关于大学生上网情况的调查报告
调查过程
为了了解现代大学生的上网情况,本人策划并在全校针对大学生上网情况进行了调查。调查时间是从6月21号到6月25号。21号上午制定了调查方案, 21号下午将调查需要的表格进行打印,由于制作样本框需要了解有多少寝室,所以我到生活老师那对寝室进行了了解。最后制作出样本框并抽出了25个寝室进行调查。依照策划我22、23号分别对抽到的寝室进行了调查,并对资料进行了整理。24号回到教室对调查的资料涉及的数据进行了计算。25号写出本次调查的报告。
成果展示及分析
通过这次调查我了解了农校大一、大二在校大学的上网情况。并得到了一些相关数据。数据如下:
上网花费/月(元)(一)
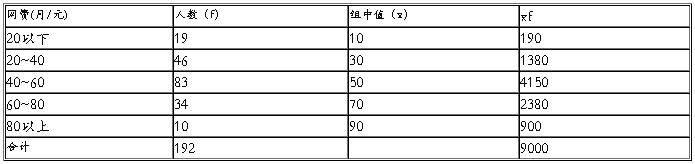
由以上数据可得:
平均数X=46.9 标准差=19.96 平均误差=1.44
极限误差=2.88 平均数区间44.02<X<49.78
每月生活费(二)
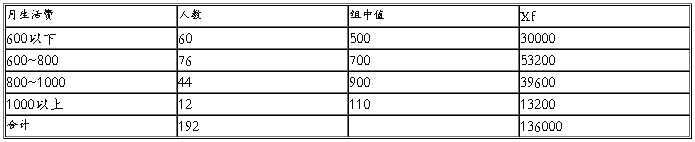
由以上数据可得:
平均数X=704 标准差=179 平均误差=12.88
极限误差=25.76 平均数区间678.24<X<729.76
结合表(一)(二)可以得知成都农业科技职业学院同学们的平均月生活费为704元,用上网的费用为46.9元.大约占生活费的1/15。在生活水平提高的同时同学们的消费情况也在发生着变化,网络的不断发展吸引了多数的人,尤其是学生们。他们愿意拿出生活费的一部分用于上网。网络对学生生活、学习的影响在日益增强。
每周上网次数(三)
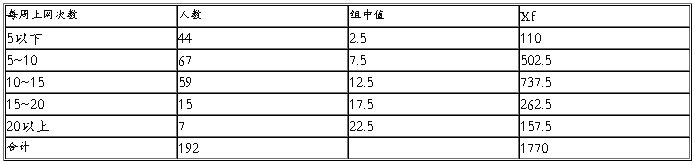
有以上数据可得:
平均数X=9.2 标准差=5.14 平均误差=0.37
极限误差=0.74平均数区间8.46<X<9.94
每次上网的时长(时/次)(四)
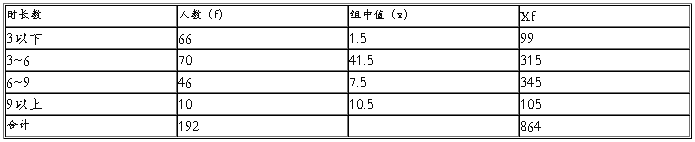
由以上数据可得:
平均数X=4.6 标准差=2.4 平均误差=0.173
极限误差=0.35 平均数区间4.31<X<5.01
结合表(三)(四)可以得知同学们每周上网的平均次数为9次,而且每次上网的平均时间为4.6个小时。在每周的学习生活中同学们已将很大一部分时间用于上网了,已经占了他们生活学习的一部分了。打正确的上网目的及时间安排是很重要的。网络的影响很大,所以我们更应该好好利用网络这个平台。合理的安排自己的时间,让网络在我们的生活学习中发挥更大的益处。
多久休息一次(时/次)(五)

由以上数据可得:
平均数X=2.5 标准差=1.1 平均误差=0.08
极限误差=0.16 平均数区间2.34<X<2.66
多久不上网会不适应(天)(六)

由以上数据可得:
平均数X=9.3标准差=4.4 平均误差=0.032
极限误差=0.64 平均数区间8.66<X<9.94
结合表(五)(六)可以得知同学们上网平均每隔2个半小时会休息一次,如果9天左右不上网会感觉到不适应。众所周知上网时间久了对人身体不好,电脑的辐射很大对皮肤和视力都极有影响。从数据也可以知道同学们对网络的依赖程度在加深,但对上网会带来的危害还是视若无睹。健康的身体是最重要的,在上网的同时请注意自己的身体健康。
网龄(年)(七)
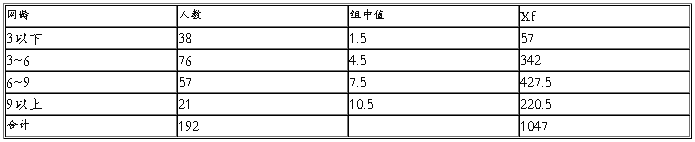
由以上数据可得:
平均数X=5.5标准差=2.07 平均误差=0.149
极限误差=0.298 平均数区间4.702<X<5.798
由表七可以知道大学生的平均网龄是5年半。同学们在还未成年的时候就开始上网了,大学生思想价值观、世界观还处于不成熟阶段,对外界诱惑和吸引力没有抵制能力,导致有部分大学生迷恋网上游戏,一味沉溺于电脑娱乐彻夜不眠,难以自拔。更有甚者整天沉溺于网上黄色、赌博、恐怖暴力等内容,参与网上犯罪,传播消极的网上文化。给其身心带来极大的危害。
网络的影响:
1、信息时代匆匆的步伐让大学生不能不使用和接受网络,不管它会带来多大的冲击,这种冲击中夹杂多少不良的成份.作为主宰新世纪的一代,大学生终归是离不开网络的.为什么同样是应用网络,大学生就不能挖掘出最实际的意义,而仅仅停留于娱乐和消遣?这恐怕就是一个认识和对待新事物的态度问题了.对于这样一种新事物,既不能视之如洪水猛兽,因为它会带来某些负面影响而因噎废食;也不能盲目的鼓吹它有这样的优点.作为大学生应该认识到沉溺于网上娱乐而不利用更多的精力关注网络上真正有价值的信息,通过网络接触社会提高辩识和思考的能力.
