XML学习心得
这个学期有幸学习了学校里开的XML认证课,接触了一个全新的概念,学到了很多也懂得了很多。下面根据我的理解介绍一下XML。
我将从五个个方面来论述XML,分别是基础知识,语法规则,格式特性,应用发展以及未来前景。
一、基础知识
XML,就是Extensible Markup Language,即可扩展标记语言。可扩展标记语言是标准通用标记语言的子集,一种用于标记电子文件使其具有结构性的标记语言。它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。XML非常适合万维网传输,提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。
通过查询资料,我得到了关于XML的一些特点总结:
l XML 是一种很像HTML的标记语言。
l XML 的设计宗旨是传输数据,而不是显示数据。
l XML 标签没有被预定义。您需要自行定义标签。
l XML 被设计为具有自我描述性。
l XML 是 W3C 的推荐标准。
人们很容易把XML和HTML混淆,可是他们是不一样的。在区分他们的不同之前,我先介绍一下HTML。
HTML是一种标记语言,是Hypertext Markup Language"的缩写,即超文本标记语言。超级文本标记语言是标准通用标记语言下的一个应用,也是一种规范,一种标准, 它通过标记符号来标记要显示的网页中的各个部分。网页文件本身是一种文本文件,通过在文本文件中添加标记符,可以告诉浏览器如何显示其中的内容,比如文字如何处理,画面如何安排,图片如何显示等等。浏览器按顺序阅读网页文件,然后根据标记符解释和显示其标记的内容,对书写出错的标记将不指出其错误,且不停止其解释执行过程,编制者只能通过显示效果来分析出错原因和出错部位。
可以看出XML 和 HTML 是为不同的目的而设计的。XML 被设计用来传输和存储数据,其焦点是数据的内容。而HTML 被设计用来显示数据,其焦点是数据的外观。很显然HTML 旨在显示信息,而 XML 旨在传输信息。还有一点不同就是,HTML标记是预定义的,它只认识诸如<html>,<p>等已经定义的标记,对于用户自己定义的标记是不认识的;XML标记是自己定义的,它是一种元标记语言,所谓“元标记”就是开发者可以根据自己的需要定义自己的标记,比如开发者可以定义如下标记<book> <name>,任何满足XML命名规则的名称都可以标记,这就为不同的应用程序打开了的大门。还有,HTML的格式要求比较松散 ;而XML是非常严格的标记语言。
XML不是对HTML 的替代,而是对HTML的补充。对 XML 最好的描述是:XML 是独立于软件和硬件的信息传输工具。
那么XML是应什么而出现的呢?
W3C于1998年2月批准了XML的1.0版本。在线电子商务活动交换的电子文档必须采用某种标准格式,统一电子文档的标准规范是电子商务的基础。HTML不适合作为电子商务的文档标准;而SGML(Standard Generalized Markup Language)又过于复杂,无法适应网络上的日常应用。
XML是对SGML的简化,语法与HTML非常相似。XML具有SGML的强大功能和可扩展性,同时又具有HTML的简单性。XML文档很容易创建,并且结构清晰,不仅让人能够明白,还让计算机也能够明白。而且它作为一种公订的、开放的标准,不受知识产权的限制。
我们可以看出XML的出现是时代的呼唤,社会的要求。
二、语法规则
在介绍语法规则之前,我先介绍一下XML的元素,属性和树结构。
1、元素
XML 元素指的是从(且包括)开始标签直到(且包括)结束标签的部分。一个元素可以包含:其他元素,文本,属性,或者前面三者都包含。元素可使用任何名称,没有保留的字词。
XML 元素必须遵循以下命名规则:
l 名称可以包含字母、数字以及其他的字符
l 名称不能以数字或者标点符号开始
l 名称不能以字母 xml(或者 XML、Xml 等等)开始
l 名称不能包含空格
2、属性
类似于HTML,XML的元素具有属性。属性提供有关元素的额外信息。
下面是属性的规则:
l 属性可以在起始标签和处理指令之间声明
l 多个属性之间使用空格分隔
l 每条属性包含属性名和属性值两个部分
n 一个元素中不能有重名的属性
n 在同一个XML文件中不同元素中属性名可以重用
n 属性名不可以包含空格
n 赋值时可以使用单引号或双引号
举一个简单的小例子:
<tree species ="Salix">Willow</tree>,其中species就是属性名,Salix就是属性值
3、树结构
XML文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端。所有的元素都可以有子元素:父、子以及同胞等术语用于描述元素之间的关系。父元素拥有子元素。相同层级上的子元素成为同胞。所有的元素都可以有文本内容和属性。
还是通过一个例子来讲述:
<书架>
<书>
<书名>Java</书名>
<作者>张三</作者>
<售价>39.00元</售价>
</书>
<书>
<书名>JavaScrip</书名>
<作者>李四</作者>
<售价>28.00元</售价>
</书>
</书架>
<书架>
<书>
<书名> </书名>
<作者> </作者>
<售价> </售价>
</书>
 </书架>
</书架>
XML的语法规则很简单,且很有逻辑。这些规则很容易学习,也很容易使用。
l 所有的XML元素都必须有一个关闭标签
l XML标签对大小写敏感
l 3、XML必须正确嵌套
l 4、XML文档必须有根元素
l 5、XML属性值必须加引号
l 6、实体引用
l 7、在XML中,空格会被保留
l 8、XML 以LF存储换行
三、格式特性
1、结合
标准通用标记语言、超文本标记语言是XML的先驱。XML结合了标准通用标记语言和HTML的优点并消除其缺点。XML仍然被认为是一种标准通用标记语言。比标准通用标记语言要简单,但能实现标准通用标记语言的大部分的功能。1996年的夏天,Sun Microssystem的John Bosak开始开发W3C SGML工作组(现在称为XML工作组)。他们的目标是创建一种标准通用标记语言,使其在Web中,既能利用标准通用标记语言的长处,又保留html的简单性。现在目标基本达到。
XML的简单使其易于在任何应用程序中读写数据,这使XML很快成为数据交换的唯一公共语言,虽然不同的应用软件也支持其它的数据交换格式,但不久之后他们都将支持XML,那就意味着程序可以更容易的与Windows, Mac OS, Linux以及其他平台下产生的信息结合,然后可以很容易加载XML数据到程序中并分析它,并以XML格式输出结果。
2、友好
为了使得标准通用标记语言显得用户友好,它重新定义了标准通用标记语言的一些内部值和参数,去掉了大量的很少用到的功能,这些繁杂的功能使得标准通用标记语言在设计网站时显得复杂化。它保留了标准通用标记语言的结构化功能,这样就使得网站设计者可以定义自己的文档类型,它同时也推出一种新型文档类型,使得开发者也可以不必定义文档类型。
四、应用发展
作为互联网的新技术,XML的应用非常广泛,可以说XML已经渗透到了互联网的各个角落。虽然人们对XML的某些技术标准尚有争议(也许这就是许多标准迟迟不能推出的原因),但是人们已经普遍认识到XML的作用和巨大潜力,并将XML应用到互联网的各个方面。
考察现在的XML应用,可以大致将它们分为:电子商务领域、网络出版、移动通信等几类。
1、电子商务
电子商务是一项涉及全球的全新业务和全新服务,是网络化的新型经济活动,它不仅仅是基于互联网的新型交易或流通方式,而基于互联网、广播电视网和电信网络等电子信息网络的生产、流通和消费活动。
随着比较购物和个性化要求以及企业-企业类型电子商务的出现,人们要求计算机能够理解数据的语义,而且能够将数据和表现的分离开来,这时HTML就显得力不从心。XML弥补了HTML的巨大缺陷,成为电子商务中的核心技术。随着XML标准体系的成熟和技术的发展,已经出现了相当多的客户化工具,尤其是可视化工具的出现,使得人们可以无须了解XML的细节就能够编写出需要的XML文档,使得XML应用在电子商务中成为可能。而浏览器对XML越来越强的支持能力,对XML应用起到了巨大的促进作用。
当前已经出现了很多基于XML的针对企业对企业电子商务的标准或旨在形成相应标准的计划,包括Microsoft的BizTalk、UN/CEFACT小组和OASIS共同发起的ebXML计划、Commerce Net发起的eCo计划、Rosetta Net的PIP(Partner Interface Process)和Rosetta Net应用网络标准、XML-EDI、Commerce One的xCBL标准、Ariba的cXML等。
2、网络出版
网络出版,又称互联网出版,是指互联网信息服务提供者将自己创作或他人创作的作品经过选择和编辑加工,登载在互联网上或者通过互联网发送到用户端,供公众浏览、阅读、使用或者下载的在线传播行为。
随着互联网的飞速发展,互联网已经成为继报刊、电台、电视台之后的一种新型媒体。在1998年5月举行的联合国新闻委员会年会上,互联网这一新型媒体被正式冠以“第四媒体”的称号。网络出版自从出现以来,用于信息发布的主要是HTML技术,但是这种方式在跨媒体出版时遇到了极大的困难,人们需要为不同媒体制作不同版本。XML的内容与显示分离的特点,人们可以一次性制作内容,配以不同的样式单,实现一次制作多次出版。
为了满足不同领域和显示设备的需要,人们利用XML定义了多个面向显示的语言,包XHTML(Extensible Hyper Text Markup Language,用XML重新定义的HTML)、面向WEB图形的VML(Vector Markup Language)、PGML(Precision Graphics Markup Language)和SVG(Scalable Vector Graphi)、面向多媒体的SMIL(Synchronized Multimedia Integration Language)、面向电子书和电子报纸的OEB(Open eBook Structure Specification)、面向手持设备的WML(Wireless Markup Language)和HDML(Handheld Device Markup Language)等。可以说XML已经成为网络出版的重要工具,并将发挥日益重要的作用。
3、移动通信
移动通信是移动体之间的通信,或移动体与固定体之间的通信。移动体可以是人,也可以是汽车、火车、轮船、收音机等在移动状态中的物体。移动通信系统由:空间系统和地面系统两部分组成。
移动通信系统从20世纪80年代诞生以来,到20##年将大体经过5代的发展历程,而且到20##年,将从第3代过渡到第4代(4G)。到4G,除蜂窝电话系统外,宽带无线接入系统、毫米波LAN、智能传输系统(ITS)和同温层平台(HAPS)系统将投入使用。未来几代移动通信系统最明显的趋势是要求高数据速率、高机动性和无缝隙漫游。实现这些要求在技术上将面临更大的挑战。此外,系统性能(如蜂窝规模和传输速率)在很大程度上将取决于频率的高低。考虑到这些技术问题,有的系统将侧重提供高数据速率,有的系统将侧重增强机动性或扩大覆盖范围。
为了满足人们随时随地与互联网连接的需要,Phone.com联合了Nokia、Ericsson、Motorola在1997年6月建立了WAP论坛,旨在利用已有的互联网技术和标准,为移动设备连接互联网建立全球性的统一规范。在1998年5月,推出了WAP规范1.0版。并于1999年11月发布最新的1.2版。WAP规范包括WAP编程模型、无线置标语言WML、微浏览器规范、轻量级协议栈、无线电话应用(WTA)框架、WAP网关几个组件。其中WML是利用XML定义的专为手持设备的置标语言。另外W3C也定义了一个基于XML的手持设备置标语言HDML,WML和HDML非常类似,因为WML脱胎于HDML,可以说根在HDML,而花开WML。需要指出的是,虽然人们在提到WAP时首先想到的是手机上网,但掌上电脑等手持设备的上网也可以使用WAP。
五、未来前景
XML自从出现以来,一直受到业界的广泛关注。自从1998年2月成为推荐标准后,许多厂商加强了对它的支持力度,包括Microsoft、IBM、ORACLE、SUN等,它们都推出了支持XML的产品或改造原有的产品支持XML。W3C也一直在致力于完善XML的标准体系。然而由于XML的复杂性和灵活性,加上工具的相对缺乏,增加了XML使用的难度。因此,XML很难在短期内完全替代HTML,成为互联网的主角。另外,由于XML是元置标语言,任何个人、公司和组织都可以利用它定义新的标准,这些标准间的通信成为了巨大的问题,因此人们在各个领域形成一些标准化组织以统一这些标准,但是这些努力并不一定能够形成理想的结果。无论如何,XML的出现为互联网的发展提供了新的动力,终将成为互联网上全新的开发平台。它促使了新的类型的软件和硬件的形成和发展,而这些发展又将反过来促进XML的发展。
从前面对XML技术简要介绍中,可以了解到,HTML只适应于显示结构较为简单内容比较单一的Web文件,然而随着标准化Java应用的普及和发展,人们越来越感觉到有必要开发一种标准的、可扩展的和结构化的语言。XML的出现正是顺应了Web技术发展的这些要求,因此它不仅具有很大的发展潜力,而且也必将反过来一步促进Web技术和Java技术的发展。
XML仍在不断改善,与XML相关的技术仍在定制之中。XML需要强大的新工具用于在文档中显示丰富复杂的数据,XML会改革终端用户在网上的行为,这有助于许多商业应该的实现。并且,XML作为一个数据标准,会开创互联网上众多新用途。
XML虽然获得了极大的支持,但是它还有很长的路要走。首先,XML的规则只是迈出了第一步,还有许多技术细节没有解决。其次,现在虽然出现了一些XML工具和应用,但是其市场反应还有待进一步观察。另外如何让更多的人迅速学会使用XML,并利用它进行开发,进而促进XML的应用也是一个问题。因此XML的出现和迅猛发展并不意味着HTML即将退出互联网舞台,由于HTML的易学易用和非常多的工具支持,HTML将在较长的时间里继续在Web舞台上充当主角。但是如果用户想超越HTML的范围,XML将是最佳的选择。
另外,由于XML是用于定义语言的元语言,任何个人、公司和组织都可以利用它来定义自己的置标语言(通过DTD或schema表示),这虽然是XML的魅力和灵活性之所在,但同时也是XML的最大问题之所在。如果每个人、公司和组织都定义了自己的置标语言,它们之间的通信就会出现困难。因此在一些领域先后出现了一些标准化组织,它们的任务就是规范本领域的置标语言,形成统一的标准,使得在本领域内的通讯成为可能。但在标准推出并得到广泛认可之前,各自为政的局面将继续下去。更糟糕的是,由于对应用的理解不一致和商业利益等原因,同一个领域也许还有多个标准化组织,它们形成的置标语言并不完全兼容,使得采取不同标准的计算机仍然难以通信。
无论如何,XML的出现使互联网跨入了一个新的阶段,它将成为因特网领域中一个重要的开发平台。XML的诞生已经而且将继续促使全新种类的应用程序的产生,而这些新的应用程序又将需要新的软件和硬件工具。可以预测,无论是在软件还是硬件上,XML都将开辟一系列的新市场,促成互联网上新的革命。
XML未来必将一片长红。
第二篇:学习心得
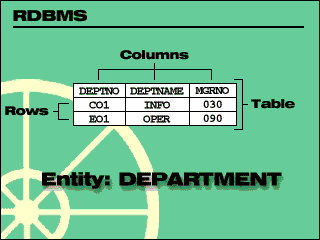
`1. A database management system provides a set of integrated data management services or tools which are used to maintain and manage logical groupings of data or information.
