Erdas基础教程: 非监督分类
1.图像分类简介(Introduction to classification)
图像分类就是基于图像像元的数据文件值,将像元归并成有限几种类型、等级或数据集的过程。常规图像分类主要有两种方法:非监督分类与监督分类,专家分类方法是近年来发展起来的新兴遥感图像分类方法,下面介绍这三种分类方法。
非监督分类运用1SODATA(Iterative Self-Organizing Data Analysis Technique )算法,完全按照像元的光谱特性进行统计分类,常常用于对分类区没有什么了解的情况。使用该方法时。原始图像的所有波段都参于分类运算,分类结果往往是各类像元数大体等比例。由于人为干预较少,非监督分类过程的自动化程度较高。非监督分类一般要经过以下几个步骤:初始分类、专题判别、分类合并、色彩确定、分类后处理、色彩重定义、栅格矢量转换、统计分析。
监督分类比非监督分类更多地要求用户来控制,常用于对研究区域比较了解的情况。在监督分类过程中,首先选择可以识别或者借助其它信息可以断定其类型的像元建立模板,然后基于该模板使计算机系统自动识别具有相同特性的像元。对分类结果进行评价后再对模板进行修改,多次反复后建立一个比较准确的模板,并在此基础上最终进行分类。监督分类一般要经过以下几个步骤:建立模板(训练样本)、评价模板、确定初步分类图、检验分类结果、分类后处理、分类特征统计、栅格矢量转换。
专家分类首先需要建立知识库,根据分类目标提出假设,井依据所拥有的数据资料定义支持假设的规则、条件和变量,然后应用知识库自动进行分类,ERDAS IMAG1NE图像处理系统率先推出专家分类器模块,包括知识工程师和知识分类器两部分,分别应用于不同的情况。
由于基本的非监督分类属于IMAGINE Essentia1s级产品功能、但在1MAGINE Professional级产品中有一定的功能扩展,而监督分类和专家分类只属于IMAGINE ProfeSsiona1级产品,所以,非监督分类命令分别出现在Data Preparation菜单和classification菜单中,而监督分类和专家分类命令仅出现在Classification菜单中。
2 非监督分类(Unsupervised Classification)
ERDAS IMAGINE使用ISODATA算法(基于最小光谱距离公式)来进行非监督分类。聚类过程始于任意聚类平均值或一个己有分类模板的平均值:聚类每重复一次,聚类的平均值就更新一次,新聚类的均值再用于下次聚类循环。 ISODATA实用程序不断重复,直到最大的循环次数已达到设定阈值或者两次聚类结果相比有达到要求百分比的像元类别已经不再发生变化。
2.1分类过程(classification ProcedUre )
第一步:调出非监督分类对话框
调出非监督分类对话框的方法有以下两种:
方法一:在ERDAS图标面板工具条中,点击Dataprep图标
→ Data Preparation →unsupervised Classification →Unsupervised Classification对话框如下:
1
方法二: 在ERDAS图标面板工具条中点击Classifier

图标
Classification---→unsupervised classification对话框如下:
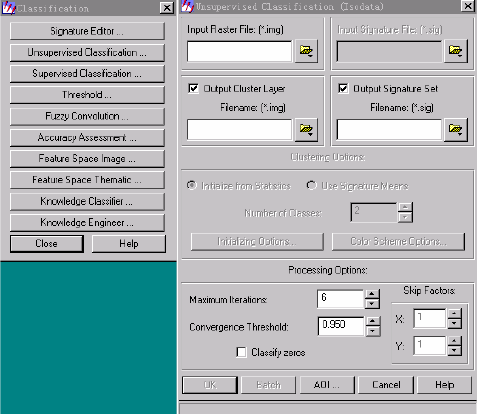
→C1assification →Unsupervised
可以看到,两种方法调出的Unsupervised Classification对话框是有一些区别的。 第二步:进行非监督分类
在Unsupervised classification对话框中:
2
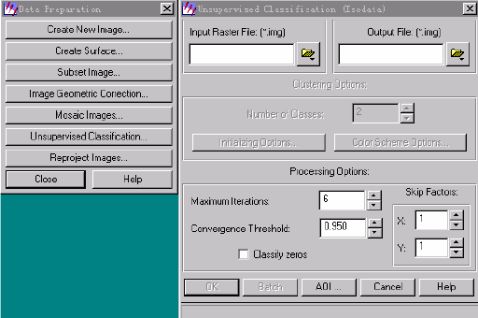
→确定输出文件(Input Raster File):lazhoucity.img(要被分类的图像)
→确定输出文件(Output File):lz-isodat.img(即将产生的分类图像)
→选择生成分类摸板文件: Output Signature Set(将产生一个模板文件)
→确定分类摸板文件(Filename ): lz-isodat.sig
→对Clustering options选择Initialize from Statistics单选框
Initialize from Statistics指由图像文件整体(或其AOI区域)的统计值产主自由聚类,分出类别的多少由自己决定。Use Signature Means是基于选定的模板文件进行非监督分类,类别的数目由模板文件决定。
→确定初始分类数(Number of classes): 18分出18个类别)
实际工作中一般将分类数取为最终分类数的2倍以上。
.点击Initializing options按钮可以调出Fi1e Statistics Options对话框以设置ISODATA的一些统计参数, .点击Co1or Scheme Options按钮可以调出output color Scheme Options对话框以决定输出的分类图像是彩色的还是黑白的。这两个设置项使用缺省值。
.定义最大循环次数(Maximum Iterations): 24
最大循环次数(Maximum Iterations)是指ISODATA重新聚类的最多次数,这是为了避免程序运行时间太长或由于没有达到聚类标准而导致的死循环。一般在应用中将循环次数都取6次以上。
→设置循环收敛阈值(Convergence Threshold):0.95
收敛阈值(Convergence Threshold)是指两次分类结果相比保持不变的像元所占最大百分之此值的设立可以避免ISODATA无限循环下去。
→点击OK按钮(关闭Unsupervised Classification对话框,执行非监督分类,获得一个初步的分类结
3

4 果)


2.2 分类评价(Evaluate Classification )
获得一个初步的分类结果以后,可以应用分类叠加(Classification over1ay)方法来评价检查分类精度。其方法如下:
第一步:显示原图像与分类图像
在视窗中同时显示lanzhoucity.img和lz-isodat.img:两个图像的叠加顺序为lanzhoucity.img在下、lz-isodat.img在上,lanzhoucity显示方式用红(4)、绿(5)、蓝(3 )。
第二步:打开分类图像属性并调整字段显示顺序 在视窗工具条中:点击
→打开Raster工具面板
→点击RaSter工具面板的图标(或者在视窗菜单条:Rster---Attributes)
→打开Raster Attribute Editor对话框(lz-isodat.img的属性表) 图标(或者选择Raster菜单项—--选择Tools菜单)
5
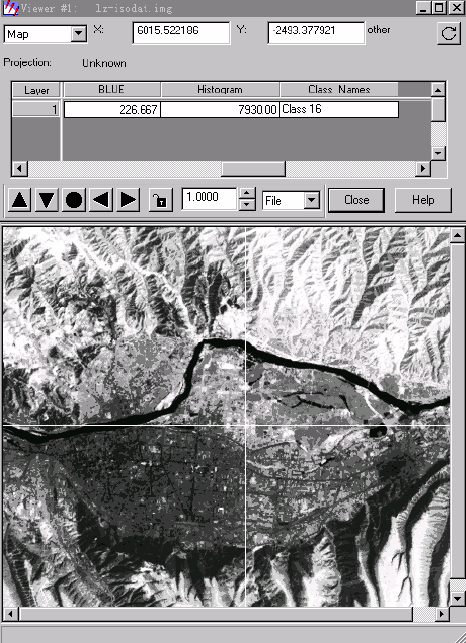
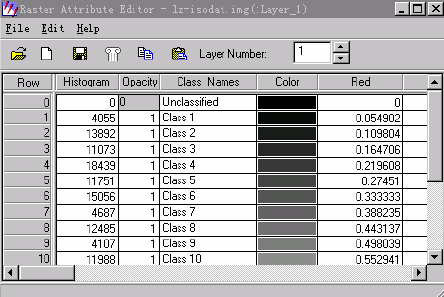
属性表中的19个记录分别对应产生的18个类及Unclassified类,每个记录都有一系列的字段。如果想看到所有字段,需要用鼠标拖动浏览条,为了方便看到关心的重要字段,需要调整字段显示顺序。
Raster Attribute Editor对话框菜单条:Edit→Column Properties →column properties对话框
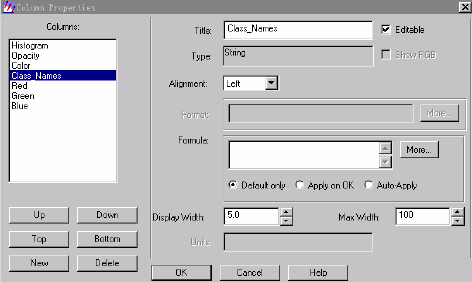
在Columns中选择要调整显示顺序的字段,通过Up、 Down、Top、Bottom等几个按钮调整其合适的位置,通过选择Display Width调整其显示宽度,通过Alignment调整其对齐方式。如果选择Editable复选框,则可以在Title中修改各个字段的名字及其它内容。
→在Column Properties对话框中调整字段顺序,最后使Histogram、opacity、 color、 class_names四个手段的显示顺序依次排在前面。
→点击OK按钮(关闭Column properties对话框)
→返回Raster Attribute Editor对话框(lz-isodat.img的属性表)
第三步:给各个类别赋相应的颜色(如果在分类时选择了彩色,这一步就可以省去)
Raster Attribute Editor对话框(lz-isodat.img的属性):
→点击一个类别的Row字段从而选择该类别
→右键点击该类别的Color字段(颜色显示区)
→As Is菜单 → 选择一种颜色
→重复以上步骤直到给所有类别赋予合适的颜色
第四步:不透明度设置
由于分类图像覆盖在原图像上面,为了对单个类别的判别精度进行分析,首先要把其它所有类别的不
6
透明程度(Opacity)值设为0(即改为透明),而要分析的类别的透明度设为1(即不透明)。
Raster Attribute Editor 对话框(lz-isodat.img的属性表):
→右键点击Opacity字段的名字
→Column Options菜单→Formula菜单项
→Formula对话框
→在Formula对话框的Formula输入框中(用鼠标点击右上数字区)输入0
→点击Apply按钮(应用设置)
→返回Raster Attribute Editor 对话框(lz-isodat.img的属性表):
→点击一个类别的ROW字段从而选择该类别
→点击该类别的Opacity字段从而进入输入状态
→在该类别的Opacity 字段中输入1,并按回车键
此时,在视窗中只有要分析类别的颜色显示在原图像的上面,其它类别都是透明的。
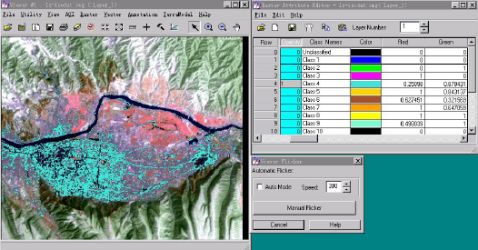
第五步:确定类别专题意义及其准确程度
视窗菜单条:Utility→flicker→viewer Flicker对话框→Auto Mode
本小步是设置分类图像在原图像修背景上闪烁,观察它与背景图像之间的关系从而断定该类别的专题意义,并分析其分类准确与否。
第六步:标注类别的名称和相应颜色
Raster Attribute Editor对话框(lz-isodat.img的属性表):
→点击刚才分析类别的ROW字段从而选择该类别
→点击该类别的class Names字段从而进入输入状态
→在该类别的Class Names字段中输入其专题意义(如居民区),并按回车键
→右键点击该类别的Color字段(颜色显示区)
→As Is菜单→选择一种合适的颜色
重复以上4、5、6三步直到对所有类别都进行了分析与处理。注意,在进行分类叠加分析时,一次可以选择一个类别,也可以选择多个类别同时进行。
7
第二篇:论述监督分类与非监督分类却别与联系,及各自优缺点
论述监督分类与非监督分类却别与联系,及各自
优缺点
监督分类:首先需要从研究区域选取有代表性的训练场地作为样本。根据已知训练区提供的样本,通过选择特征参数(如像素亮度均值、方差等),建立判别函数,据此对样本像元进行分类,依据样本类别的特征来识别非样本像元的归属类别。
非监督分类:在没有先验类别作为样本的条件下,根据像元间相似度大小进行计算机自动判别归类,无须人为干预,分类后需确定地面类别。
区别与联系:
根本区别在于是否利用训练场地来获取先验的类别知识。
非监督分类不需要更多的先验知识,据地物的光谱统计特性进行分类。当两地物类型对应的光谱特征差异很小时,分类效果不如监督分类效果好。
? 监督分类常常用于对分类区比较了解情况下,要求用户控制.
? 1)选择可以识别或可以断定其类型的像元建立模板,然后基于该模板使系统自动识别具有相同特征的像元.
? 2)对分类结果进行评价后再对模板进行修改,多次反复后建立比较正确的模板,在此基础上最终进行分类.
各自优缺点:
监督分类的特点:
主要优点:可充分利用分类地区的先验知识,预先确定分类的类别;可控制训练样本的选择,并可通过反复检验训练样本,以提高分类精度(避免分类中的严重错误);可避免非监督分类中对光谱集群组的重新归类。
主要缺点:人为主观因素较强;训练样本的选取和评估需花费较多的人力、时间;只能识别训练样本中所定义的类别,对于因训练者不知或因数量太少未被定义的类别,监督分类不能识别,从而影响分结果(对土地覆盖类型复杂的地区需特别注意)。
非监督分类特点:
主要优点:无需对分类区域有广泛地了解,仅需一定的知识来解释分类出的集群组;人为误差的机会减少,需输入的初始参数较少(往往仅需给出所要分出的集群数量、计算迭代次数、分类误差的阈值等);可以形成范围很小但具有独特光谱特征的集群,所分的类别比监督分类的类别更均质;独特的、覆盖量小的类别均能够被识别。 主要缺点:对其结果需进行大量分析及后处理,才能得到可靠分类结果;分类出的集群与地类间,或对应、或不对应,加上普遍存在的“同物异谱”及“异物同谱”现象,使集群组与类别的匹配难度大;因各类别光谱特征随时间、地形等变化,则不同图像间的光谱集群组无法保持其连续性,难以对比。