华东理工大学2014—2015学年第 2 学期
《 社会统计学 》期终考试 课程论文 2015.6
班级__ __ 学号__ ___ 姓名___ __
开课学院 社会学院 任课教师 成绩__________

1
基于主成分回归分析的西安房地产价格走势
摘要:研究以西安市为例,选取影响房地产价格的人均GDP X1、总人口X2、城镇居民人均可支配收入X3、土地购置费X4、房屋造价X5等11 个可以量化的因素,采用SPSS 软件进行主成分分析,将11 个因素转化为3个主成分,然后建立模型,采用回归分析方法对3 个主成分与各个年份房地产价格的关系进行分析,并对2012--2015 年房地产均价进行预测。从预测结果来看,预测结果实际值与预测值的差异较小、精度较高,预测值可以在一定程度上反映西安市房地产市场状况,预测模型及预测结果能够为房地产企业以及政府、购房者的决策提供参考。
关键词:房地产价格 主成分分析 线性回归 西安市
一、研究背景及意义
住房是关系到国计民生的重大问题,目前房价问题已经成为一个引起广泛关注的重要经济问题和社会问题。陕西省20xx年政府工作报告中明确提出:“支持房地产市场健康平稳发展,多渠道增加住房有效供给,满足自住性、改善性的商品房需求”; “强化各级政府的责任,充分发挥省保障性住房建设公司的作用,继续抓好保障性安居工程建设,加快城乡建设进度,确保工程质量”。陕西省围绕制定一系列的房地产政策其目的也在与保持房价平稳,维护房地产市场的健康发展。在这一大背景下有必要对房地产市场的总体趋势做出判断,对房价问题进行深入分析。为此,笔者以陕西省西安市为研究区域,采用主成分分析法和回归分析法对西安市房地产价格各个影响因素进行了分析并对未来价格走势进行预测。
二、实证分析
2.1 变量的选取与说明
经过参考、借鉴相关研究文献资料,研究选取商品房平均销售价格Y ( 元/㎡) 为因变量,选取人均GDP X1( 元) 、总人口X2( 万人) 、城镇居民人均可支配收入X3( 元) 、土地购置费X4( 万元) 、房屋造价X5(元/平方米) 、城乡居民人民币储蓄存款余额X6( 万元) 、房地产开发投资额占固定资产投资额的比重X7( %) 、房屋竣工面积占施工面积的比重X8( %) 、房屋销售面积X9( 万平方 - 2 -
米) 、城市居民家庭人均消费支出X10( 万平方米) 、个人住房公积金贷款利率X11( %) 等影响房地产价格的11 个指标作为子变量。以西安市为例,所搜集的数据如表1所示(数据主要源于互联网,陕西省年鉴等)。
表1
Y:商品房X1:人X2:总人X3:城镇居民X4:土地X5:房屋X6:城乡居民年份 均价(元均GDP口(万人均可支配收购置费造价(元储蓄余额(万
/m2) (元) 人) 入(元) (万元) /m2) 元) 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011
2095 2042 2148 2624 2851 3317 3379 3906 3890 4453 4988
10628 694.80 11831 702.60 13341 706.60 15294 725.00 16406 806.81 18890 822.52 22463 830.54 27794 837.52 32411 843.46 38355 846.78 45676 851.34
6704.90 7183.50 7748.40 8544.00 9627.90 10905.40 12662.00 15207.00 18963.00 22244.00 26962.00
121220 84198 192245 156426 302200 204900 381412 669495 543862 873909 1423668
1176.00 1120.23 1612.02 2051.81 2278.55 2052.41 2092.46 2398.84 3096.47 3141.00 3627.37
8008600 9880400 12105600 14328600 17167600 19505300 20023800 25137000 30842000 36410900 41911400
