经典包分类算法总结
1 RFC算法
1.1 RFC算法介绍
RFC(Recursive Flow Classification)算法[1]是一种多维IP分类快速查找算法,通过对实际的过滤规则数据库的考察,发现数据库中的过滤规则都有内在的结构和冗余度,这个特点可以为分类算法所利用。 RFC算法的主要思想是将IP分类问题看成一个将包头中的S比特数据到T比特的classID的一个映射(T=logN且N<<S,N是过滤规则的总数)。如果预先计算出包头中的这S位共2s种不同情况中每种情况所对应的classID值。那么每一个包只需要一次查表,即一次内存访问就可以得到相应的classID,但是这样会消耗极大的空间。RFC的思想是映射不是通过一步来完成,而是通过多个阶段(phase)完成,如图1.1所示。每个阶段的结果是将一个较大的集合映射成一个较小的集合,称其为一次缩减(reduction)。RFC算法共分P个阶段,每个阶段由一些列的并行的查找组成。每个查找的结果值比用于查找的索引值要短(故称为一次缩减)。
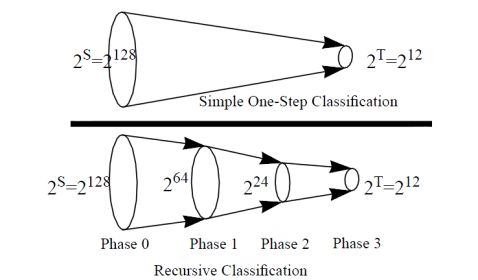
图1 RFC的基本构思
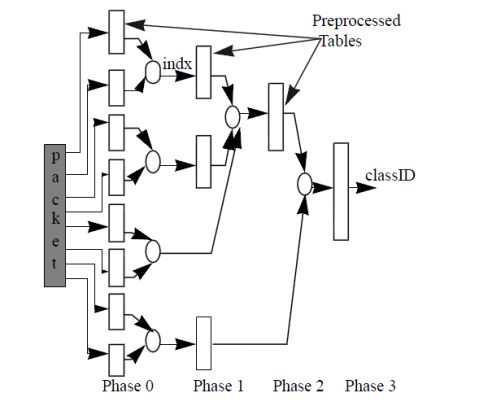
图2 一个四阶段的RFC缩减树
图1.2中建立了一种4阶段的缩减树,对IP包查找过程如下:
1)在第一阶段(Phase 0),包头中的K个域被分成若干个块
(chunks),每个块被用来作为并行查找的索引;
2)在后面的几个阶段,每次查找内存的索引值都是由前几个阶段的查找结果合并而成的。一种简单的合并办法就是将查找结果按二进制串连接起来(concatenation),但还有更好的方法可以节省空间;
3)在最后一个阶段,查找的结果得到一个值。由于我们进行了预先的计算,这个值就是该包对应的classID。
1.2 RFC算法性能分析
RFC算法受到两个参数的影响:
1)选取的阶段的数目P
2)在给定P的情况下,"缩减"树的形状.也就是后面的阶段的索引值从前面哪几个阶段的查找结果进行合并。
在给定P的情况下,给出一种严格的判定方法来选择最优的缩减树很困难。[1]中给出了两种启发性原则:
1)尽可能合并具有一定“相关性”的块。如我们尽可能早的将同一个IP地址的两个块进行合并。因为具有“相关性”的两个块往往在同一条规则或者在少数几个规则中集中出现。尽早对其进行合并,可以避免后续合并产生不必要的扩展;
2)在不引起内存激增的情况下.尽可能合并多的块。
在P和缩减树固定的情况下,随着过滤规则树N的增加,消耗的内存量也增加。同时,对于同样的过滤规则数据库,P=3比P=4消耗更多的内存,但是查找速度前者比后者要快。
RFC算法的优点:(1)易于并行处理,处于同一阶段的预处理表和
交叉乘积表可被并行地索引,处于不同阶段的表也可被并行的索引,这些表各自独立,处于不同的存储单元。(2)与其他算法相比,更适用于实际的网络中。
RFC算法的缺点:缺乏一般性,因为它与分类器的结构有关,因此需要针对不同的分类器来进行微调(tuning)才能达到理想中的最佳工作状态。一般的解决方法是在算法设计时便留有许多的参数供日后设定,像在RFC算法中所需要的阶段数,每一阶段中所做的化简比例等都是可以在执行时期设定的。
2 Set-prunning trie
2.1 Hierarchical Tries
