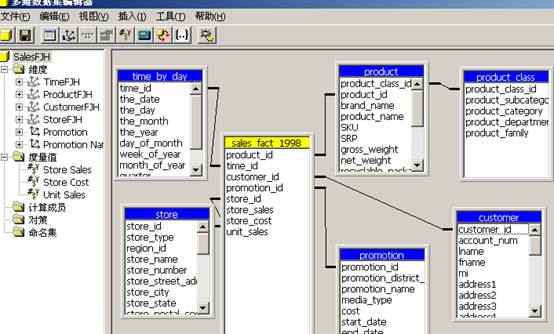
5、假设你是 FoodMart Corporation 的数据库管理员。FoodMart 是一家大型的连锁店,在美国、墨西哥和加拿大有销售业务。市场部想要按产品和顾客分析 1998 年进行的所有销售业务数据。要求建立Sales多维数据集,多维数据集是由维度和事实定义的。
其维度有“Time”维度、“Product”维度、“Customer”维度、“Store”维度和“Promotion” 维度,事实表为sales_fact_1998,事实表中的度量为:store_sales、store_cost、unit_sales。理解每个维度的级别。
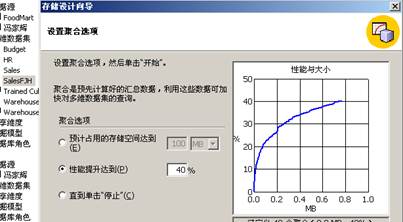
6、可以使用多维数据集编辑器对现有多维数据集进行更改。在使用或浏览多维数据集中的数据之前,要求设计多维数据集中的数据和聚合的存储选项。即设计好 Sales 多维数据集的结构之后,需要选择要使用的存储模式并指定要存储的预先计算好的值的数量。完成此项操作之后,需要用数据填充多维数据集。这里选择 MOLAP 作为存储模式,创建 Sales 多维数据集的聚合设计,然后处理该多维数据集。处理 Sales 多维数据集时将从 ODBC 源中装载数据并按照聚合设计中的定义计算汇总值。
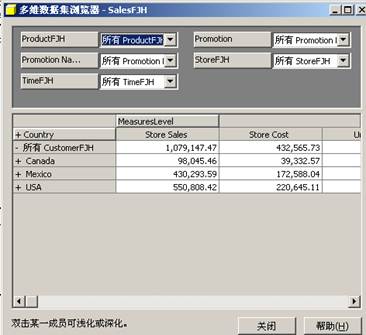
7、使用多维数据集浏览器,可以用不同的方式查看数据:可以筛选出可见的维度数据量,可以深化以看到数据的细节,还可以浅化以看到较为概括的数据。这里可以使用多维数据集浏览器对 Sales 数据进行切片和切块操作。要求理解OLAP操作下数据的含义,从而可以分析数据。
8、人力资源部想按商店来分析雇员的工资。本节将建立一个 HR(人力资源)多维数据集,以进行雇员工资分析。将把 Employee(雇员)维度创建为父子维度。然后使用该维度以及常规维度来生成 HR 多维数据集。其中,事实数据表为salary(工资), 维度为Employee(雇员)、Store(商店)、Time(时间)。了解如何建立父子维度。
9、建立计算成员和成员属性。在Sales 多维数据集中建立“Average price” 计算成员,思考建立该计算成员的目的。市场部希望将 Sales 多维数据集分析功能扩展到根据客户的下列特征分析客户销售数据:性别、婚姻状况、教育程度、年收入、在家子女数和会员卡。需要向 Customer 维度添加以下六个成员属性:Gender(性别)、Marital status(婚姻状况)、Education(教育程度)、Yearly Income(年收入)、Num Children At Home(在家子女数)和 Member Card(会员卡)。这些成员属性将限制 Customer 维度中的每个成员。 理解什么是计算成员和成员属性,为什么要建立?