X7:房地产开发投X8:房屋竣工X9:房屋销
民家庭人均
年份 资额占固定资产投面积占施工面售面积( 万
消费支出
资额的比重(%) 积的比重(%) 平方米)
(元) 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011
2.2 房地产价格影响因素的主成分分析
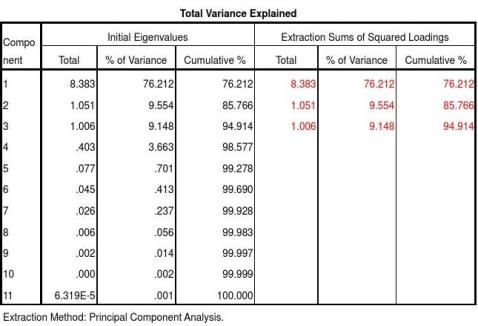
2.2.1 主成分个数与主成分载荷计算 由表2 可以看出,特征值λ
34.72 23.43 23.35 26.11 25.27 25.42 27.30 26.99 28.63 27.85 20.62 29.91
42.07 42.51 28.12 25.29 23.31 16.63 16.76 16.57 14.17 9.51 6.92 7.72
212.90 225.30 252.90 252.70 305.50 497.30 621.50 833.90 760.70 1256.02 1587.81 1796.03
5446 5816 6419 6805 7428 7900 8987 10098 12016 14251 16543 18503
X11:个人住房公积金贷款利率(%)
4.59 4.59 4.59 4.05 4.23 4.41 4.59 5.01 4.51 3.87 4.90 4.90
1 = 8.383,λ2 = 1.051,λ3 = 1.006 ( 其他的特征
- 3 -
值小于1,未列出),前3 主成分的累积贡献率为94.914% > 85% ( 表2) ,为此确定主成分的个数为3,对应的主成分载荷见表3。
由因子得分系数绝对值大于0.5 的原则,第一主成分主要由X1、X2、X3、X4、X5、X6、X8、X9、X10支配,反映了人口状况、收入与储蓄水平、房屋成本及房屋销售情况; 第二主成分主要由X7 支配,反映了房屋开发投资情况; 第三主成分主要由X11支配,反映了金融政策。
- 4 -

2.2.2 主成分特征向量及得分计算
用主成分载荷除以特征值的平方根就得到各个主成分的特征向量(表4) 。
表4
特征向量
X1
X2
X3
X4
X5
X6
X7
X8
X9
X10
X11
X12
μ1 0.34 0.31 0.34 0.33 0.33 0.34 -0.02 -0.31 0.34 0.34 0.10 0.34
μ2 0.05 -0.04 0.07 0.16 -0.14 -0.01 0.84 0.26 0.05 0.03 0.40 0.05 μ3 -0.01 -0.04 -0.01 0.06 -0.16 -0.04 -0.49 0.13 0.05 -0.01 0.84 -0.01
并利用主成分的特征向量,写出主成分公式Z1、Z2、Z3:
利用上述3个公式,得到主成分的得分如表5所示。
表5
2001 2002 2003 2004 2005 2006 2007 2008 2009
-3.128 -2.596 -2.235 -1.657 -0.537 -0.224 0.525 1.352 2.455
-0.267 -0.598 -0.682 -0.782 -0.679 0.004 0.542 0.388 -0.704
1.054 0.903 -0.919 -0.487 -0.206 -0.002 1.093 -0.445 -2.11

- 5 -
2011
5.528 1.416 0.127
2.3 房地产价格的回归分析 2.3.1 多元回归分析
在上文主成分分析的基础上,将所提的主成分Z1、Z2、Z3作为自变量,把1900-2010 年房地产销售均价作为因变量Y,采用SPSS 进行多元线性回模拟,通过拟合发现,初次得到房地产年销售均价的线性回归结果如表6,图1、图2所示。
表6

- 6 -
图
1
图2
2.3.2 剔除变量后的回归分析
通过拟合发现,模型拟合度R2 = 0.970,拟合程度较好。通过计算,F 检验中Sig.= 0.000 < 0.05 ( 置信区间) ,这说明拟合的回归方程通过了方差 - 7 -