分层查找树算法就是将分类字段的每一个维分成一层构造一个分层查找树,实际上就是对一维查找树的简单扩展,使用递归方式来生成分层查找树。基本思想是:设一个分类器C={Rj}有k个域,如果k>1,开始构建第一维的查找树,将其称之为F1-trie,它所对应的是分类器中每一条规则第一个域的前缀集{Rjl}。F1-trie中的每个结点表示一个前缀front,然后在front处进行递归构建一个(k—1)维的分层查找树Tp。前缀节点front使用“下一级查找树的指针next"指向下一级分层树Tp。由表2.1的规则库得出的分层查找树如图2.1所示。 假设D是树中一个结点,如果D’是D的前缀,一般称D’是D的祖先。如果D’是D的最长前缀,则称D’是D的最小祖先。 分类过程:进入分类算法的IP报文D(Dl,D2,?,Dd),分层查
找树算法首先根据Dl在F1-trie树上进行遍历,从而找到Dl的一条最佳匹配前缀,记下最后一个匹配结点为Z,然后沿着“下一级查找树的指针next”继续遍历(Z—1)维的分层查找树,记录下这条路径上所有匹配的规则。接着要回溯到Z的最小祖先Z’,所谓的最小祖先就是指设Z是树中一个结点,如果Z’是Z的最长前缀,则称Z’是Z的最小祖先。继续沿着Z’的“下一个查找树的指针next”进行遍历,直到Z节点的所有祖先都被遍历一次为止。最后,选择匹配规则中优先级最高的规则为进入分类报文的最佳匹配规则。如图给出了二元组D(00l,110)的分层查找树,其中虚线表示整个查找的过程。
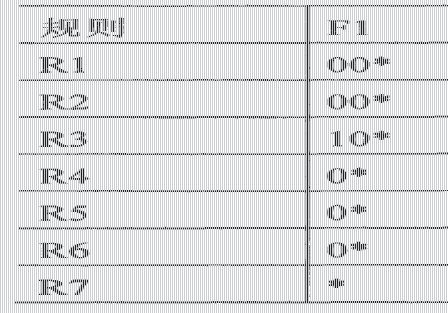
表2.1 规则库实例
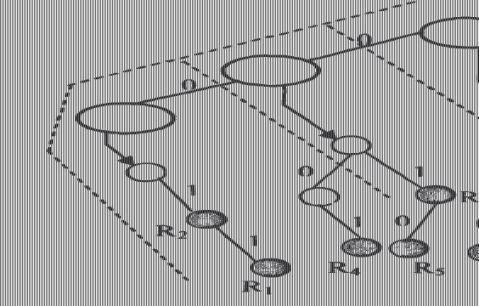
图2.1 2-D Hierarchical Tries实例
该算法的优点是直接、简单、易于硬件实现,但是由于分类维数的增加整个算法的回溯查找时间就随之增长,因此不利于规则维数的扩展性,同时也不法直接支持范围匹配。
2.2 Set-pruning trie
由于分层查找树算法的一些局限性,后来就提出了一种集合归并查找树算法,在分层查找树的算法上进行了改进,该算法主要是解决了分成查找树算法中多次回溯的问题,提出了通过对多维分层查找树中的某些结点进行多次复制的解决方案。下面介绍一下在查找过程中匹配l失败情况下,如何进行节点规则的复制。首先假设T(Z)是表示节点Z所指向的查找树,如果v对应前缀s,查找树T(D)中没有以sl开头的串,那么节点v则表示T(Z)中匹配字节l失败的结点。再假设Z’是Z的最小祖先节点,它所指向的下一层查找树有以s1开头的前缀串,假定是在结点u上。如果结点u有左儿子,并且对应某条规则,
那么就把结点u的左儿子复制到结点v上,作为结点v的左儿子;否则对结点u重复以上操作。但是如果不存在这样的结点u,就无需对结点进行复制。匹配2失败情况下的复制结点方法与上述方法一样。最后在查找过程中,记录下匹配优先级最高的那条规则。
如图2.2给出了二元组P(001,110)的集合归并查找树,其中虚线表示查找的过程。
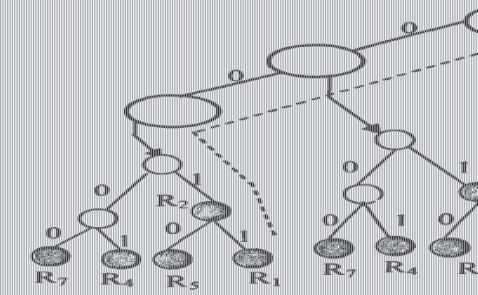
图2.2 Set-pruning trie实例
通过对多维分层查找树中某些结点进行多次复制,集合归并查找树算法的性能与分层查找树算法相比,减少了多维分层的层次,提高了分类查找的效率。但是由于多次复制结点使得所需存储空间增大,也不利于规则维数的扩展性。
3 Grid of trie
文献[3]介绍了种子算法Grid of Tries和Crossproducting算法。这
节主要介绍Grid of Tries算法,应用决策树方法解决关于源地址和目的地址前缀对的包分类问题。
如果将数据结构中的Trie of tries从一维扩展到二维,就形成Grid of Tries[3]。以表3.1中的数据库为例来说明这个扩展过程。先不考虑过滤规则数据库中源IP地址,根据过滤规则数据库中目的地址前缀构造一棵Trie of tries(称为Dest-Trie树)。这个目的前缀Trie树中每个节点,如果在数据库中存在其对应的目的地址前缀,则会指向一棵源地址Trie树(称为Src-trie树)。否则相应的指针为空(如图3.1中的空心圆圈所示)。
Grid of Tries算法在查找过程中是分成两步的。第一步是通过对目的Ip地址做最长匹配前缀,然后再通过查找对应的源地址Trie树得到代价最小的过滤规则。这意味着,任意一个Dest-Trie树中的节点不但包含过滤规则数据库中与该节点对应的源地址前缀,还应当包含该目的前缀的“前缀”(即它在Dest-Trie树中的祖先)所有的源地址前缀,由此建立的Grid of Tries树如图3.1所示。
以上建立的Grid of tries树是Trie树的简单扩展,其时间复杂度为O(W)。但是很明显,在内存方面,它存在着极大的浪费,每个Dest-Trie节点不但存储它自身的源地址前缀,还存储其祖先的源地址前缀。在最坏情况下,其空间复杂度可达到O(N2)。
一种改进的办法就是去掉这些多余的拷贝,每个目的地址前缀只包含在过滤规则数据库中与该目的地址配对的源地址前缀,由此我们得到一种改进的Grid of tries树。当去掉冗余拷贝之后,查找一个目
的—源地址对对应的最小代价的classID,不仅要从目的地址的最长匹配前缀所指向的Src-Trie树中进行搜索,还必须对该目的地址的最长匹配前缀的祖先所指向的Src-Trie树中进行搜索,从搜索所经过的路径中找出代价最小的过滤规则的classID,这使得时间复杂度上升到O(w2)。
一个巧妙的解决方法是引入转向指针,即通过预处理将Src-Trie树中的空指针指向其Dest-Trie树的某个祖先对应的Src-Trie中的节点,使得在查找过程中沿着最长匹配路径能够尽可能的前进。此外,为了确保算法的正确性,还必须保证目的-源IP前缀对中前缀长的节点,对应的代价也小(即IP前缀匹配越精确代价越小),这些都是通过预处理完成的。经过第二次改进的Grid of tries树见图3.2所示。 根据该图,对一个包,查找最小代价过滤规则的过程如
下:先对目的地址做最长前缀匹配,然后沿着目的地址最长匹配前缀所指向的Src-Trie根据包头的源地址沿着0、1指针(或者转向指针)尽可能的前进,直到无法继续前进为止,沿途经过的结点中存储的过滤规则代价最小的过滤规则所对应的classID即是其分类的classID。此时算法的时间复杂度为O(W)空间复杂度为O(NW)。 GOT算法还可改进。由于DT仅用于一维最长匹配前缀搜索,因此可采用更高效搜索方法。实际中可将总搜索次数降低到logw +w。另一种改进是采用多比特树替代单比特ST树,使ST的深度从w减少到w/m(m为比特数),故查找时间可降为O(logw+w/m)。但所需空间将从2Nw增加到Nw2m/m,因此m需折衷选择。此外,算法需要
较多的预处理时间。通过扩展,GOT还可支持范围匹配,与CP算法结合也可实现多维的分类,但最坏情况下的性能无法保证。
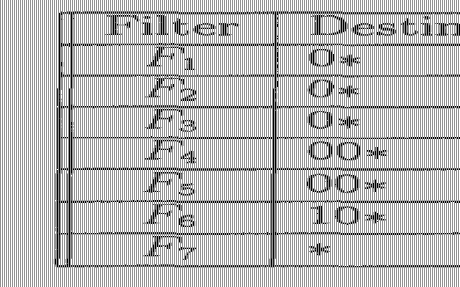
表3.1 规则库实例
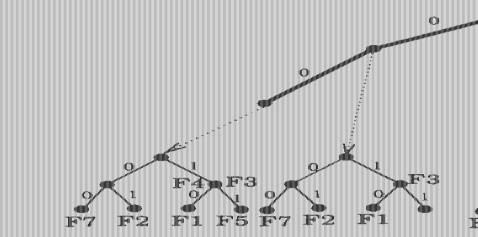
图3.1 根据表3.1建立的Grid of trie
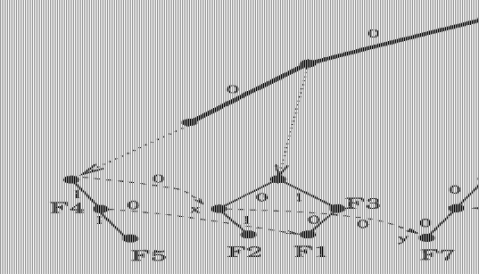
图3.2 改进过的Grid of trie
4 Cross-Producting算法
Cross-Producting算法可实现对多维的任意规则的快速匹配,其基本思想是以牺牲空间为代价换取时间复杂度的降低。CP算法先在每一维上分别进行匹配,把结果连接起来形成交叉乘积,在乘积空间中直接映射到最佳匹配。CP算法查找时间很短,但最坏情况下乘积空间巨大(O(N k)),如50条规则需约1.5M空间。一种改进的On-Demand CP算法采用了缓存(Cache)技术降低空间的需求,使之能用于更大规模的规则库,但其最坏情况下的搜索时间得不到保证。
Cross-Producting的Cache策略是基于对过虑规则中各域值的交叉组合的“缓存”,每一个交叉组合对应一类IP包,因此用少量的Cross-Producting就可以代表相当数量的一类IP包。在Cross-Producting中表现出的局部性,也相应好得多,Cache的效率也高得多。
Cross-Producting算法是先根据包头H不同的数据域分别做最长前缀匹配,可以证明将各个域的最长前缀配的结果连接起来产生的Cross-Producting所对应的最佳过虑规则也是H的最佳匹配过滤规则。如果预先计算出所有的Cross-Producting所对应的最佳匹配规则,那么就可以只需要先分别对各个域分别做最长前缀匹配,然后通过一次查表(假定采用的Hash表不发生冲突)就可以得到最终结果。而且分别对不同的域查找其最长前缀的匹配,在硬件上非常容易进行并行处理。
但在极端情况下,Cross-Product可能会产生内存爆炸问题,解决办法是采取和硬件Cache相类似的思想(并不将所有的Cross-product的最佳匹配过滤规则都存起来(而是固定实际存储的最佳匹配过滤规则的数量(类似一个固定大小的硬件Cache,称其为软Cache,软Catche的内容是动态更新的。当一个包头H到达的时候,先对其按照各自的域得到最精确匹配,然后将不同域的查找结果连接起来(进行Hash查找)。在绝大部分情况下,都能够成功(称为cache hit)。在不成功的情况下(说明相应的cross-product尚不在cache中(此时需要进行计算,得到最佳匹配前缀的cross-product,同时,根据某种置换策略将软Cache中的一个不常用的cross-product换出(换入当前的cross-product)。
5 Bit Vector
5.1 Parallel BV
Parallel BV(Parallel Bit Vector or Bit Vector Scheme)算法[2],由
Lakshman和Stiliads提出。作者假设所有规则已经按优先级(Priority)排序。对于每维,N条规则最多能定义2N+1个基本间隔。每维每个基本间隔都为之定义一个N位的位向量,其每位对应一条规则。在构造每个位向量时,其所有位均被初始化为“0”,然后将该向量中所有与该基本间隔交叠的规则对应的位都置为“1”。一旦所有位向量和d个数据结构计算完毕,查找也变得的简单。由于每维持有一个数据结构,各维查找可以独立进行,各找到一个位向量,待各维查找均己完毕,共找到d个位向量。接着,d个位向量执行“与”(AND)操作,得到一个最终的位向量。此位向量中,所有“1"位对应之规则均为匹配规则,而最高一个“1"位对应之规则具有最高优先级,为最佳匹配。 该算法的查找时间为O(logN),内存需求为O(N2)。该算法适于硬件实现。令W表示内存接口宽度,则访问一个N位向量需要?N/W?次访问。
5.2 ABV
ABV(Aggregated Bit-Vector)算法[5],通过对规则集的统计观察,对ParallelBV算法加以改进。ABV将所有规则转化成前缀,和TCAM一样导致规则集的膨胀。一开始,ABV向量的构造和Parallel BV向量方法相同。作者充分利用真实规则集与输入包相匹配的规则个数一般是5或更小这条性质,该性质导致N位向量稀疏。为减少内存访问次数,ABV将N位向量分割成A大块(Chunk),每个大块有?N/A?位。进行压缩时,块中全为“0”则值为“0”,否则值为“1”,值为“l”的块在查找时需要恢复。
该算法查找过程如下。每个独立查找返回一个A位的ABV向量,然后将这些ABV向量相“与",合并成一个ABV向量。ABV向量中每个“1”位,需要恢复成原向量,重新执行“与”操作。直到所有向量中所有位对应的是一条规则。用真实规则仿真,ABV算法的内存访问次数比Parallel BV算法小4倍。使用模拟规则仿真,ABV算法的内存访问次数比小20倍。
6 TCAM算法
CAM是Content Access Memory的缩写,是一种专用存储器件,可实现快速大批量的数据进行并行搜索。原先的CAM是一种单纯的二进制器件,每一个比特位只能存储0或1这两个二进制数,而最近几年出现一种可以存储三种值的三态CAM,它的每个存储位置可存储O、1或X这三种值。TCAM算法就是将所有的规则使用TCAM(三态CAM)硬件来实现,从而实现并行匹配,该算法的空间复杂度为O(N),时间复杂度为O(1)。TCAM算法以变量/掩码形式存储一个w比特的项。其中,变量和掩码都是w比特长,这种表示形式和IP地址表示方法相类似,这也使得TCAM算法在IP路由查找中得到了比较广泛的应用。在IP报文分类问题,如果W=64,那么对于二维IP报文分类规则(61.136.*)、(202.117.112.*),在TCAM中存储形式为(61.136.0.0、202.117.112.0、255.255.0.0、255.255.255.0)。在分类的时候,先提取相应参数域,然后在连接各个参数域所组成的TCAM输入值,查找在掩码位置值为l的二进制位与变量相匹配则就找到匹配
位。
该算法分类速度极快,但是却需要增加一个容量为dNw的CAM存储器,由于这种存储器价格较高,而且耗电量大,又不能直接支持范围匹配,因而对规则数、规则数量以及每维宽度的可扩展性都比较差,仅仅适用于规则量较小的的IP报文分类。
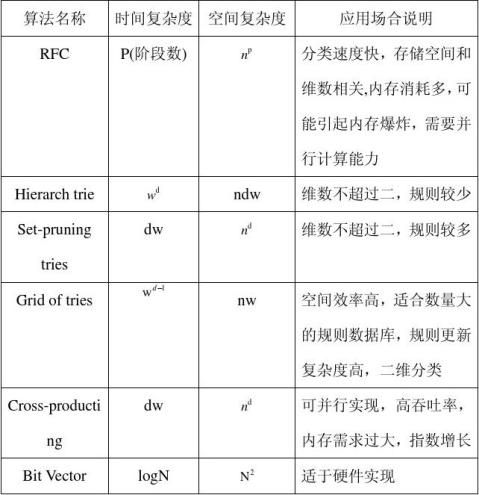
6 各种算法性能比较

参考文献
[1] P.Gupta and N.McKeown.Packet Classification on Multiple Fields.ACM Sigcomm.August 1 999.
[2] T.V.Lakshman and D.Stiliadis,“High-Speed Policy-based Packet Forwarding Using Efficient Multidimensional Range Matching,”in ACM SIGCOMM'98,September 1 998.
[3] V.Srinivasan,S.Suri,G.Varghese,and M.Waldvogd.Fast and Scalable Layer Four Switching.ACM Sigcomm.June 1998.
[4]Gupta P,McKeown N.Algorithms for packet classification.IEEE Network,Mar 2001 15 2:24-32
[5] Florin Baboescu and George Varghese. Scalable Packet Classification.SIGCOMM’01, August 27-31,