(数学建模论文摘要撰写方法)
摘要(黑体不加粗四号居中)
(第1段)首先简要叙述所给问题的意义和要求,并分别分析每个小问题的特点
(以下以三个问题为例)。根据这些特点我们对问题1用。。。。。。。。的方法解决;对问题2用。。。。。。。。的方法解决;对问题3用。。。。。。。。的方法解决。
(第2段) 对于问题1,我们用。。。。。。。。数学中的。。。。。。。。首先建立了。。。。。。。。
模型I。在对。。。。。。。。模型改进的基础上建立了。。。。。。。。。模型II。对模型进行了合理的理论证明和推导,所给出的理论证明结果大约为。。。。。。。。。,然后借助于。。。。。。。数学算法和。。。。。。软件,对附件中所提供的数据进行了筛选,去除异常数据,对残缺数据进行适当补充,并从中随机抽取了3组数据(每组8个采样)对理论结果进行了数据模拟,结果显示,理论结果与数据模拟结果吻合。(方法、软件、结果都必须清晰描述,可以独立成段,不建议使用表格)
(第3段)对于问题2,我们用。。。。。。。。
(第4段)对于问题3,我们用。。。。。。。。
如果题目单问题,则至少要给出2种模型,分别给出模型的名称、思想、软件、结果、亮点详细说明。并且一定要在摘要对两个或两个以上模型进行比较,优势较大的放后面,这两个(模型)一定要有具体结果。
(第5段) 如果在??条件下,模型可以进行适当修改,这种条件的改变可能来自你的一
种猜想或建议。要注意合理性。此推广模型可以不深入研究,也可以没有具体结果。
关键词:本文使用到的模型名称、方法名称、特别是亮点一定要在关键字里出现,
5~7个较合适。
注:字数700~1200之间;摘要中必须将具体方法、结果写出来;摘要写满几乎
一页,不要超过一页。摘要是重中之重,必须严格执行!。
页码:1(底居中)
一、问题重述(第二页起黑四号)
在保持原题主体思想不变下,可以自己组织词句对问题进行描述,主要数据可以直接复制,对所提出的问题部分基本原样复制。篇幅建议不要超过一页。大部分文字提炼自原题。
二、问题分析
主要是表达对题目的理解,特别是对附件的数据进行必要分析、描述(一般都有数据附件),这是需要提到分析数据的方法、理由。如果有多个小问题,可以对每个小问题进行分别分析。
(假设有3个问题)
(一) 问题1的分析
对问题1研究的意义的分析。
问题1属于。。。。。数学问题,对于解决此类问题一般数学方法的分析。 对附件中所给数据特点的分析。
对问题1所要求的结果进行分析。
由于以上原因,我们可以将首先建立一个。。。。。。的数学模型I,然后将建立一个。。。。。。。的模型II,。。。。。。。。。。对结果分别进行预测,并将结果进行比较.
(二) 问题2的分析
对问题2研究的意义的分析。
问题2属于。。。。。数学问题,对于解决此类问题一般数学方法的分析。 对附件中所给数据特点的分析。
对问题2所要求的结果进行分析。
由于以上原因,我们可以将首先建立一个。。。。。。的数学模型I,然后将建立一个。。。。。。。的模型II,。。。。。。。。。。对结果分别进行预测,并将结果进行比较.
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
三、模型假设(4号黑体)
(以下小4号)
1. 假设题目所给的数据真实可靠;
2.
3.
4.
5.
6.
