考试题型:填空24%+简答4*4=16%+解答4*15=6
Chapter 1重要概念
1.什么编译程序?P3
答:编译程序的主要功能是把用高级语言编写的源程序翻译为等价的目标程序。
2.编译程序的工作过程?(6个阶段)P4
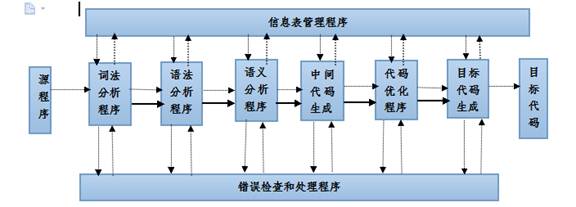
1、词法分析程序 2、语法分析程序 3、语义分析程序 4、中间代码生成
5、代码优化程序 6、目标代码生成
(不做优化是4个阶段,5、6不要)
3.编译程序的逻辑结构?P4 图1-2 编译程序的逻辑结构
4.执行高级语言编写的程序:(编译执行、解释执行)
1)按编译方式在计算机上执行用高级语言编写的程序,一般须经过两个阶段。第一个阶段称为编译阶段,其任务是由编译程序将源程序编译为目标程序,若目标程序不是机器代码,而是汇编语言程序,则尚需汇编程序再行汇编为机器代码程序;第二阶段称为运行阶段,其任务是在目标计算机上执行编译阶段所得到的目标程序。
2)用高级语言编写的程序也可以通过解释程序来执行。解释程序也以源程序作为它的输入,它与编译程序的主要区别是在解释程序的执行过程中不产生目标程序,而是解释执行源程序本身。
缺点:这种边翻译边执行的方式工作效率很低,但由于解释程序的结构比编译程序简单,且占用内存较少,在执行过程中也易于在源程序一级对程序进行修改,因此一些规模较小的语言,如BASIC,也常采用此种方式。
5.P11 第一段
编译程序的各部分之间的关系,是指他们之间的逻辑关系,而不一定是执行时间上的先后顺序,事实上,可按不同的执行流程来组织上述各部分的工作,这在很大程度上依赖与编译过程中对源程序扫描的遍数,以及如何划分各遍扫描所进行的工作。此处所说的“遍”,是指对源程序或其内部表示从头到尾扫视一次,并进行有关的加工处理工作。
(执行过程:单遍扫描、多遍扫描(大多数))
Chapter 2 前后文无关文法和语言
1.文法和语言的形式定义
产生语言就是制定出有限个规则(文法),借助于它们,就能产生出此语言的全部句子。
2.文法规则四要素:
文法 :四要素(VN,VT,S,P)。
1)产生语言的规则中的一系列需定义的语法范畴的名字称为非终结符号(大写字母),其集合记为 VN
2)规则中不需进一步定义的基本符号称为终结符号,其集合记为VT
3)非终结符中最终需定义的那个为推导句子开始的语法范畴,称其为开始符号或识别符号,记作S
4)每一规则是用 ::= 或 -> 连接起来的有序对,也称为产生式,用P表示.
3.句型的分析是指构造一种算法,用以判断所给符号串是否为某一文法的句型(或句子) 。
分两类方法:
自顶向下分析:从开始符推导出句子或句型
自底向上分析:从句子或句型归约出开始符
4.短语和句柄
语法树的应用——语法分析(自顶向下分析,自底向上分析)
用语法树进行句型分析:
用语法树自顶向下进行推导,---最右推导
用语法树自底向上进行归约。--最左规约
5.文法和语言的Chomsky分类
1)0型文法或短语结构文法(PSG)
2)1型文法或前后文有关文法(CSG)
3)2型文法或前后文无关文法(CFG).