检验,方程总体显著。在T 检验中Z2的Sig. = 0.543 > 0.05 ( 置信区间) ,Z3的Sig. = 0.759 > 0.05 ( 置信区间) ,这说明Z2、Z3参数的可信度较差,拟合的回归方程未通过T 检验,可以将Z2、Z3剔除,然后在进行一次回归模型的拟合。在剔除Z2、Z3后采用同样的方法对Y 和Z1 进行拟合,得到房地产价格的回归结果,如表7、图3所示。
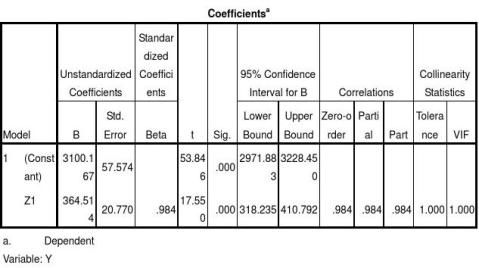
图3
- 8 -
2.3.3 剔除变量后的房地产价格回归与拟合
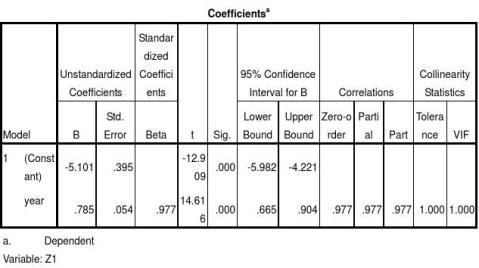
由于在建立房地产价格和Z1、Z2、Z3( Z2、Z3已剔除,故不做分析) 回归方程时涉及到时间变量( t) ,在进行房地产价格回归模型建立后要进行预测必须建立Z1与时间( t) 的预测方程及得到预测值。为此,取2000 年= 1,2001 年= 2,?,2011 年= 12,?,2015 年= 16,得到时间( t) 的数据,依据表5 中Z1数据,采用SPSS 软件进行回归拟合。结果表明,模型拟合度R2 = 0. 955,F 检验中Sig. = 0.000 < 0. 05 ( 置信区间) ,这表明拟合的回归方程通过方差检验,方程总体显著,在T 检验中Sig. = 0.000 < 0. 05 ( 置信区间) ,这说明该参数的可信度较高,拟合的回归方程通过,具体结果如表8所示。
表8
2.4房地产价格的预测结果
根据上述分析,由Z1(受到t的影响)对房地产价格的预测结果如表9、图4所示。
表9
年份 2000 2001 2002 2003 2004 2005 2006 2007 2008
year 1 2 3 4 5 6 7 8 9
Z1 -4.316 -3.531 -2.746 -1.961 -1.176 -0.391 0.394 1.179 1.964
房产预测价格 1522.606576 1809.535066 2096.463556 2383.392046 2670.320536 2957.249026 3244.177516 3531.106006 3818.034496
房产实际价格
1509 2095 2042 2148 2624 2851 3317 3379 3906
- 9 -
2009
2010
2011
2012
2013
2014
2015
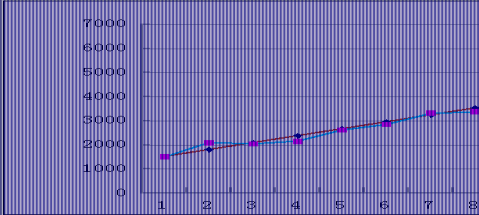
10 11 12 13 14 15 16 2.749 3.534 4.319 5.104 5.889 6.674 7.459 4104.962986 4391.891476 4678.819966 4965.748456 5252.676946 5539.605436 5826.533926 3890 4453 4988 5012 5314 5548 5846
图4
三、结论分析
研究通过主成分分析得到3 个主成分,然后进行回归预测,建立二元回归方程,但由于第二、第三个主成分未通过T 检验,被剔除,重新进行回归拟合,结果显示,重新拟合后,拟合度较好,F 检验、T 检验均通过,回归方程可以用于预测未来房价。通过房价预测结果与房价实际值对比发现,误差较小,这再次说明回归方程成立,同时也可以说明预测模型及结果可为相关研究及政策制定提供参考。由预测结果可以看出,未来几年房地产价格还会上涨。随着关中—天水规划区的进一步实施、沣渭新区的建设、西安国际化大都市战略的逐渐推进以及未来一段时间西安城市化进程的加快,会推动房价的上升,这进一步验了研究的实证结果。
当然,本文的研究也存在一定的局限性: 一是考虑到数据的易得性,指标选取只是选取影响房地产价格的各个可以量化的因素,以便进行预测分析,这些可以量化的数据也是选取对房价有重要影响的指标,对宏观经济运行情况、国内房 - 10 -
地产调控政策、国际经济发展状况等不易量化的因素没有考虑在内,这就使得计算结果存在一定的偏差。二是选取各个指标数据来源于统计局以及各个统计网站,各个部门存在统计口径不一致以及统计数据本来就与实际值存在误差的情况,房地产数据是整个西安市的平均价格,从而从致使结果与市场实际值存在一定的偏差。因此,对于西安市房地产格的定量分析预测存在一定局限性,本文模型所选取的因素具有代表性,虽然不能全面反映房地产市场的所有影响因素,对于房地产的预测研究具有一定的现实意义。针对这些存在的问题,笔者将在今后的研究中继续探索和完善。