In this branch of mathematics, a table is called a relation.
2. Codd's original theory was based on 12 principles.
(1)The first is that all data in an RDBMS is stored in tables.
(2)Another principle is that you need a language to retrieve or manipulate data in these tables. This language is known as SQL and is part of the relational theory.
3. A table consists of columns and rows. Columns are the attributes of the entity. They are the same for every particular instance of the entity.
Every particular instance of the entity is a row. Rows are not usually stored in any particular order.
There is only one value at every row and column position in a table. This means that all data values are atomic.
4. There must be some way to identify uniquely just one instance or row of a table in order to manipulate the data in it. The unique key will allow you to do just that.
5. There are two terms you may hear to describe SQL. The first is non-navigational. This means that you only need to tell DB2, through SQL, what data you want. You do not need to specify how DB2 is to get that data. By using the optimizer, DB2 determines the best access path. For example, it decides whether to use an index to retrieve data.
SQL is also a non-procedural language. A procedural language is a programming language such as C or COBOL. SQL is not a programming language. It does not do looping or go through extensive if-then-else steps one record at a time. SQL handles a set of records in a table and can be embedded into a programming language to take advantage of the capacity of the language to carry out procedural logic on that data.
6. Data Manipulation Language (DML) allows you to retrieve and manipulate data. SELECT is your basic read statement. Both SELECT and UPDATE work at the column level. INSERT and DELETE function at the row level.
Data Definition Language (DDL) allows you to CREATE and maintain the physical data structures or objects in your database. You CREATE a table or index. The ALTER statement allows you to add a column to the end of a table. If you no longer need an object, you can simply DROP that object.
Control Language provides the control statements that govern data security. You must be authorized to use various objects in DB2. You need to be granted the ability to SELECT, UPDATE, INSERT, or DELETE against a table and to CREATE a table. If you no longer need these privileges, they can be revoked.

第一部分: db2规划
第一章 db2产品
1. DB2 PE 拥有 DB2 Workgroup Server Edition 的所有功能部件,不过有一个例外:远程客户机无法连接到运行着该 DB2 版本的数据库上。(但是,带有控制中心(Control Center)的工作站可以连接到这些数据库,以执行远程管理。)因为―这个 DB2 到底还是 DB2‖,所以那些针对 DB2 PE 而开发的应用程序都将能够在 DB2 的任何其它版本上运行。您可以使用 DB2 PE 开发 DB2 应用程序,然后再将它们用于生产环境。
2. DB2 Workgroup Server Edition(DB2 WSE)是一个功能齐全的、支持 Web 的客户机/服务器 RDBMS。DB2 WSE 提供了一种低价位的入门级服务器,它主要针对小型企业和部门计算。它在功能上与 DB2 Enterprise Server Edition 几乎完全相当,只不过它没有集成的大型机连通性(通过 DB2 Connect 组件),而且它的可扩展性以及功能部件很有限(例如,DB2 WSE 不支持 64 位计算或 DB2 数据链接文件管理器(DB2 Data Links File Manager))。正如前面提到的,针对 DB2 任何一个版本编写的应用程序可透明地移植到任何分布式平台的另一个版本上。在 UNIX、Linux 和 Windows 环境中,您可以在最多为四个处理器的对称多处理(symmetric multiprocessing,SMP)机器上安装 DB2 WSE。DB2 WSE 是根据使用并发(有时称为能力定价)或注册用户选项的客户机到服务器模型发放许可证的。DB2 WSE 的许可证发放选项不允许外部基于 Web 的使用;如果您想通过 Web 使用针对 SMB 的 DB2 版本,那么您应该考虑 DB2 Workgroup Unlimited Server Edition(DB2 WSUE)。DB2 WSE 可用于在公司防火墙后从内部进行 Web 访问。在这种情况中,您必须能够计算正通过公司内部网访问 DB2 服务器的用户数。
3. DB2 Workgroup Server Unlimited Edition(DB2 WSUE)从本质上说是 DB2 WSE,只是许可证的条款不同。如果用户需要通过因特网和内部网提供 DB2 数据,但不需要 DB2 Enterprise Server Edition(DB2 ESE)的附加功能、特性和优点,那么他们通常就可以考虑 DB2 的这个版本。DB2 WSUE 不能创建 64 位实例、未提供连接集中器并且没有包含 DB2 ESE 所具有的集成 DB2 Connect 组件。
4. 在 Windows XP 上运行 DB2 ESE V8 时不可用于生产目的,但允许在该 OS 上进行用户验收测试、测试以及应用程序开发。这不是 DB2 的限制:Microsoft 限制了其 Windows 服务器产品的单用户版本可以处理的并发连接数。DB2 ESE 包含 DB2 WSE 提供的所有功能;另外,它还包含 DB2 Connect 组件(该组件使您能够连接到基于 iSeries 和 zSeries 的 DB2 数据库,以及象 CICS、VSAM 和 IMS 之类的非数据库主机资源)。在 DB2 V8 中,每个运行 DB2 ESE 的服务器被许可可以有五个注册用户连接到基于主机的数据源。如果您需要额外连接,那么应该购买单独的 DB2 Connect 服务器许可证和用户权利。DB2 ESE 是按照每个处理器发放许可证的,它可以基于单个 SMP 机器的多个处理器安装,也可以安装到多台机器上。由于 DB2 ESE 拥有数据库分区功能部件(database partitioning feature,DPF),所以它能够在单个服务器内、跨多个数据库服务器(所有的服务器都必须运行在相同的操作系统上)或在该机器以外的大型 SMP 机器内对数据分区。您可以将 DPF 作为 DB2 ESE 处理器许可证的一部分购买。有了 DPF,数据库大小就只受限于您拥有的计算机数。
5. DB2 提供了用于与 DB2 服务器通信的客户机。DB2 客户机有三种类型:DB2 运行时
客户机(DB2 Runtime Client):这类客户机为运行各种平台的工作站提供了访问 DB2 数据库的能力。它只提供基本连通性 — 不多不少刚刚好。如果您要建立到远程 DB2 服务器或 DB2 连接网关(Connect Gateway)(它帮助您访问类似 DB2 for z/OS 的大型机或主机系统上的 DB2)的连通性,那么您至少必须使用这个客户机。当然,您可以使用任何客户机进行连接。DB2 管理客户机(DB2 Administration Client):这类客户机为各种平台的工作站提供了通过控制中心或配置助手(Configuration Assistant)访问并管理 DB2 数据库的能力。DB2 管理客户机具有 DB2 运行时客户机的所有功能,并且还包含所有 DB2 管理工具、文档以及对瘦客户机的支持。它还提供了管理 z/OS 和 IMS 子系统的能力(如果您有 DB2 Connect)。DB2 应用程序开发客户机(DB2 Application Development Client):这类客户机提供了开发访问 DB2 服务器的应用程序所需的工具和环境。您可以使用 DB2 应用程序开发客户机来构建和运行 DB2 应用程序。当然,由于这是 DB2 客户机,所以它还向用户提供了连通性功能。
6. DB2 Extender 可以让数据库应用程序除了处理传统的数字和字符数据以外,
还可以处理图像、XML、视频、声音、空间对象、复杂文档以及更多的数据类型。使用扩展器,您可以将所有这些类型的数据存入数据库,并利用 SQL(该语言用于与关系数据库通信)来处理它们。XML Extender:DB2 的 XML Extender 提供了新的数据类型,它们允许您在 DB2 数据库中存储 XML 文档,该扩展器还添加了帮助您在数据库内处理这些 XML 文档的功能。DB2 Net Search Extender:这个扩展器对那些需要快速执行数据库信息搜索的企业提供了帮助。您很可能会看到一些因特网应用程序在使用该扩展器,这些应用程序在搜索大型索引时需要卓越的搜索性能以及并发查询的可伸缩性。所以,如果您需要高速的内存搜索,那么这个扩展器很适合您。DB2 Spatial
Extender:该扩展器允许您在 DB2 中存储、管理和分析空间数据(即,关于地理特征的位置信息),以及传统的文本和数字数据。有了这种能力,您就可以生成、分析和利用关于地理特征的空间信息,例如办公楼的位置或洪水区域的范围。Text、Audio、Image 和 Video(TAIV)Extender:这些扩展器允许您将关系数据库扩展成可以使用象文本、歌曲、图片和电影那样非传统的数据格式。
7. 数据链接允许您管理驻留在数据库之外的文件,就好像逻辑上它们位于数据库内。数据链接
保证了对这些外部文件的参照完整性、提供了对它们的增强访问控制并支持事务性环境中的自动且协调的备份和恢复能力(对于数据管理是至关重要的)。
8. 在许多大型组织中,大量数据是由 DB2 for AS/400、DB2 for MVS/ESA、DB2 for z/OS
或 DB2 for VSE & VM 管理的。运行在任何受支持的 DB2 分布式平台上的应用程序都可以透明地使用这些数据,就好像本地数据库服务器在管理它们。您还可以使用各种各样的现成或定制开发的带有 DB2 Connect 及其相关工具的数据库应用程序。DB2 Connect 提供了从 Windows、Linux 和 UNIX 平台到大型机和中等规模数据库的连通性。
第二章 db2工具
背景:DB2 有两类工具:免费工具和可单独购买的附加工具。免费工具是 DB2 安装的一部分,可以从控制中心、配置助手启动,也可以单独地启动(稍后您将在本教程中了解这些信息)。可以使用一个单独的工具集来帮助简化 DBA 的任务:管理和恢复数据并使之可访问。 有五个用于 DB2 分发版的工具可以单独购买:
? DB2 恢复专家(DB2 Recovery Expert):使用大量的诊断和 SMART(自我管
理和资源调优)技术,从而提供了简化、全面以及自动的恢复,以使故障时间缩短到最小。
? DB2 性能专家(DB2 Performance Expert):将性能监控、报告、缓冲池分析
以及性能仓库功能集成在一个工具中。它提供了单一的系统概述,以一致的方式监控许多不同平台上的所有子系统和实例。
?
? DB2 高性能卸装(DB2 High Performance Unload):从 DB2 上快速且高效地卸装和抽取数据,以进行跨企业系统的数据移动。 DB2 Web 查询工具(DB2 Web Query Tool):安全且同时将所有用户直接连接
到多个企业数据库,而无须考虑数据库大小、硬件、操作系统或位置。这个工具还支持 Informix Dynamic Server 9.x。
? DB2 表编辑器(DB2 Table Editor):快速且轻松地访问、更新和删除跨多个 DB2
数据库平台的数据。这个工具还支持 Informix Dynamic Server 9.x。
1. 与 DB2 包含在一起的工具(这里称为 DB2 工具;不要将它们与附加的(add-on)DB2
工具相混淆,附加工具是单独提供的)对大多数 DB2 功能部件提供了一整套省时和减少出错机会的图形界面。DB2 工具是 DB2 管理客户机的一部分。在安装 DB2 服务器时,实际上同时还安装了 DB2 管理客户机的所有组件(尽管大多数人没有意识到)。DB2 工具实际上被分成两类:控制中心(CC)和配置助手(CA)。控制中心主要用于管理 DB2 服务器,而配置助手用于设置客户机/服务器通信和维护注册表变量(尽管它可以完成更多任务;过一会儿您会了解有关 CA 的更多信息)。另外,还有其它几个集成在一起的中心,可以从控制中心启动它们。
2. 在任何 DB2 工具中(在可应用时)您都应该能找到大约六个基本功能部件:向导、Generate
DDL、Show SQL/Show Command、Show Related、过滤器(Filter)和 Help。 所有 DB2 产品中都有 DB2 命令行处理器(DB2 Command Line Processor,DB2 CLP),它是一个应用程序,可以用来运行 DB2 命令、操作系统命令或 SQL 语句。我们将介绍 DB2 中两种不同的处理器:DB2 命令行处理器(DB2 CLP)和 DB2 命令窗口(DB2 Command Window,DB2 CW)。
更改 DB2 处理器选项的方法有两种。通过设置DB2OPTIONS注册表变量(必须大写),或在输入 DB2 命令时指定命令行标志,您可以设置会话的命令选项。后一种方法将覆盖在注册表级别上进行的任何设置。要打开一个选项,用减号(-)作为相应选项字母的前缀;例如,要打开自动提交功能(是缺省状态),输入db2 –c create…。要关闭一个选项,在该选项字母的前后各加一个减号(-c-),或用一个加号(+)作为其前缀。缺省情况下,自动提交功能被设置成(-c)。这个选项指定是否将单独处理每个语句。在打开该选项时,就会自动提交或回滚每个语句。如果一个语句成功执行了,那么就会提交该语句以及在该语句之前发出的并且其自动提交被设置成关闭(+c 或 -c-)的所有成功语句。但是,如果该语句执行失败,那么就会回滚该语句以及在该语句之前发出的且其自动提交被设置成关闭的所有成功语句。如果该语句的自动提交被设置成关闭,那么您必须显式地发出提交或回滚命令。-f是引用某一文件作为执行脚本。
第三章: 控制中心
1. 控制中心(CC)是 DB2 服务器的中心管理工具。您可以使用 CC 来管理系统、DB2 实例、DB2 z/OS 子系统、IMS 数据源、数据库、数据库对象等等。通过 CC,您还可以打开其它中心和工具以帮助您优化查询、调度作业以及编写和保存脚本;执行数据仓库任务;创建存储过程和用户定义函数;使用 DB2 命令;以及监控 DB2 系统的―健康‖状况。控制中心依赖数据库管理服务器(Database Administration Server,DAS)。DAS 帮助控制中心调度作业以针对数据库服务器运行作用、管理远程数据库服务器上的对象以及做更多事情。
使用 DB2 复制中心(DB2 RC)来管理 DB2 数据库和其它关系数据库(DB2 或非 DB2)之间的复制。通过 DB2 RC,您可以定义复制环境、将指定的更改从一个位置应用到另一个位置以及使两个位置上的数据同步。
使用卫星管理中心(DB2 SAC)来设置和管理执行相同业务功能的一组 DB2 服务器。这些服务器称为卫星,它们都运行相同的应用程序,并拥有相同的 DB2 配置(数据库定义)来支持那个应用程序。
可以使用 DB2 命令中心来执行 DB2 命令和 SQL 语句;执行 MVS 控制台命令;使用命令脚本以及查看 SQL 语句的存取方案的图形表示。DB2 命令中心上不同的选项卡提供了不同的功能:
? 在 Interactive 选项卡上,您可以执行 SQL 语句或 DB2 命令。(在命令中心输入 DB2 命令类似于以交互式 DB2 CLP 方式进行工作:您不必使用 前缀。)要运行您输入的 DB2 命令或语句,单击齿轮(位于该工具右上角)或按下 Ctrl+Enter。通过在命令前添加感叹号(),您还可以从 DB2 命令中心输入特定于操作系统的命令。例如,要列出当前目录的内容,输入 。
? 在 Script 选项卡上,您可以依次执行命令、创建并保存脚本、将保存的脚本存储到任务中心(Task Center,在其中,您可以调度脚本使之在特定时间运行 — 下页会有这方面的更多信息)、运行现有脚本或调度任务。
?
? 在 Query Results 选项卡上,您可以看到查询的结果。还可以保存查询的结果或编辑表的内容。(上图显示的就是这个页面。) 在 Access Plan 选项卡上,您可以看到您在 Interactive 页面或 Script 页面上指定的任何可说明语句的存取方案。当 DB2 编译 SQL 语句时,它会生成存取方案。您可以使用该信息来调优查询以获得更佳的性能。如果您指定了多个语句,那么只为第一个语句创建存取方案。
DB2 命令中心还附带了 SQL 助手(SQL Assist)工具(在下一节中我将详细谈论它)。要调用 SQL 助手工具,请单击 Interactive 页面上的 SQL Assist 按钮。DB2 命令中心也可以用基于 Web 的方式运行。在这种方式中,任何 Web 浏览器、PDA、移动设备或可以访问因特网的其它普及设备都可以对 DB2 服务器执行命令。这有助于 DBA 与他们的 DB2 系统保持持续的联系。在 Web 方式中,命令中心没有可视化解释(Visual Explain)或 SQL 助手功能部件。
使用 DB2 任务中心(DB2 TC)来运行任务(可以立即执行或根据调度执行),并告知所完成任务的状态。DB2 TC 是 DB2 V7 脚本中心(Script Center)的替代工具,它包含后者的所有功能,以及更多其它功能。任务是一个脚本,它伴有相关的失败或成功条件、调度和通知。您可以在 DB2 TC 内创建任务、在其它工具内创建脚本并将它保存到 DB2 TC、导入现有脚本或将来自 DB2 对话框或向导(例如 Load 向导)的选项保存为脚本。脚本可以包含 DB2、SQL 或操作系统命令。对于每个任务,您可以:
?
?
?
? 调度该任务 指定成功和失败的条件 指定当该任务成功完成或当它失败时将执行的操作 指定当该任务成功完成或当它失败时将通知的电子邮件地址(包括寻呼机) 使用 DB2 运行状况中心(DB2 HC)来监控 DB2 环境的状态,并对它作任何必要更改。当您使用 DB2 时,监控程序持续跟踪一组健康指示器。如果健康指示器的当前值超出了它的警告和警报阈值所定义的可接受操作范围,那么健康监控程序就生成健康警报。DB2 附带一组预定义的阈值,您可以定制这些阈值。根据 DB2 实例的配置,当健康监控程序生成警告时,会发生下列某些操作或全部操作:
?
?
?
? 在管理通知日志记录中编写一项,您可以通过日志(Journal)进行阅读(详细信息,请参阅下一页)。 DB2 GUI Tool 窗口的右下角出现运行状况中心状态―指示灯‖。 执行脚本或任务。 电子邮件或寻呼机消息被发送到为这个实例指定的联系人。
DB2 日志显示有关任务、数据库操作和运行、控制中心操作、消息以及警报的历史信息。该工具有四个选项卡,每个都向 DBA 提供有价值的信息:
? Task History:显示以前所执行任务的结果。您可以使用该信息来估算将来的任务要
运行多长时间。在该页面中,每执行一次任务就占一行。与此不同的是,任务中心里,每个任务只有一行,而不管该任务执行了多少次。
对于每次执行完毕的任务,您可以执行以下操作:
o 查看执行结果
o 查看被执行的任务
o 编辑被执行的任务
o 查看任务执行的统计信息
o 从日志删除任务执行对象
? Database History:显示来自恢复历史记录文件的信息。在执行了各类操作(包括:
备份、恢复、前滚、装入以及重组)后就更新这个文件。如果您需要恢复数据库或表空间,那么这个信息会很有用。
?
? Messages:显示以前从控制中心和其它 GUI 工具发出的消息。 Notification Log:显示来自管理通知日志记录的信息。
DB2 许可证中心显示了安装在您系统上的 DB2 产品的 DB2 许可证状态和使用信息。
联系人列表,如果您在运行状况中心定义的阈值已经被超出,或者正接近警戒状态,那么系统将(通过电子邮件或寻呼机)向这些联系人发出警告。
使用信息中心以查找有关任务、参考资料、故障查找、样本程序以及相关网站的信息。
第四章 配置助手
配置助手(CA)是 DB2 V8 中的一个新工具,它让您可以维护一个数据库列表,您的应用程序可以连接、管理和控制这些数据库。
Each database that you wish to access from the CA must be cataloged at a DB2 client before you can work with it. Use the CA to configure and maintain database objects that you or your applications will be using. The Add Database wizard will help you catalog nodes and databases, while shielding you from the inherent complexities of these tasks.
通过 CA,您可以使用现有的数据库、添加新的数据库、绑定应用程序、设置客户机数据库管理器配置参数以及导入和导出配置概要文件。
第五章 其他工具
您可以利用的其它 DB2 工具还有很多,它们会使您的工作更轻松。这些工具是作为控制中心或配置助手中独立的工具免费提供的。不要将这些工具和可单独获得的 DB2 附加工具相混淆。 与三四章相比,只是这里的工具用的不多,而三四章中工具比较常用罢了。
可视化说明让您将用于已解释的 SQL 语句的存取方案看作一张图表。你可以使用从图表上获取的信息来调优您的 SQL 查询,以获得更佳的性能。可视化说明还让您动态地说明 SQL 语句并查看生成的存取方案图。
DB2 DC 是一个快速的迭代开发环境,用于构建存储过程(SP)、用户定义函数(UDF)、结构化的数据类型以及更多其它事情。
第六章 数据仓库
包含运作数据(运行业务日常交易的数据)的系统包含了业务分析员可用来更好地理解业务是如何运作的信息。例如,他们可以看到一年中的哪些时候在哪些地区销售了哪些产品。这有助于识别异常情况,或者规划未来的销售。
但是,如果分析员直接访问运作数据,那么会产生几个问题:
? 他们可能没有查询运作数据库的专门知识。例如,查询 IMS 数据库需要一个使用专门
类型的数据操作语言的应用程序。一般而言,那些拥有查询运作数据库专门技术的程序员都全职维护数据库及其应用程序。
? 性能对于许多运作数据库(例如银行的数据库)是关键。系统无法处理用户对运作数据
存储所进行的―特别的‖查询。想象一下您正在因特网上处理您的银行业务并支付帐单。当您按下 OK 按钮时,处理付款通常只要几秒钟。现在,请考虑银行分析员正在设法搞清楚如何从现有的客户群赚取更多的钱。该分析员运行了一个查询,它非常复杂,以致于现在完成您的事务要花大约 30 秒时间。很显然,这个性能时间是不能接受的(而且分析员所幻想的新费用也是不可能的)。由于这个原因,一般将运作数据存储和报告数据存储(包括 OLAP 数据库)分开。
但是,在近几年中,报告数据存储已经逐渐成为伪操作(pseudo-operational)数据存储而且很流行。这样的存储称为操作数据存储(operation data store)(ODS)。例如,请考虑电信业。ODS 在这些公司中很流行,因为它们尽可能快地设法识别欺骗性的费用。DB2 是非常适合于运作和报告工作负载的少数几个数据库之一。
? 运作数据通常并不是业务分析员使用的最佳格式。例如,对于分析员来说,根据产品、
地区和季节而汇总的销售数据比原始数据有用得多。
数据仓库解决了这些问题。在数据仓库中,您创建信息化的数据(informational data)(该数据抽取自运作数据,随后对其进行转换和清理,以用于最终用户的决策)存储。例如,数据仓库工具可能会复制运作数据库中的所有销售数据、执行计算以汇总数据以及将汇总好的数据写到与运作数据分开的数据库。最终用户可以查询这个分开的数据库(数据仓库),而不会影响运作数据库。
The Data Warehouse Center, included at no additional cost with DB2, provides SQL-based extract, transform, and load (ETL) capabilities to move and transform data.
对于全能的数据仓库项目,IBM 提供了 DB2 数据仓库管理器(DB2 Data Warehouse Manager,DB2 DWM)。DB2 DWM 实际上是一个由四个产品组成的套件:
?
?
?
? 数据仓库中心(Data Warehouse Center),附带有用于 ETL 的增强和扩展的 SQL 转换功能、更多支持所有受 DB2 支持的操作系统的代理等等 信息目录中心(Information Catalog Center)是最终用户级元数据资源库 查询巡视器(Query Patroller)是一个功能强大的主动查询管理器 查询管理实用程序(Query Management Facility,QMF),一个用于 Windows
的查询报告生成工具
数据仓库中心提供:
?
?
? 注册和访问异类数据源 数据抽取和转换步骤的定义 填充仓库和仓库管理过程的自动化
元数据是描述数据的数据。例如,元数据可以描述数据源,或者描述数据是如何组装在一起的。
第七章 OLAP
OLAP 指的是在线分析处理(Online Analytical Processing)。该技术的特点是可以轻松地在聚合信息和派生信息之间导航,从而以一致的、快如思想的(speed-of-thought)的响应时间来提供结果。
使用 OLAP 技术的工具(例如 DB2)允许您就您的业务询问直观和复杂的特殊问题,例如―我的主导产品第三季度在整个东南地区的收益如何?‖这样的问题需要多个方面的数据,例如时间、地区和产品。这些方面被称为维(dimension)。 立方体中各轴线的交汇点称为事实(fact),每个交汇点都代表一个有关业务的事实。
OLAP 的种类有很多,最常见的是多维 OLAP(MOLAP)和关系 OLAP(ROLAP)。DB2 可以处理这两种 OLAP。MOLAP 是由 DB2 OLAP Server 产品处理的,而 ROLAP 是由 DB2 中的本机数据存储处理的。
OLAP 服务器处理多维请求,这些请求要求计算、合并多维数据库和/或关系数据库的信息,以及从多维数据库和/或关系数据库检索信息。
MOLAP 的未来发展趋势还在争论中。许多用户喜欢 MOLAP,因为它通常被认为是解答分析性问题的比较快的 OLAP 方法。MOLAP 的缺点是它需要一个独立的数据存储引擎(多维引擎)、独立的管理方法和独立的查询语言及 API。 DB2 OLAP Server(它是 Hyperion Essbase 服务器的重新包装)有自己独立于 DB2 的存储引擎,并且它还有自己的 API。同样,Microsoft 的分析服务产品(它们的 MOLAP 版本称为 MDX)有它自己的查询语言和管理问题。ROLAP 的支持者认为学习如何管理新的数据库引擎以及编写新的查询语言是一种负担,他们更愿意利用现有的 SQL 技能来进行 OLAP。T
第二部分 db2安全性
第一章 db2安全性
1. 数据库安全性计划应该定义:
?
?
?
?
?
? 允许谁访问实例和/或数据库 在何处和如何验证用户的密码 授予用户的权限级别 允许用户运行的命令 允许用户读和/或修改的数据 允许用户创建、修改和/或删除的数据库对象
2. DB2 中有三种主要机制允许 DBA 实现数据库安全性计划:认证、授权和特权(authentication, authorization, and privileges)。
当您试图访问 DB2 实例或数据库时,认证是您将碰到的第一项安全性功能。DB2 认证同底层操作系统的安全性功能密切合作来验证用户标识和密码。DB2 也可以与诸如 Kerberos 之类的安全性协议协作来对用户进行认证。
授权涉及确定用户和/或组可以执行的操作,以及他们能够访问的数据对象。用户是否能够执行高级数据库与实例管理操作,这是由指派给用户的权限决定的。DB2 内的五种不同权限级别是 SYSADM、SYSCTRL、SYSMAINT、DBADM 和 LOAD。
特权比权限更具粒度性,可以将其指派给用户和/或组。特权可以帮助定义用户能够创建或删除的对象。它们还定义了一些命令,用户可以使用这些命令来访问诸如表、视图、索引和包之类的对象。
3. 在考虑整个数据库环境的安全性时,十分重要的一点是要理解术语客户机、服务器、网关和主机。数据库环境经常包括几种不同的机器;必须在任何潜在的数据访问点处保护数据库。在处理 DB2 认证时,客户机、服务器、网关和主机的概念十分重要。
下面的这幅图演示了基本的客户机-服务器-主机配置。
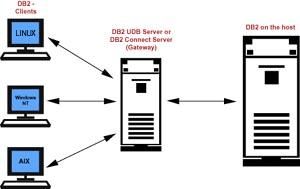
数据库服务器是指物理地存放数据库的机器(或分区数据库系统中的机器)。DB2 数据库客户机则是配置成针对服务器上的数据库进行查询的机器。这些客户机可以是本地的(即,它们可以驻留在与数据库服务器相同的物理机器上),也可以是远程的(即,它们可以驻留在独立的机器上)。
如果数据库驻留在大型机机器上,该机器运行诸如 AS/400(iSeries)或 OS/390(zSeries)之类的操作系统,那么它就称为主机或主机服务器。网关是指运行 DB2 Connect 产品的机器。DB2 客户机机器通过网关可以与驻留在主机机器上的 DB2 数据库连接。网关也称为 DB2 Connect Server。
第二章 db2认证
1. DB2 认证控制着数据库安全性计划的下列几个方面:
?
? 允许谁访问实例和/或数据库 在何处和如何验证用户的密码
不管什么时候发出 attach 或 connect 命令,DB2 都依靠底层操作系统安全性功能来完成上面的工作。attach 命令用于连接到 DB2 实例,而 connect 命令则用于连接到 DB2 实例内的数据库。还要了解catalog。
2. DB2 使用认证类型来确定在何处进行认证。举个例子来说吧,在客户机-服务器环境中,是由客户机机器还是由服务器机器来验证用户的标识和密码呢?在客户机-网关-主机环境中,是由客户机来验证标识和密码还是由主机来验证呢?

*这些设置只对 Windows 2000 操作系统有效。
3. 将认证设置成在数据库服务器上执行是通过在数据库管理器配置(Database Manager Configuration,DBM CFG)文件中使用 AUTHENTICATION 参数来实现的。记住,DBM CFG 文件是一个实例级配置文件。因而,AUTHENTICATION 参数会影响实例内的所有数据库。 将认证设置成在网关上进行是使用 catalog database 命令实现的。注:认证从不在网关本身上执行。在 DB2 V8 中,必须总是在客户机或主机数据库服务器上执行认证。
我们将把一台客户机配置成连接到服务器机器(DB2 分布式平台)上的数据库,而另一台客户机配置成连接到主机(如 DB2 for OS/390)上的数据库。(具体内容见教材)
Cataloging a remote database server from a Linux, UNIX, or Windows gateway is: performed on a Linux, UNIX, or Windows machine to open the catalogs in the DB2 database server and present a user with a list of all accessible tables in that database.
第三章 权限控制
1. DB2 权限控制数据库安全性计划的以下几方面:
?
?
?
? 授予用户的权限级别 允许用户运行的命令 允许用户读和/或修改的数据 允许用户创建、修改和/或删除的数据库对象
在 DB2 所提供的五种权限中,SYSADM、SYSCTRL 和 SYSMAINT 是实例级权限。 这意味着权限(作用的)范围包括实例级命令和对实例内的所有数据库所执行的命令。这些权限只能指派给某个组;可以通过 DBM CFG 文件来进行指派。
DBADM 和 LOAD 权限是为了某个特定的数据库而指定给某个用户或组的。可以用 GRANT 命令来显式地完成这一工作。
通过发出以下命令,用户可以确定他们具有哪些权限及数据库级别的特权:
db2 get authorizations
注:对组成员资格的任何引用都意味着已经在操作系统级别定义了用户和组名称。
2. DB2 中的 SYSADM 权限类似于 UNIX 上的 root 权限或 Windows 上的
Administrator 权限。对某个 DB2 实例具备 SYSADM 权限的用户能够对该实例、该实例内的任何数据库以及这些数据库内的任何对象发出任何 DB2 命令。他们还能够访问数据库内的数据,并能够授予或取消特权和权限。SYSADM 用户是唯一允许更新 DBM CFG 文件的用户。 SYSADM 权限是通过 DBM CFG 文件中的 SYSADM_GROUP 参数来控制的。在创建实例时,在 Windows 上,该参数被设置成 Administrator(虽然在您发出命令 db2 get dbm cfg 时该参数好象为空)。在 UNIX 上,该参数被设置成创建实例的主用户组。由于 SYSADM 用户是唯一允许更新 DBM CFG 的用户,因此他们也是唯一允许向其它组授予任何 SYS* 权限的用户。
记住,只有将实例停止然后重新启动,上面的更改才会生效。
3. 具有 SYSCTRL 权限的用户可以在实例内执行所有管理和维护命令。然而,与 SYSADM 用户不同的是,除非向他们授予了访问数据库内任何数据所需的特权,否则他们就不能访问这些数据。
SYSCTRL 用户可以对实例内的任何数据库执行的命令示例有:
?
?
?
?
?
?
db2start/db2stop db2 create/drop database db2 create/drop tablespace db2 backup/restore/rollforward database db2 runstats (可以对任何表执行该命令) db2 update db cfg for database dbname
4. 具有 SYSMAINT 权限的用户可以发出的命令是具有 SYSCTRL 权限的用户所允许发出的命令的子集。SYSCTRL 用户只能执行与维护有关的任务。如:
?
?
?
? db2start/db2stop db2 backup/restore/rollforward database db2 runstats (可以对任何表执行该命令) db2 update db cfg for database dbname
注意:具有 SYSMAINT 权限的用户不能够创建或删除数据库或表空间。除非向他们授予了访问数据库内任何数据所需的特权,否则他们也不能访问这些数据。
5.总的来说,DBADM 用户几乎能够完全控制数据库。但 DBADM 用户不能执行类似下面的维护或管理任务:
?
?
?
? drop database drop/create tablespace backup/restore database update db cfg for database db name
然而,他们却可以执行下列任务:
?
?
? db2 create/drop table db2 grant/revoke (任何特权) db2 runstats (任何表)
DBADM 用户还被自动授予数据库对象及其内容的全部特权。由于 DBADM 权限是一种数据库级权限,因此可以将它指派给用户和组。
6. LOAD 权限允许用户对表发出 LOAD 命令。在填充具有大量数据的表时,通常使用 LOAD 这种执行更快的命令来替代插入或导入命令。根据您希望执行的 LOAD 类型的不同,仅仅具有 LOAD 权限可能还是不够的。还可能需要对该表具有特定特权。
具有 LOAD 权限的用户可以运行下列命令:
?
?
?
?
?
?
? db2 quiesce tablespaces for table db2 list tablespaces db2 runstats (任何表) db2 load insert (必须对表具有插入特权) db2 load restart/terminate after load insert (必须对表具有插入特权) db2 load replace (必须对表具有插入和删除特权) db2 load restart/terminate after load replace (必须对表具有插入
和删除特权)
第四章 特权
1. 一般可以将特权归为两大类:数据库级特权和对象级特权,前者的作用范围覆盖数据库内的所有对象,而后者仅与特定对象有关。 可以授予用户的数据库级别特权有:
? ? ? ? ? ? ? ?
CREATETAB:用户可以在数据库内创建表。
BINDADD:用户可以使用 BIND 命令在数据库内创建包。 CONNECT:用户可以连接到数据库。
CREATE_NOT_FENCED:用户可以创建不受防护的、由用户定义的函数(UDF)。 IMPLICIT_SCHEMA:用户可以不使用 CREATE SCHEMA 命令而在数据库内隐式地创建模式。
LOAD:用户可以将数据装入到表中
QUIESCE_CONNECT:用户可以在数据库处于停顿状态时访问数据库。
CREATE_EXTERNAL_ROUTINE:用户可以创建一个过程,供应用程序和数据库的其他用户使用。
数据库对象包括表、视图、索引、模式和包。 下面的表汇总了这些特权。
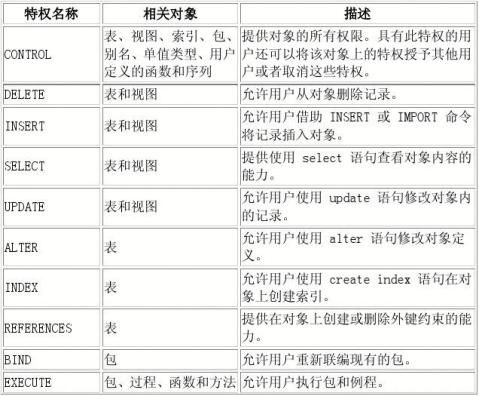

有关对象级特权的信息存放在系统目录视图中。视图名称是 syscat.tabauth、syscat.colauth、syscat.indexauth、syscat.schemaauth、
syscat.routineauth 和 syscat.packageauth。
2.通过使用 GRANT 和 REVOKE 命令,可以显式地向用户或组授予特权或取消这些特权。注:取消一个组的特权并不需要取消该组中的所有成员的这种特权。例如,取消 grp1 对表 lisac.org 的(除 CONTROL 以外的)全部特权可能会使用以下命令:
db2 revoke all on table lisac.org from group grp1
但是,用户 tst1(他是 grp1 的成员)将会仍然保持对该表的 select 特权,因为他或她曾经被直接授予该项特权。
3.下表汇总了一些命令,这些命令会导致数据库管理器隐式地授予特权。注:当所创建的对象被删除时,这些特权也会被隐式地取消。然而在显式取消更高级别特权时,这些特权却不会被取消。

*当用户创建数据库时,该用户就被隐式地授予了对该数据库的 DBADM 权限。与 DBADM 权限同时隐式授予的还有 CONNECT、CREATETAB、BINDADD、IMPLICIT_SCHEMA 和 CREATE_NOT_FENCED 这几种特权。即便取消了 DBADM 权限,用户仍将保持这些特权。 **PUBLIC 是一个特殊 DB2 组,这个组包括某个特定数据库的所有用户。与到目前为止我们所讨论过的其它组不同,并不需要在操作系统级别上定义 PUBLIC。缺省授予了 PUBLIC 几种特权。例如,该组被自动授予了对数据库的 CONNECT 特权和对目录表的 SELECT 特权。可以对 PUBLIC 组发出 GRANT 和 REVOKE 命令,如:
db2 grant select on table sysibm.systables to public
db2 revoke select on table sysibm.systables from public
4.间接特权:数据库管理器执行包(package)时能够间接获得特权。包含有一条或多条已经转换成某种格式的 SQL 语句,DB2 在内部使用这种格式来执行这些语句。换句话来说,包含有多条可执行格式的 SQL 语句。如果包内的所有语句都是静态的,那么用户将只需要包上的 EXECUTE 特权就能成功地执行包中的语句。
例如,假定 db2package1 执行下列静态 SQL 语句:
db2 select * from org
db2 insert into test values (1, 2, 3)
在这种情况下,具有对 db2package1 的 EXECUTE 特权的用户将被间接授予对表 org 的 SELECT 特权和对表 test 的 INSERT 特权。
第三部分 访问DB2 UDB数据
第一章 DB2数据库由什么组成
1. DB2 数据库实际上由一组对象组成。从用户的角度看,数据库是(希望)以某种方式相关的表的集合。
从数据库管理员(DBA — 就是您)的角度看,情况就比那稍稍复杂一点。实际的数据库包含许多下面列出的物理和逻辑对象:
?
?
? 表、视图、索引和模式 锁、触发器、存储过程和包 缓冲池、日志文件和表空间
在以上对象中,有些(如表或视图)帮助确定数据是如何组织的。另一些对象(如表空间)引用数据库的物理实现。剩下的一些对象(如缓冲池和其它内存对象)则仅处理如何管理数据库性能。
2. DB2 用逻辑和物理两种存储模型来处理数据。用户处理的实际数据位于表中。虽然表由列和行构成,但用户并不知道数据的物理表示。这种情况有时被称为数据的物理无关性。
表本身位于表空间中。表空间被用作数据库和包含实际表数据的容器对象之间的一层。表空间可包含多个表。
容器是物理存储设备。可以用目录名、设备名或文件名来标识它。一个容器分配给一个表空间。一个表空间可以跨越多个容器,这意味着您可以绕开操作系统的限制,这些限制可能会限定一个容器可以容纳的数据量。下图中说明了所有这些对象之间的关系。

3. 表、索引、长字段(有时称为二进制大对象或 BLOB)是在 DB2 数据库内创建的对象。这些对象被映射到表空间,而表空间本身则被映射到物理磁盘存储器。
表是一个无序的数据记录集。它由列和行构成,通常称之为记录。表可以是永久(基)表、临时(声明的)或临时(派生的)表。从 DBA 的角度看,为这些表对象中的每一个都分配了空间,但这些空间却在不同的表空间中。
索引是与单个表相关联的物理对象。索引用来在表中强制实施唯一性(也就是说,确保没有重复值),以及在检索信息时改进性能。不需要索引也能运行 SQL(Structured Query Language,结构化查询语言)语句;但如果您创建一些索引来加速查询处理的话,您的用户将会感激您的这一远见。
长字段(或 BLOB)是表内的一种数据类型。这种数据类型通常由非结构化数据(图像、文档和音频文件)构成,并且包含数量极大的信息。在表内存储这种数据会导致删除、插入和操作这些对象时的过度开销。所以并不直接将它们存储在表的行中,而是存储一个指针,这个指针链接到大型(Large)表空间(以前称为长字段(Long Field)表空间)中的位置。DBA 需要了解这种数据类型,这样才能创建合适的表空间来包含这些对象。
4. DB2 支持两种表空间:
?
? 系统管理的空间(System-Managed Space,SMS):这里,操作系统的文件系统管理器分配并管理空间,其中表是缺省表空间类型。 数据库管理的空间(Database-Managed Space,DMS):这里,数据库管理器
控制存储空间。这种表空间实质上是特殊用途文件系统的实现,旨在最好地满足数据库管理器的需要。
SMS 表空间需要的维护很少。然而,SMS 表空间提供的优化选项较少,并且性能也许不及 DMS 表空间。
5. 我们在这一章里介绍了许多基础知识。让我们小结一下所学的 DB2 数据库知识。
?
?
? 数据库是对象的集合,包括表、索引、视图和长对象。 这些对象存储于表空间中,后者由容器组成。 表空间可以由操作系统管理(SMS),或由 DB2 管理(DMS)。
? 主要根据性能和维护因素来决定使用哪种表空间。
第二章 创建第一个数据库
1.当您发出 CREATE DATABASE 命令时,DB2 创建了许多文件。这些文件包括日志文件、配置信息、历史文件和三个表空间。这三个表空间是:
?
?
? SYSCATSPACE:这是存放 DB2 系统目录的地方,系统目录跟踪所有与 DB2 对象相关的元数据。 TEMPSPACE1:DB2 放置中间结果的临时工作区。 USERSPACE1:缺省情况下所有用户对象(表和索引)所在的地方。
所有这些文件都位于您缺省驱动器上的 DB2 目录中。
重要事项:所有的容器在所有的数据库中都必须是唯一的;一个容器只能属于一个表空间。
第三章 对db2数据库编目
1. DB2 在创建数据库时自动对其编目。它在本地数据库目录中为数据库编制一项目录,并在系统数据库目录编制另一项目录。如果数据库是从远程客户机(或为从同一机器上的不同实例执行的客户机)创建,则还在客户机实例的系统数据库目录中创建一项。
那么,为什么必须要对数据库编目呢?因为如果没有这一信息,应用程序就无法连接到数据库!DB2 有多个目录用来访问数据库。这些目录允许 DB2 查找它知道的数据库,不管数据库在本地系统还是在远程系统。系统数据库目录包含列表和指针指示:在哪里可以找到每个已知的数据库。节点目录包含有关如何以及在哪里可以找到远程系统或实例的信息。要在这些目录中的任何一个中放入一项,可以使用 CATALOG 命令。要除去某一项,可使用 UNCATALOG 命令。
对数据库编目相对较简单。如果您已经创建了数据库,通常就不需要这一步了。但是,如果您以前取消了对数据库的编目,如果您想为该数据库设置 ALIAS(别名),或者如果您需要从客户机访问该数据库,那么可能就需要那么做。
2. 需要连接到 DB2 数据库的用户应该在本地工作站上对数据库编目。为了做到这一点,用户可使用 CATALOG 命令或 DB2 配置助手(Configuration Assistant,CA)。CA 让您维护应用程序能够连接的数据库列表。它对节点和数据库编目,同时使用户不用理会这些任务固有的复杂性。
在客户机上对数据库编目(catalog)有三种方法:
?
?
? 使用发现(discovery)的自动化配置 使用访问概要(access profile)的自动化配置 手工配置
就客户机而言,使用概要或发现来对数据库编目是最简单的方法。采用手工配置需要知道数据库的位置及特征,这样才能顺利地运行命令。
3. 小结
在创建了数据库的服务器上通常不需要对 DB2 数据库编目。但是,要从客户机访问数据库,该客户机必须首先在本地对数据库编目,这样应用程序才能访问数据库。
CATALOG 命令可用来对数据库编目,不过配置助手(CA)是更易于使用的工具,它允许自动化的发现和对数据库编目。
除了在每一台客户机上对数据库编目以外,DBA 也可以使用 LDAP 服务来创建数据库信息的中央资源库。
第四章 用控制中心操作db2对象
1. DB2 控制中心是功能强大的工具,它使得日常的数据库维护变得非常简单。有各种可用向导能帮助您创建或修改许多数据库对象。
您也可以使用 Control Center 来生成 DB2 命令,以便以后在脚本或程序中使用。这一特性允许您开发您想用但没有实际执行过的命令。
DBA 感兴趣的两个命令是 Show Related 和 Generate DDL 命令。Show Related 将显示与该表相关的所有数据库对象,如索引或表空间。Generate DDL 命令将对该表的定义实施逆向工程,以便在出现故障时可以重新创建表设计。
2. 小结
DB2 控制中心也可用来修改存在于数据库中的对象。对于每个对象类型,您会看到定义了其能更改的内容的不同选项。
DBA 在控制中心内执行的大多数操作都可以被捕获并保存,以便在脚本中使用。将这一工具和命令向导相结合,就可以使数据库的维护比输入命令简单得多。
第四部分 使用DB2 UDB数据
在本教程中,您将学到:
?
? SQL 的基础知识,主要是 SQL 语言元素的基础知识 如何使用数据控制语言(Data Control Language,DCL)来提供对数据库对象的访
问控制
?
?
? 如何使用数据定义语言(Data Definition Language,DDL)来创建、修改或删除数据库对象 如何使用数据操作语言(Data Manipulation Language,DML)来选择、插入、更新或删除数据 如何从命令行创建和调用 SQL 过程
第一章 结构化查询语言(SQL)
1. 大多数 SQL 语句包含一个或多个下列语言元素:
? 字符:单字节字符可以是一个字母(A-Z、a-z、$、# 和 @,或扩展字符集中的一个
成员)、一个数字(0-9)或一个特殊字符(包括逗号、星号、加号、百分号、与号以及几个其它符号)。
?
?
? 标记:标记是一个或多个字符的序列。标记不能包含空格,除非它是定界标识符(由双引号括起的一个或多个字符)或字符串常量。 标识符:SQL 标识符是用于构成名称的标记。 数据类型:值的数据类型决定了 DB2 如何解释该值。DB2 支持许多内置数据类型,
也支持用户定义的数据类型(user-defined data type,UDT)。有关 DB2 的内置数据类型的信息,请参阅数据类型。
?
? 常量:常量指定一个值。常量可以分为字符型、图形或十六进制型字符串常量,或整型、小数型、浮点型数值常量。 函数:函数是一组输入数据值和一组结果值之间的关系。数据库函数可以是内置的,也
可以是用户定义的。列函数的参数是相似值的集合;列函数返回单一值。内置列函数的示例有 AVG、MIN、MAX 和 SUM。标量函数的参数是一个个独立的标量值;标量函数返回单一值。内置标量函数的示例有 CHAR、DATE、LCASE 和 SUBSTR。
?
? 表达式:表达式指定一个值。字符串表达式、算术表达式和条件表达式都可以用于根据对一个或多个条件的求值指定一个特定结果。 断言:断言指定了一个条件,对于给定的行或组这个条件可能是真(true)、假(false)
或者未知(unknown)。断言有一些子类型:
o 基本断言对两个值进行比较(例如,x > y)。
o BETWEEN 断言把一个值同某一范围内的值进行比较。
o EXISTS 断言测试某些行的存在性。
o IN 断言把一个或多个值同一个值的集合进行比较。
o LIKE 断言搜索具有某种模式的字符串。
o NULL 断言测试空值。
2.内置数据类型可以分成数值型(numeric)、字符串型(character string)、图形字符串(graphic string)、二进制字符串型(binary string)或日期时间型(datetime)。还有一种叫做 DATALINK 的特殊数据类型。DATALINK 值包含了对存储在数据库以外的文件的逻辑引用。
数值型数据类型包括 SMALLINT、INTEGER、BIGINT、DECIMAL(p,s)、REAL 和 DOUBLE。所有数值都有符号和精度。精度是指除符号以外的二进制或十进制的位数。如果数字的值大于等于零,就认为符号为正。
?
?
?
? 小整型,SMALLINT:小整型是两个字节的整数,精度为 5 位。小整型的范围从 -32,768 到 32,767。 大整型,INTEGER 或 INT:大整型是四个字节的整数,精度为 10 位。大整型的范围从 -2,147,483,648 到 2,147,483,647。 巨整型,BIGINT:巨整型是八个字节的整数,精度为 19 位。巨整型的范围从 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807。 小数型,DECIMAL(p,s)、DEC(p,s)、NUMERIC(p,s) 或 NUM(p,s):小数型
的值是一种压缩十进制数,它有一个隐含的小数点。压缩十进制数将以二-十进制编码(binary-coded decimal,BCD)记数法的变体来存储。小数点的位置取决于数字的精度(p)和小数位(s)。小数位是指数字的小数部分的位数,它不可以是负数,也不能大于精度。最大精度是 31 位。小数型的范围从 -10**31+1 到 10**31-1。 ? 单精度浮点数(Single-precision floating-point),REAL:单精度浮点数是实
数的 32 位近似值。数字可以为零,或者在从 -3.402E+38 到 -1.175E-37 或从
1.175E-37 到 3.402E+38 的范围内。
? 双精度浮点数(Double-precision floating-point),DOUBLE,DOUBLE
PRECISION 或 FLOAT:双精度浮点数是实数的 64 位近似值。数字可以为零,或者在从 -1.79769E+308 到 -2.225E-307 或从 2.225E-307 到
1.79769E+308 的范围内。
字符串是字节序列。字符串包括 CHAR(n) 类型的定长字符串和 VARCHAR(n)、LONG VARCHAR 或 CLOB(n) 类型的变长字符串。字符串的长度就是序列中的字节数。
?
? 定长字符串,CHARACTER(n) 或 CHAR(n):定长字符串的长度介于 1 到 254 字节之间。如果没有指定长度,那么就认为是 1 个字节。 变长字符串,VARCHAR(n)、CHARACTER VARYING(n) 或 CHAR
VARYING(n):VARCHAR(n) 类型的字符串是变长字符串,最长可达 32,672 字节。
?
? LONG VARCHAR:LONG VARCHAR 类型的字符串是变长字符串,最长可达 32,700 字节。 字符大对象字符串(Character Large Object String),CLOB(n[K|M|G]):CLOB 是
变长字符串,最长可以达到 2,147,483,647 字节。如果只指定了 n,那么 n 的值就是最大长度。如果指定了 nK,那么最大长度就是 n*1,024(n 的最大值为
2,097,152)。如果指定了 nM,那么最大长度就是 n*1,048,576(n 的最大值为
2,048)。如果指定了 nG,那么最大长度就是 n*1,073,741,824(n 的最大值是 2)。CLOB 用于存储基于大单字节字符集(single-byte character set,SBCS)字符的数据或基于混合(多字节字符集(MBCS)和 SBCS)字符的数据。
图形字符串是表示双字节字符数据的字节序列。图形字符串包括类型为 GRAPHIC(n) 的定长图形字符串和类型为 VARGRAPHIC(n)、LONG VARGRAPHIC 和 DBCLOB(n) 的变长图形字符串。字符串的长度就是序列中双字节字符的数目。
?
? 定长图形字符串,GRAPHIC(n):定长图形字符串的长度介于 1 到 127 个双字节字符之间。如果没有指定长度,就认为是 1 个双字节字符。 变长图形字符串,VARGRAPHIC(n):VARGRAPHIC(n) 类型的字符串是变长图形
字符串,最大长度可达 16,336 个双字节字符。
?
? LONG VARGRAPHIC:LONG VARGRAPHIC 类型的字符串是变长图形字符串,最大长度可达 16,350 个双字节字符。 双字节字符大对象字符串,DBCLOB(n[K|M|G]):双字节字符大对象是变长双字节
字符图形字符串,最长可达 1,073,741,823 个字符。如果只指定了 n,那么 n 就是最大长度。如果指定了 nK,那么最大长度就是 n*1,024(n 的最大值为 1,048,576)。如果指定了 nM,那么最大长度就是 n*1,048,576(n 的最大值为 1,024)。如果指定了 nG,那么最大长度就是 n*1,073,741,824(n 的最大值是 1)。DBCLOB 用于存储基于大 DBCS(双字节字符集,double-byte character set)字符的数据。 二进制字符串是字节序列。二进制字符串包括 BLOB(n) 类型的变长字符串,它用于容纳非传统型的数据,诸如图片、语音或混合媒体等,还可以容纳用户定义的类型及用户定义的函数的结构化数据。
? 二进制大对象,BLOB(n[K|M|G]):二进制大对象是变长字符串,最长可达
2,147,483,647 字节。如果只指定了 n,那么 n 就是最大长度。如果指定了 nK,那么最大长度就是 n*1,024(n 的最大值为 2,097,152)。如果指定了 nM,那么最大长度就是 n*1,048,576(n 的最大值为 2,048)。如果指定了 nG,那么最大长度就是 n*1,073,741,824(n 的最大值是 2)。
日期时间型数据类型包括 DATE、TIME 和 TIMESTAMP。日期时间值可在某些算术和字符串操作中使用,而且兼容某些字符串,但它们既不是字符串,也不是数字。
? DATE:DATE 是一个由三部分组成的值(年、月和日)。年份部分的范围是从 0001
到 9999。月份部分的范围是从 1 到 12。日部分的范围是从 1 到 n,其中 n 的值取决于月份。DATE 列长 10 个字节。
? TIME:TIME 是一个由三部分组成的值(小时、分钟和秒)。小时部分的范围是从 0
到 24。分钟和秒部分的范围都是从 0 到 59。如果小时为 24,分钟和秒的值都是 0。TIME 列长 8 个字节。
? TIMESTAMP:TIMESTAMP 是一个由七部分组成的值(年、月、日、小时、分钟、
秒和微秒)。年份部分的范围是从 0001 到 9999。月份部分的范围是从 1 到 12。日部分的范围是从 1 到 n,其中 n 的值取决于月份。小时部分的范围是从 0 到 24。分钟和秒部分的范围都是从 0 到 59。微秒部分的范围是从 000000 到 999999。如果小时是 24,那么分钟值、秒的值和微秒的值都是 0。TIMESTAMP 列长 26 个字节。
日期时间值的字符串表示:尽管 DATE、TIME 和 TIMESTAMP 的值的内部表示对用户是透明的,日期、时间和时间戳记也可以用字符串来表示,CHAR 标量函数(请参阅 SQL 的―词类(parts of speech)‖)可以用于创建日期时间值的字符串表示。
?
?
? 日期值的字符串表示是一个以数字开始,长度不少于 8 个字符的字符串。日期值的月份和日部分中前面的零可以省略。 时间值的字符串表示是以数字开头,长度不少于 4 个字符的字符串。时间值的小时部分前面的零可以省略,秒部分可以完全省略。如果秒的值没有指定,那么就认为是 0。 时间戳记值的字符串表示是以数字开头,长度不少于 16 个字符的字符串。完整的时间
戳记字符串表示形式为 yyyy-mm-dd-hh.mm.ss.nnnnnn。时间戳记值的月、日或
小时等几部分前面的零可以省略,微秒可以截断或完全省略。如果任何时间戳记值的微秒部分尾零被省略掉了,那么将假定空缺的数位上是零。
图形字符串是表示双字节字符数据的字节序列。图形字符串包括类型为 GRAPHIC(n) 的定长图形字符串和类型为 VARGRAPHIC(n)、LONG VARGRAPHIC 和 DBCLOB(n) 的变长图形字符串。字符串的长度就是序列中双字节字符的数目。
?
?
?
? 定长图形字符串,GRAPHIC(n):定长图形字符串的长度介于 1 到 127 个双字节字符之间。如果没有指定长度,就认为是 1 个双字节字符。 变长图形字符串,VARGRAPHIC(n):VARGRAPHIC(n) 类型的字符串是变长图形字符串,最大长度可达 16,336 个双字节字符。 LONG VARGRAPHIC:LONG VARGRAPHIC 类型的字符串是变长图形字符串,最大长度可达 16,350 个双字节字符。 双字节字符大对象字符串,DBCLOB(n[K|M|G]):双字节字符大对象是变长双字节
字符图形字符串,最长可达 1,073,741,823 个字符。如果只指定了 n,那么 n 就是最大长度。如果指定了 nK,那么最大长度就是 n*1,024(n 的最大值为 1,048,576)。如果指定了 nM,那么最大长度就是 n*1,048,576(n 的最大值为 1,024)。如果指定了 nG,那么最大长度就是 n*1,073,741,824(n 的最大值是 1)。DBCLOB 用于存储基于大 DBCS(双字节字符集,double-byte character set)字符的数据。 二进制字符串是字节序列。二进制字符串包括 BLOB(n) 类型的变长字符串,它用于容纳非传统型的数据,诸如图片、语音或混合媒体等,还可以容纳用户定义的类型及用户定义的函数的结构化数据。
? 二进制大对象,BLOB(n[K|M|G]):二进制大对象是变长字符串,最长可达
2,147,483,647 字节。如果只指定了 n,那么 n 就是最大长度。如果指定了 nK,那么最大长度就是 n*1,024(n 的最大值为 2,097,152)。如果指定了 nM,那么最大长度就是 n*1,048,576(n 的最大值为 2,048)。如果指定了 nG,那么最大长度就是 n*1,073,741,824(n 的最大值是 2)。
日期时间型数据类型包括 DATE、TIME 和 TIMESTAMP。日期时间值可在某些算术和字符串操作中使用,而且兼容某些字符串,但它们既不是字符串,也不是数字。
? DATE:DATE 是一个由三部分组成的值(年、月和日)。年份部分的范围是从 0001
到 9999。月份部分的范围是从 1 到 12。日部分的范围是从 1 到 n,其中 n 的值取决于月份。DATE 列长 10 个字节。
? TIME:TIME 是一个由三部分组成的值(小时、分钟和秒)。小时部分的范围是从 0
到 24。分钟和秒部分的范围都是从 0 到 59。如果小时为 24,分钟和秒的值都是 0。TIME 列长 8 个字节。
? TIMESTAMP:TIMESTAMP 是一个由七部分组成的值(年、月、日、小时、分钟、
秒和微秒)。年份部分的范围是从 0001 到 9999。月份部分的范围是从 1 到 12。日部分的范围是从 1 到 n,其中 n 的值取决于月份。小时部分的范围是从 0 到 24。分钟和秒部分的范围都是从 0 到 59。微秒部分的范围是从 000000 到 999999。如果小时是 24,那么分钟值、秒的值和微秒的值都是 0。TIMESTAMP 列长 26 个字节。
日期时间值的字符串表示:尽管 DATE、TIME 和 TIMESTAMP 的值的内部表示对用户是透明的,日期、时间和时间戳记也可以用字符串来表示,CHAR 标量函数(请参阅 SQL 的―词类(parts of speech)‖)可以用于创建日期时间值的字符串表示。
?
?
? 日期值的字符串表示是一个以数字开始,长度不少于 8 个字符的字符串。日期值的月份和日部分中前面的零可以省略。 时间值的字符串表示是以数字开头,长度不少于 4 个字符的字符串。时间值的小时部分前面的零可以省略,秒部分可以完全省略。如果秒的值没有指定,那么就认为是 0。 时间戳记值的字符串表示是以数字开头,长度不少于 16 个字符的字符串。完整的时间
戳记字符串表示形式为 yyyy-mm-dd-hh.mm.ss.nnnnnn。时间戳记值的月、日或小时等几部分前面的零可以省略,微秒可以截断或完全省略。如果任何时间戳记值的微秒部分尾零被省略掉了,那么将假定空缺的数位上是零。
第二章 据控制语言(DCL)
1. DCL 是 SQL 的子集。它用于提供对数据库对象的访问控制。有两级安全性来控制数据库对象的访问。控制访问 DB2 实例的第一级由操作系统来管理。这一级叫做认证,它将会涉及到利用有效的用户标识和密码来证实用户的身份。第二级安全性控制对服务器上的数据库的访问。
2. 权限和特权
如果您拥有权限或访问所需的特权,那么在您与数据库连接以后,就可以访问数据库、数据库中的对象和数据。
权限泛指用户权力。它们包括:
? SYSADM:这一权限级别给予用户如下能力:运行实用程序、发出数据库和数据库管
理器命令以及控制数据库管理器实例中的数据库对象。除了拥有授予其它权限的所有功能以外,具有 SYSADM 权限的用户还可以迁移数据库、修改数据库管理器配置文件以及授予 DBADM 权限。
? SYSCTRL:这一权限级别使用户能够执行所有管理任务,如运行对数据库管理器实例
及其数据库的维护和实用程序操作。拥有 SYSCTRL 权限的用户不能直接访问数据,除非特别授予其附加的特权。除 SYSMAINT 权限的职能以外,拥有 SYSCTRL 权限或更高权限的用户还可以创建或删除数据库、强迫应用程序从数据库断开、恢复到新数据库、创建、删除或改变表空间、更新数据库、节点或分布式连接服务(distributed connection services,DCS)目录。
? SYSMAINT:这一权限级别的用户能够执行维护活动,但不能访问数据库实例内的数
据。拥有 SYSMAINT 或更高权限的用户可以更新数据库配置文件、备份数据库或表空间、恢复到现有的数据库、恢复表空间、执行前滚恢复,停止或启动数据库实例、运行跟踪、为实例或其数据库生成系统监控程序快照。
? DBADM:这一权限级别适用于独立的数据库。拥有数据库的 DBADM 权限的用户可
以对该数据库执行任何管理任务,如创建数据库对象、装入数据和监控数据库活动。拥有 DBADM 权限的用户可以阅读日志文件、创建、激活及删除事件监控程序、查询表
空间状态、更新历史文件、使表空间停顿、重组表、使用 runstats 实用程序收集目录统计数据。数据库创建者自动拥有该数据库的 DBADM 权限。
? LOAD:这一权限级别的用户能够针对某个特定数据库执行装入操作。如果用户只有
LOAD 权限,那他还必须对表拥有表级别上的特权(如 INSERT 特权)才能向表装入数据。如果装入操作要替换表里的现有数据,那么用户还必须拥有对该表的 DELETE 特权。
特权是可以授予用户的特定权力,从而允许他们使用数据库中的特定对象。特权是创建或访问数据库对象的权力。特权可生效的对象包括数据库、模式、表空间、表、视图、别名、服务器、包和索引。
如果您创建了一个对象,那您就拥有那个对象的所有访问权。也就是所谓的拥有对象的
CONTROL 特权。拥有对象的 CONTROL 特权的用户可以让其它用户能够访问这个对象,并且允许其它用户授予针对该对象的特权。可以使用 SQL GRANT 或 REVOKE 语句来授予或撤消特权。
单独的特权(如 SELECT、INSERT、DELETE 和 UPDATE)允许用户执行某一特定功能,有时是针对特定对象执行特定功能。
要授予针对数据库对象的特权,您必须拥有 SYSADM 权限、DBADM 权限、CONTROL 特权或者对该对象有 WITH GRANT OPTION(GRANT 语句的可选项)。您必须有 SYSADM 或 DBADM 权限才能授予其它用户 CONTROL 特权。您必须有 SYSADM 权限才能授予 DBADM 权限。
3. 模式是命名对象(如表、视图、触发器和函数)的集合。模式提供了对象在数据库中的逻辑分类。对象名由两部分组成,模式名用作第一部分。例如,考虑名称 SMITH.STAFF。在这个示例中,STAFF 表的全限定名称包括模式名 SMITH 以使其同其它任何在系统目录中被命名为 STAFF 的表区分开来。模式本身就是一个数据库对象。拥有 SYSADM 或 DBADM 权限的用户都可以更改用户对任何模式(即使是隐式创建的模式)所拥有的特权。 4. GRANT privilege ON object-type object-name
TO [{USER | GROUP | PUBLIC}] authorization-name
[WITH GRANT OPTION]
指定关键字 PUBLIC 将把特权授予所有用户。一些操作系统允许用户和组同名。在这种情况下,可以指定可选的关键字 USER 或 GROUP 以示区别。例如:
GRANT INSERT, DELETE ON TABLE staff TO USER rosita WITH GRANT OPTION
该示例中,WITH GRANT OPTION 使 Rosita 能够授予其他用户 INSERT 或 DELETE 特权。
5. REVOKE privilege ON object-type object-name
FROM [{USER | GROUP | PUBLIC}] authorization-name
要撤消对象上的特权,您必须对包含该对象的数据库拥有 SYSADM 权限和 DBADM 权限,或者拥有该对象的 CONTROL 特权。拥有对象的 WITH GRANT OPTION 并不能让您撤消该
对象的特权。即使撤消了组对对象的特权,但并不能保证已撤消了该组中的每个成员对该对象的特权。如果该组中的任何成员曾作为个体或另一个组的成员被授予过特权,那么除非发出另外的 REVOKE 语句,否则他们将保留这些特权。
第三章 数据定义语言(DDL)
1. CREATE 语句用于创建数据库对象,包括:
?
?
?
?
?
?
?
?
?
? 缓冲池(Buffer pool) 事件监控程序(Event monitor) 函数(Function) 索引(Index) 模式(Schema) 存储过程(Stored procedure) 表(Table) 表空间(Table space) 触发器(Trigger) 视图(View)
每当您创建数据库对象时,都会更新系统目录。
2. DECLARE语句与 CREATE 语句是类似的,只有一点例外,用它所创建的是只能在数据库连接期间存在的临时表。当您要用到中间结果时,临时表挺有用的。和任何其它表一样,声明过的表可以被引用,也可以被修改或删除。表是唯一可以被声明的对象。当您声明临时表时,不会更新系统目录。临时表必须由模式名 SESSION 显式(否则将隐式)限定,因为每个定义声明过的表的会话对该临时表都有自己的(可能是唯一的)描述。
3. ALTER 语句可以用来更改现有数据库对象的一些特征,包括:
?
?
?
? 缓冲池 表 表空间 视图
您不可以改变索引。如果您想要更改索引,那么就必须删除它然后用不同的定义创建一个新的。 4. 您可以删除任何 SQL CREATE 或 DECLARE 语句所创建的对象,包括:
?
?
?
?
?
? 缓冲池 事件监控程序 函数 索引 模式 存储过程
?
?
?
? 表 表空间 触发器 视图
DROP 语句从系统目录中删除对象的定义,因此也从数据库本身删除了这些定义。
第四章 数据操作语言(DML)
1. SELECT 语句用于检索表或视图数据。
select要限制结果集中的行数,请使用 FETCH FIRST 子句。例如:
SELECT * FROM staff FETCH FIRST 10 ROWS ONLY
使用 DISTINCT 子句来消除结果集中重复的行。例如:
SELECT DISTINCT dept, job FROM staff
使用 AS 子句为选择列表上的表达式或项指定一个有意义的名字。
SELECT name, salary + comm AS pay FROM staff
2. 在构造搜索条件时,请务必要:
?
?
?