2、下面是从网上找到的一些资料:学生与IT从业者为网游主力,20年龄段玩家占60%,35岁以下的玩家占据网游玩家的95%,网游企业纷纷上市固然可喜,换来的却是一代中国人的心理缺失,作为方面没有人希望自己的孩子整天泡在游戏中,偏偏网游又是一个个喜欢难以自拔的娱乐方式,就象是清政府时代的鸦片,其实每个人都知道鸦片有害,照样趋之若骛,且不说沉溺于网络对眼睛尚未稳定的青少年有害处,长期的沉溺于网游也容易让人更加自以为是,如果说80后的标签是"自我",90后可能是"自以为是".
从中可以看出我们大学生已经严重沉迷于网络游戏,把网络作为了自己娱乐的最主要方式,无论是新闻.看电视.聊天游戏都依靠这网络.
大学生上网存在问题的原因
1.与有关部门对大学生上网关注引导不够有关
网络已经走进了当代大学生的生活,成为了大学生校园生活的一个重要部分。但学校的相关部门对大学生上网并不十分关注,不去正确引导大学生上网,不去教会学生鉴别网上事物的好坏,甚至有些老师和管理干部至今仍不会使用电脑,更不用说上网了,这样的老师和干部又怎能正确引导大学生对待上网呢¡
2.与大学生好奇心、好胜心强,精力旺盛及对网上污染抵制能力差有关
大学生思想价值观、世界观还处于不成熟阶段,对外界诱惑和吸引力没有抵制能力,导致有部分大学生迷恋网上游戏,一味沉溺于电脑娱乐彻夜不眠,难以自拔。更有甚者整天沉溺于网上黄色、赌博、恐怖暴力等内容,参与网上犯罪,传播消极的网上文化。给其身心带来极大的危害。
3.与校园文化生活不够丰富有关
“双休日”及“五一”“十一”长假,使当代大学生课余时间越来越充足,而校园文化生活并未随之丰富起来。校园文化生活内容单调,形式单一,参加范围窄,这正好为大学生热衷上网提供了时间上的条件。
大学生应正确利用网络
1、学习方面:
互联网向大学生展示了各类知识结构,对于知识选择的灵活性大大增加,学习的主动性也大大提高,学习的内容自然大大超过了狭隘的课本范围,这对于大学生能力的提高应是大有裨益的.当然并不否认网络同时带来了一些不良的信息,特别对于大学生而言,完整的价值观念还未形成,好奇心又很强,很容易受到外来事物的影响.网络完全开放和虚拟的空间可以让大学生随心所欲的表现自己,但如果把握不好,好奇的心态和过分的追求个性张扬的心理也许会把学习引入歧途.现在时代是迅速制造距离的时代,在纷繁的现象背后仍是优胜劣汰的残酷现实,清净的大学校园有而是如此,因小看大,不可不戒.别让它耽误了我们的学习.
2、娱乐方面:
对反动、色情、迷信的信息,自觉地不看,不听,不信。对这些精神“毒品”,不要抱着好奇、试试看的心理,一“吃”就上瘾,一上瘾就难以自拔。与其以后进“戒毒所”,不如一开始就抵制它。一个不懂得抵制的人,总是跟着感觉走、跟着时髦走的人,是不可能实现道德自律的。不在网上发表不负责任的言论。网上聊天,可帮助我们交流信息和思想。如果认为在那个虚拟的世界里可以不负责任地胡说八道,那就错了。虚拟的世界连着真实的世界,影响着每一个坐在电脑前面的人,一个有正义感、有责任感的人,在生活中会处处以负责任的态度行事,主持正义,反对邪恶。
3. 身体健康方面:
(1)上网对身体的影响的主要原因是上网时间过长和使用电脑坐姿错误.
(2)长时间的上网,会对眼睛有伤害,使其疲劳,从而影响视力.
我的建议:
大家在上网时,能够正确地按照规定的作姿.上网时间不要过长,每上一个小时后能够休息一下以释解疲劳.能正确利用网络。
第二篇:统计学资料
3、简要说明统计数据的来源。
答:统计数据来源于直接组织的调查、观察和科学试验,我们称之为第一手数据或直接的数据;或者来源于已有的数据,我们称之为第二手的数据或间接的数据。
4.获取直接统计数据的渠道主要有哪些?
答:获取直接统计数据的渠道主要有两种,即普查和抽样调查。
5、简要说明抽样误差和非抽样误差。
答:抽样误差是利用样本推断总体时产生的误差。
非抽样误差是由于调查过程中各有关环节工作失误造成的。
12、简述众数、中位数和均值的特点和应用场合。
答:众数是将数据按大小顺序排队形成次数分配后,在统计分布具有明显集中趋势点的数值,是数据一般水平代表性的一种。正态分布和一般的偏态分布中,分布最高峰点所对应的数值即众数。
中位数是数据排序后,位置在最中间的数值。中位数将数据分成两半,一半数据比中位数大,一半比中位数小。
均值就是算术平均数,是数据集中趋势的最主要测度值。
众数最容易计算,但不是永远存在,同时作为集中趋势代表值应用的场合很少;中位数很容易理解、很直观,它不受极端值的影响,这既是它有价值的方面,也是它数据信息利用不够充分的地方;均值是对所有数据平均后计算的一般水平代表值,数据信息提取得最充分,特别是当要用样本信息对总体进行推断时,均值就更显示出它的各种优良特征。均值在整个统计方法中应用最广,对经济管理和工程等实际工作也是最为重要的方法之一。
13、为什么要计算离散系数?
答:离散系数是用来对两组数据的差异程度进行相对比较的。因为在比较相关的两组数据的差异程度时,方差和标准差是以均值为中心计算出来的,因而有时直接比较方差是不准确的,需要剔除均值大小不等的影响,需要计算并比较离散系数。
P156
1、 简述评价估计量好坏的标准。
答:评价估计量的标准主要有:无偏估计、有效性、相合性。
无偏估计是指估计量抽样分布的数学期望等于被估计的总体参数。
一个无偏的估计量并不意味着它非常接近被估计的参数,它还必须与总体参数的离散程度比较小。对同一总体参数的两个无偏点估计量,标准差越小的估计量越有效。
相合性是指随着样本容量的增大,点估计值越来越接近被估总体的参数。
2、z α/2 σ/√n 的含义是什么?
答:含义是估计总体均值时的允许误差,也称为估计误差或误差范围。也就是说,总体均值的置信区间由两部分组成:点估计值和允许误差。
3、 解释置信水平的含义。
答:置信水平是指总体参数值落在样本统计值某一区内的概率;
4、 解释置信水平为95%的置信区间的含义。
答:是指在置信水平为95%的时候,样本统计值与总体参数值间误差范围。
Where amazing happens!Just do it! 乐观,进取,加油,阳光!!! 35
P206
3、 第1类错误和第2类错误分别是指什么?它们发生的概率大小之间存在怎样的关系?
答:当原假设为真时拒绝原假设,所犯的错误称为第1类错误,又称为弃真错误,通常记为α。当原假设为假时没有拒绝原假设,所犯的错误称为第2类错误,又称为取伪错误,通常记为β。当α增大时,β减小;当β增大时,α减小,两类错误就像一个翘翘板。
4、 什么是显著性水平?它对于假设检验决策的意义是什么?
答:显著性水平即在统计假设检验中,公认的小概率事件的概率值被称为统计假设检验的显著性水平,记为α。α的取值越小,此假设检验的显著性水平越高。
5、 什么是P值?P值检验和统计量检验有什么不同?
答:如果原假设H0为真,所得到的样本结果会像实际观测结果那么极端或更极端的概率,称为P值,也称为观察到的显著性水平。
根据样本观测结果计算得到的,并据以对原假设和备择假设做出决策的某个样本统计量,称为检验统计量。
检验统计量实际上是总体参数的点估计量,但是点估计量并不能直接作为检验的统计量,只有将其标准化后,才能用于度量它与原假设的参数值之间的差异程度。
显著性水平α是在检验之前确定的,这也就意味着事先确定了拒绝哉。这样,不论检验统计量的值是大还是小,只要它的值落入拒绝域就拒绝原假设H0,否则就不拒绝原假设H0。这种固定的显著性水平α对检验结果的可靠性起一种度量作用,但不中的是,α是犯第一类错误的上限控制值,它只提供检验结论可靠性的一个大致范围,而对于一个特定的假设检验问题,却无法给出观测数据与原假设之间不一致程度的精确度量。也就是说,公从显著性水平来比较,如果选择的α值相同,则所有检验结论的可靠性都一样。
P值与原假设的对或错的概率无关,它是关于数据的概率。P值告诉我们:在某个总体的许多样本中,某一类数据出现的经常程度,也就是说,P值是当原假设正确时,得到所观测的数据的概率。如果原假设是正确的话,P值告诉我们得到这样的观测数据是多么的不可能。相当不可能得到的数据,就是原假设不对的证据。P值是反映实际观测到的数据与原假设H0之间不一致程度的一个概率值。P值越小,说明实际观测到的数据与H0之间不一致的程度就越大,检验的结果也就越显著。
6、 什么是统计上的显著性?
答:发生第一类错误的概率也常被用于检验结论的可靠性度量,假设检验中犯的第一类错误发生的概率被称为显著性水平,记为α。显著性水平是指当原假设实际上正确时,检验统计量落在拒绝哉的概率。
P248
1、 什么是方差分析?它所研究的是什么?
答:方差分析是检验多个总体均值是否相等的统计方法。它是通过检验各总体的均值是否相等来判断分类型自变量对数值型因变量是否有显著影响。
表面上看,方差分析是检验多个总体的均值是否相同,但是本质上它所研究的是分类型自变量对数值型因变量的影响,如它们之间有没有关系,关系的密切程度如何,等等。
3、方差分析包括哪些类型?它们有何区别?