10、已经为客户维度添加了六个成员属性,可以创建一个带有 Yearly Income(年收入)成员属性的虚拟维度,然后将这个新创建的维度添加到 Sales 多维数据集中。使用虚拟维度,可以基于多维数据集中的维度成员的成员属性对多维数据集数据进行分析。 其优点是不占用磁盘空间或处理时间。
11、理解多维数据集角色和数据库角色的联系和区别、建立角色的目的。
12、查看销售多维数据集的元数据和维度的元数据,加深对元数据概念和分类的理解。
实验小结:
思考题
给出一个数据仓库成功应用的案例,包括所解决的问题,功能等。
实验二 使用WEKA进行分类与预测
实验类型:综合性 实验学时:4
实验目的:
掌握数据挖掘平台WEKA的使用。综合运用数据预处理、分类与预测的挖掘算法、结果的解释等知识进行数据挖掘。从而加深理解课程中的相关知识点。
实验内容:
阅读并理解WEKA的相关中英文资料,熟悉数据挖掘平台WEKA,针对实际数据,能够使用WEKA进行数据的预处理,能选择合适的分类与预测算法对数据进行分析,并能解释分析结果。
实验步骤:
1、在开始->程序->启动WEKA,进入Explorer界面,熟悉WEKA的界面功能。
2、选择数据集,将要处理的数据集转换成WEKA能处理的格式 .ARFF格式。在实验中我用的数据集是bank-data.csv,然后把它转化成了WEKA能处理的格式bank-data.arff 。思考:如何将其它格式的数据文件转换为.ARFF格式?有两种方式:(1)用WEKA 3.5中提供了一个“Arff Viewer”模块,我们可以用它打开一个CSV文件将进行浏览,然后另存为ARFF文件。(2)进入“Simple CLI”模块,在窗口的最下方输入java weka.core.converters.CSVLoader bank-data.csv > bank-data.arff,就可以把数据集bank-data.csv转换成WEKA能处理的bank-data.arff。
3、根据选择的数据挖掘算法,如果有必要,在Weka Explorer界面,Preprocess选项中,进行相应的数据预处理。我选用的数据集bank-data.arff总共有11个属性 其中属性ID对数据挖掘来说是没有意义的就把把它去除掉,剩下10个属性。这10个属性中“age”,“income”和“children”三个属性的属性值是数值型的,在对数据集进行分类和预测时我采用的算法只能处理所有的属性都是分类型的情况,因此要对这三个属性进行离散化。思考:在filter中,supervised和unsupervised的区别?答:选择supervised 需要设置一个class属性,而unsupervised却忽略class属性。
4、在Weka Explorer界面,单击Visualize选项,进入WEKA 的可视化页面,可以对当前的关系作二维散点图式的可视化浏览。
5、选择相应的分类与预测挖掘算法对数据集进行分析,进行算法参数的具体设置。实验中我选择Classifier->trees->J48 决策树算法对数据集bank-data.arff进行分析,参数设置为classifiers.trees.J48 -C 0.25 -M 2(confidence factor=0.25,minNumobj=2)。J48算法由决策树生成算法,剪枝算法,规则生成算法3部分组成。决策树生成树算法依据信息墒理论,选择当前样本集中具有最大信息增益率的属性作为测试属性不断对样本集进行划分,最终构造出一棵完全决策树;剪枝算法采用错误的剪枝方法对完全决策树进行修剪,得到简化决策树;规则生成算法把完全决策树转化成一组if..then 规则集并进行化简。思考:classifier->trees->J48算法与classifier->trees->id3算法的区别与联系。答:J48算法是ID3算法的改进,增加了对连续型的属性,属性值空缺的情况的处理;而ID3算法只适用于所有属性都是离散字段的情况。
6、对分析所获得的结果进行解释。在用J48对数据集进行分类时采用了10折交叉验证(10-fold cross validation)来选择和评估模型(选取了pep属性作为测试属性,其属性值有两个:YES,NO)。一部结果如下:
Correctly Classified Instances 206 68.6667 %(这是模型的准确率)
Incorrectly Classified Instances 94 31.3333 %(这是模型的出错率)