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
注意:假设对整篇文章具有指导性,有时决定问题的难易。一定要注意假设的
某种角度上的合理性,不能乱编,完全偏离事实或与题目要求相抵触。注意罗列要工整。
四、定义与符号说明(4号黑体)
(对文章中所用到的主要数学符号进行解释小4号)
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
尽可能借鉴参考书上通常采用的符号,不宜自己乱定义符号,对于改进的一些模型,符号可以适当自己修正(下标、上标、参数等可以变,主符号最好与经典模型符号靠近)。对文章自己创新的名词需要特别解释。其他符号要进行说明,注意罗列要工整。如“xij~第i种疗法的第j项指标值”等,注意格式统一,不要出现零乱或前后不一致现象,关键是容易看懂。
五、模型的建立与求解(4号黑体)
第一部分:准备工作(4号宋体)
(一)数据的处理
1、。。。。。。数据全部缺失,不予考虑。
2、对数据测试的特点,如,周期等进行分析。
3、。。。。。。数据残缺,根据数据挖掘等理论根据。。。。。变化趋势进行补充。
4、对数据特点(后面将会用到的特征)进行提取。
(二)聚类分析(进行采样)
用。。。。。。。软件聚类分析和各个不同问题的需要,采得。。。组采样,每组5-8个采样值。将采样所对应的特征值进行列表或图示。
(二)预测的准备工作
根据数据特点,对总体和个体的特点进行比较,以表格或图示方式显示。 第二部分:问题1的。。。模型(4号宋体)
(一)模型I(。。。。。。的模型)
1. 该种模型的一般数学表达式,意义,和式中各种参数的意义。注明参考文献。
2. 。。。。。。模型I的建立和求解
(1) 说明问题1适用用此模型来解决,并将模型进行改进以适应问
题1。
(2) 借助准备工作中的采样,(用拟合等方法)确定出模型中的参
数。
(3) 给出问题1的数学模型I表达式和图形表示式。
(4) 给出误差分析的理论估计。
3.模型I的数值模拟
将模型I进行数值计算,并与附件中的真实采样值(进行列表或图
示)比较。对误差进行数据分析。
(二)模型II(。。。。。。的模型)
1. 该种模型的一般数学表达式,意义,和式中各种参数的意义。注明参考文献。
2. 。。。。。。模型II的建立和求解
(1) 说明问题1适用用此模型来解决,并将模型进行改进以适应问
题1。
(2) 借助准备工作中的采样,通过确定出模型中的参数。
(3) 给出问题1的数学模型I表达式和图形表示式。
(4) 给出误差分析的理论估计。
3.模型II的数值模拟
将模型II进行数值计算,并与附件中的真实采样值(进行列表或图示)比较。对误差进行数据分析
(三)模型III(。。。。。。的模型)
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
(四)问题1的三种数学模型的比较。
对三种模型的优点和缺点结合原始数据和模拟预测数据进行比较。给出各自得优点和缺点。
第三部分:问题2的。。。个模型(4号宋体)
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
第四部分:问题3的。。。个模型(4号宋体)
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
六、模型评价与推广
对本文中的模型给出比较客观的评价,必须实事求是,有根据,以便评卷人参考。
推广和优化,需要挖空心思,想出合理的、甚至可以合理改变题目给出的条件的、不一定可行但是具有一定想象空间的准理想的方法、模型。(大胆、合理、心细。反复推敲,这段500字半页左右的文字,可能决定生死存亡。)
七、参考文献(4号黑体)
(书写格式如下)
[1] 作者名1,作者名2.文章名字.杂志名字,年,卷(期):起始页码-结束页码
[2] 作者名1,作者名2.书名.出版地:出版社,年,起始页码-结束页码
[3] 作者名1,作者名2.文章名字. 年,卷(期):起始页码-结束页码,网页地
址。
[4] 李传鹏,什么是中国标准书号, .cn/mypage/page2.asp?pgid=51440&pid=46275,2006-9-18。
[5] 徐玖平、胡知能、李军,运筹学(II类),北京:科学出版社,2004。
[6] Ishizuka Y, AiyoshiE. Double penalty method for bilevel optimization problems. Annals of Operations Research, 24: 73- 88,1992。 注意:5篇以上!
