北京理工大学珠海学院《统计分析与SPSS的应用》报告
人均地区生产总值及人均消费水平报告
学 院:商学院 年 级: 09级2班
专 业:公管事业管理 第3小组成员魏晗090804021048


1/ 11
北京理工大学珠海学院《统计分析与SPSS的应用》报告
2/ 11
北京理工大学珠海学院《统计分析与SPSS的应用》报告
目 录
1.人均GDP与人均消费.......................................................3
2.我国居民消费情况.........................................................3
3.我国人均GDP…………………………………………………………………………………3
4.人均GDP与人均消费统计分析………………………………………………………………4
5数据分析...................................................................6
6.结论及建议……………………………………………………………………………………9
7.参考文献………………………………………………………………………………………10
3/ 11
北京理工大学珠海学院《统计分析与SPSS的应用》报告
一.人均GDP与人均消费
由于消费是所有经济行为有效实现的最终环节,唯有消费需求的不断上升才有经济增长的持久拉动力,而居民的消费水平在很大程度上又受整体经济状况的影响。国内生产总值是用于衡量一国总收入的一种整体经济指标,经济扩张时期,居民收入稳定,GDP也高,居民用于消费的支出较多,消费水平较高;反正,经济收缩时,收入下降,GDP也低,用于消费的支出较少,消费水平随之下降。改革开放以来,国家的GDP不断增长的同时,人民的物质生活也在不断提高。本报告将对我国人均GDP与人均消费进行分析。
…… …… 余下全文


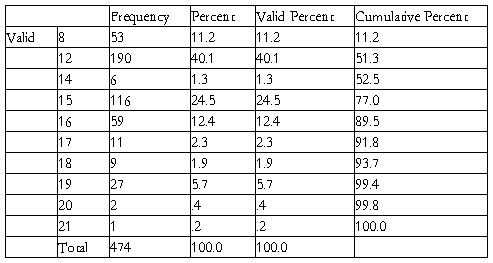
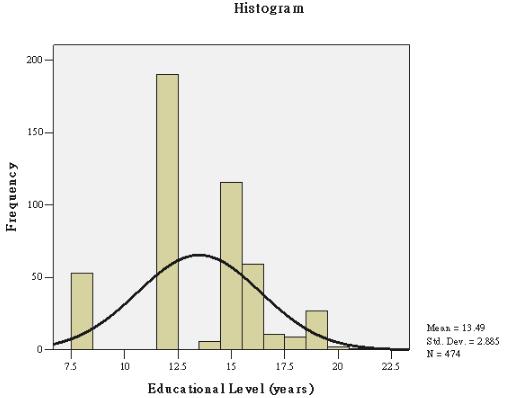
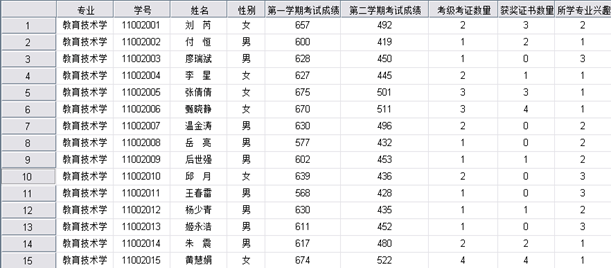




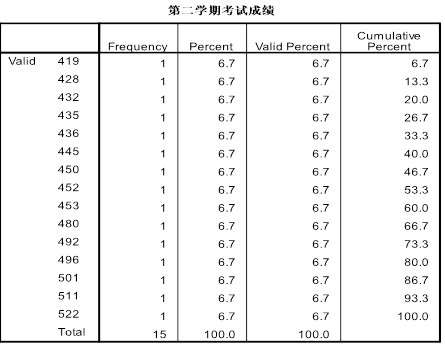
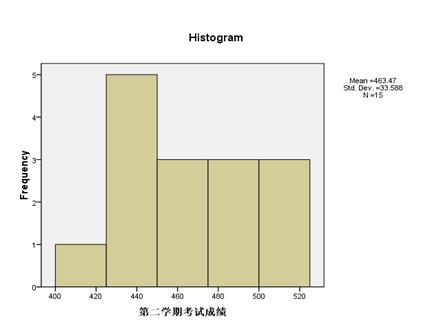
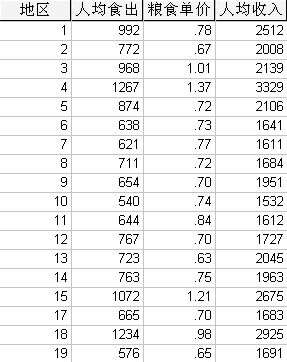
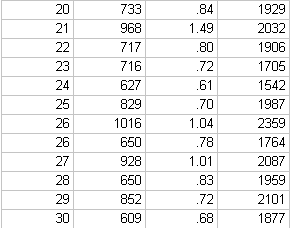

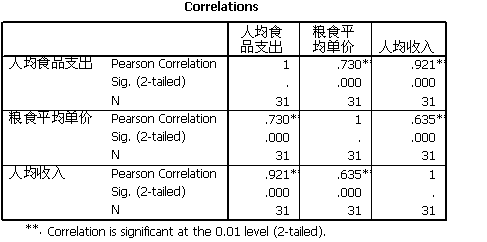
 b.在spssd的菜单栏中选择点击Analyze correlate Bivariate,
b.在spssd的菜单栏中选择点击Analyze correlate Bivariate,