=== Confusion Matrix ===
a b <-- classified as
74 64 | a = YES
30 132 | b = NO
这个矩阵是说,原本“pep”是“YES”的实例,有74个被正确的预测为“YES”,有64个错误的预测成了“NO”;原本“pep”是“NO”的实例,有30个被错误的预测为“YES”,有132个正确的预测成了“NO”。74+64+30+132 = 300是实例总数,而(74+132)/300 = 0.68667正好是正确分类的实例所占比例。这个矩阵对角线上的数字越大,说明预测得越好。
实验小结:
思考题
给出数据挖掘中分类与预测成功应用的案例,并简要介绍。
实验三 使用WEKA进行关联规则与聚类分析
实验类型:综合性 实验学时:4
实验目的:
掌握数据挖掘平台WEKA的使用。综合运用数据预处理、关联规则与聚类的挖掘算法、结果的解释等知识进行数据挖掘。从而加深理解课程中的相关知识点。
实验内容:
阅读并理解WEKA的相关中英文资料,熟悉数据挖掘平台WEKA,针对实际数据,能够使用WEKA进行数据的预处理,了解属性选择,能选择合适的关联规则与聚类算法对数据进行分析,并能解释分析结果。
实验步骤:
1、在开始->程序->启动WEKA,进入Explorer界面,熟悉WEKA的界面功能。
2、选择数据集,将要处理的数据集转换成WEKA能处理的格式。在这次实验中我选用的数据集还是上次实验中的用到的数据集bank-data.arff,把属性ID除去,在进行关联规则分析时还要对age”,“income”和“children”三个数值型属性进行离散化;而在聚类分析的时候把“children”属性改为分类型。
3、在Weka Explorer界面,单击Select attributes选项,进入WEKA 的属性选择页面。
5、在Weka Explorer界面,单击Associate选项,进入WEKA 的关联规则页面。选择一个关联规则算法对数据集进行分析,进行算法参数的具体设置。我选择的算法为Apriori算法,参数设置为Apriori -N 5 -T 1 -C 1.5 -D 0.05 -U 1.0 -M 0.1 -S -1.0 -c -1(lowerBoundMinSupport=0.1,upperBoundMinSupport=1,“metricType”设为lift,“minMetric”设为1.5,“numRules”设为5,选择排在前5的那些关联规则,此外lift(x →y)=p(x∪y)/p(x)*p(y)).
Apriori算法有两步:(1). 从事务数据库中挖掘出所有频繁项集;(2). 基于第1步挖掘到的频繁项集,继续挖掘出全部的频繁关联规则。得到的结果如下:
1. age='(-inf-34]' 195 ==> income='(-inf-24386]' current_act=YES 138 conf:(0.71) < lift:(1.97)> lev:(0.11) [68] conv:(2.16)
2. income='(-inf-24386]' current_act=YES 215 ==> age='(-inf-34]' 138 conf:(0.64) < lift:(1.97)> lev:(0.11) [68] conv:(1.86)
3. income='(-inf-24386]' 285 ==> age='(-inf-34]' car=NO 100 conf:(0.35) < lift:(1.97)> lev:(0.08) [49] conv:(1.26)
4. age='(-inf-34]' car=NO 107 ==> income='(-inf-24386]' 100 conf:(0.93) < lift:(1.97)> lev:(0.08) [49] conv:(7.02)
5. age='(-inf-34]' 195 ==> income='(-inf-24386]' pep=NO 111 conf:(0.57) < lift:(1.94)> lev:(0.09) [53] conv:(1.62) 结果中这五个关联规则里都列出来了关联度的四项指标:置信度conf=p(x|y),;lift(x →y)=p(x∪y)/p(x)*p(y); Leverage,lev= p(x∪y)- p(x)*p(y); Conviction conv=p(x)p(!y)/p(x∪!y).