答:单因素方差分析:方差分析中只涉及一个分类型自变量时,称为单因素方差分析;它研究的是一个分类型变量对一个数值型因变量的影响。
双因素方差分析:方差分析中涉及两个分类型自变量时,称为双因素方差分析。其中包括无交互作用的双因素方差分析和有交互作用的双因素分析。
如果两个因素对试验结果的影响是相互独立的,分别判断行因素和列因素对试验数据的影响,这时的双因素方差分析称为无交互作用的双因素方差分析或无重复双因素方差分析。
如果除了行因素和列因素对试验数据的单独影响外,两个因素的搭配还会对结果产生一种新的影响,
Where amazing happens!Just do it! 乐观,进取,加油,阳光!!! 36
这时的双因素方差分析称为有交互作用的双因素方差分析或可重复双因素方差分析 。
7、 解释水平项平方和、误差平方和的含义。
答:水平项误差平方和简记为SSA,它是各组平均值与总平均值的误差平方和,反映各总体的样本均值之间的差异程度,因此双称为组间平方各。
误差项平方和,简记为SSE,它是每个水平或的各样本数据与其组平均值误差的平方和,反映了每个样本各观测值的离散状况,因此双称为组内平方和或残差平方和。
11、解释R2的含义和作用。
答:用自变量平方和(SSA)及残差平方和(SSE)占总平方和(SST)的比例大小来度量自变量对因变量的影响效应。其中自变量平方和占总平方和的比例记为R2,即:
R2=SSA(组间SS)/SST(总SS)
其算术平方根R可以用来测量自变量与因变量之间的关系强度。
P289
1、 相关分析与回归分析的关系是什么?
答:相关分析与回归分析的研究目的和研究方法是有明显区别的。从研究目的上看,相关分析是用一定的数量指标(相关系数)度量变量间相互联系的方向和程度,回归分析却是要寻求变量间联系的具体数学形式,是要根据自变量的固定值去估计和预测因变量的值。从对变量的处理来看,相关分析对称地对待相互联系的变量,不考虑二者的因果关系,也就是不区分自变量和因变量,相关的变量不一定具有因果关系,均视为随机变量;回归分析是在变量因果关系分析的基础上研究其中的自变量的变动对因变量的具体影响,必须明确划分自变量和因变量,回归分析中对变量处理是不对称的,在回归分析中通常假定自变量在重复抽样中是取固定值的处理是不对称的,在回归分析中通常假定自变量在重复抽样中是取固定值的非随机变量,只有因变量是具有一定概率分布的随机变量。
2、 什么是总体回归函数和样本回归函数?它们之间的区别是什么?
答:假如已知所研究的经济现象总体中因变量Y和自变量X的每个观测值,便可以计算出总体因变量Y的条件期望E(Y\X),并将其表现为自变量X的某种函数,这个函数称为总体回归函数(简记为PRE)。
在实际的经济问题,通常总体包含的单位数很多,无法掌握所有单位的数值,总体回归函数实际上是未知的。可能做到的只是对应于自变量X的选定水平,对因变量Y的某些样本进行观测,然后通过对样本观测获得的信息去估计总体回归函数,这就是样本回归函数。
样本回归函数的函数形式应与设定的总体回归函数的函数形式一致。
5、 什么是随机误差项和残差?它们之间的区别是什么?
答:随机误差项也称误差项,是一个随机变量,针对总体回归函数而言。
残差项是一随机变量,针对样本回归函数而言。
随机误差是方程假设的,而残差是原值与拟合值的差。实践中经常用残差去估计这个随机误差项。
6、 为什么在对参数进行最小二乘估计时,要对模型提出一些基本的假定?
答:回归分析要用样本数据去估计回归函数中的参数,而各种估计方法都是以一定假定为前提的。总体回归函数中的随机扰动项ui是无法直接观测的,为了进行回归分析,需要对其性质作一些基本的假定。完全满足以上基本假定的线性回归模型,称为古典线性回归模型。对于古典线性回归模型的估计最简便、最常用的是普通最小二乘法。
P327
2为什么平均发展速度用几何平均法计算?计算平均发展速度的水平法的特点是什么?
答:平均发展速度是各期环比发展速度的序时平均数,通常采用几何平均法去计算。这是由于现象发展的总速度并不等于各期环比发展速度之和,而是等于各期环比发展速度的连乘积,所以各期环比发展速度的
Where amazing happens!Just do it! 乐观,进取,加油,阳光!!! 37
序时平均数,不能在速度代数和基础上按算术平均法去计算,而只能在速度连乘积基础上按几何平均法去
计算。
3、 甲企业近四年产品销售量分别增长了9%、7%、8%、6%;乙企业这四年产品的次品率也正好是9%、
7%、8%、6%。这两个企业这四年的平均增长率和平均次品率的计算是否一样?为什么?
答:不一样。这里的增长速度=(今年速度-去年速度)/去年速度。
10、循环变动和季节变动的区别是什么?
答:循环变动是指以若干年(或季、月)为一定周期的有一定规律性的周期波动。
季节变动是指受自然因素的影响,在一年中随季节的更替而发生的有规律的变动。
循环变动的周期长短很不一致,不像季节前明显的按月或按季的固定周期规律,循环变动的规律性不
甚明显。
P327
1、 什么是统计决策?它包括哪些基本步骤?
答:不少决策问题,需要利用有关的统计信息和相应的统计分析方法。从广义上讲,所有利用统计方法和
统计信息的决策都可以称为统计决策。
步骤:一、确定决策目标。二、拟订备选方案。三、列出自然状态。四、选择“最佳”或“满意”的
方案。五、实施方案。
2、 什么是完全不确定型决策?什么是风险型决策?它们之间的主要区别是什么?
答:完全不确定型决策是在对各种状态发生的概率一无所知的情况下进行决策。它包括最大的最大收益值
准则、最大的最小收益准则、最小的最大后悔值准则、折中准则和等可能性准则。
风险型决策是指决策者对决策对象的自然状态和客观条件比较清楚,也有比较明确的决策目标,但是
实现决策目标必须冒一定风险。每个备选方案都会遇到几种不同的可能情况,而且已知出现每一种情况的
可能性有多大,即发生的概率有多大,因此在依据不同概率所拟定的多个决策方案中,不论选择哪一种方
案,都要承担一定的风险。
风险型决策与完全不确定型决策不同之处在于:它是在估计出状态空间的概率分布的基础上进行决策。
3、 什么是贝叶斯决策?为什么要进行贝叶斯决策?
答:贝叶斯决策就是在不完全信息下,对部分未知的状态用主观概率估计,然后用贝叶斯公式对发生概率
进行修正,最后再利用期望值和修正概率做出最优决策。
原因:利用贝叶斯决策方法,可以将先验的信息和补充的信息结合在一起进行分析与判断,从而提高
了决策的可靠性。同时,利用该方法,还可以对信息的价值以及是否需要采集新的补充信息做出科学的判
断。
模拟题:
一. 单项选择题(每小题2 分,共20 分)
1. 对于未分组的原始数据,描述其分布特征的图形主要有( )
A. 直方图和折线图 B. 直方图和茎叶图
C. 茎叶图和箱线图 D. 茎叶图和雷达图
2. 在对几组数据的离散程度进行比较时使用的统计量通常是( )
A. 异众比率 B. 平均差 C. 标准差 D. 离散系数
3. 从均值为100、标准差为10的总体中,抽出一个n = 50的简单随机样本,样本均值的数学期望和方差分别为( )
A. 100 和2 B. 100 和0.2 C. 10 和1.4 D. 10 和2
4. 在参数估计中,要求通过样本的统计量来估计总体参数,评价统计量标准之一是使它与总体参数的离差越小越好。这种
Where amazing happens!Just do it! 乐观,进取,加油,阳光!!! 38
评价标准称为( )
A. 无偏性 B. 有效性 C. 一致性 D. 充分性
5. 根据一个具体的样本求出的总体均值95%的置信区间( )
A. 以95%的概率包含总体均值 B. 有5%的可能性包含总体均值
C. 一定包含总体均值 D. 可能包含也可能不包含总体均值
6. 在方差分析中,检验统计量F 是( )
A. 组间平方和除以组内平方和 B. 组间均方和除以组内均方
C. 组间平方和除以总平方和 D. 组间均方和除以组内均方
7. 在回归模型y = b +b x +e 0 1
中,e 反映的是( )
A. 由于x 的变化引起的y 的线性变化部分
B. 由于y 的变化引起的x 的线性变化部分
C. 除x 和y 的线性关系之外的随机因素对y 的影响
D. 由于x 和y 的线性关系对y 的影响
8. 在多元回归分析中,多重共线性是指模型中( )
A. 两个或两个以上的自变量彼此相关
B. 两个或两个以上的自变量彼此无关
C. 因变量与一个自变量相关
D. 因变量与两个或两个以上的自变量相关
9. 若某一现象在初期增长迅速,随后增长率逐渐降低,最终则以K 为增长极限。描述该类现象所采用的趋势线应为( )
A. 趋势直线 B. 指数曲线 C. 修正指数曲线 D. Gompertz 曲线
10. 消费价格指数反映了( )
A. 商品零售价格的变动趋势和程度
B. 居民购买生活消费品价格的变动趋势和程度
C. 居民购买服务项目价格的变动趋势和程度
D. 居民购买生活消费品和服务项目价格的变动趋势和程度
二. 简要回答下列问题(每小题5 分,共20 分)
1. 解释总体与样本、参数和统计量的含义。
2. 简述方差分析的基本假定?
3. 简述移动平均法的基本原理和特点。
4. 解释拉氏指数和帕氏指数。
三. (20 分)一种产品需要人工组装,现有三种可供选择的组装方法。为比较哪种方法更好,随机抽取10 个工人,让他们分
别用三种方法组装。下面是10 个工人分别用三种方法在相同时间内组装产品数量(单位:个)的描述统计量:
方法1 方法2 方法3
平均 165.7 平均 129.1 平均 126.5
中位数 165 中位数 129 中位数 126.5
众数 164 众数 129 众数 126
标准差 2.45 标准差 1.20 标准差 0.85
峰值 -0.63 峰值 -0.37 峰值 0.11
偏斜度 0.38 偏斜度 -0.23 偏斜度 0.00
极差 8 极差 4 极差 3
最小值 162 最小值 127 最小值 125
最大值 170 最大值 131 最大值 128
(1) 你准备采用什么方法来评价组装方法的优劣?试说明理由。
Where amazing happens!Just do it! 乐观,进取,加油,阳光!!! 39
(2) 如果让你选择一种方法,你会作出怎样的选择?试说明理由。
四. (20 分)从一批零件中随机抽取36 个,测得其平均长度为149.5cm,标准差为1.93cm。
(1) 试确定该种零件平均长度95%的置信区间。
(2) 若要求该种零件的标准长度应为150cm,用假设检验的方法和步骤检验该批零件符合标准要求?
(a = 0.05)。
(3) 在上面的估计和检验中,你使用了统计中的哪一个重要定理?请简要解释这一定理。
五. ((20 分)一家产品销售公司在30 个地区设有销售分公司。为研究产品销售量(y)与该公司的销售价格(x1)、各地区的年人
均收入(x2)、广告费用(x3)之间的关系,搜集到30个地区的有关数据。利用Excel得到下面的回归结果(a = 0.05 ):
方差分析表
变差来源 df SS MS F Significance F
回归 4008924.7 8.88341E-13
残差 — —
总计 29 13458586.7 — — —
参数估计表
Coefficients 标准误差 t Stat P-value
Intercept 7589.1025 2445.0213 3.1039 0.00457
X Variable 1 -117.8861 31.8974 -3.6958 0.00103
X Variable 2 80.6107 14.7676 5.4586 0.00001
X Variable 3 0.5012 0.1259 3.9814 0.00049
(1) 将方差分析表中的所缺数值补齐。
(2) 写出销售量与销售价格、年人均收入、广告费用的多元线性回归方程,并解释各回归系数的意义。
(3) 检验回归方程的线性关系是否显著?
(4) 检验各回归系数是否显著?
(5) 计算判定系数2 R ,并解释它的实际意义。
(6) 计算估计标准误差
y s ,并解释它的实际意义。
模拟试卷二:
一、 单项选择题(每小题2 分,共20 分)
1. 甲、乙、丙三人的数学平均成绩为72 分,加上丁后四人的平均成绩为78 分,则丁的数学成绩为
A. 96 B. 90 C.80 D.75
2. 以下是根据8 位销售员一个月销售某产品的数量制作的茎叶图
0 3
8 7 6 2
5 5
6
5
4
则销售的中位数为 A. 5 B. 45 C. 56.5 D. 7.5
3. 10 个翻译当中有8 个人会英语,7 个人会日语。从这10 个人当中随机地抽取一个人,他既会英语又会日语的概率为
A.
10
8
B.
10
5
C.
10
7
D.
10
1
4. 某汽车交易市场共发生了150 项交易,将销售记录按付款方式及汽车类型加以区分如下:
Where amazing happens!Just do it! 乐观,进取,加油,阳光!!! 40
一次付款 分期付款
新车
旧车
5
25
95
25
如果从销售记录中随机抽取一项,该项是分期付款的概率是
A. 0.95 B. 0.5 C. 0.8 D. 0.25
5. 某火车票代办点上季度(共78 天)的日销售额数据如下:
销售额(元) 天数
3000 以下 8
3000—3999 22
4000—4999 25
5000—5999 17
6000 及以上 6
从中任选一天,其销售额不低于5000 元的概率为
A.
13
1
B.
78
23
C.
78
72
D. 0
6. 纺织品平均10 平方米有一个疵点,要观察一定面积上的疵点数X , X 近似服从
A. 二项分布 B. 泊松分布 C. 正态分布 D. 均匀分布
7. 某总体容量为N ,其标志值的变量服从正态分布,均值为m ,方差为2 s 。X 为样本容量为n 的简单随机样本的均
值(不重复抽样),则X 的分布为
A. ( , ) 2 N m s B. ( , )
2
n
N
s
m C. ( , )
2
n
N X
s
D. )
1
( ,
2
-
-
×
N
N n
n
N
s
m
8. 在参数估计中,要求通过样本的统计量来估计总体参数,评价统计量标准之一是使它与总体参数的离差越小越好。这种
评价标准称为
B. 无偏性 B. 有效性 C. 一致性 D. 充分性
9. 拉氏指数方法是指在编制综合指数时
A. 用基期的变量值加权 B. 用报告期的变量值加权
C. 用固定某一时期的变量值加权 D. 选择有代表性时期的变量值加权
10. 根据各季度商品销售额数据计算的季节指数分别为∶一季度125%,二季度70%,三季度100%,四季度105%。受季节
因素影响最大的是
B. 一季度 B. 二季度 C. 三季度 D. 四季度
二、 简要回答下列问题(每小题5 分,共20 分)
1. 解释95%的置信区间。
2. 简述风险型决策的准则。
3. 简述居民消费价格指数的作用。
4. 在回归模型= b +b +b + +b +e p p y x x L x 0 1 1 2 2
中,对e 的假定有哪些?
三、 (15 分)下面是36 家连锁超市10 月份的销售额(万元)数据:
167 190 166 180 167 165 174 170 187
185 183 175 158 167 154 165 179 186
189 195 178 197 176 178 182 194 156
Where amazing happens!Just do it! 乐观,进取,加油,阳光!!! 41
160 193 188 176 184 179 176 177 176
(1) 根据上面的原始数据绘制茎叶图。
(2) 将销售额等距分为5 组,组距为10,编制次数分布表;
(3) 绘制销售额次数分布的直方图,说明销售额分布的特点。
(4) 说明直方图和茎叶图的区别。
四、 (15 分)甲、乙两个班参加同一学科考试,甲班的平均考试成绩为86 分,标准差为12 分。乙班考试成绩的分布如
下:
考试成绩(分) 学生人数(人)
60 以下
60—70
70—80
80—90
90—100
2
7
9
7
5
合计 30
要求:(1)计算乙班考试成绩的均值及标准差;
(2)比较甲乙两个班哪个班考试成绩的离散程度大?