4)3型文法或正规文法。(左线性文法+右线性文法)
编译过程的词法分析使用正规文法(3型文法)描述单词结构;
语法分析采用前后文无关文法(2型文法)描述语句结构
课堂练习
1)Chomsky定义的四种形式语言文法分别为 0型文法,1型文法,2型文法 ,3型文法,其中3型文法用于描述词法,2型文法用于描述语法。
2)递归文法产生的语言语句集合是无限集合。
3)规范推导是最右推导,规范归约是最左归约。
定义每种语言的文法都是不 (不|—)唯一的。
文法的化简与改造主要包括无用符号和无用产生式的删除 ,ε-产生式的消除 ,单产生式的消除几项内容。
大题:1)画出句子的语法树,找出所有的短语,直接短语和句柄(运算符最低原则)
Chapter3 词法分析及词法分析程序
1)了解6种定义,特点
正规文法、状态转换图、有限自动机FA(NFA、DFA)、状态转换矩阵、正规表达式、正规集
大题:正规式--状态图(NFA)--确定化---最小化
顺序:或,连接,闭包
(1)状态转换图的五要素
1)有限非空状态集K
2)有限输入字母表∑
3)状态之间的映射关系f
4)初态S0∈K
5)终态集Z∈K
(2)1.确定的有限自动机(DFA)
若FA在每个状态,对输入符号的下一状态是唯一的,称此种FA为确定的有限自动机DFA
2.非确定的有限自动机(NFA)
若FA在某个状态,对输入符号的下一状态不是唯一的,而是状态集的一个子集,称此种FA为非确定的有限自动机NFA。
(3)正规式中用到符号:
* 闭包 最优 (优先顺序可用括号加以改变)
· 连接(不引起混乱可略去) 次之
| 或 最后
正规式:将文法的终结符号用以上三种运算符连接起来组成的正规文法的表达式,是另一种用于描述正规文法的直观表示。
正规集:正规式所描述的字符串的集合。
(4)词法分析方法(正规文法、状态转换图、状态转换矩阵)
(5)单词描述(正规文法、状态转换图、有限自动机FA(NFA、DFA)、状态转换矩阵、正规表达式、正规集)
课堂练习:
1.单词的编译器内部表示为二元式(class , value)
2.单词的描述形式有许多种,包括文法形式正规文法,图示方式状态转换图,便于计算机存储的状态转换矩阵,自动机又分为NFA,DFA两种,正规表达式和正规集最便于体现单词的结构
3.Bell实验室M.Lesk等人用C语言研制的一个词法分析程序的自动生成工具叫LEX
4.判断(对)所有带有ε的自动机都是非确定的自动机
Chapter 4 语法分析和语法分析程序
1.语法分析方法:
自顶向下分析法:如递归下降法,LL(1)等(最左推导)
自底向上分析法:如算符优先法(分析表达式常用),LR等(最右规约)
大题LR、SLR1
(1)LL(1)---预测分析法(LL(1)分析法→最左推导→LL(1)分析表)
1) 编写文法,消除二义性;
2) 消除左递归、提取左因子;
3) 求 FIRST 集和 FOLLOW 集
FIRST(γ):γ可以推出的开头的终结符号(或ε)
FOLLOW(A):在所有句型中可能直接跟在A之后的终结符号
4)检查是不是 LL(1) 文法
(若不是 LL(1),说明文法的复杂性超过自顶向下方法的分析能力 )
5) 按照 LL(1) 文法构造预测分析表
6) 实现预测分析器
(2)算符优先分析法(构造算符优先矩阵→分析句子)
广义运算符: 文法的终结符号
广义运算对象: 非终结符
(3)LR(0)分析法
A.引入S’->S拓广文法
B.构造识别所有规范句型全部的活前缀的DFA
C.构造LR(0)分析表 rj---产生式编号
D.分析句子
(4)SLR(1)分析表

课堂练习
1、LL(1)分析器由 缓冲区 , 分析栈 , 分析表 ,
控制程序 四部分组成。
2、语法分析的方法主要分为 自顶向下 和 自底向上 两大类,前者又包括LL(1)分析法和递归下降法两种具体方法,后者又包括LR分析法和算符优先分析法两种具体方法
3、判断
( 错)1、自顶向下语法分析采用规范推导。(最左)
( 对)2、所有左递归文法均无法直接用LL(1)分析方法进行语法分析。
( 错)3、所有的自底向上语法分析,每步分析都是找出当前句型的句柄进行归约。(算符优先矩阵→最左素短语)
( 对)4、一个文法如果是LR(0)文法,则必定是LR(1)文法。(更多的文法适应SLR(1))
Chapter 5 语法制导翻译及中间代码生成
1)语法制导翻译:在一遍扫描中,由语法分析引导,既完成语法分析任务,又完成语义分析和中间代码生成方面的工作。