6、在Weka Explorer界面,单击Cluster选项,进入WEKA 的聚类页面。选择一个聚类算法对数据集进行分析,进行算法参数的具体设置。我选择的算法是K-means,参数设置为SimpleKMeans -N 6 -S 200(numClusters=6即分为六个类,seed=200,之所以设置seed的值为200,因为此时平方误差和最小)。K-means 算法首先随机的指定K个簇中心。然后:1)将每个实例分配到距它最近的簇中心,得到K个簇;2)计分别计算各簇中所有实例的均值,把它们作为各簇新的簇中心。重复1)和2),直到K个簇中心的位置都固定,簇的分配也固定。运行的结果如下:
Number of iterations: 6
Within cluster sum of squared errors: 1551.726508653268(这是平方误差之和)
Clustered Instances
0 175 ( 29%)
1 85 ( 14%)
2 53 ( 9%)
3 87 ( 14%)
4 130 ( 22%)
5 70 ( 12%)(每个类的包含的实例个数以及占总实例的百分比)
实验小结:
思考题
给出数据挖掘中关联规则与聚类成功应用的一些案例,并简要介绍。
实验四 数据挖掘算法的程序实现
实验类型:设计性 实验学时:4
实验目的:
运用数据挖掘、程序设计等相关知识,选择一个数据挖掘的常用算法进行程序设计实现。加深对数据挖掘算法基本原理、详细执行过程和具体应用情况的理解。
实验内容:
采用任何一种自己熟悉的编程语言,完成算法的程序设计,并在每个程序设计语句后面进行详细的注释。能够运用实现的算法来解决某个具体的问题,得到并解释程序运行的结果。
在这次实验中我用的是JAVA语言实现关联规则中的Apriori算法。具体代码如下:
Apriori算法的核心实现类为AprioriAlgorithm,代码如下:
public class AprioriAlgorithm {
private Map<Integer, Set<String>> txDatabase; // 事务数据库
private Float minSup; // 最小支持度
private Float minConf; // 最小置信度
private Integer txDatabaseCount; // 事务数据库中的事务数
private Map<Integer, Set<Set<String>>> freqItemSet; // 频繁项集集合
private Map<Set<String>, Set<Set<String>>> assiciationRules; // 频繁关联规则集合
public AprioriAlgorithm(Map<Integer, Set<String>> txDatabase, Float minSup,
Float minConf) {
this.txDatabase = txDatabase;
this.minSup = minSup;
this.minConf = minConf;
this.txDatabaseCount = this.txDatabase.size();
freqItemSet = new TreeMap<Integer, Set<Set<String>>>();
assiciationRules = new HashMap<Set<String>, Set<Set<String>>>();
}
public Map<Set<String>, Float> getFreq1ItemSet() {
Map<Set<String>, Float> freq1ItemSetMap = new HashMap<Set<String>, Float>();
Map<Set<String>, Integer> candFreq1ItemSet = this.getCandFreq1ItemSet();
Iterator<Map.Entry<Set<String>, Integer>> it = candFreq1ItemSet
.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Set<String>, Integer> entry = it.next();
// 计算支持度
Float supported = new Float(entry.getValue().toString())
/ new Float(txDatabaseCount);
if (supported >= minSup) {
freq1ItemSetMap.put(entry.getKey(), supported);}
}
return freq1ItemSetMap;
}
public Map<Set<String>, Integer> getCandFreq1ItemSet() {
Map<Set<String>, Integer> candFreq1ItemSetMap = new HashMap<Set<String>, Integer>();
Iterator<Map.Entry<Integer, Set<String>>> it = txDatabase.entrySet()
.iterator();
// 统计支持数,生成候选频繁1-项集
while (it.hasNext()) {
Map.Entry<Integer, Set<String>> entry = it.next();
Set<String> itemSet = entry.getValue();
for (String item : itemSet) {
Set<String> key = new HashSet<String>();
key.add(item.trim());
if (!candFreq1ItemSetMap.containsKey(key)) {
Integer value = 1;
candFreq1ItemSetMap.put(key, value);
} else {
Integer value = 1 + candFreq1ItemSetMap.get(key);
candFreq1ItemSetMap.put(key, value); } }
}
return candFreq1ItemSetMap;
}
public Set<Set<String>> aprioriGen(int m, Set<Set<String>> freqMItemSet) {
Set<Set<String>> candFreqKItemSet = new HashSet<Set<String>>();
Iterator<Set<String>> it = freqMItemSet.iterator();
Set<String> originalItemSet = null;
while (it.hasNext()) {
originalItemSet = it.next();
Iterator<Set<String>> itr = this.getIterator(originalItemSet,
freqMItemSet);
while (itr.hasNext()) {
