《海量数据处理常用思路和方法》
大数据量,海量数据 处理方法总结
最近有点忙,稍微空闲下来,发篇总结贴。
大数据量的问题是很多面试笔试中经常出现的问题,比如baidu google 腾讯 这样的一些涉及到海量数据的公司经常会问到。
下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题。下面的一些问题基本直接来源于公司的面试笔试题目,方法不一定最优,如果你有更好的处理方法,欢迎与我讨论。
1.Bloom filter
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:
对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。
还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数个数。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况下,m至少要等于n*lg(1/E)才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应该>=nlg(1/E)*lge 大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。
扩展:
Bloom filter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全1表示元素在不在这个集合中。Counting bloom filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。
问题实例:给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿,n=50亿,如果按出错
率0.01算需要的大概是650亿个bit。现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些urlip是一一对应的,就可以转换成ip,则大大简单了。
2.Hashing
适用范围:快速查找,删除的基本数据结构,通常需要总数据量可以放入内存
基本原理及要点:
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
扩展:
d-left hashing中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key 存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
问题实例:
1).海量日志数据,提取出某日访问百度次数最多的那个IP。
IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。
3.bit-map
适用范围:可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
基本原理及要点:使用bit数组来表示某些元素是否存在,比如8位电话号码
扩展:bloom filter可以看做是对bit-map的扩展
问题实例:
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map。
4.堆
适用范围:海量数据前n大,并且n比较小,堆可以放入内存
基本原理及要点:最大堆求前n小,最小堆求前n大。方法,比如求前n小,我们比较当前元素与最大堆里的最大元素,如果它小于最大元素,则应该替换那个最大元素。这样最后得到的n个元素就是最小的n个。适合大数据量,求前n小,n的大小比较小的情况,这样可以扫描一遍即可得到所有的前n元素,效率很高。
扩展:双堆,一个最大堆与一个最小堆结合,可以用来维护中位数。
问题实例:
1)100w个数中找最大的前100个数。
用一个100个元素大小的最小堆即可。
5.双层桶划分 ----其实本质上就是【分而治之】的思想,重在“分”的技巧上!
适用范围:第k大,中位数,不重复或重复的数字
基本原理及要点:因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行。可以通过多次缩小,双层只是一个例子。
扩展:
问题实例:
1).2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
有点像鸽巢原理,整数个数为2^32,也就是,我们可以将这2^32个数,划分为2^8个区域(比如用单个文件代表一个区域),然后将数据分离到不同的区域,然后不同的区域在利用bitmap就可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方便的解决。
2).5亿个int找它们的中位数。
这个例子比上面那个更明显。首先我们将int划分为2^16个区域,然后读取数据统计落到各个区域里的数的个数,之后我们根据统计结果就可以判断中位数落到那个区域,同时知道这个区域中的第几大数刚好是中位数。然后第二次扫描我们只统计落在这个区域中的那些数就可以了。
实际上,如果不是int是int64,我们可以经过3次这样的划分即可降低到可以接受的程度。即可以先将int64分成2^24个区域,然后确定区域的第几大数,在将该区域分成2^20个子区域,然后确定是子区域的第几大数,然后子区域里的数的个数只有2^20,就可以直接利用direct addr table进行统计了。
6.数据库索引
适用范围:大数据量的增删改查
基本原理及要点:利用数据的设计实现方法,对海量数据的增删改查进行处理。
扩展:
问题实例:
7.倒排索引(Inverted index)
适用范围:搜索引擎,关键字查询
基本原理及要点:为何叫倒排索引?一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
以英文为例,下面是要被索引的文本:
T0 = "it is what it is"
T1 = "what is it"
T2 = "it is a banana"
我们就能得到下面的反向文件索引:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
检索的条件"what", "is" 和 "it" 将对应集合的交集。
正向索引开发出来用来存储每个文档的单词的列表。正向索引的查询往往满足每个文档有序频繁的全文查询和每个单词在校验文档中的验证这样的查询。在正向索引中,文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。也就是说文档指向了它包含的那些单词,而反向索引则是单词指向了包含它的文档,很容易看到这个反向的关系。
扩展:
问题实例:文档检索系统,查询那些文件包含了某单词,比如常见的学术论文的关键字搜索。
8.外排序
适用范围:大数据的排序,去重
基本原理及要点:外排序的归并方法,置换选择 败者树原理,最优归并树
扩展:
问题实例:
1).有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16个字节,内存限制大小是1M。返回频数最高的100个词。
这个数据具有很明显的特点,词的大小为16个字节,但是内存只有1m做hash有些不够,所以可以用来排序。内存可以当输入缓冲区使用。
9.trie树
适用范围:数据量大,重复多,但是数据种类小可以放入内存
基本原理及要点:实现方式,节点孩子的表示方式
扩展:压缩实现。
问题实例:
1).有10个文件,每个文件1G, 每个文件的每一行都存放的是用户的query,每个文件的query都可能重复。要你按照query的频度排序 。
2).1000万字符串,其中有些是相同的(重复),需要把重复的全部去掉,保留没有重复的字符串。请问怎么设计和实现?