实现方法:对文法中的每一产生式,都附加一“语义动作”或“语义子程序”,且在语法分析过程中,每当用一产生式进行推导或归约时,语法分析程序除执行相应的语法分析动作之外,同时调用相应的语义子程序。
2)属性文法:一种附带有语义属性的前后文无关文法。
3)中间代码:介于源程序与目标程序之间的代码形式,
形式简单、含义明确、结构清晰、易于优化
4)四元式:(操作符,第一操作数,第二操作数,结果)
大题:1.算术表达式
2.布尔表达式改进记值
3.程序流程控制语句的翻译(序列、条件分支、while循环)
第二篇:编译原理大总结
《编译原理》期末复习指导
本课程是计算机专业的重要专业课之一,主要介绍程序设计语言编译构造的基本原理和基本实现方法。本课程主要讲授形式语言、有限状态自动机和词法分 析、自顶而下和自底而上的语法分析、中间代码生成、存储器的动态分配与管
理、符号表的组织与管理、代码生成、出错恢复等内容。通过本课程学习,使学生对编译的基本概念、原理和方法有完整的和清楚的理解,并能正确地、熟练地运用。
一、通过本课程的学习,应使学生达到以下基本要求:
1、正确理解什么是编译程序;了解编译程序工作的基本过程及其各阶段的基本
任务;熟悉编译程序总框;了解编译程序的生成过程和构造工具。
2、理解程序语言词法、语法和语义等概念;熟悉高级程序语言一般结构和主要共同特征。正确理解上下文无关文法基本概念,包括:文法的定义、编写、句
型、句子、语言、语法树、二义性等;理解三种参数传递方式:传值、传地址、传名的含义。
3、理解词法分析器功能及形式;熟练掌握词法分析器设计的原理,掌握运用状态转换图进行词法分析器设计。
4、正确理解自顶而下分析的基本思想;熟练掌握递归下降分析基本方法:消除左递归,消除回溯,构造递归下降子程序;掌握预测分析程序的基本原理和预测分析表构造;理解LL(1)方法的定义。
5、正确理解自下而上语法分析的基本思想,以及归约、短语、句柄、分析树等概念;掌握算符优先分析基本方法:算符优先表和和算符优先函数构造技术。
6、正确理解语法制导翻译基本原理;掌握基于属性文法的处理方法,了解自上而下分析制导翻译基本思想和实现方法。
7、熟悉常见的几种中间语言:四元式、三元式、逆波兰表示;掌握各种语句到四元式的翻译方法,包括:简单算术表达式,布尔表达式,控制语句,数组引用,过程调用等。
8、理解符号表的作用及符号表组织和使用方法,了解名字的作用范围,了解符号表中一般应包含的内容。
9、正确理解目标程序运行进存储空间的使用和组织管理方式;理解静态分配和动态存储分配基本思想;掌握FORTRAN存储分配的处理方式;掌握栈式动态分配中活动记录的作用、组织、内容及使用;了解嵌套过程语言程序运行时整个运行栈的内容的组织。
10、正确理解代码优化的定义和各种可能的优化概念;掌握用DAG表示进行局部优化的方法。
11、正确理解代码生成过程的基本问题,理解待用信息、寄存器描述和地址描述等概念;掌握简单代码生成算法、寄存器分配策略。
二、文字教材
文字教材是教学媒体的核心,是传递教学信息及学生进行自主学习的基本依据,是整个教学媒体体系的基础。包括主教材、学习指导书和参考资料汇编、教学大纲、课程教学设计方案、复习提要等。
1、《编译原理》徐国定编著,高等教育出版社。
参考资料:
1、《程序设计语言编译原理(第3版)》陈火旺、刘春林等编著,国防工业出版社。
2、《程序设计语言与编译》龚天富、侯文永编,电子工业出版社。
3、《编译原理—习题与解析》伍春香编著,清华大学出版社。
4、
三、教学内容和教学要求
第一章 概论
主要内容:编译程序,编译过程概述,编译程序的结构,编译程序与程序设计环境,编译程序生成,学习构造编译程序。
重点:编译程序工作的基本过程及其各阶段的基本任务,编译程序总框。
第二章 形式语言基础
主要内容:程序语言定义,初等数据类型,数据结构,高级高级语言的一般特性,程序结构,语句与控制结构,上下文无关文法,语法分析树与二义性。 重点:上下文无关文法,程序语言定义参数传递。
第三章 有限状态自动机和词法分析
主要内容:词法分析器任务,词法分析器设计,正规表达式与有限自动机,词法分析器自动生成。
重点:词法分析器的任务与设计,状态转换图。
第四章 自顶向下句法分析
主要内容:语法分析器的功能,自上而下语法分析(递归下降分析法,预测分析程序),LL(1)分析法,递归下降分析程序构造,预测分析程序,自上而下分析的错误诊察,语义错误诊察。
重点:递归下降子程序,预测分析表构造,LL(1)文法。