八、附件(4号黑体)
(正文中不许出现程序,如果要附程序只能以附件形式给出)
20xx年数学建模评分参考标准:
摘要(很重要) 5分
数据筛选 35分
数学模型 35分
数据模拟 15分
总体感觉 10分
特别注意:
1、问题的结果要让评卷人好找到;显要位置---独立成段
2、摘要中要将方法、结果讲清楚;
3、可以有目录也可以不要目录;
4、建模的整个过程要清楚,自圆其说,有结果、有创新;
5、 模型要与数据结合,用数据验证过;
6、如果数学方法选错,肯定失败;
7、规范、整洁;总页数在35~45之间为宜。
8、必须有数学模型,同一问题的不同模型要比较;
9、数据必须有分析和筛选;
10、 模型不能太复杂,若用多项式回归分析,次数以3次为好。
第二篇:20xx年全国数学建模-论文模板
全国大学生数学建模竞赛论文格式规范
l 本科组参赛队从A、B题中任选一题,专科组参赛队从C、D题中任选一题。(全国评奖时,每个组别一、二等奖的总名额按每道题参赛队数的比例分配;但全国一等奖名额的一半将平均分配给本组别的每道题,另一半按每题论文数的比例分配。)
l 论文用白色A4纸打印;上下左右各留出至少2.5厘米的页边距;从左侧装订。
l 论文第一页为承诺书,具体内容和格式见本规范第二页。
l 论文第二页为编号专用页,用于赛区和全国评阅前后对论文进行编号,具体内容和格式见本规范第三页。
l 论文题目、摘要和关键词写在论文第三页上(无需译成英文),并从此页开始编写页码;页码必须位于每页页脚中部,用阿拉伯数字从“1”开始连续编号。注意:摘要应该是一份简明扼要的详细摘要,请认真书写(但篇幅不能超过一页)。
l 从第四页开始是论文正文(不要目录)。论文不能有页眉或任何可能显示答题人身份和所在学校等的信息。
l 论文应该思路清晰,表达简洁(正文尽量控制在20页以内,附录页数不限)。
l 引用别人的成果或其他公开的资料(包括网上查到的资料) 必须按照规定的参考文献的表述方式在正文引用处和参考文献中均明确列出。正文引用处用方括号标示参考文献的编号,如[1][3]等;引用书籍还必须指出页码。参考文献按正文中的引用次序列出,其中书籍的表述方式为:
[编号] 作者,书名,出版地:出版社,出版年。
参考文献中期刊杂志论文的表述方式为:
[编号] 作者,论文名,杂志名,卷期号:起止页码,出版年。
参考文献中网上资源的表述方式为:
[编号] 作者,资源标题,网址,访问时间(年月日)。
l 在论文纸质版附录中,应给出参赛者实际使用的软件名称、命令和编写的全部计算机源程序(若有的话)。同时,所有源程序文件必须放入论文电子版中备查。论文及源程序电子版压缩在一个文件中,一般不要超过20MB,且应与纸质版同时提交。(如果发现程序不能运行,或者运行结果与论文中报告的不一致,该论文可能会被认定为弄虚作假而被取消评奖资格。)
l 本规范中未作规定的,如排版格式(字号、字体、行距、颜色等)不做统一要求,可由赛区自行决定。
l 在不违反本规范的前提下,各赛区可以对论文增加其他要求(如在本规范要求的第一页前增加其他页和其他信息,或在论文的最后增加空白页等)。
l 不符合本格式规范的论文将被视为违反竞赛规则,无条件取消评奖资格。
l 本规范的解释权属于全国大学生数学建模竞赛组委会。
[注] 赛区评阅前将论文第一页取下保存,同时在第一页和第二页建立“赛区评阅编号”(由各赛区规定编号方式),“赛区评阅纪录”表格可供赛区评阅时使用(各赛区自行决定是否在评阅时使用该表格)。评阅后,赛区对送全国评阅的论文在第二页建立“全国统一编号”(编号方式由全国组委会规定,与去年格式相同),然后送全国评阅。论文第二页(编号页)由全国组委会评阅前取下保存,同时在第二页建立“全国评阅编号”。
全国大学生数学建模竞赛组委会
2013年8月26日修订
20##高教社杯全国大学生数学建模竞赛
承 诺 书
我们仔细阅读了《全国大学生数学建模竞赛章程》和《全国大学生数学建模竞赛参赛规则》(以下简称为“竞赛章程和参赛规则”,可从全国大学生数学建模竞赛网站下载)。
我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛章程和参赛规则的,如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛章程和参赛规则,以保证竞赛的公正、公平性。如有违反竞赛章程和参赛规则的行为,我们将受到严肃处理。
我们授权全国大学生数学建模竞赛组委会,可将我们的论文以任何形式进行公开展示(包括进行网上公示,在书籍、期刊和其他媒体进行正式或非正式发表等)。
我们参赛选择的题号是(从A/B/C/D中选择一项填写):
我们的参赛报名号为(如果赛区设置报名号的话):
所属学校(请填写完整的全名):
参赛队员 (打印并签名) :1.
2.
3.
指导教师或指导教师组负责人 (打印并签名):
(论文纸质版与电子版中的以上信息必须一致,只是电子版中无需签名。以上内容请仔细核对,提交后将不再允许做任何修改。如填写错误,论文可能被取消评奖资格。)
日期: 年 月 日

赛区评阅编号(由赛区组委会评阅前进行编号):
20##高教社杯全国大学生数学建模竞赛
编号专用页
赛区评阅编号(由赛区组委会评阅前进行编号):
赛区评阅记录(可供赛区评阅时使用):

全国统一编号(由赛区组委会送交全国前编号):
全国评阅编号(由全国组委会评阅前进行编号):
论文题目(不必自行拟题,直接使用竞赛题目即可)
摘 要
葡萄酒质量可通过有资质的评酒员打分确定,酿酒葡萄的好坏及葡萄酒本身的理化特性与所酿葡萄酒的质量也有直接的关系,因此从葡萄酒和葡萄检测的理化指标分析角度也将会在一定程度上反映葡萄酒和葡萄的质量。
针对问题一,单因素方差分析两组评酒员的评价结果是否有差异。建立单因素方差分析模型,通过单因素方差分析检验,经查表可知检验统计量F在因素影响不显著的范围内,故第一组与第二组无显著性差异。方差分析哪组结果更可信。计算每组10个评酒员对同一酒品整体评分方差,白葡萄酒、红葡萄酒共54种酒方差取均值,得出第一组方差小于第二组方差,故第一组结果更可信。
针对问题二,采用模糊聚类分析方法。经查阅资料选取对葡萄质量影响显著的几种理化性质与对附件一中每一种酒由第一组10位评酒员整体评分的均值作为样本集合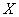 ,使用绝对值减数法建立模糊矩阵
,使用绝对值减数法建立模糊矩阵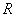 ,通过传递闭包法聚类并选出较适合的聚类分析布尔矩阵(的
,通过传递闭包法聚类并选出较适合的聚类分析布尔矩阵(的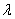 截矩阵),进行葡萄等级分成四类。
截矩阵),进行葡萄等级分成四类。
针对问题三,采用模糊聚类分析方法。首先根据葡萄和葡萄酒的各理化性质这些统计量值作出了特性指标矩阵,再采用模糊聚类分析中的最优划分法得出聚类分类结果,在白葡萄和白葡萄酒中,花色苷、单宁、色泽(L*(D65))含量差异明显,而总酚、葡萄总黄酮、白藜芦醇、DPPH、色泽(a*(D65)、b*(D65))、芳香物质含量类似。在红葡萄和红葡萄酒中,花色苷、单宁、色泽(L*(D65))含量差异明显,而总酚、葡萄总黄酮、白藜芦醇、DPPH、色泽(a*(D65)、b*(D65))、芳香物质含量类似。说明在某些方面葡萄的理化性质含量会直接影响到葡萄酒的理化成分含量,所以葡萄的品质对葡萄酒品质的优劣起着决定性作用。
