课 程 学 习 总 结


共 页 第 页

第二篇:数据结构——课程总结new
课程总结(提要)
一、 数据结构和抽象数据类型ADT
定义:一个数学模型以及定义在该模型上的一组操作。
构成一个抽象数据类型的三个要素是:
 数据对象、数据关系、基本操作
数据对象、数据关系、基本操作
数据结构(非数值计算程序设计问题中的数学模型)
 ·逻辑结构(描述数据元素之间的关系)
·逻辑结构(描述数据元素之间的关系)
线性结构—— 线性表、栈、队列、串、数组、广义表
非线性结构 —— 树和森林、二叉树、图
集合结构 —— 查找表、文件
·存储结构 (逻辑结构在存储器中的映象)
(逻辑结构在存储器中的映象)
按“关系”的表示方法不同而分:
 顺序结构—以数据元素在存储器中的一个固定的相对位置来表示“关系”
顺序结构—以数据元素在存储器中的一个固定的相对位置来表示“关系”
链式结构—以指针表示数据元素的“后继”或“前驱”
·基本操作(三类)
结构的建立和销毁
查找——引用型操作(不改变元素间的关系)
 按“关系”进行检索
按“关系”进行检索
按给定值进行检索
遍历——访问结构中的每一个数据元素,且对每个元素只访问一次
修改 —— 加工型操作(改变元素间的关系)
 插入
插入
删除
更新(删除+插入)
二、线性结构
·线性表和有序表
—— 不同存储结构的比较
顺序表:可以实现随机存取;O(1)
插入和删除时需要移动元素;O(n)
需要预分配存储空间;
适用于“不常进行修改操作、表中元素相对稳定”的场合。
链表:只能进行顺序存取;O(n)
插入和删除时只需修改指针; O(1)
不需要预分配存储空间;
适用于“修改操作频繁、事先无法估计最大表长”的场合。
—— 应用问题的算法时间复杂度的比较
例如,以线性表表示集合进行运算的时间复杂度为O(n2),
而以有序表表示集合进行运算的时间复杂度为O(n)
·栈和队列——数据类型的特点及其应用范畴
·串——和线性表的差异:
数据对象不同(数据元素限定为单个字符)、基本操作集不同(串整体作为操作对象)、存储结构不同
¾¾ 串的模式匹配算法
·数组——只有引用型的操作,∴只需要顺序存储结构
多维到一维的不同映象方法:
 以行序为主序(低下标优先)
以行序为主序(低下标优先)
以列序为主序(高下标优先)
三、非线性结构
¾¾ 树和森林、二叉树、图
· 数据类型的定义(结构特点和基本操作)
· 存储结构
· 二叉树的特性及其证明方法
· 遍历
·何谓“遍历”?对结构中的每个元素都访问到,且只被访问一次
·对非线性结构的遍历需要确定一条搜索路径
·两条搜索路径:深度优先搜索和广度优先搜索
·逻辑定义
深度优先搜索—— 以结构中的某个数据元素为起始点,首先访问该数据元素,然后依次以它的各个“后继”为起始点进行“深度优先搜索遍历”。
其特点为:在访问了起始数据元素之后,沿着某一条“路径”(后继)向前,直至“到底”,然后退回一步找另一个后继,再向前继续,……,直至所有通路都走遍。
广度优先搜索——以结构中的某个数据元素为起始点,首先访问该数据元素,然后先访问其所有后继;之后其它结点的访问次序由已被访问的结点的访问次序决定:先被访问的结点的后继“优先于”后被访问的结点的后继。
其特点为:在访问了起始数据元素之后,先访问它的所有后继,然后再依这些后继被访问的先后次序访问它们的后继,……,直至没有后继未被访问为止。
·算法的形式描述
深度优先搜索——通常采用递归的形式
二叉树(先序、中序、后序)、树/图(先根、后根)
一般形式算法的描述:
void DFSearch(ADT DS, ElemType v)
{ // 从v开始,对DS进行深度优先搜索遍历
if (DS) {
visit(v); (visited[v]=true;)
w=FirstSucc(v);
while (w) {
if (!visited[v]) DFSearch(DS, w);
w=NextSucc(DS, v, w);
}//while
}//if
}//DFSearch
不同数据结构(逻辑和存储)有不同写法。
例如对森林,起始点只有一个(第一棵树的根),只有两个后继,且各棵树互不相交,按搜索路径上的访问次序有先序遍历和中序遍历之分。
void PreOrder_F(CSTree T) {
// 对以T为根指针的森林进行先序遍历
if (T) {
visit(T->data);
PreOrder_F( T->firstchild ); // 先序遍历第一棵树的子树森林
PreOrder_F( T->nextsibling ); // 先序遍历其余树构成的森林
}//if
} // PreOrder_F
或者从森林是树的集合角度来看遍历(依次从左至右依次先根遍历各棵子树) while(树) do PreOrder_T(树);
void PreOrder_T(CSTree T) {
// 对以T为根指针的树进行先根遍历
if (T) {
visit(T->data); p=T->firstchild;
while(p) {
PreOrder_T(p);
// 对以 p 为根指针的子树进行先根遍历
p=p->next;
}//while
} // PreOrder_T
·由“访问”操作的不同可以实现不同的操作
具体问题具体分析,按分割求解的思想:
“递归基”考虑最简单的结构(“空集”/“只含一个元素”)
“归纳项”分析原问题和子问题之间的关系
·不同的问题要求不同的搜索路径
·“线索化”的过程即为在遍历过程中建立结点之间的线性关系
广度优先搜索——不能用递归(先进先出)
必须利用“队列”记下访问次序,以便由此确定以后的元素的访问次序
·对不同的存储结构,算法的差异
不同的存储结构表现在表示“后继”的方法不同
二叉树 —— 二叉链表(静态、动态)、顺序表(只适用于完全二叉树)
树 —— 孩子-兄弟链表、孩子链表(≡≡图的邻接表)、双亲链表
图 —— 邻接表、邻接矩阵
具体算法采用何种存储结构由算法需要解决的问题而定
四、查找表—— 集合结构
·根据查找表所需进行的操作种类和期望达到的ASL来选择构造查找表的方法
顺序表、有序表(静态查找树)、索引顺序表 —— 静态查找表
二叉排序树、B-树和B+树、键树 —— 查找树
哈希表 —— 动态查找表也可用于表示静态查找表
各自的特点、操作的实现方法,注意 它们之间的相同点和不同点
例如:顺序表的特点是:结构简单,便于插入但不便于删除;平均查找长度较大ASL=O(n),查找树?哈希表?
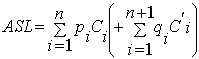 —— 平均查找长度的计算公式对任何查找表都适用
—— 平均查找长度的计算公式对任何查找表都适用
一般情况下只考虑查找成功的平均查找长度,即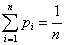 ,关键在于如何计算Ci
,关键在于如何计算Ci
·判定树和ASL的计算方法
——判定树用于描述查找方法,关键字在判定树上的层次恰为找到它时和给定值进行比较的次数。注意判定树的画法取决于查找方法的本身而不是具体的算法。
判定树非程序流图
·哈希表的特点
是在关键字和记录的存储地址之间建立了一个映象关系,以此减少查找的盲目性,哈希表的最大特点是它的平均查找长度不是表长的函数,因此利用它可以设计出使平均查找长度控制在期望值范围内的查找表。
——如何构造哈希表以及如何计算它的Ci。
——在特殊的情况下,可以做到ASL=0
—— 无法画出它的判定树
—— 掌握各种构造哈希表的方法以及处理冲突的方法
五、内部排序
·进行排序的目的:得到有序表
排序和查找相互关联,有时排序的过程也可以看成是一个动态造表的过程,如:插入排序;二叉查找树
·了解各种排序方法的特点以便灵活应用
例如:直接插入排序适用于“近似有序序列”;
快排的思想可用以“调整”;
选择排序、起泡排序和堆排序可用以“选出若干满足条件元素”;
各种排序方法的混合使用
·排序算法的描述
例如:一次划分、建堆
算法和存储结构的关系
·排序算法的时间复杂度及其简单分析方法
·各种排序方法的综合比较
时间性能——平均情况、最坏情况、最好情况
(从关键字的比较和记录的移动两个方面进行分析)
空间性能——需要的辅助空间
八、图
¾¾各种存储结构的定义、各个应用问题算法的执行过程
九、算法时间复杂度的分析
掌握系统分析的方法。