五、 (15 分)某企业生产的袋装食品采用自动打包机包装,每袋标准重量为100 克。现从某天生产的一批产品中按重复抽样
随机抽取50 包进行检查,测得每包重量(克)如下:
每包重量(克) 包数
96~98 2
98~100 3
100~102 34
102~104 7
104~106 4
合计 50
已知食品包重服从正态分布,要求:
(1) 确定该种食品平均重量95%的置信区间。
(2) 如果规定食品重量低于100 克属于不合格,确定该批食品合格率95%的置信区间。
(3) 采用假设检验方法检验该批食品的重量是否符合标准要求?(写出检验的具体步骤)。
(注: 1.96 2 0.025 z = z = a
)
六、 (15 分)随着零售业市场竞争的日益加剧,各零售商不断推出新的促销策略。物通百货公司准备利用五一假日黄金周采
取部分商品的大幅度降价策略,旨在通过降价赢得顾客、提高商品的销售额,同时也可以进一步调整商品的结构。为
分析降价对销售额带来的影响,公司收集的降价前一周和降价后一周集中主要商品的有关销售数据,如下表:
几种主要商品一周的销售数据
商品名称 计量单位
价格(元) 销售量
降价前 降价后 降价前 降价后
甲 台 3200 2560 50 70
乙 套 860 516 120 180
丙 件 180 126 240 336
(1) 降价后与降价前相比,三种商品的总销售额增长的百分比是多少?销售额增长的绝对值是多少?
(2) 以降价后的销售量为权数,计算三种商品的平均降价幅度是多少?由于降价而减少的销售额是多少?
(3) 以降价前的价格为权数,计算三种商品的销售量平均增长幅度是多少?由于销售量增长而增加的销售额是多
少?
Where amazing happens!Just do it! 乐观,进取,加油,阳光!!! 42
说明你在分析上述问题时采用的是什么统计方法?采用该方法的理由是什么?
模拟试卷一答案:
七、 单项选择题
1. CDABD BCACD
八、 简答题
i. 总体:所研究的全部个体(元素)的集合。
样本:从总体中抽取的一部分元素的集合,构成样本的元素的数目称为样本容量。
参数:研究者想要了解的总体的某种特征值,参数通常是一个未知的常数。
统计量:根据样本数据计算出来的一个量。由于样本是我们所已经抽出来的,所以统计量总是知道的。
ii. (1)每个总体都应服从正态分布。也就是说,对于因素的每一个水平,其观测值是来自正态分布总体的简单随机样本。
(2)各个总体的方差2 s 必须相同。也就是说,对于各组观察数据,是从具有相同方差的正态总体中抽取的。
(3)观测值是独立的。
iii. 移动平均法是趋势变动分析的一种较简单的常用方法。当时间数列的变动趋势为线性状态时,可采用移动平均法进行描
述和分析。该方法是通过扩大原时间数列的时间间隔,并按一定的间隔长度逐期移动,分别计算一系列移动平均数,由
这些平均数形成的新的时间数列对原时间数列的波动起到一定的修匀作用,削弱了原数列中短期偶然因素的影响,从而
呈现出现象发展的变动趋势。
iv. 拉氏指数是1864 年德国学者拉斯贝尔斯(Laspeyres)提出的一种指数计算方法,它是在计算一组项目的综合指数时,把
作为权数的各变量值固定在基期而计算的指数。
帕氏指数是1874 年德国学者帕煦(Paasche)所提出的一种指数计算方法,计算一组项目的综合指数时,把作为权数的
变量值固定在报告期计算的指数。
九、 (1)用离散系数。 因为标准差不能用于比较不同组别数据的离散程度。
(2)三种组装方法的离散系数分别为: = 0.015 A v , = 0.009 B v , = 0.007 C v 。虽然方法A 的离散程度要大
于其他两种方法,但其组装产品的平均数量远远高于其他两种方法。所以还是应该选择方法A。
十、 (1) 149.5 0.63
36
1.93
149.5 1.96 2 ± = ± ´ = ±
n
s
x za
(148.87,150.13)
(2) : 150 0 H m = , : 150 1 H m ¹ 。
检验统计量1.55
1.93 36
149.5 150
= -
-
z = ,由于1.55 1.96 2 = - < = a z z 。不拒绝原假设。符合要求。
(3)使用了中心极限定理。从均值为m 、方差为2 s 的总体中,抽取容量为n 的随机样本,当n 充分大时(通常要求
n ³ 30),样本均值x 的抽样分布近似服从均值为m 、方差为n 2 s 的正态分布。
十一、 (1)
变差来源 df SS MS F Significance F
回归 3 12026774.1 4008924.7 72.8 8.88341E-13
残差 26 1431812.6 55069.7 — —
Where amazing happens!Just do it! 乐观,进取,加油,阳光!!! 43
总计 29 13458586.7 — — —
(2)
1 2 3 y? = 7589.1025 -117.8861x +80.6107 x +0.5012 x
回归系数? 117.8861
1 b = - 表示:在年人均收入和广告费用不变的条件下,销售价格每增加1 元,销售量平均减
少117.8861 个单位; ? 80.6107
1 b = 表示:在年销售价格和广告费用不变的条件下,人均收入每增加1 元,销售量平均增
加80.6107个单位;? 0.5012
3 b = 表示:在年销售价格和人均收入不变的条件下,广告费用增加1元,销售量平均增加0.5012
个单位。
(3)由于Significance F=8.88341E-13<0.05。拒绝原假设,线性关系显著。
(4)各回归系数检验的P 值分别为:0.00103、0.00001、0.00049,均小于0.05,表明各回归系数均显著。
(5) 89.36%
13458586 .7
12026774 .1 2 R = = 。它表示在销售量的总变差中,被销售价格、年人均收入、广告费用与销售量
之间的线性关系所解释的比例为89.36%。
(6) 234.67
30 3 1
1431812 .6
=
- -
= y s 。它表示销售价格、年人均收入和广告费用预测销售量时的平均预测误差为
234.67 元。
模拟试卷二答案:
一、 单项选择题
1. ACCCB BDBAB
二、 简要回答下列问题
1. 如果用某种方法构造的所有区间中有95%的区间包含总体参数的真值,5%的区间不包含总体参数的真值,那么,
用该方法构造的区间称为置信水平为95%的置信区间。
