词法分析程序实验报告
班级:2013211306 学号:2013211321 姓名:严浩
一)实验目的:
(1)掌握词法分析程序的实现方法和技术:利用c语言描述了一个词法分析器,
旨在对于词法分析的过程站在计算机的角度进行了解与体会。
(2)加深对有限自动机模型的理解:语法分析的过程就是一个对所碰到的单词
符号进行自动机模拟的过程,碰到一个自己需要的字符就进行状态转换,并最终
到达终止状态,即完成了一个运用源语言进行分析的过程。
(3)理解词法分析在编译程序中的作用:其主要任务是从左到右逐个字符的对
源程序进行扫描,按照源语言的语法规则识别出一个个的单词符号,把识别出来
的单词符号存入符号表中,并产生用于词法分析的记号序列。
(4)用c语言对一个简单语言的子集编制一个一遍扫描的编译程序,以加深对
编译原理的理解,掌握编译程序的实现方法和技术。
二)实验环境
Windows8.1 Cfree
三)实验总结:
1.一开始想用数组来存储每一行的字符串,后来发现极其不方便,尤其是当你要连接两段字符串的时候,所以后来改成了用链表来存储每一行的字符串,但每个单词还是用字符数组来存。
2.忘记了在扫描完一个单词后,指针要回退,否则会漏读字符,所以后来有加上了retract()函数。
3.一开始把运算符也当做单词,后来发现后,用总单词数减去运算符以及标点数才得到正确的单词数。
4.书上的伪代码不完整,只对一部分运算符进行了处理,像‘&’‘|’‘“’等都没有处理,还需要自己补充。
四)源代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
#define len sizeof(struct Node)
struct Node{
char data;
struct Node *nextp;
};
struct Node *head,*p; //头指针和操作用的指针
char C;//全局变量,用于存储当前得到的字符
int notkey = 0;//统计非关键字字符个数
char token[255];//字符数组,存放读取的字符串
int num = 0;//非字符串单词数
char * key[] =
{"auto","double","int","struct","break","else","long",
"switch","case","enum","register","typedef","char",
"extern","return","union","const","float","short","unsigned",
"continue","for","signed","void","default","goto",
"sizeof","volatile","do","if","while","static" };//关键字查询表
void get_char(){//读取字符
C = p -> data;
p = p -> nextp;
}
void get_nbc(){//.一直扫描,直到非空
while(C == ' '){
get_char();
}
}
void concat(){// 将字符连接
size_t i;
i = strlen(token);
token[i] = C;
token[i + 1] = '\0';
}
int letter(char ch){//判断是否为字符
return isalpha((int) ch);
}
int digit(char ch){//判断是否为数字
return isdigit((int) ch);
}
void retract(){//指针回退
struct Node *l;
l = head -> nextp;
while(l -> nextp != p){
l = l -> nextp;
}
p = l;
}
int reserve(){//判定是否为关键字
int keyjudge = 0;
for(keyjudge = 0; keyjudge <= 31 ; keyjudge ++){
if(strcmp( key[keyjudge] , token) == 0){
return keyjudge;
}
}
return 255;
}
//扫描缓冲区函数定义
void scaner(){
int c;
int j = 0;
for( j = 0 ; j < 30 ; j ++){
token[j] = '\0';
}
get_char();
get_nbc();
if(letter(C))//处理字符
{
while((letter(C)) || (digit(C)))//以字母开头的字母数字串
{
concat(); //字符放入token数组中
get_char(); //指针再往后读一个字符
}
retract(); //当出现除字母,数字外的字符时,指针回退
c = reserve(); //字母数字串与保留字匹配
if(c != 255)
printf("(%s,-)\n",key[c]); //输出保留字记号
else
{
printf("(%s,%d)\n",token, notkey);
}
}
else if(digit(C))
{
while(digit(C))
{
concat();
get_char();
}
retract();
printf("(num,%d)\n",atoi(token));
}
else{
num ++;
switch(C){
case'+':
get_char();
if(C == '+')
printf("(++,-)\n");
else if(C == '=')
printf("(+=,-)\n");
else
{
retract();
printf("(+,-)\n");
}
break;
case'-':
get_char();
if(C == '-')
printf("(--,-)\n");
else if(C == '=')
printf("(-=,-)\n");
else if(C == '>')
printf("(->,-)\n");
else
{
retract();
printf("(-,-)\n");
}
break;
case'*':
if(C == '=')
printf("(*=,-)\n");
else
{
retract();