针对问题四,采用相关性分析与BP神经网络方法。首先对所有葡萄与葡萄酒的理化性质与该葡萄/葡萄酒对应的整体评分做相关性分析,得出单宁、PH值等理化指标对葡萄酒质量影响较大。并对一部分酒样品数据(有重要影响的理化性质与酒样品得分(第一组整体评分))用BP神经网络进行学习和培训,从而可对剩余酒样品的评分进行预测。并且由于误差分析较小,故预测结果较准确,说明由葡萄与葡萄酒的理化指标可评价葡萄酒质量。
关键词:单因素方差分析;模糊聚类分析;平方自合成方法;BP神经网络
一、问题重述
确定……
二、问题分析
……
三、模型假设
……
四、符号说明
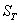 总偏差平方和
总偏差平方和
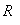 评酒的组数
评酒的组数
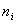 第i组评酒数目
第i组评酒数目
……
五、模型建立与求解
5.1 显著性差异判断与结果可信评估
5.1.1单因素方差分析
单因素方差分析也称作一维方差分析。它检验由单一因素影响的(几个相互独立的)因变量由因素各水平分组的均值之间的差异是否具有统计意义。还可以对该因素的若干水平分组中哪一组与其他各组均值间具有显著性差异进行分析,即进行均值的多重比较。
表1:单因素方差分析表

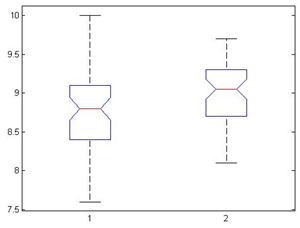
图1:方差分析图
六、结果分析与检验
1、判断两组评价结果有无显著性差异,采用单因素方差分析法分析显著性程度,可信度较高。分析哪一组更可信,采用方差分析的方法,方差大的评价结果离散程度大,可以分析出可信度。
七、模型的评价和推广
1、优点:
2、缺点:
……
八、参考文献
[1] ……
附 录
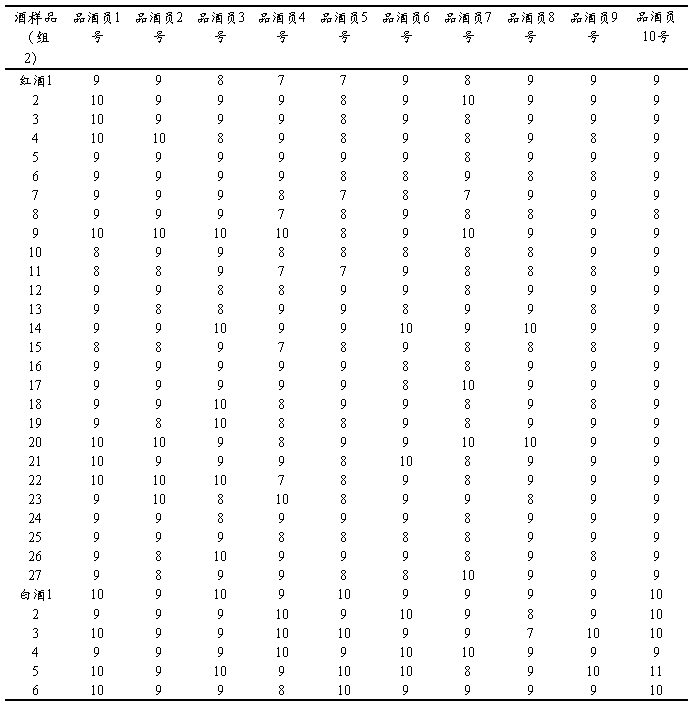
第一题:
下表为第二组品酒员对红白酒的总体评分(第一组品酒员对红白葡萄酒的综合评分方法同第二组):