第五章 自底向上句法分析
主要内容:自下而上语法分析(算符优先分析法),算符优先分析,LR分析器,
LR(0)项目集族和LR(0)分析表的构造,SLR分析表的构造,规范LR分析表的构造,出错处理概述,词法分析阶段的错误诊察,语法分析(自下而上)阶段的错误诊察,语法分析器自动产生工具YACC。
重点:归约,算符优先表构造,LR分析法。
第六章 中间代码生成和符号表
主要内容:中间语言,说明语句,赋值语句的翻译,布尔表达式的翻译,控制语句的翻译,过程调用的处理各种常见中间语言形式,各种语句到四元式的翻译。符号表的组织与作用,整理与查找,名字的作用范围,符号表的内容。 重点:三种中间语言:四元式、三元式、逆波兰表示;算术表达式的翻译,布尔表达式的翻译,控制语句的翻译。符号表的作用与内容。
第七章 运行时刻存储和环境管理
主要内容:目标程序运行时的活动,运行时存储器的划分,静态存储管理,简单的栈式存储分配的实现,嵌套过程语言的栈式实现,堆式动态存储分配。 重点:静态分配策略和动态分配策略基本思想,嵌套过程语言栈式分配,活动
记录、运行时栈的组织。
第八章 代码生成
主要内容:目标机器模型,一个简单代码生成器,寄存器分配,DAG目标代码,窥孔优化。
重点:简单代码生成器,寄存器分配策略。
第九章 出错恢复
主要内容:词法分析的出错恢复,LR和LL句法分析的出错恢复
重点:错误的恢复方法。
四、考核方式说明
该课程的考核由形成性考核和期末课程考核两部分组成。其中形成性考核成绩由平时作业和上机实验两部分成绩组成,各占总成绩的10%,期末课程考核占总成绩的80%。
平时作业考核:要求学生认真完成平时作业,各办学点应组织作业的批改和成
绩的核定。平时作业的成绩评定标准和要求按省电大有关文件执行。
上机实验考核:学员必须完成规定的上机实验,并撰写实验报告,由辅导实验的老师批改并评定成绩,学员实验成绩评定单必须加盖承担实验单位的公章方能生效。
课程结业考核:该课程的结业考核在期末进行,采用笔试、闭卷,由省电大统一组织命题,试卷采用百分制,卷面成绩按80%的比例折算计入总成绩。
四、考试题型
试题类型包括:选择题,判断题,填空题,简答题,应用题。
模拟试题
一 、单项选择题
1.把汇编语言程序翻译成机器可执行的目标程序的工作是由______完成的。
A.编译器 B.解释器
C.汇编器 D.预处理器
2.编译过程中,语法分析器的任务是______。
1) 分析单词是怎样构成的
2) 分析单词串是如何构成语句和说明的
3) 分析语句和说明是如何构成程序的
4) 分析程序的结构
A.2和3 B.3和4
C.2,3和4 D.1,2,3和4
3.高级语言编译程序常用的语法分析方法中,递归下降分析法属于______分析方法。
A.自左至右 B.自顶向下
C.自底向上 D.自右向左
4.算符优先文法是指_______的文法。
1) 没有形如U->…VW…的规则 (U,V,W∈Vn)
2) 终结符号集Vt中任意两个符号对之间至多有一种优先关系成立。
3) 没有相同的规则右部。
4) 没有形如U->ε的规则
A.1,2 B.1,2,3
C.1,2,3,4 D.1,2,4
5.动态存储分配时,可以采用的分配方法是
1) 以过程为单位的栈式动态存储分配
2) 堆存储分配
3) 最佳分配方法
A.1 B.2
C.1,2 D.1,2,3
二、填空题
1.编译方式和解释方式的根本区别在于__________________。
2.LL(1)分析法中,第一个L的含义是_________________,第二个L的含义
是___________________,“1”的含义是____________________。
3.过程调用时,参数的传递方法通常有__________、__________、__________和传名。
4.一个上下文无关文法所含四个组成部分是____________集、______________集、_____________集和______________集。
三、判断题
1.算符优先关系表不一定存在对应的优先函数。…………( )
2.每个文法都能改写为LL(1)文法。………………………( )
3.符号表由词法分析程序建立,由语法分析程序使用……( )
4.上下文无关文法规则的左部一定是非终结符号…………( )
5.LL(1)文法有可能是二义性的。…………………………( )
四、简述题
1. 简述词法分析阶段的任务。
2. 什么是语法制导翻译?