printf("(*,-)\n");
}
break;
case'/':
get_char();
if(C == '/')
{
get_char();
printf("注释为:");
while(C != '\n')
{
printf("%c",C);
get_char();
}
printf("\n");
}
else if(C == '*')
{
get_char();
printf("注释为:");
while(C != '*')
{
printf("%c",C);
get_char();
}
printf("\n");
get_char();
}
else if(C == '=')
{
printf("(/=,-)\n");
break;
}
else
{
retract();
printf("(/,-)\n");
}
break;
case'%':
get_char();
if(C == '=')
printf("%s\n","(%=,-)");
else
{
retract();
printf("%s\n","(%,-)");
}
break;
case'<':
get_char();
if(C == '=')
printf("(relop,LE)\n");
else
{
retract();
printf("(relop,LT)\n");
}
break;
case'>':
get_char();
if(C == '=')
printf("(relop,GE)\n");
else
{
retract();
printf("(relop,GT)\n");
}
break;
case'=':
get_char();
if(C == '=')
printf("(relop,EQ)\n");
else
{
retract();
printf("(assign-op,-)\n");
}
break;
case'!':
get_char();
if(C == '=')
printf("(relop,NE)\n");
else
{
retract();
printf("(logic,NOT)\n");
}
break;
case'&':
get_char();
if(C == '&')
printf("(logic,AND)\n");
else
{
retract();
printf("(&,-)\n");
}
break;
case'|':
get_char();
if(C == '|')
printf("(logic,OR)\n");
else
{
retract();
printf("(|,-)\n");
}
break;
case'\n': printf("(enter-op,-)\n");break;
case';': printf("(;,-)\n");break;
case':': printf("(:,-)\n");break;
case'{': printf("({,-)\n");break;
case'}': printf("(},-)\n");break;
case'(': printf("((,-)\n");break;
case')': printf("(),-)\n");break;
case'[': printf("([,-)\n");break;
case']': printf("(],-)\n");break;
case'.': printf("(.,-)\n");break;
case',': printf("(,,-)\n");break;
case'?': printf("(?,-)\n");break;
default: printf("error"); break;
}
}
}
//主函数
int main() {
int rownum = 0;
int bytenum = 0;
int word = 0;
head = (struct Node*)malloc(len);//头结点空间
head -> data = ' ';
head -> nextp = NULL;
p = head;
printf("请在待分析的代码的下一行加上$:\n");
while(1){//以行为单位,读入代码,进行处
int i = 0;
char temp[260];// 假定每行字符数不超260
gets(temp);
if(temp[0] == '$')//如果读到第一字符为$,则做终止处理
break;
rownum ++;
p -> nextp = (struct Node*)malloc(len);
p = p -> nextp;
while( temp[i] != '\0' && i < 260 ){
p -> data = temp[i];
p -> nextp = (struct Node*)malloc(len);
if(!(p -> nextp)){
printf("Error,don't have enough memory.\n");
exit(1);
}
p = p -> nextp;
i ++;
bytenum ++;
}
p -> data = '\n';
p -> nextp = NULL;
}//扫描缓冲区,计算字符数和行数
p=head->nextp;//指向本行C语言代码第一个字符
while(p->nextp!=NULL) //循环直到本行打印结束,并计算单词数
{
printf("%c",p->data);
p=p->nextp; //从头至尾遍历链表
}
printf("\n"); //显示最后一个回车
p = head -> nextp;
while( p -> nextp != NULL){
scaner();//进行词法分析
word++;
if( reserve() == 255)
notkey ++;
}
printf("This program has:%d lines. \n",rownum);
printf("Besides note,there are %d words.\n",word - num);
printf("There are %d bytes.\n",bytenum + rownum);//输出提示信息
system("Pause");
return 0;
}
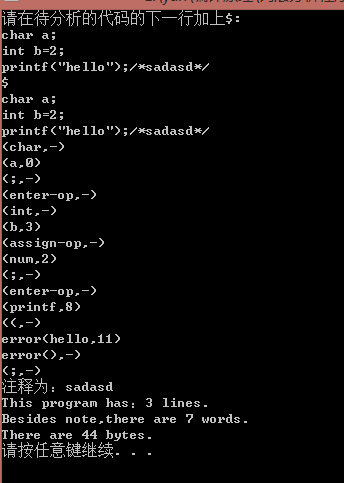
五)实验结果: