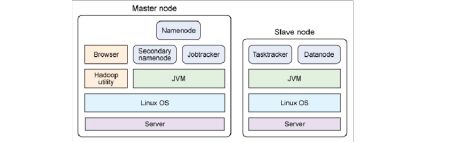
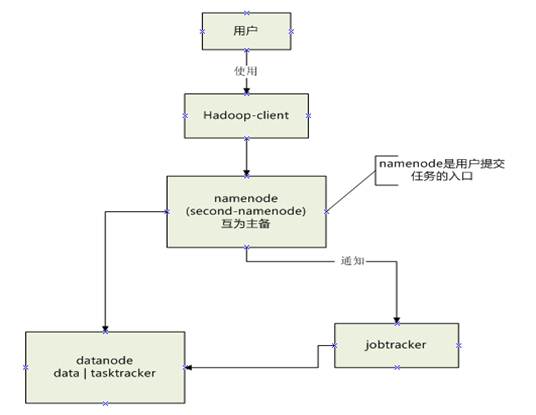
一、对hadoop的基本认识 Hadoop是一个分布式系统基础技术框架,由Apache基金会所开发。利用hadoop,软件开发用户可以在不了解分布式底层细节的情况下,开发分布式程序,从而达到充分利用集群的威力高速运算和存储的目的。
Hadoop是根据google的三大论文作为基础而研发的,google的三大论文分别是:MapReduce、GFS和BigTable。因此,hadoop也因此被称为是
google技术的山寨版。不过这种“山寨版”却成了当下大数据处理技术的国际标准(因为它是世界上唯一一个做得相对完善而又开源的框架)。
Hadoop框架中最核心的设计就是:MapReduce和HDFS。MapReduce的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释
MapReduce就是“任务的分解与结果的汇总”。HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。
MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。这不是什么新思想,其实它的本质就是一种“分治法”的思想,把一个巨大的任务分割成许许多多的小任务单元,最后再将每个小任务单元的结果汇总,并求得最终结果。在分布式系统中,机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率,同时这种资源无关性,对于计算集群的扩展无疑提供了最好的设计保证。任务分解处理以后,那就需要将处理以后的结果再汇总起来,这就是Reduce要做的工作。
多任务、并行计算、云计算,这些词汇并不是新名词,在hadoop出现之前,甚至在google出现之前,就已经出现过分布式系统和分布式程序,hadoop新就新在它解决了分布式系统复杂的底层细节,程序员可以在不了解底层分布式细节的情况下编写高效的分布式程序,hadoop服务会自动将任务分配给不同的计算机节点,由这些节点计算最后汇总并处理计算结果。利用hadoop,程序作者可以将精力放在具体的业务逻辑上,而不是繁琐的分布式底层技术细节。另外,传统的分布式系统一般会利用若干台高性能的计算机,而hadoop则只需将大量普通的pc机连系在一起,组成一个分布式集群。
…… …… 余下全文