3. 什么是素短语?
4. 什么是静态存储分配?
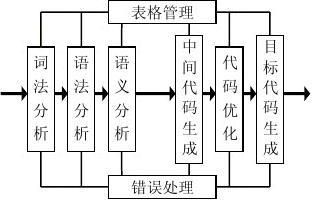
5. 画图说明编译程序的组成结构。
五、综合应用题
1. 设文法G(S):
S→(L) | aS | a
L→L,S | S
(1) 消除左递归和回溯;
(2) 计算每个非终结符的FIRST和FOLLOW;
(3) 构造预测分析表。
2. 已知文法G(E)
E→T|E+T
T→F|T * F
F→(E)|i
(1) 给出句型(T * F+i)的最右推导及画出语法树;
(2) 给出句型(T * F+i)的短语、素短语。
参考答案
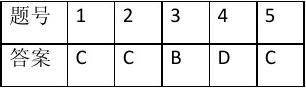
一、单项选择题
二、填空题
1.是否生成目标代码
2.从左向右进行分析,每次进行最左推导,向输入串中查看一个输入符号
3.传值,传地址,传结果 (顺序可互换)
4.终结符、非终结符、开始符号、产生式 (顺序可互换)
三、判断题
1.√
2.×
3.×
4.√
5.×
四、名词解释
1、答: 词法分析的基本任务是从左向右扫描每行源程序的符号,识别出单词及其属性,把单词换成统一的内部表示送给语法分析程序。同时还要完成在语法分析之前需要做的工作,如删除注解、空格、换行符等非必要信息,把标识符登录到符号表及某些预加工处理等。
2、答: 语法制导翻译就是在进行语法分析的同时,完成语义的分析,即在语法
分析的过程中,根据语言的语义定义随时翻译已识别的那部分语法成分的全部含义。
答: 有以下特征的短语称为素短语:
1) 它首先是一个短语。
2) 它至少含一个终结符号。
3) 除自身外,不再包含其它素短语。
3、答: 如果在编译时就能确定一个程序在运行时所需要的存储空间的大小,则在编译时就能够安排好目标程序运行时的全部数据空间,并确定每个数据项的存储单元地址,而这些数据项的存储地址在运行时始终不变,这就是静态存储分配。
4、答:
五、 综合应用题
1.解:
(1)
S→(L)|aS’ S’→S|ε L→SL’ L’→SL’|ε
(2)
FIRST)S)={(,a} FOLLOW(S)={#,,,)} FIRST(S’)={,a,ε} FOLLOW(S’)={#,,,)} FIRST(L)={(,a} FOLLOW(L)={ )} FIRST(L’)={,,ε} FOLLOW(L’〕={ )}
(3)


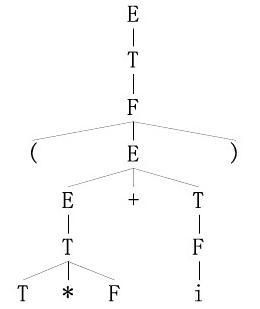
(1) 最右推导:
E→T→F→(E)→(E+T) →(E+F)→(E+i)→(T+i)→(T*F+i) 语法树:
(2) 短语:(T*F+i),T*F+i,T*F, 素短语:T*F,i i