- 11 -
第二篇:地统计学论文
在逻辑回归和克里金该方法的基础上研究土壤污染和人类活动的相关性
关键词:回归克里金 逻辑回归 指示克里金 重金属 土壤污染
摘要:在台湾的中心地区,量化土壤的污染和长期土地利用的相关性是一个管理土壤资源的非常有效地方式。定义有害的地区为重金属含量超过相应的可控标准的地区,此项研究不仅估算了有害地区概率分布的空间格局,有害地区的概率是使用指示克里金方法而且只基于那些可观测的重金属数据得出,还通过逻辑回归和回归克里金法考虑辅助变量来估算可能有害地区的空间格局。估算结果显示通过指示克里金法和回归克里金法估算的有害空间格局比用指示克里金法估算的还要零碎。此外,指示克里金和回归克里金能够确定污染源和污染途径的关系。在结果的基础上,受害地区和工长的位置以及研究区灌溉系统的位置有着极为密切的关系。这些方式为未来检测土壤污染提供了一个探索危害性的有效方式。逻辑克里金和回归克里金不仅能识别土壤污染的自然和人为的因素,而且提高了辨别受害区域土壤污染的超微性。特别是,回归克里金法考虑到用空间残差来改善逻辑克里金中的优势。
1. 介绍
金属离子位于饮食来源必须提供的关键营养当中。一些重金属元素是人类每分每秒必不可少的,然而那些超过限制的不是致癌的就是有毒的。此外,由于重金属在人体内不能被降解或是摧毁,所以他们具有持久性。重金属污染和人类活动有密切的关系。化学和冶金行业是重金属在自然中最重要的来源。还有,由于人类的活动土壤的重金属污染已占主导趋势。重金属集中的热点地区是离台湾中部近的工厂和灌溉系统。工厂被怀疑往台湾中部的灌溉渠道排放废水,当地的站点可能被这种途径污染。由于人类的行为活动,不合理的废水处置,农业土壤的重金属污染在全世界范围内快速增长。
在逻辑回归的基础上,许多研究已经分析出推动力因素和土壤污染是怎样相互关系着来决定土壤污染发生的可能性。逻辑回归分析检查出污染集中区的概率超出了一系列资源的极限值。使用逻辑回归,tesoriero 和voss估计普吉声音盆地硝酸盐污染的含水层脆弱性。使用同样的方式,twarakavi 和 kaldarachchi sumas-blaine 预测含水层重金属污染物的敏感性。也是使用逻辑回归,lee 量化出砷浓度和水化学参数的污染敏感性是怎样相关联的。他们的研究在基于推动力的点上确定出决定污染公害的概率。为了增加逻辑回归模型的准确率,这个研究通过套用回归克里金法建模而得出重金属的危害概率。回归克里金法包含着对辅助变量的因变量的回归分析和回归残差的简单克里金。大多数研究证实回归克里金对于实际应用中的空间估计是一种灵活但又稳健的方式。基于回归克里金法,趋势估计与残余插值是分离的,趋势估计涉及到任意复杂形式的回归。通过使用回归克里金,基于已建立的过程模型staceyetal改善了土壤中氧化亚氮的预测能力。Hengletal讨论回归克里金的特征,优点和极限,用一个简单的例子和三个案例研究举例说明了这些特征。众所周知,回归克里金是一种混合残差的方式。回归克里金起初在辅助信息上使用回归分析,后来使用简单的克里金并用一个非常出名的方式向回归分析模型中插入残差。
此外,土壤污染监测在弄明白环境的危险性方面,是一个必须的和过高花费的过程。不用测量整个区域内的土壤数据,克里金模型就能被用来估计土壤污染的空间格局。指示克里金法除了划定有危害的区域,还能确定区域内重金属污染的概率分布。指示克里金法提供了一个非参数分布,估计非抽样位置直接使用固定扩值和澄清公害危险的空间格局。通过使用指示克里金,goovaert 估计并绘制出镉和铜污染的危害程度,引入了瑞士岸区域的表土层。基于指示克里金法,van meihe goovaert评估出重金属集中区污染元素的概率,那些元素超过了比利时空气传播的镉污染区域的环境极限值。以上这个模型通过观察土壤集中区和测量研究区域的数据,而适用于评估重金属污染区域的有害危险程度。
进一步,此项研究的目的是:1.辨别土壤污染中包括人类行为多变性的因素2.提高估计的准确性3.评估有土壤重金属污染的空间有害地图4.强调土壤中带有金属的热点地区的分布率。
2.方法和材料