3).寻找热门查询:查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个,每个不超过255字节。
10.分布式处理 mapreduce
适用范围:数据量大,但是数据种类小可以放入内存
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。

Bloom-Filter,即布隆过滤器,19xx年由Bloom中提出。它可以用于检索一个元素是否在一个集合中。
Bloom Filter(BF)是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。它是一个判断元素是否存在集合的快速的概率算法。Bloom Filter有可能会出现错误判断,但不会漏掉判断。也就是Bloom Filter判断元素不再集合,那肯定不在。如果判断元素存在集合中,有一定的概率判断错误。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter比其他常见的算法(如hash,折半查找)极大节省了空间。 它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。 Bloom Filter的详细介绍:Bloom Filter
2、 Bloom-Filter的基本思想 Bloom-Filter算法的核心思想就是利用多个不同的Hash函数来解决“冲突”

。
计算某元素x是否在一个集合中,首先能想到的方法就是将所有的已知元素保存起来构成一个集合R,然后用元素x跟这些R中的元素一一比较来判断是否存在于集合R中;我们可以采用链表等数据结构来实现。但是,随着集合R中元素的增加,其占用的内存将越来越大。试想,如果有几千万个不同网页需要下载,所需的内存将足以占用掉整个进程的内存地址空间。即使用MD5,UUID这些方法将URL转成固定的短小的字符串,内存占用也是相当巨大的。
于是,我们会想到用Hash table的数据结构,运用一个足够好的Hash函数将一个URL映射到二进制位数组(位图数组)中的某一位。如果该位已经被置为1,那么表示该URL已经存在。
Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便是Bloom-Filter的基本思想。
原理要点:一是位数组, 而是k个独立hash函数。
1)位数组:
假设Bloom Filter使用一个m比特的数组来保存信息,初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0,即BF整个数组的元素都设置为0。
2)添加元素,k个独立hash函数
为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。
当我们往Bloom Filter中增加任意一个元素x时候,我们使用k个哈希函数得到k个哈希值,然后将数组中对应的比特位设置为1。即第i个哈希函数映射的位置hashi(x)就会被置为1(1≤i≤k)。
注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位,即第二个“1“处)。

3)判断元素是否存在集合

在判断y是否属于这个集合时,我们只需要对y使用k个哈希函数得到k个哈希值,如果所有hashi(y)的位置都是1(1≤i≤k),即k个位置都被设置为1了,那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素(因为y1有一处指向了“0”位)。y2或者属于这个集合,或者刚好是一个false positive。
显然这 个判断并不保证查找的结果是100%正确的。
Bloom Filter的缺点:
1)Bloom Filter无法从Bloom Filter集合中删除一个元素。因为该元素对应的位会牵动到其他的元素。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。 此外,Bloom Filter的hash函数选择会影响算法的效果。
2)还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数个数,即hash函数选择会影响算法的效果。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况 下,m至少要等于n*lg(1/E) 才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应 该>=nlg(1/E)*lge ,大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意:
这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。
一般BF可以与一些key-value的数据库一起使用,来加快查询。由于BF所用的空间非常小,所有BF可以常驻内存。这样子的话,对于大部分不存在的元素,我们只需要访问内存中的BF就可以判断出来了,只有一小部分,我们需要访问在硬盘上的key-value数据库。从而大大地提高了效率。