2. (1)期望值准则。它是以各方案收益的期望值的大小为依据,来选择合适的方案。(2)变异系数准则根据变异系
数作为选择方案的标准,以变异系数较低的方案作为所要选择的方案。
(3)最大可能准则。在最可能状态下,可实现最大收益值的方案为最佳方案。
(4)满意准则。首先要给出一个满意水平,然后,将各种方案在不同状态下的收益值与目标值相比较,并以收益值
不低于目标值的累积概率为最大的方案作为所要选择的方案。
3. (1)用于反映通货膨胀状况。(2)反映货币购买力变动。货币购买力是指单位货币能够购买到的消费品和服务的
数量。(3)反映对职工实际工资的影响。消费价格指数的提高意味着实际工资的减少,消费价格指数下降则意味着
实际工资的提高。因此,利用消费价格指数可以将名义工资转化为实
4. (1)误差项e 是一个期望值为0的随机变量,即E(e ) = 0。
(2)对于自变量
p x , x , , x 1 2 L 的所有值,e 的方差s 2 都相同。
(3)误差项e 是一个服从正态分布的随机变量,且相互独立。即e ~ N(0,s ) 2 。
三、 (1)茎叶图如下:
茎 叶
15 4 6 8
Where amazing happens!Just do it! 乐观,进取,加油,阳光!!! 44
16 0 5 5 6 7 7 7
17 0 4 5 6 6 6 6 7 8 8 9 9
18 0 2 3 4 5 6 7 8 9
19 0 3 4 5 7
(7) 频数分布表如下:
(8) 直方图如下:
(9) 茎叶图类似于横置的直方图,与直方图相比,茎叶图既能给出数据的分布状况,又能给出每一个原始数
值,即保留了原始数据的信息。而直方图虽然能很好地显示数据的分布,但不能保留原始的数值。在应用方
面,直方图通常适用于大批量数据,茎叶图通常适用于小批量数据。
四、 (1) -77 x乙 , s乙=11.86
(2) 0.140
86
12
v甲= = , 0.154
77
11.86
v乙= = 。乙班的离散程度大。
五、 (1) x = 101.32,s =1.63。
101.32 0.45
50
1.63
101.32 1.96 2 ± = ± ´ = ±
n
s
x za
(100.87,101.77)
(2) 0.10
50
5
p = = 。
0.10 0.08
50
0.10(1 0.10)
0.10 1.96
(1 )
2 = ±
-
= ± ´
-
±
n
p p
p za
(2%,18%)
(3) : 100 0 H m = , : 100 1 H m ¹ 。
检验统计量5.73
1.63 50
101.32 100
=
-
z = ,由于5.73 1.96 2 = > = a z z 。拒绝原假设。不符合要求。
六、 (1)三种商品的总销售额增长的百分比:
1 102.62% 1 2.62%
306400
314416
1
3200 50 860 120 180 240
2560 70 516 180 126 336
1
0 0
1 1 - = - = - =
´ + ´ + ´
´ + ´ + ´
- =
å
å
p q
p q
销售额增
长的绝对值= 314416 306400 8016(元) 1 1 0 0 åp q -åp q = - =
0
2
4
6
8
10
12
150-155
155-160
160-165
165-170
170-175
175-180
180-185
185-190
190-195
195-200
分组 频数
150-155 1
155-160 2
160-165 1
165-170 6
170-175 2
175-180 10
180-185 4
185-190 5
190-195 3
195-200 2
合计 36
Where amazing happens!Just do it! 乐观,进取,加油,阳光!!! 45
(2)三种商品的平均降价幅度:
1 71.58% 1 28.42%
439280
314416
1
3200 70 860 180 180 336
2560 70 516 180 126 336
1
0 1
1 1
1 0 - = - = - = -
´ + ´ + ´
´ + ´ + ´
= - =
å
å
p q
p q
p
由于降价而减少的销售额= 314416 439280 124864(元) 1 1 0 1 åp q -åp q = - = -
(3)三种商品的销售量平均增长幅度:
1 143.37% 1 43.37%
306400
439280
1
3200 50 860 120 180 240
3200 70 860 180 180 336
1
0 0
0 1
1 0 - = - = - =
´ + ´ + ´
´ + ´ + ´
= - =
å
å
p q
p q
q
由于销售量增长而增加的销售额=
439280 306400 132880(元) 0 1 0 0 åp q -åp q = - =
(4)采用的是统计指数方法。由于所要分析的是三种不同商品销售额、价格和销售量的综合变动。要进行综合并进行对比,
通常要采用指数的方法。
管理学
第一章
1、界定效果和效率的差别P7 P8
效率:以最少的投入获得最多的产出。也被称为用正确的方法生产。
Efficiency: Getting the most output from the least amount of input. Referred to as ―doing things right‖
效果:完成各种活动来实现组织的目标。也被称为做正确的事情。
Effectiveness: completing activities so that the organizational are attain .referred to as ―doing the right thing‖
效率考虑的是资源的利用,效果考虑的是目标的实现. Efficiency focus on getting the best of the resources while Effectiveness pay
more attention to the accomplishing of goals.
2、管理者的工作p9
计划、组织、领导、控制
Planning、organizing、commanding、coordinating
3、层次划分P6 图
高层管理者、中层管理者、基层管理者、非管理雇员
Top managers、Middle managers 、First-line managers、 Nonmanagerial employees__