研究评估台湾中部地区工厂附近的一个农业区的空间地图,特别强调土壤中金属元素的分布和关系。在逻辑回归和克里金的基础上,重金属的空间分布格局被予以分析。讨论台湾长华村人类行为和重金属的抽样调查。
2.1研究区域
区域是台湾一个非常重要的农业区的长华村。东边是长华市,西边是鹿港镇。此区域的农业用地是461ha,占整个区域的百分之六十二。在1970年以后,政府鼓励轻工业。将近106家工厂聚集在这个研究区。在这个研究区的工厂包括金属业,电镀业,纺织业以及金属表面处理业,些工厂被怀疑往研究区的灌溉渠道排放污水。
2.2抽样调查和化学分析
20##年的2月到8月之间,台湾的环境保护管理会在这个研究区开展了一个土壤重金属调查项目,调查了1309个表土层的例子(包括铬,铜,镍,锌,铅,砷,镉和汞的集中区),并得出了数据。由于研究区农地的不规则性,抽样战略地点是不一致的。研究区不是一个规则的区域,它是由于灌溉系统的地形决定的。这些抽样的地方在图一(b)里显示。使用不锈钢铲子和再生障碍性勺子从每一个样区采集接近1公斤的土壤,然后储藏在塑料食物袋。在室温下将空气晾干后,每一份样土有3克被分解,筛到0.85毫米,地面的0.15毫米是细粉。每3克研磨样品在室温条件下加入7毫升硝酸和21毫升盐酸吸收2小时,慢慢地氧化土壤中的有机物。接下来,这个100毫升的王水将被过滤。最后,电感偶合Plasma-Optical发射光谱仪确定样品集中区的重金属水平。
图一(b)
2.3逻辑回归法
逻辑回归提供了基于推动力基础上每一个位置每一种污染危害出现的概率。逻辑回归法定量危害发生和推动力之间的关系,规定如下:
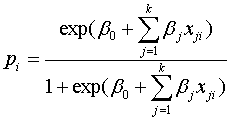 (1)
(1)
and
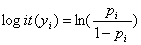 (2)
(2)
 表示在网格单元
表示在网格单元 中超过可控标准集中区重金属元素的概率,
中超过可控标准集中区重金属元素的概率, 是推动力因素的个数,y
是推动力因素的个数,y 表示在网格单元中相互依存的指标变量,x
表示在网格单元中相互依存的指标变量,x 表示在
表示在 因素下的每一个因素的值,
因素下的每一个因素的值, 是估计系数,
是估计系数, 是逻辑模型中每一个推动力因素的系数。研究中的逻辑回归由SPSS统计软件执行,重要变量由卡方检验确定。
是逻辑模型中每一个推动力因素的系数。研究中的逻辑回归由SPSS统计软件执行,重要变量由卡方检验确定。
2.4回归克里金法
随机功能被模拟为是趋势和随机变量的结合物。回归克里金用两种方法去连接这些:回归法用于适应解释型变量,用期望值为零的简单克里金法去适应残差。
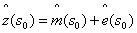
=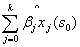 +
+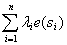 (3)
(3)
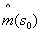 是拟合的趋势,
是拟合的趋势, 是剩余插值,
是剩余插值, 是推动力因素,
是推动力因素, 是估计的趋势模型系数,
是估计的趋势模型系数, 是残差的空间独立结构决定的克里金重量并且e(s)是在s处的残差值。回归系数用合适的方式从样本中估计。
是残差的空间独立结构决定的克里金重量并且e(s)是在s处的残差值。回归系数用合适的方式从样本中估计。
此外,回归克里金在数学上是与普遍克里金以及外部漂移克里金是一样的。回归克里金能够将辅助变量整合而构成关心属性的普遍趋势。克里金方式然后适用于模拟残差的空间分布。回归克里金中有害污染概率的估计由研究中逻辑回归提供。
2.5指示克里金
指示克里金估计的是一个给定的位置点超过特别极限值的污染物集中区的概率,数据z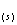 被定义为以下指标:
被定义为以下指标:
I(s,z)={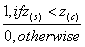 (4) 有问题
(4) 有问题
如果重金属的集中程度z超过了z 则指示值是0,否则为1.