Set<String> identicalSet = new HashSet<String>(); // 两个项集相同元素的集合(集合的交运算)
identicalSet.addAll(originalItemSet);
Set<String> set = itr.next();
identicalSet.retainAll(set); // identicalSet中剩下的元素是identicalSet与set集合中公有的元素
if (identicalSet.size() == m - 1) { // (k-1)-项集中k-2个相同
Set<String> differentSet = new HashSet<String>(); // 两个项集不同元素的集合(集合的差运算)
differentSet.addAll(originalItemSet);
differentSet.removeAll(set); // 因为有k-2个相同,则differentSet中一定剩下一个元素,即differentSet大小为1
differentSet.addAll(set); // 构造候选k-项集的一个元素(set大小为k-1,differentSet大小为k)
candFreqKItemSet.add(differentSet); // 加入候选k-项集集合
}
}
}
return candFreqKItemSet;
}
private Iterator<Set<String>> getIterator(Set<String> itemSet,
Set<Set<String>> freqKItemSet) {
Iterator<Set<String>> it = freqKItemSet.iterator();
while (it.hasNext()) {
if (itemSet.equals(it.next())) {
break;
}
}
return it;
}
public Map<Set<String>, Float> getFreqKItemSet(int k,
Set<Set<String>> freqMItemSet) {
Map<Set<String>, Integer> candFreqKItemSetMap = new HashMap<Set<String>, Integer>();
// 调用aprioriGen方法,得到候选频繁k-项集
Set<Set<String>> candFreqKItemSet = this.aprioriGen(k - 1, freqMItemSet);
// 扫描事务数据库
Iterator<Map.Entry<Integer, Set<String>>> it = txDatabase.entrySet().iterator();
// 统计支持数
while (it.hasNext()) {
Map.Entry<Integer, Set<String>> entry = it.next();
Iterator<Set<String>> kit = candFreqKItemSet.iterator();
while (kit.hasNext()) {
Set<String> kSet = kit.next();
Set<String> set = new HashSet<String>();
set.addAll(kSet);
set.removeAll(entry.getValue()); // 候选频繁k-项集与事务数据库中元素做差元算
if (set.isEmpty()) { // 如果拷贝set为空,支持数加1
if (candFreqKItemSetMap.get(kSet) == null) {
Integer value = 1;
candFreqKItemSetMap.put(kSet, value);
} else {
Integer value = 1 + candFreqKItemSetMap.get(kSet);
candFreqKItemSetMap.put(kSet, value);
}
}
}
}
// 计算支持度,生成频繁k-项集,并返回
return support(candFreqKItemSetMap);
}
public Map<Set<String>, Float> support(
Map<Set<String>, Integer> candFreqKItemSetMap) {
Map<Set<String>, Float> freqKItemSetMap = new HashMap<Set<String>, Float>();
Iterator<Map.Entry<Set<String>, Integer>> it = candFreqKItemSetMap
.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Set<String>, Integer> entry = it.next();
// 计算支持度
Float supportRate = new Float(entry.getValue().toString())
/ new Float(txDatabaseCount);
if (supportRate < minSup) { // 如果不满足最小支持度,删除
it.remove();
} else {
freqKItemSetMap.put(entry.getKey(), supportRate);
}
}
return freqKItemSetMap;
}
public void mineFreqItemSet() {
// 计算频繁1-项集
Set<Set<String>> freqKItemSet = this.getFreq1ItemSet().keySet();
freqItemSet.put(1, freqKItemSet);
// 计算频繁k-项集(k>1)
int k = 2;
while (true) {
Map<Set<String>, Float> freqKItemSetMap = this.getFreqKItemSet(k,
freqKItemSet);
if (!freqKItemSetMap.isEmpty()) {
this.freqItemSet.put(k, freqKItemSetMap.keySet());
freqKItemSet = freqKItemSetMap.keySet();
} else {
break;
}
k++;
}
}
public void mineAssociationRules() {
freqItemSet.remove(1); // 删除频繁1-项集
Iterator<Map.Entry<Integer, Set<Set<String>>>> it = freqItemSet
.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, Set<Set<String>>> entry = it.next();
for (Set<String> itemSet : entry.getValue()) {
// 对每个频繁项集进行关联规则的挖掘
mine(itemSet);
}
}
}
public void mine(Set<String> itemSet) {
int n = itemSet.size() / 2; // 根据集合的对称性,只需要得到一半的真子集
for (int i = 1; i <= n; i++) {
// 得到频繁项集元素itemSet的作为条件的真子集集合
Set<Set<String>> properSubset = ProperSubsetCombination
.getProperSubset(i, itemSet);
// 对条件的真子集集合中的每个条件项集,获取到对应的结论项集,从而进一步挖掘频繁关联规则
for (Set<String> conditionSet : properSubset) {
Set<String> conclusionSet = new HashSet<String>();
conclusionSet.addAll(itemSet);
conclusionSet.removeAll(conditionSet); // 删除条件中存在的频繁项
confide(conditionSet, conclusionSet); // 调用计算置信度的方法,并且挖掘出频繁关联规则
}
}
}
public void confide(Set<String> conditionSet, Set<String> conclusionSet) {
// 扫描事务数据库
Iterator<Map.Entry<Integer, Set<String>>> it = txDatabase.entrySet()
.iterator();
// 统计关联规则支持计数
int conditionToConclusionCnt = 0; // 关联规则(条件项集推出结论项集)计数
int conclusionToConditionCnt = 0; // 关联规则(结论项集推出条件项集)计数
int supCnt = 0; // 关联规则支持计数
while (it.hasNext()) {
Map.Entry<Integer, Set<String>> entry = it.next();
Set<String> txSet = entry.getValue();
Set<String> set1 = new HashSet<String>();
Set<String> set2 = new HashSet<String>();
set1.addAll(conditionSet);
set1.removeAll(txSet); // 集合差运算:set-txSet
if (set1.isEmpty()) { // 如果set为空,说明事务数据库中包含条件频繁项conditionSet
// 计数
conditionToConclusionCnt++;
}
set2.addAll(conclusionSet);
set2.removeAll(txSet); // 集合差运算:set-txSet
if (set2.isEmpty()) { // 如果set为空,说明事务数据库中包含结论频繁项conclusionSet
// 计数
conclusionToConditionCnt++;
}
if (set1.isEmpty() && set2.isEmpty()) {
supCnt++;
}
}
// 计算置信度
Float conditionToConclusionConf = new Float(supCnt)
/ new Float(conditionToConclusionCnt);
if (conditionToConclusionConf >= minConf) {
if (assiciationRules.get(conditionSet) == null) { // 如果不存在以该条件频繁项集为条件的关联规则
Set<Set<String>> conclusionSetSet = new HashSet<Set<String>>();
conclusionSetSet.add(conclusionSet);
assiciationRules.put(conditionSet, conclusionSetSet);
} else {
assiciationRules.get(conditionSet).add(conclusionSet);
}
}
Float conclusionToConditionConf = new Float(supCnt)
/ new Float(conclusionToConditionCnt);
if (conclusionToConditionConf >= minConf) {
if (assiciationRules.get(conclusionSet) == null) { // 如果不存在以该结论频繁项集为条件的关联规则
Set<Set<String>> conclusionSetSet = new HashSet<Set<String>>();
conclusionSetSet.add(conditionSet);
assiciationRules.put(conclusionSet, conclusionSetSet);
} else {
assiciationRules.get(conclusionSet).add(conditionSet);
}
}
}
public Map<Integer, Set<Set<String>>> getFreqItemSet() {
return freqItemSet;
}
public Map<Set<String>, Set<Set<String>>> getAssiciationRules() {
return assiciationRules;
}
}
ProperSubsetCombination类是一个辅助类,在挖掘频繁关联规则的过程中,用于生成一个频繁项集元素的非空真子集,实现如下:
public class ProperSubsetCombination {
private static String[] array;
private static BitSet startBitSet; // 比特集合起始状态
private static BitSet endBitSet; // 比特集合终止状态,用来控制循环
private static Set<Set<String>> properSubset; // 真子集集合
public static Set<Set<String>> getProperSubset(int n, Set<String> itemSet) {
String[] array = new String[itemSet.size()];
ProperSubsetCombination.array = itemSet.toArray(array);
properSubset = new HashSet<Set<String>>();
startBitSet = new BitSet();
endBitSet = new BitSet();
// 初始化startBitSet,左侧占满1
for (int i=0; i<n; i++) {
startBitSet.set(i, true);}
// 初始化endBit,右侧占满1