? 只对数值型数据类型应用算术运算 只在兼容的数据类型间进行比较 将字符值括在单引号之内 完全按字符在数据库内的值指定字符值
子查询是出现在主查询的 WHERE 子句内的 SELECT 语句,并把其结果集提供给该 WHERE 子句。例如:
"SELECT lastname FROM employee
WHERE lastname IN
(SELECT sales_person FROM sales
WHERE sales_date < '01/01/1996')"
相关名称(correlation name)是在查询的 FROM 子句中定义的,可以用作表的较为简便的缩略名。相关名称还消除了对不同表中相同列名的模糊引用。例如:
"SELECT e.salary FROM employee e
WHERE e.salary <
(SELECT AVG(s.salary) FROM staff s)"
3. 使用 ORDER BY 子句根据一列或多列中的值对结果集进行排序。ORDER BY 子句中指定的列名不一定要在选择列表中指定。例如:
"SELECT name, salary FROM staff
WHERE salary > 20000
ORDER BY salary"
您可以在 ORDER BY 子句中指定 DESC 来以降序排列结果集:
ORDER BY salary DESC
4. 连接是把两个或两个以上的表中的数据组合在一起的查询。常常必须从两个或两个以上的表中选择信息,因为一张表不可能包含所有需要的信息。连接向结果集添加列。
SELECT deptnumb, deptname, id AS manager_id, name AS manager
FROM org, staff
WHERE manager = id
ORDER BY deptnumb
上面看到的语句就是一个内连接的示例。内连接只从交叉乘积中返回满足连接条件的行。如果某一行在一个表中存在,但不在另一张表中,那么结果集中将不包括这一行。要显式地指定内连接,可以通过在 FROM 子句中用 INNER JOIN 运算符来改写前面的查询:
...
FROM org INNER JOIN staff
ON manager = id
...
关键字 ON 为将要连接的表指定连接条件。
内连接的结果集中包括分别与左表(ORG)和右表(STAFF)中的 Manager 列和 ID 列的值相匹配的行。(当您想要在两个表上执行连接时,您可以任意指定一个表为左表,而另外一个就是右表。)
外连接返回的是内连接操作生成的行,以及内连接操作无法返回的行。外连接共有三类:
?
?
? 左外连接包括内连接加上在左表中但内连接不会返回的那些行。这类连接在 FROM 子句中使用 LEFT OUTER JOIN(或 LEFT JOIN)运算符。 右外连接包括内连接加上在右表中但内连接不会返回的那些行。这类连接在 FROM 子句中使用 RIGHT OUTER JOIN(或 RIGHT JOIN)运算符。 全外连接包括内连接加上在左表和右表中但内连接不会返回的那些行。这类连接在
FROM 子句中使用 FULL OUTER JOIN(或 FULL JOIN)运算符。
5.您可以使用集合运算符 UNION、EXCEPT 或 INTERSECT 把两个或两个以上的查询合并成一个查询。集合运算符将处理查询结果、去掉重复结果并返回最终结果集。
?
? UNION 集合运算符会把两个或两个以上其它结果表合并生成一个结果表。 EXCEPT 集合运算符生成一个结果表时,把第一个查询返回的所有行包括在内,但
不计第二个以及其后的所有查询(即将后面查询的结果从第一个查询结果中去除后得到的集合)。
? INTERSECT 集合运算符提供只包括由所有查询都返回的行来生成一个结果表。 6.可以使用 GROUP BY 子句组织结果集中的行。每一组用结果集中的一行来表示。例如: SELECT sales_date, MAX(sales) AS max_sales FROM sales
GROUP BY sales_date
通常 HAVING 子句和 GROUP BY 子句一起使用可以检索出只满足某个特定条件的组作为结果。HAVING 子句可以包含一个或多个断言,把组的某个特性同该组的另一个特性或常量相比较。例如:
"SELECT sales_person, SUM(sales) AS total_sales FROM sales
GROUP BY sales_person
HAVING SUM(sales) > 25"
7.数据库函数是一组输入数据值和一个结果值之间的关系。DB2 通用数据库提供了许多内置函数,包括列函数和标量函数:
? 列函数对列中的一组值进行操作。例如:
o SUM(sales) 返回 Sales 列中值的总和。
o AVG(sales) 返回 Sales 列中值的总和除以该列中值的个数。
o MIN(sales) 返回 Sales 列中的最小值。
o MAX(sales) 返回 Sales 列中的最大值。
o COUNT(sales) 返回 Sales 列中的非空值的个数。
? 标量函数对一个值进行操作返回另外一个值。例如:
o ABS(-5) 返回 -5 的绝对值 — 即 5。
o HEX(69) 返回数字 69 的十六进制表示 — 即 45000000。
o LENGTH('Pierre') 返回―Pierre‖字符串中的字节数 — 即 6。对于
o
o
o
o
o GRAPHIC 字符串,LENGTH 函数返回双字节字符数。 YEAR('03/14/2002') 抽取日期时间值 03/14/2002 的年份部分 — 即 2002。 MONTH('03/14/2002') 抽取日期时间值 03/14/2002 的月份部分 — 即 3。 DAY('03/14/2002') 抽取日期时间值 03/14/2002 的日部分 — 即 14。 LCASE('SHAMAN') 或 LOWER('SHAMAN') 返回一个字符串,其中所有字符都已转换成小写字符 — 在本例中为 shaman。 UCASE('shaman') 或 UPPER('shaman') 返回一个字符串,其中所有
字符都已转换成大写字符 — 在本例中为 SHAMAN。
8.INSERT 语句可以用于向表或视图中添加新行。向视图中插入一行,那么这一行也会被插入到该视图所基于的表中。您可以:
?
? 使用 VALUES 子句来指定一行或多行的列数据。例如: INSERT INTO staff VALUES (1212,'Cerny',20,'Sales',3,90000.00,30000.00)
? INSERT INTO staff VALUES
(1213,'Wolfrum',20,'Sales',2,90000.00,10000.00)
或代之以:
INSERT INTO staff (id, name, dept, job, years, salary, comm)
VALUES
(1212,'Cerny',20,'Sales',3,90000.00,30000.00),
(1213,'Wolfrum',20,'Sales',2,90000.00,10000.00)
?
?
?
?
?
?
? 指定一个全选择(fullselect)来标明要从其它表或视图复制过来的数据。全选择是生成结果表的语句。例如: CREATE TABLE pers LIKE staff INSERT INTO pers SELECT id, name, dept, job, years, salary, comm FROM staff WHERE dept = 38
第五章 SQL过程
1. SQL 过程是一个存储过程,它的主体是用 SQL 编写的。主体包含了 SQL 过程的逻辑。它可以包括变量声明、条件处理、控制流语句和 DML。可以在一条复合语句中指定多条 SQL 语句,该复合语句将这几条语句组合成一个可执行块。
要成功创建 SQL 过程,您必须已经在数据库服务器上安装了 DB2 应用程序开发客户机(DB2 Application Development Client)。(请参阅本系列的第一篇教程以获取关于应用程序开发客户机的更多信息。)DB2 通过使用嵌入式 SQL 将 SQL 过程转换成等价的 C 应用程序;这表示在您可以创建 SQL 过程之前,还必须在数据库服务器上安装并配置受支持的 C 编译器。
第五部分 使用DB2 UDB对象
在本教程中,您将学习:
?
?
?
?
?
? DB2 提供的内置数据类型,以及定义表时适合使用哪些数据类型(有关数据类型的不同处理,请参阅本系列教程中的第四篇。) 高级数据类型的概念。 在 DB2 数据库中创建表、视图和索引。 唯一性约束、参照完整性约束和表检查约束的特性与使用。 如何使用视图来限制对数据的访问。 索引的特性使用。
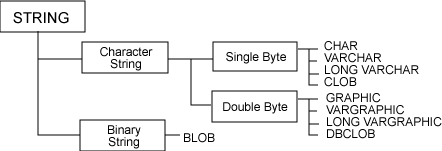
第一章 数据类型
1. 内置数据类型的分类如下:
?
?
?
? 数字型(Numeric) 字符串型(String) 日期时间型(Datetime) 数据链接型(Datalink)
用户定义的数据类型分类如下:
?
?
? 用户定义的单值类型 用户定义的结构化类型 用户定义的引用类型

2. DB2 还提供一些数据类型来存储非常长的字符串数据。所有的长字符串数据类型都有相似的特征。首先,数据物理上并没有和行数据一起存储在数据库中,这意味着访问该数据需要额外的处理。长数据类型的长度最多可以定义为 2 GB。但是,实际上只使用必需的空间。 3. DB2 提供三种数据类型来存储日期和时间:
?
?
? DATE TIME TIMESTAMP
这些数据类型的值以内部格式存储在数据库中;但是,应用程序可以把它们作为字符串来操作。当检索这些数据类型中的某一个时,它被表示为一个字符串。更新这些数据类型时,必须用引号将值括起来。
4. DB2 提供 DATALINK 数据类型来管理外部文件。DATALINK 列允许您存储对数据库之外的文件的引用。这些文件所驻留的文件系统 可与数据库在同一服务器上,也可以在远程服务器上。
5. 用户定义的数据类型有以下三种:
? 用户定义的单值类型:您可以根据内置类型定义新数据类型。新类型将具有与内置类型
相同的特性,但您可以用它来确保只比较类型相同的值。例如,您可以根据
DECIMAL(10,2) 定义加元类型(CANDOL)和美元类型(USADOL)。这两种类型都基于同一内置类型,但除非应用转换函数,否则不能比较它们。
? 用户定义的结构化类型:您可以创建由几列内置类型组成的类型。然后可以在创建表时
使用这一结构化的类型。例如,您可以创建名为 ADDRESS 的结构化类型,它包含街道号码、街道名称、城市等数据。然后您可以在定义其它表(如雇员或供应商)时使用这个类型,因为这些表都需要相同的数据。同样,结构化类型可以在层次结构中拥有子类型。这允许属于某个层次结构的对象存储在数据库中。
? 用户定义的引用类型:当使用结构化类型时,您可以用引用类型来定义对另一个表中行
的引用。这些引用看上去和引用约束相似;但是,它们并不强制表之间存在一定的关系。表中的引用允许您以不同的方式指定查询。
DB2 Extender 是通过使用用户定义的类型和用户定义的函数(UDF)的特性实现的。每个扩展器都带有一个或多个 UDT、操作 UDT 的 UDF 和特定的应用程序编程接口(API),或许还有其它工具。
第二章 表
1.所有的数据都存储在数据库的表中。表由不同数据类型的一列或多列组成。数据存储在行或记录中。
表是用 CREATE TABLE SQL 语句来定义的。DB2 还提供了一个 GUI 工具用于创建表,该工具将根据您指定的信息来创建表。它还会生成 CREATE TABLE SQL 语句,您以后可以在脚本或应用程序中使用该语句。
数据库有一组表,名为系统目录表(system catalog table),这些表保存关于数据库中所有对象的信息。目录表 SYSCAT.TABLES 包含的每一行对应数据库中定义的一个表。
SYSCAT.COLUMNS 包含的每一行对应数据库中每个表的每一列。您可以用 SELECT 语句查看目录表,就和查看数据库中任何其它的表一样;但是不能使用 INSERT、UPDATE 或 DELETE 语句来修改数据。作为数据定义语句(DDL)(如 CREATE)和其它操作(如 RUNSTATS)的结果,表会自动被更新。
2.表以表空间的形式存储在数据库中。表空间有分配给它们的物理空间。在创建表之前必须先创建表空间。当创建表时,您可以让 DB2 将表放置在缺省表空间中,也可以指定您希望表驻留在哪个表空间。以下 CREATE TABLE 语句将 BOOKS 表放置在 BOOKINFO 表空间中。
CREATE TABLE BOOKS ( BOOKID INTEGER,
BOOKNAME VARCHAR(100),
ISBN CHAR(10) )
IN BOOKINFO
3. 可以使用 CREATE TABLE SQL 语句创建与数据库中另一个表或视图相似的表: CREATE TABLE MYBOOKS LIKE BOOKS
该语句创建的表与原始的表或视图有相同的列。新表的列与旧表或视图中的列有相同的名称、数据类型和可为空的属性。您还可以指定子句,这些子句将复制其它属性,如列缺省值和标识属性。
创建了表之后,可用几种方法对它填充数据。INSERT 语句允许您将一行或数行数据插入表中。DB2 还提供了一些实用程序可插入来自文件的大量数据。IMPORT 实用程序使用 INSERT 语句插入行。它旨在将少量数据装入数据库。LOAD 实用程序将行直接插到数据库中的数据页上,因此比 IMPORT 实用程序快得多。它旨在装入大量数据。
4.可以用 ALTER TABLE SQL 语句更改表的某些特征。例如,您可以:
?
?
?
?
? 添加一列或多列 添加或删除主键 添加或删除一个或多个唯一性约束或参照约束 添加或删除一个或多个检查约束 更改 VARCHAR 列的长度
表的某些特征是不能更改的。例如,您不能从表中除去一列。另外,您不能更改表驻留的表空间。要更改这样的特征,必须保存表数据,删除表,然后重新创建它。
5. DROP TABLE 语句从数据库中除去表,同时删除数据和表定义。如果对表定义了索引或约束,它们也会被删除。
6. 表的列是在 CREATE TABLE 语句中用列名和数据类型指定的。可以对列指定限制其中数据的附加子句。
缺省情况下,列允许空值。如果不希望允许空值,可对列指定 NOT NULL 子句。还可以使用 WITH DEFAULT 子句和缺省值来指定缺省值。下面的 CREATE TABLE 语句创建表 BOOKS,其中 BOOKID 列不允许空值,BOOKNAME 的缺省值是 TBD。
CREATE TABLE BOOKS ( BOOKID INTEGER NOT NULL,
BOOKNAME VARCHAR(100) WITH DEFAULT 'TBD',
ISBN CHAR(10) )
在 BOOKS 表中,BOOKID 是为每本书指派的唯一号码。可以用 GENERATED ALWAYS AS IDENTITY 指定 DB2 生成 BOOKID,而不必让应用程序生成标识符:
CREATE TABLE BOOKS ( BOOKID INTEGER NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), BOOKNAME VARCHAR(100) WITH DEFAULT 'TBD',
ISBN CHAR(10) )
GENERATED ALWAYS AS IDENTITY 使得每条记录都有一个 BOOKID 生成。生成的第一个值将是 1,然后通过对前一个值加 1 生成后续值。
您也可以使用 GENERATED ALWAYS 选项让 DB2 自动计算某个列的值。以下的示例定义名为 AUTHORS 的表,其中包含对小说和非小说书籍的计数。通过将这两个计数相加计算出 TOTALBOOKS 列。
CREATE TABLE AUTHORS (AUTHORID INTEGER NOT NULL PRIMARY KEY,
LNAME VARCHAR(100),
FNAME VARCHAR(100),
FICTIONBOOKS INTEGER,
NONFICTIONBOOKS INTEGER,
TOTALBOOKS INTEGER GENERATED ALWAYS
AS (FICTIONBOOKS + NONFICTIONBOOKS) )
第三章 约束
1. DB2 提供了几种方法来控制什么数据能够存储在列中。这些特性被称为约束(constraint)或规则(rule),数据库管理器强制一个数据列或一组列遵守这些约束或规则。
DB2 提供三种约束:
?