则指示值是0,否则为1.
在n确定的条件下,I(s;z|(n))的估计值,如以下所示:
E[I(s;z|(n))]=Prob[z≤z|(n) ] (5)
超过z的概率如以下所示,
Prob[z>z|(n) ] =1- Prob[z≤z|(n) ] (6)
普遍克里金的概率分布为:
Prob[z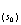 ≤z|(n) ]=
≤z|(n) ]=
 (7)
(7)
在(7)式中,I(s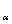 ;z
;z )代表在
)代表在 确定的情况下的指数值,
确定的情况下的指数值, =1,…,n;
=1,…,n; 是I(s;z)的权重,I(s;z)是由以下克里金体系确定的:
是I(s;z)的权重,I(s;z)是由以下克里金体系确定的:
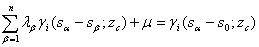 (8)
(8)
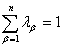 (9)
(9)
在(9)式中, 是拉格朗日乘数,
是拉格朗日乘数, 是在样本
是在样本 和
和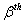 之间变化的指标值,
之间变化的指标值, 是在样本和s
是在样本和s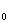 之间变化的指标值,=1,…,n;研究中的克里金和指标
之间变化的指标值,=1,…,n;研究中的克里金和指标
克里金是由GSLIB(地统计数据库)执行的。
3.结果和讨论
3.1基本的统计数据
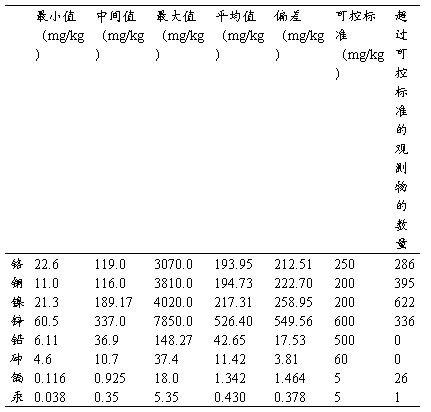
表1总结了八种被调查的重金属的统计数据。在台湾,污染控制标准如以下所示,该标准是由台湾环境保护组织通过对监管区土壤重金属调查所得:铬:250mg/kg,铜:200 mg/kg,镍:200 mg/kg,锌:600 mg/kg,铅:500 mg/kg,砷:60 mg/kg,镉:5 mg/kg,汞:5 mg/kg。表一列举了超过可控标准的例子,铬的286个,铜的395个,镍的622个,锌的336个。一些例子对于镉(26例)和汞(1例)是可利用的。在研究区没有砷和铅污染的出现。基于基本的统计分析,四种重金属元素(铬,铜,镍,锌)被选定来评估空间污染危害地图。
表一:原例中得重金属的描述性统计
3.2逻辑回归法估计的空间概率
基于逻辑回归模型,超过可控标准的重金属集中区的概率通过预测危害与污染源的关系被评估出来。表二列举了四种重金属元素的逻辑回归模型的系数。在回归结果的基础上,金属业的距离与确定此地铬污染的可疑性成正比例关系。同时,距渠道的距离,汽车修理厂的距离以及造纸业的距离与概率成反比例关系。水业的距离,所有工厂的距离以及化学业的距离有助于评估铜危害的危险性。然而,农业土地,距渠道的距离,距灌溉渠道的距离,距主要灌溉渠道的距离,表面处理业,纺织业电镀业以及其他行业的距离与铜危害性污染成负相关关系。为了估计镍污染发生的概率,合适的逻辑模型使用了三个正相关的系数因素(与金属业,纺织业的距离)和负相关因素(农用地,与渠道灌溉,渠道,皮革,橡胶业的距离)。为了估计锌危害发生的概率四个正相关因素(人口,与水产业化学工业金属业)和七个负相关因素(建设用地,农用地与渠道,主要灌溉渠道,排水渠道,造纸业,电镀业的距离)被用来适用逻辑模型。还有,人口密度,离主干道的距离,土壤水力传导系数和土壤流失因素不具有统计学意义,没有改善模型的利用。结果反映出在研究区人口密度以及土壤性质和土壤污染物没有直接的关系。
表二
图2在逻辑回归的基础上,显示出超过可控标准的土壤集中区的概率图,其中包括铬,铜,镍和锌。研究区重金属的可疑性显示出人类活动在这个地区占主导地位,人类活动导致了高的重金属积聚。结果也显示出逻辑回归是另一种实用的估计土壤污染发生率的方式,即使在没有直接测量各处污染物的每一个例子中都能实现。总的说来,地图指示出工厂和灌溉系统和高的可变性密切相关。和先前有关的估计结果指示出重金属的实用以及人类资源的分布与工厂和灌溉渠道有密切的关系。此外,来源于人类不同的活动的污染物影响着土壤。由于工业活动,重金属的农业土壤污染已经变得更严重而遍布整个研究区。重金属污染与像电镀业,金属业,金属表面处理,纺织业这样的工厂有关系。研究区,土壤集中区与化学原料使用的强度以及工业化的程度相关。由于研究区金属土壤集中区的分布,工业活动和农业活动是重金属污染的主要原因。土壤,特别是那些用污染的水灌溉的地区,含有非常高的重金属数量。
图二
3.3通过克里金方法得出的空间分布率
地统计学能通过变差函数描述环境数据的空间格局,预测非抽样地区有关属性的值。超过可控标准的任何一个非抽样点的重金属污染的概率由克里金模型所确定。有害物质概率的空间分布能够通过指示变差函数来确定。变差是变差函数模型的一种功能。表三列出了四种重金属元素的指示变差函数的参数。铬和铜是指数模型镍和锌是球状模型。模型中所有的R的平方都超过了0.92。在抽样点之中变差函数定量了有害物质地图的空间多变性。变差的结果指示出铬和铜的范围是57米和66米。然而镍和锌的范围是255米和252米。这个发现揭示出一种空间相关性,镍和锌的距离比铬和铜的距离远。以上结果也揭示出锌的变差模型有较高的块金值,显示出小规模的多变性。
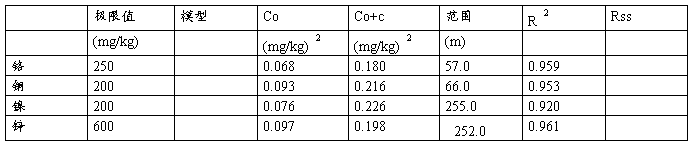
Rss代表面积减少的总量
图3显示了铬,铜,镍,锌的土壤污染的概率图,这四种元素都超过了逻辑克里金的可控标准。估计结果指示出镍污染的有害性超过了其他元素。图4显示了回归克里金下超过可控标准的重金属概率图,并且提高了逻辑回归的结果。然而,逻辑回归的空间的概率分布图缺少空间相关性。在观测的多个方面上,回归克里金和逻辑克里金的图表显示了多变性的相似形式和重金属的集中分布,但是锌不包括在内。采用克里金方法的图包括了观测点的特征,显示了研究区有害土壤的碎片形式。还有,回归克里金的结果显示通过增加克里金估计到回归预测值里去,是降低回归克里金预测方差的有效方式。当介绍空间趋势的确定性进程极大地影响土壤污染的可变性时,一个纯粹随机的地理统计学的假设是不能令人满足的。
在研究过程中,土壤污染物的的分布趋势的确定是通过把污染来源的信息纳入模型当中。明显的,人类可能影响着重金属的空间分布图。在大多数地点带有重金属特征的有害物通常污染来源加倍。此外,土壤污染物的结果可疑性地图提供了一种可替代方式,这种方式可以探索空间资源和未来环境管理工程的不确定污染物。
3.4逻辑回归和克里金方法的比较
表四
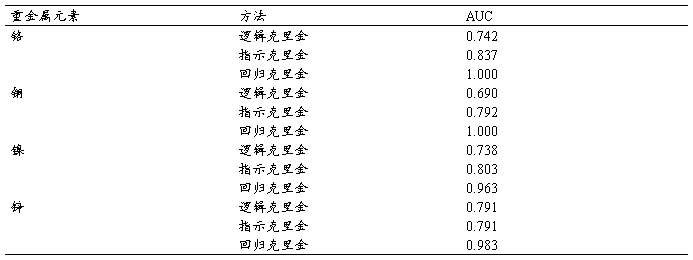
相对操作特征是衡量逻辑回归或者指示克里金适宜性的标准。低于ROC曲线的地区被估算着去测量模型中的解释性力量。AUC的估计值超过0.7的被普遍的认为是优良的,然而估计值超过0.9被认为是预示了一个极好的模型适宜性。表四总结了铬,铜,镍,锌在三种模型中的AUC。逻辑回归的AUC值从0.690到0.791,指示克里金的AUC值从到0.791到0.837,回归克里金的AUC值从0.963到1。AUC结果显示回归克里金的AUC比指示克里金和逻辑回归的AUC都高。这个发现暗示着回归克里金比指示克里金和逻辑回归有着较高的预测力。还有,回归克里金提供了任何一种重金属基于推动力因素在任何的位置危害可能性的概率。这个发现也预示着回归克里金产生一些益处,也定量着有害危险与推动力因素之间的关系。我们的研究结果和之前的一个研究相一致,回归克里金是一个很有效的空间预测方式,而且这种方式能在大的点设置时插入样本环境变量。此外,juanghe lee在辅助变量(协同克里金,回归克里金,有Q码因素分析的克里金)的基础上使用了三种插入方式在台湾的一个污染地插入了重金属集中区。这些插入方式更有效的使用辅助变量评估概率,以至于估计出重金属的空间分布。
表五

在研究当中,这三种方式除了提供每一种重金属元素危害的概率,而且在划定有害地区也是非常有效的。此外,0.95,0.85.0.75以及0.50的有害概率分布被用来划定土壤污染物的安全与有害区域,同时在多种概率的基础上描绘有害的状况。表五指示出有害区的百分比随着有害标准的不同而不同。多种方式决定的多种有害地区的结果为政策的制定者在更深的程度提供了一个有价值的参考。估计结果显示出有重金属污染等级的区域铬的含量是0到2.8%,铜的是3.%到4.4%,镍的是13.2%到18.3%,锌是2.5%到38.3%。这个发现提供了有害地区的信息,除了逻辑回归中的锌研究区域的四种重金属元素中,镍占有害污染的最大部分。这个研究在概率图的基础上,运用了三种方法去辨别安全的和有害的区域。和克里金方式相比较,通过逻辑回归的方法得出了锌的含量过高,通过逻辑回归的方法得出的铬铜镍的含量过低。更进一步,以上结果显著地作用于通过使用这三种方式而量化的有害区的成果。
4.结论
这个研究调查了模型方式的可行性,运用一个特别的案例研究探测污染和人类活动的关系。估计结果显示出回归克里金提高了预测效率,并在一个相对高程度的适宜环境中提供了可解释性力量。此外,像距渠道的距离,农业用地,工厂的距离这些推动力因素和土壤的重金属污染有着密切关系。这种提出的方式能够被延伸至包括土壤污染的交通运输。在研究区土壤污染和污染来源有密切的关系,来源包括工业工厂和灌溉系统。这些提倡的模型在人们没有确定土壤集中区而直接覆盖整个研究区域的情况下这是非常高端的,用来评估重金属的可疑性。通过空间地图,模型估计能够使土地利用的计划者帮着辨别有污染的区域。还有,逻辑回
5.致谢(未翻译)
报告