for (int i=array.length-1; i>=array.length-n; i--) {
endBitSet.set(i, true);
}
// 根据起始startBitSet,将一个组合加入到真子集集合中
get(startBitSet);
while(!startBitSet.equals(endBitSet)) {
int zeroCount = 0; // 统计遇到10后,左边0的个数
int oneCount = 0; // 统计遇到10后,左边1的个数
int pos = 0; // 记录当前遇到10的索引位置
// 遍历startBitSet来确定10出现的位置
for (int i=0; i<array.length; i++) {
if (!startBitSet.get(i)) {
zeroCount++;
}
if (startBitSet.get(i) && !startBitSet.get(i+1)) {
pos = i;
oneCount = i - zeroCount;
// 将10变为01
startBitSet.set(i, false);
startBitSet.set(i+1, true);
break;
}
}
// 将遇到10后,左侧的1全部移动到最左侧
int counter = Math.min(zeroCount, oneCount);
int startIndex = 0;
int endIndex = 0;
if(pos>1 && counter>0) {
pos--;
endIndex = pos;
for (int i=0; i<counter; i++) {
startBitSet.set(startIndex, true);
startBitSet.set(endIndex, false);
startIndex = i+1;
pos--;
if(pos>0) {
endIndex = pos;
}
}
}
get(startBitSet);
}
return properSubset;}
private static void get(BitSet bitSet) {
Set<String> set = new HashSet<String>();
for(int i=0; i<array.length; i++) {
if(bitSet.get(i)) {
set.add(array[i]);
}
}
properSubset.add(set);
}
}
对上述Apriori算法的实现进行了简单的测试,测试用例如下所示:
public class TestAprioriAlgorithm {
public static void main(String[] args) {
// 构造模拟事务数据库txDatabase
Map<Integer, Set<String>> txDatabase;
txDatabase = new HashMap<Integer, Set<String>>();
set1.add("a");
set1.add("c");
set1.add("d");
txDatabase.put(1, set1);
Set<String> set2 = new TreeSet<String>();
set2.add("b");
set2.add("c");
set2.add("e");
txDatabase.put(2, set2);
Set<String> set3 = new TreeSet<String>();
set3.add("a");
set3.add("b");
set3.add("c");
set3.add("e");
txDatabase.put(3, set3);
Set<String> set4 = new TreeSet<String>();
set4.add("b");
set4.add("e");
txDatabase.put(4, set4);
Float minSup = new Float("0.50");//最小支持度为0.5
Float minConf = new Float("0.70");//最小置信度为0.7
AprioriAlgorithm apriori = new AprioriAlgorithm(txDatabase, minSup, minConf);
System.out.println("挖掘频繁1-项集 : " + apriori.getFreq1ItemSet());
System.out.println("候选频繁2-项集 :"+ apriori.aprioriGen(1, apriori.getFreq1ItemSet().keySet()));
System.out.println("挖掘频繁2-项集 :"+ apriori.getFreqKItemSet(2, apriori.getFreq1ItemSet().keySet()));
System.out.println("挖掘频繁3-项集 :"+ apriori.getFreqKItemSet(3, apriori.getFreqKItemSet(2, apriori.getFreq1ItemSet().keySet()).keySet()));
apriori.mineFreqItemSet(); // 挖掘频繁项集
System.out.println("挖掘频繁项集 :" + apriori.getFreqItemSet());
apriori.mineFreqItemSet(); // 挖掘频繁项集
apriori.mineAssociationRules();
System.out.println("挖掘频繁关联规则 :" + apriori.getAssiciationRules());
}
}
运行结果:
挖掘频繁1-项集 : {[a]=0.5, [c]=0.75, [b]=0.75, [e]=0.75}
候选频繁2-项集 :[[a,e], [a,b], [c,e], [c,b], [a, c], [b, e]]
挖掘频繁2-项集 :{[c,e]=0.5, [c, b]=0.5, [a, c]=0.5, [b, e]=0.75}
挖掘频繁3-项集 :{[c, b,e]=0.5}
挖掘频繁项集 :{1=[[a], [c], [b], [e]], 2=[[c,e], [c, b], [a,c], [b, e]], 3=[[c, b, e]]}
挖掘频繁关联规则 :{[c,e]=[[b]], [a]=[[c]], [c, b]=[[e]], [b]=[[e]], [e]=[[b]]}
结果解释:
在最小支持度为0.5,最小置信度为0.7的情况下,挖掘出了5个频繁关联规则:[c,e]=[b], [a]=[c], [c, b]=[e], [b]=[e], [e]=[b] 其中confidence([c, e]=[b])=0.5/0.5=1,
confidence([a]=[c])=0.5/0.5=1, confidence([c, b]=[e])=0.5/0.5=1, confidence([b]=[e])=0.75/0.75=1, confidence([e]=[b])=0.75/0.75=1,这五个关联规则的置信度都大于最小置信度0.7。
实验小结: