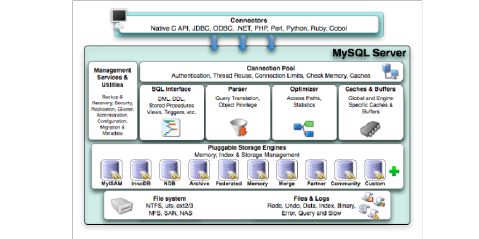
配置my.cnf/my.ini,增加 --log-slow-queries 配置,记录所有的slow query,然后挨个优化 本文来源于 WEB开发网 原文链接:.cn/mysql/3573.htm
select @a=DRClass1, @b=DRClass2, @c=DRClass3, @d=DRClass4, @e=DRClass5 from Teacher Where TeacherID = @TeacherID
create table classname(classname char(50))
insert into classname (classname) values (@a)
if (@b is not null)
begin
insert into classname (classname) values (@b)
if (@c is not null)
begin
insert into classname (classname) values (@c)
if (@d is not null)
begin
insert into classname (classname) values (@d)
if (@e is not null)
begin
insert into classname (classname) values (@e)
end
end
end
end
select * from classname
以上这些SQL语句能不能转成一个存储过程?我自己试了下
ALTER PROCEDURE Pr_GetClass
@TeacherID int,
@a char(50),
@b char(50),
@c char(50),
@d char(50),
@e char(50)
as
select @a=DRClass1, @b=DRClass2, @c=DRClass3, @d=DRClass4, @e=DRClass5 from Teacher Where TeacherID = @TeacherID
…… …… 余下全文