一个Bloom Filter有以下参数:

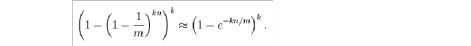
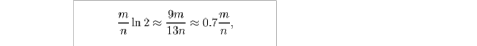

Bloom Filter的f满足下列公式:
在给定m和n时,能够使f最小化的k值为:
此时给出的f为:
根据以上公式,对于任意给定的f,我们有:
n = m ln(0.6185) / ln(f) [1]
同时,我们需要k个hash来达成这个目标:
k = - ln(f) / ln(2) [2]
由于k必须取整数,我们在Bloom Filter的程序实现中,还应该使用上面的公式来求得实际的f:
f = (1 – e
以上3个公式是程序实现Bloom Filter的关键公式。
-kn/mk)

[3]
CounterBloom Filter
BloomFilter有个缺点,就是不支持删除操作,因为它不知道某一个位从属于哪些向量。那我们可以给Bloom Filter加上计数器,添加时增加计数器,删除时减少计数器。
但这样的Filter需要考虑附加的计数器大小,假如同个元素多次插入的话,计数器位数较少的情况下,就会出现溢出问题。如果对计数器设置上限值的话,会导致Cache Miss,但对某些应用来说,这并不是什么问题,如Web Sharing。
Compressed Bloom Filter 为了能在服务器之间更快地通过网络传输Bloom Filter,我们有方法能在已完成Bloom Filter之后,得到一些实际参数的情况下进行压缩。
将元素全部添加入Bloom Filter后,我们能得到真实的空间使用率,用这个值代入公式计算出一个比m小的值,重新构造Bloom Filter,对原先的哈希值进行求余处理,在误判率不变的情况下,使得其内存大小更合适。
4、 Bloom-Filter的应用
Bloom-Filter一般用于在大数据量的集合中判定某元素是否存在。例如邮件服务器中的垃圾邮件过滤器。在搜索引擎领域,Bloom-Filter最常用于网络蜘蛛(Spider)的URL过滤,网络蜘蛛通常有一个URL列表,保存着将要下载和已经下载的网页的URL,网络蜘蛛下载了一个网页,从网页中提取到新的URL后,需要判断该URL是否已经存在于列表中。此时,Bloom-Filter算法是最好的选择。
1.key-value 加快查询
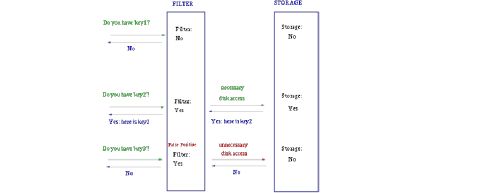
一般Bloom-Filter可以与一些key-value的数据库一起使用,来加快查询。
一般key-value存储系统的values存在硬盘,查询就是件费时的事。将Storage的数据都插入Filter,在Filter中查询都不存在时,那就不需要去Storage查询了。当False Position出现时,只是会导致一次多余的Storage查询。
由于Bloom-Filter所用的空间非常小,所有BF可以常驻内存。这样子的话,对于大部分不存在的元素,我们只需要访问内存中的Bloom-Filter就可以判断出来了,只有一小部分,我们需要访问在硬盘上的key-value数据库。从而大大地提高了效率。如图:
2 .Google的BigTable
Google的BigTable也使用了Bloom Filter,以减少不存在的行或列在磁盘上的查询,大大提高了数据库的查询操作的性能。
3. Proxy-Cache
在Internet Cache Protocol中的Proxy-Cache很多都是使用Bloom Filter存储URLs,除了高效的查询外,还能很方便得传输交换Cache信息。
4.网络应用
1)P2P网络中查找资源操作,可以对每条网络通路保存Bloom Filter,当命中时,则选择该通路访问。 2)广播消息时,可以检测某个IP是否已发包。
3)检测广播消息包的环路,将Bloom Filter保存在包里,每个节点将自己添加入Bloom Filter。
4)信息队列管理,使用Counter Bloom Filter管理信息流量。
5. 垃圾邮件地址过滤
像网易,QQ这样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。
一个办法就是记录下那些发垃圾邮件的 email地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。
如果用哈希表,每存储一亿个 email地址,就需要 1.6GB的内存(用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB的内存。
而Bloom Filter只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。
BloomFilter决不会漏掉任何一个在黑名单中的可疑地址。而至于误判问题,常见的补救办法是在建立一个小的白名单,存储那些可能别误判的邮件地址。
5、 Bloom-Filter的具体实现
c语言实现:
stdafx.h:
1.
2.
3.
4.
5.
6. #pragma once #include <stdio.h> #include "stdlib.h" #include <iostream> #include <time.h> using namespace std;
1.
2.
3.
4.
5.
6.
7.
8.
9. #include "stdafx.h" #define ARRAY_SIZE 256 /*we get the 256 chars of each line*/ #define SIZE 48000000 /* size should be 1/8 of max*/ #define MAX 384000000/*the max bit space*/ #define SETBIT(ch,n) ch[n/8]|=1<<(7-n%8) #define GETBIT(ch,n) (ch[n/8]&1<<(7-n%8))>>(7-n%8)
10.
11. unsigned int len(char *ch);/* functions to calculate the length of the url*/
12.
13. unsigned int RSHash(char* str, unsigned int len);/* functions to calculate the hash value of the url
*/
14. unsigned int JSHash(char* str, unsigned int len);/* functions to calculate the hash value of the url
*/
15. unsigned int PJWHash(char* str, unsigned int len);/* functions to calculate the hash value of the ur
l*/
16. unsigned int ELFHash(char* str, unsigned int len);/* functions to calculate the hash value of the ur
l*/
17. unsigned int BKDRHash(char* str, unsigned int len);/* functions to calculate the hash value of the u
rl*/
18. unsigned int SDBMHash(char* str, unsigned int len);/* functions to calculate the hash value of the u
rl*/
19. unsigned int DJBHash(char* str, unsigned int len);/* functions to calculate the hash value of the ur
l*/
20. unsigned int DEKHash(char* str, unsigned int len);/* functions to calculate the hash value of the ur
l*/
21. unsigned int BPHash(char* str, unsigned int len);/* functions to calculate the hash value of the url
*/
22. unsigned int FNVHash(char* str, unsigned int len);/* functions to calculate the hash value of the ur
l*/
23. unsigned int APHash(char* str, unsigned int len);/* functions to calculate the hash value of the url
*/
24. unsigned int HFLPHash(char* str,unsigned int len);/* functions to calculate the hash value of the ur
l*/
25. unsigned int HFHash(char* str,unsigned int len);/* functions to calculate the hash value of the url*
/
26. unsigned int StrHash( char* str,unsigned int len);/* functions to calculate the hash value of the ur
l*/
27. unsigned int TianlHash(char* str,unsigned int len);/* functions to calculate the hash value of the u
rl*/
28.
29.
30. int main()
31. {
32. int i,num,num2=0; /* the number to record the repeated urls and the total of it*/
33. unsigned int tt=0;
34. int flag; /*it helps to check weather the url has already existed */
35. char buf[257]; /*it helps to print the start time of the program */
36. time_t tmp = time(NULL);
37.
38. char file1[100],file2[100];
39. FILE *fp1,*fp2;/*pointer to the file */
40. char ch[ARRAY_SIZE];
41. char *vector ;/* the bit space*/
42. vector = (char *)calloc(SIZE,sizeof(char));
43.
44. printf("Please enter the file with repeated urls:\n");
45. scanf("%s",&file1);
46. if( (fp1 = fopen(file1,"rb")) == NULL) { /* open the goal file*/
47. printf("Connot open the file %s!\n",file1);
48. }
49.
50. printf("Please enter the file you want to save to:\n");
51. scanf("%s",&file2);
52. if( (fp2 = fopen(file2,"w")) == NULL) {
53. printf("Connot open the file %s\n",file2);
54. }
55. strftime(buf,32,"%Y-%m-%d %H:%M:%S",localtime(&tmp));
56. printf("%s\n",buf); /*print the system time*/
57.
58. for(i=0;i<SIZE;i++) {
59. vector[i]=0; /*set 0*/
60. }
61.
62. while(!feof(fp1)) { /* the check process*/
63.
64. fgets(ch,ARRAY_SIZE,fp1);
65. flag=0;
66. tt++;
67. if( GETBIT(vector, HFLPHash(ch,len(ch))%MAX) ) {
68. flag++;
69. } else {
70. SETBIT(vector,HFLPHash(ch,len(ch))%MAX );
71. }
72.
73. if( GETBIT(vector, StrHash(ch,len(ch))%MAX) ) {
74. flag++;
75. } else {
76. SETBIT(vector,StrHash(ch,len(ch))%MAX );
77. }
78.
79. if( GETBIT(vector, HFHash(ch,len(ch))%MAX) ) {
80. flag++;
81. } else {
82. SETBIT(vector,HFHash(ch,len(ch))%MAX );
83. }
84.
85. if( GETBIT(vector, DEKHash(ch,len(ch))%MAX) ) {
86. flag++;
87. } else {
88. SETBIT(vector,DEKHash(ch,len(ch))%MAX );
89. }
90.
91. if( GETBIT(vector, TianlHash(ch,len(ch))%MAX) ) {
92. flag++;
93. } else {
94. SETBIT(vector,TianlHash(ch,len(ch))%MAX );
95. }
96.
97. if( GETBIT(vector, SDBMHash(ch,len(ch))%MAX) ) {
98. flag++;
99. } else {
100. SETBIT(vector,SDBMHash(ch,len(ch))%MAX ); 101. }
102.
103. if(flag<6)
104. num2++;
105. else
106. fputs(ch,fp2);
107.
108. /* printf(" %d",flag); */
109. }
110. /* the result*/
111. printf("\nThere are %d urls!\n",tt);
112. printf("\nThere are %d not repeated urls!\n",num2); 113. printf("There are %d repeated urls!\n",tt-num2); 114. fclose(fp1);
115. fclose(fp2);
116. return 0;
117. }
118.
119.
120. /*functions may be used in the main */
121. unsigned int len(char *ch)
122. {
123. int m=0;
124. while(ch[m]!='\0') {
125. m++;
126. }
127. return m;
128. }
129.
130. unsigned int RSHash(char* str, unsigned int len) {
131. unsigned int b = 378551;
132. unsigned int a = 63689;
133. unsigned int hash = 0;
134. unsigned int i = 0;
135.
136. for(i=0; i<len; str++, i++) {
137. hash = hash*a + (*str);
138. a = a*b;
139. }
140. return hash;
141. }
142. /* End Of RS Hash Function */
143.
144.
145. unsigned int JSHash(char* str, unsigned int len)
146. {
147. unsigned int hash = 1315423911;
148. unsigned int i = 0;
149.
150. for(i=0; i<len; str++, i++) {
151. hash ^= ((hash<<5) + (*str) + (hash>>2));
152. }
153. return hash;
154. }
155. /* End Of JS Hash Function */
156.
157.
158. unsigned int PJWHash(char* str, unsigned int len)
159. {
160. const unsigned int BitsInUnsignedInt = (unsigned int)(sizeof(unsigned int) * 8); 161. const unsigned int ThreeQuarters = (unsigned int)((BitsInUnsignedInt * 3) / 4);
162. const unsigned int OneEighth = (unsigned int)(BitsInUnsignedInt / 8);
163. const unsigned int HighBits = (unsigned int)(0xFFFFFFFF) << (BitsInUnsignedInt - OneEighth); 164. unsigned int hash = 0;
165. unsigned int test = 0;
166. unsigned int i = 0;
167.
168. for(i=0;i<len; str++, i++) {
169. hash = (hash<<OneEighth) + (*str);
170. if((test = hash & HighBits) != 0) {
171. hash = ((hash ^(test >> ThreeQuarters)) & (~HighBits));
172. }
173. }
174.
175. return hash;
176. }
177. /* End Of P. J. Weinberger Hash Function */
178.
179.
180. unsigned int ELFHash(char* str, unsigned int len)
181. {
182. unsigned int hash = 0;
183. unsigned int x = 0;
184. unsigned int i = 0;
185.
186. for(i = 0; i < len; str++, i++) {
187. hash = (hash << 4) + (*str);
188. if((x = hash & 0xF0000000L) != 0) {
189. hash ^= (x >> 24);
190. }
191. hash &= ~x;
192. }
193. return hash;
194. }
195. /* End Of ELF Hash Function */
196.
197.
198. unsigned int BKDRHash(char* str, unsigned int len)
199. {
200. unsigned int seed = 131; /* 31 131 1313 13131 131313 etc.. */
201. unsigned int hash = 0;
202. unsigned int i = 0;
203.
204. for(i = 0; i < len; str++, i++)
205. {
206. hash = (hash * seed) + (*str);
207. }
208.
209. return hash;
210. }
211. /* End Of BKDR Hash Function */
212.
213.
214. unsigned int SDBMHash(char* str, unsigned int len) 215. {
216. unsigned int hash = 0;
217. unsigned int i = 0;
218.
219. for(i = 0; i < len; str++, i++) {
220. hash = (*str) + (hash << 6) + (hash << 16) - hash; 221. }
222.
223. return hash;
224. }
225. /* End Of SDBM Hash Function */
226.
227.
228. unsigned int DJBHash(char* str, unsigned int len) 229. {
230. unsigned int hash = 5381;
231. unsigned int i = 0;
232.
233. for(i = 0; i < len; str++, i++) {
234. hash = ((hash << 5) + hash) + (*str);
235. }
236.
237. return hash;
238. }
239. /* End Of DJB Hash Function */
240.
241.
242. unsigned int DEKHash(char* str, unsigned int len) 243. {
244. unsigned int hash = len;
245. unsigned int i = 0;
246.
247. for(i = 0; i < len; str++, i++) {
248. hash = ((hash << 5) ^ (hash >> 27)) ^ (*str); 249. }
250. return hash;
251. }
252. /* End Of DEK Hash Function */
253.
254.
255. unsigned int BPHash(char* str, unsigned int len)
256. {
257. unsigned int hash = 0;
258. unsigned int i = 0;
259. for(i = 0; i < len; str++, i++) {
260. hash = hash << 7 ^ (*str);
261. }
262.
263. return hash;
264. }
265. /* End Of BP Hash Function */
266.
267.
268. unsigned int FNVHash(char* str, unsigned int len)
269. {
270. const unsigned int fnv_prime = 0x811C9DC5;
271. unsigned int hash = 0;
272. unsigned int i = 0;
273.
274. for(i = 0; i < len; str++, i++) {
275. hash *= fnv_prime;
276. hash ^= (*str);
277. }
278.
279. return hash;
280. }
281. /* End Of FNV Hash Function */
282.
283.
284. unsigned int APHash(char* str, unsigned int len)
285. {
286. unsigned int hash = 0xAAAAAAAA;
287. unsigned int i = 0;
288.
289. for(i = 0; i < len; str++, i++) {
290. hash ^= ((i & 1) == 0) ? ( (hash << 7) ^ (*str) * (hash >> 3)) : 291. (~((hash << 11) + (*str) ^ (hash >> 5))); 292. }
293.
294. return hash;
295. }
296. /* End Of AP Hash Function */
297. unsigned int HFLPHash(char *str,unsigned int len) 298. {
299. unsigned int n=0;
300. int i;
301. char* b=(char *)&n;
302. for(i=0;i<strlen(str);++i) {
303. b[i%4]^=str[i];
304. }
305. return n%len;
306. }
307. /* End Of HFLP Hash Function*/
308. unsigned int HFHash(char* str,unsigned int len) 309. {
310. int result=0;
311. char* ptr=str;
312. int c;
313. int i=0;
314. for (i=1;c=*ptr++;i++)
315. result += c*3*i;
316. if (result<0)
317. result = -result;
318. return result%len;
319. }
320. /*End Of HKHash Function */
321.
322. unsigned int StrHash( char *str,unsigned int len) 323. {
324. register unsigned int h;
325. register unsigned char *p;
326. for(h=0,p=(unsigned char *)str;*p;p++) { 327. h=31*h+*p;
328. }
329.
330. return h;
331.
332. }
333. /*End Of StrHash Function*/
334.
335. unsigned int TianlHash(char *str,unsigned int len) 336. {
337. unsigned long urlHashValue=0;
338. int ilength=strlen(str);
339. int i;
340. unsigned char ucChar;
341. if(!ilength) {
342. return 0;
343. }
344. if(ilength<=256) {
345. urlHashValue=16777216*(ilength-1);
346. } else {
347. urlHashValue = 42781900080;
348. }
349. if(ilength<=96) {
350. for(i=1;i<=ilength;i++) {
351. ucChar=str[i-1];
352. if(ucChar<='Z'&&ucChar>='A') {
353. ucChar=ucChar+32;
354. }
355. urlHashValue+=(3*i*ucChar*ucChar+5*i*ucChar+7*i+11*ucChar)%1677216; 356. }
357. } else {
358. for(i=1;i<=96;i++)
359. {
360. ucChar=str[i+ilength-96-1];
361. if(ucChar<='Z'&&ucChar>='A')
362. {
363. ucChar=ucChar+32;
364. }
365. urlHashValue+=(3*i*ucChar*ucChar+5*i*ucChar+7*i+11*ucChar)%1677216; 366. }
367. }
368. return urlHashValue;
369.
370. }
371. /*End Of Tianl Hash Function*/
网上找到的php简单实现:
1.
2.
3.
4.
5.
6. <?php /** * Implements a Bloom Filter */ class BloomFilter {
7.
8.
9. /** * Size of the bit array *
10. * @var int
11. */
12. protected $m;
13.
14. /**
15. * Number of hash functions
16. *
17. * @var int
18. */
19. protected $k;
20.
21. /**
22. * Number of elements in the filter
23. *
24. * @var int
25. */
26. protected $n;
27.
28. /**
29. * The bitset holding the filter information
30. *
31. * @var array
32. */
33. protected $bitset;
34.
35. /**
36. * 计算最优的hash函数个数:当hash函数个数k=(ln2)*(m/n)时错误率最小
37. *
38. * @param int $m bit数组的宽度(bit数)
39. * @param int $n 加入布隆过滤器的key的数量
40. * @return int
41. */
42. public static function getHashCount($m, $n) {
43. return ceil(($m / $n) * log(2));
44. }
45.
46. /**
47. * Construct an instance of the Bloom filter
48. *
49. * @param int $m bit数组的宽度(bit数) Size of the bit array
50. * @param int $k hash函数的个数 Number of different hash functions to use
51. */
52. public function __construct($m, $k) {
53. $this->m = $m;
54. $this->k = $k;
55. $this->n = 0;
56.
57. /* Initialize the bit set */
58. $this->bitset = array_fill(0, $this->m - 1, false);
59. }
60.
61. /**
62. * False Positive的比率:f = (1 – e-kn/m)k
63. * Returns the probability for a false positive to occur, given the current number of items in t
he filter
64. *
65. * @return double
66. */
67. public function getFalsePositiveProbability() {
68. $exp = (-1 * $this->k * $this->n) / $this->m;
69.
70. return pow(1 - exp($exp), $this->k);
71. }
72.
73. /**
74. * Adds a new item to the filter
75. *
76. * @param mixed Either a string holding a single item or an array of
77. * string holding multiple items. In the latter case, all
78. * items are added one by one internally.
79. */
80. public function add($key) {
81. if (is_array($key)) {
82. foreach ($key as $k) {
83. $this->add($k);
84. }
85. return;
86. }
87.
88. $this->n++;
89.
90. foreach ($this->getSlots($key) as $slot) {
91. $this->bitset[$slot] = true;
92. }
93. }
94.
95. /**
96. * Queries the Bloom filter for an element
97. *
98. * If this method return FALSE, it is 100% certain that the element has
99. * not been added to the filter before. In contrast, if TRUE is returned,
100. * the element *may* have been added to the filter previously. However with
101. * a probability indicated by getFalsePositiveProbability() the element has
102. * not been added to the filter with contains() still returning TRUE.
103. *
104. * @param mixed Either a string holding a single item or an array of
105. * strings holding multiple items. In the latter case the
106. * method returns TRUE if the filter contains all items.
107. * @return boolean
108. */
109. public function contains($key) {
110. if (is_array($key)) {
111. foreach ($key as $k) {
112. if ($this->contains($k) == false) {
113. return false;
114. }
115. }
116.
117. return true;
118. }
119.
120. foreach ($this->getSlots($key) as $slot) {
121. if ($this->bitset[$slot] == false) {
122. return false;
123. }
124. }
125.
126. return true;
127. }
128.
129. /**
130. * Hashes the argument to a number of positions in the bit set and returns the positions 131. *
132. * @param string Item
133. * @return array Positions
134. */
135. protected function getSlots($key) {
136. $slots = array();
137. $hash = self::getHashCode($key);
138. mt_srand($hash);
139.
140. for ($i = 0; $i < $this->k; $i++) {
141. $slots[] = mt_rand(0, $this->m - 1);
142. }
143.
144. return $slots;
145. }
146.
147. /**
148. * 使用CRC32产生一个32bit(位)的校验值。
149. * 由于CRC32产生校验值时源数据块的每一bit(位)都会被计算,所以数据块中即使只有一位发生了变化,也会得到
不同的CRC32值。
150. * Generates a numeric hash for the given string
151. *
152. * Right now the CRC-32 algorithm is used. Alternatively one could e.g.
153. * use Adler digests or mimick the behaviour of Java's hashCode() method.
154. *
155. * @param string Input for which the hash should be created
156. * @return int Numeric hash
157. */
158. protected static function getHashCode($string) {
159. return crc32($string);
160. }
161.
162. }
163.
164.
165.
166. $items = array("first item", "second item", "third item");
167.
168. /* Add all items with one call to add() and make sure contains() finds
169. * them all.
170. */
171. $filter = new BloomFilter(100, BloomFilter::getHashCount(100, 3));
172. $filter->add($items);
173.
174. //var_dump($filter); exit;
175. $items = array("firsttem", "seconditem", "thirditem");
176. foreach ($items as $item) {
177. var_dump(($filter->contains($item)));
178. }
179.
180.
181. /* Add all items with multiple calls to add() and make sure contains()
182. * finds them all.
183. */
184. $filter = new BloomFilter(100, BloomFilter::getHashCount(100, 3));
185. foreach ($items as $item) {
186. $filter->add($item);
187. }
188. $items = array("fir sttem", "secondit em", "thir ditem");
189. foreach ($items as $item) {
190. var_dump(($filter->contains($item))); 191. }
192.
193.
194.
195.
问题实例】 给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿bit,n=50亿,如果按出错率0.01算需要的大概是650亿个bit。 现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些urlip是一一对应的,就可以转换成ip,则大大简单了。