?
? 唯一性约束,用于确保列中的值是唯一的。 参照完整性约束,用于定义表之间的关系,并确保这些关系持续有效。 表检查约束,用于验证列数据没有违反为列定义的规则。
2. 唯一性约束用于确保列中的值是唯一的。可对一列或多列定义唯一性约束。必须将唯一性约束中包括的每一列都定义为 NOT NULL。
可将唯一性约束定义成 PRIMARY KEY 或 UNIQUE 约束。可在创建表时将这些约束作为 CREATE TABLE SQL 语句的一部分来定义,或者在创建表之后用 ALTER TABLE 语句添加这些约束。
什么时候该定义 PRIMARY KEY,而什么时候又该定义 UNIQUE 键呢?这取决于数据的性质。在上个示例中,BOOKS 表有 BOOKID,它用于唯一地标识一本书。在其它包含与该
书相关信息的表中也使用该值。在此情况下,您就应该把 BOOKID 定义为主键。DB2 在一个表中只允许定义一个主键。
ISBN 号列应该是唯一的,但它却不是在数据库中被引用的值。在此情况下,可将 ISBN 列定义为 UNIQUE。
CREATE TABLE BOOKS (BOOKID INTEGER NOT NULL PRIMARY KEY,
BOOKNAME VARCHAR(100),
ISBN CHAR(10) NOT NULL CONSTRAINT BOOKSISBN UNIQUE ) DB2 在一个表中只允许定义一个主键;但是,可以定义多个唯一性约束。
每当您对某一列定义 PRIMARY 或 UNIQUE 键时,DB2 就创建一个唯一性索引对该列强制执行唯一性。DB2 将不允许您创建重复的唯一性约束或重复的索引。例如,以下针对 BOOKS 表的语句将失败:
ALTER TABLE BOOKS ADD CONSTRAINT UNIQUE (BOOKID)
3. 其主键与另一个表相关的表(这里是 AUTHORS)被称为父表。与父表相关的表(这里是 BOOKS)被称为从属表。您可以为一个父表定义多个从属表。您也可以定义同一个表中各行之间的关系。在此情况下,父表和从属表是同一个表。
例:CREATE TABLE AUTHORS (AUTHORID INTEGER NOT NULL PRIMARY KEY, LNAME VARCHAR(100),
FNAME VARCHAR(100))
CREATE TABLE BOOKS (BOOKID INTEGER NOT NULL PRIMARY KEY,
BOOKNAME VARCHAR(100),
ISBN CHAR(10),
AUTHORID INTEGER REFERENCES AUTHORS)
当您为一组表定义了参照约束后,在对它们执行更新操作时,DB2 会强制这些表遵守参照完整性规则:
? DB2 会确保只向定义了参照完整性约束的列插入有效数据。这意味着在父表中必须始
终有这样的一行,其键值等于您正插入从属表的行中的外键值。例如,如果将一本新书插入(AUTHORID 为 437 的)BOOKS 表中,那么在 AUTHORS 表中必须已经有 AUTHORID 为 437 的一行。
? 当从父表中删除在从属表中有从属行的行时,DB2 也会强制遵守规则。DB2 采取的行
动取决于为表定义的删除规则。可指定的规则有四种:RESTRICT、NO ACTION、CASCADE 和 SET NULL。
o 如果指定 RESTRICT 或 NO ACTION,则 DB2 不允许删除父行。必须先删
除从属表中的行才能删除父表中的行。这条规则是缺省值,所以在我们定义
AUTHORS 和 BOOKS 表时,对这些表应用了这一规则。
o 如果指定 CASCADE,则从父表中删除行时也会自动删除所有从属表中的从属
行。
o 如果指定 SET NULL,则从父表中删除父行时,从属行中的外键值被设置为空
(如果可为空的话)。
? 当更新父表中的键值时,可指定两种规则:RESTRICT 和 NO ACTION。如果从属表
中有从属行,RESTRICT 将不允许更新键值。如果更新结束时,从属表中有的从属行在父表中没有父键,则 NO ACTION 会使对父键值的更新操作被拒绝。
4.表检查约束用于限制表中某一列中的值。DB2 将确保在插入和更新时不违反这条约束。假定我们给 BOOKS 表添加一个表示书籍类型的列,并且我们希望允许的值是 F(小说)和 N(非小说)。我们可以如下添加带检查约束的 BOOKTYPE 列:
ALTER TABLE BOOKS ADD BOOKTYPE CHAR(1) CHECK (BOOKTYPE IN ('F','N') )
第四章 视图
1. 视图允许不同的用户或应用程序以不同的方式查看同一数据。它不仅使数据更易于访问,而且可以利用它限制某些用户能够查看或更新的行和列。
对于用户,视图看起来就象表一样。除了视图定义外,视图在数据库中不占用空间;视图中显示的数据派生自另一个表。您可以对现有的表、另一个视图或两者的某种组合创建视图。对另一个视图定义的视图被称为嵌套视图。
您可以定义这样的视图,其列名称不同于基表中对应的列名称。您也可以定义这样的视图,它检查插入或更新的数据是否符合视图的条件。
在数据库中定义的视图的列表存储在系统目录表 SYSIBM.SYSVIEWS 中,对这个表还定义了一个名为 SYSCAT.VIEWS 的视图。系统目录还有一个 SYSCAT.VIEWDEP,对于在数据库中定义的每个视图,它都有一行与从属于该视图的每个视图或表相对应。同样,每个视图在 SYSIBM.SYSTABLES 中都有一个项,在 SYSIBM.SYSCOLUMNS 中有多个项,因为可以象表一样使用视图。
2. 如果您删除某个视图所基于的表或另一个视图,则该视图在数据库虽然仍有定义,但不起作用。SYSCAT.VIEWS 的 VALID 列指明视图是有效(Y)还是无效(X)。即使重新创建基表,这个没有支持的视图仍为无效;您还是必须重新创建它。您不能修改视图;要更改视图定义,必须先删除而后重新创建它。
3. 当您创建视图时,可以把它定义成只读视图或可更新视图。视图的 SELECT 语句决定视图是只读的还是可更新的。通常,如果视图的行可映射至基表的行,则视图是可更新的。创建可更新视图的规则是复杂的,并且取决于查询的定义。例如,使用 VALUES、DISTINCT 或 JOIN 特性的视图是不可更新的。通过查看 SYSCAT.VIEWS 的 READONLY 列,您可以很容易地确定视图是否为可更新的:Y 表示它是只读的,N 表示它不是只读的。 4. CREATE VIEW NONFICTIONBOOKS AS SELECT * FROM BOOKS WHERE BOOKTYPE = 'N'
前面定义的 NONFICTIONBOOKS 视图只包括 BOOKTYPE 为 N 的行。如果您将 BOOKTYPE 为 F 的行插入该视图,DB2 将把该行插入到基表 BOOKS。但是,如果随后从视图进行选择操作,您无法通过该视图看到新插入的行。如果您不希望用户插入视图范围以外的行,可以用 check option 定义该视图。用 WITH CHECK OPTION 定义视图就是告诉 DB2 检查使用该视图的语句是否满足视图的条件。
以下语句用 WITH CHECK OPTION 定义了一个视图:
CREATE VIEW NONFICTIONBOOKS AS
SELECT * FROM BOOKS WHERE BOOKTYPE = 'N'
WITH CHECK OPTION
该视图仍将限制用户只能看到非小说类书籍;此外,它还防止用户插入 BOOKTYPE 列中值不为 N 的行,并防止用户将现有行中 BOOKTYPE 列的值更新为不是 N 的值。例如,将不再允许以下语句:
INSERT INTO NONFICTIONBOOKS VALUES (...,'F');
UPDATE NONFICTIONBOOKS SET BOOKTYPE = 'F' WHERE BOOKID = 111
5. 当定义嵌套视图时,可用检查选项来限制操作。但是,您还可以指定其它子句来定义如何继承限制。可将检查选项定义为 CASCADED 或 LOCAL。如果没有指定关键字,则 CASCADED 是缺省值。(注意二者区别)
当用 WITH CASCADED CHECK OPTION 创建视图时,针对该视图执行的所有语句都必须满足该视图以及所有底层视图的条件 — 即使没有用检查选项定义那些视图也是如此。
接下来,假设我们使用 WITH LOCAL CHECK OPTION 在视图 NONFICTIONBOOKS 的基础上创建视图 NONFICTIONBOOKS2。现在,针对该视图执行的语句只需满足指定了检查选项的视图的条件。
第五章 索引
1.索引是表中一列或多列的键值的有序列表。创建索引的原因有两个:
?
? 确保一列或多列中值的唯一性。 提高对表进行查询的性能。为了执行查询时提高性能,或以索引的顺序显示查询结果,
DB2 优化器会使用索引。
可将索引定义为唯一的或非唯一的。非唯一索引允许有重复键值;唯一索引只允许一个键值在列表中出现一次。唯一索引确实允许出现一次空值。但第二个空值会造成重复,因此是不允许的。 索引是用 CREATE INDEX SQL 语句创建的。为支持 PRIMARY KEY 或 UNIQUE 约束,也可以隐式地创建索引。当创建唯一索引时,会检查键数据的唯一性,如果发现重复值,操作就失败。
可将索引创建为升序、降序或双向。所选择的选项取决于应用程序将如何访问数据。
2.索引名用于创建和删除索引。除此之外,查询或更新表时不使用索引名。
缺省情况下,索引以升序创建,但您也可以创建降序的索引。您甚至可以对索引中的多个列指定不同的顺序。
3.索引存储在表空间中。如果表驻留在数据库管理的表空间中,您可以选择将索引分别放到单独的表空间中。这必须在创建表的时候使用 INDEXES IN 子句来定义。表一旦创建,其索引的位置就固定了,除非删除而后重新创建,否则不能更改这一位置。
当然,DB2 也提供了 DROP INDEX SQL 语句用于从数据库中除去索引。索引是无法修改的。如果需要更改索引(例如,给键添加另一个列),必须删除而后重新创建它。
当在数据库中创建索引时,键以指定的次序存储。若查询请求以此指定次序存储的数据,则索引有助于提高这类查询的性能。升序索引还可用于确定 MIN 列函数的结果;降序索引用于确定 MAX 列函数的结果。如果应用程序需要数据同时以相反的顺序排序,DB2 允许创建双向索引。双向索引消除了创建逆向索引的需要,而且消除了用优化器按逆向排列数据的需要。它还允许高效地检索 MIN 和 MAX 函数值。要创建双向索引,可在 CREATE INDEX 语句上指定 ALLOW REVERSE SCANS 选项。
DB2 将不允许您用同一定义创建多个索引。这一点甚至适用于为支持主键或唯一性约束而隐式创建的索引。因此,既然 BOOKS 表已经有了对 BOOKID 列定义的主键,那么试图对 BOOKID 列创建索引的操作将会失败。
创建索引需要较长的时间。DB2 必须读每一行来抽取键,将那些键排序,然后将列表写到数据库。如果表很大,则用临时表空间对键进行排序。
3. 您可以在每个表上创建一个索引作为群集索引(clustering index)。当经常以特定次序引用表数据时,群集索引比较有用。群集索引定义数据在数据库中存储的次序。在插入期间,DB2 会试图将新的行放置得靠近有相似键的行。然后,在查询请求以群集索引序列排序的数据期间,可以更快地检索数据。
要将索引创建为群集索引,可在 CREATE INDEX 语句上指定 CLUSTER 子句。 CREATE INDEX IAUTHBKNAME ON BOOKS (AUTHORID,BOOKNAME) CLUSTER
4.在创建索引时,您可以选择包括额外的列数据,该数据与键存储在一起,但实际上并不属于键本身,而且不会被排序。在索引中包括额外的列主要是为了提高某些查询的性能:如果数据可在索引页中获得,DB2 就不需要访问数据页来获取它了。
CREATE UNIQUE INDEX IBOOKID ON BOOKS (BOOKID) INCLUDE(BOOKNAME)
那为什么不干脆在索引中包括所有数据呢?首先,这需要更多的数据库物理空间,因为必然要在索引复制表数据。其次,每当更新数据值时,数据的所有副本都需要得到更新,在有许多更新发生的数据库中,这将是极大的开销。
5.以下是创建索引时的一些考虑事项。
? 因为索引是持久的键值列表,它们在数据库中需要空间。因此创建许多索引将在数据库中需要较多的存储空间。所需的存储空间量由键列的长度决定。DB2 提供了一个工具来帮助您估计索引的大小。
?
? 索引是值的额外副本,所以如果表中的数据被更新,索引也必须被更新。如果表数据经常被更新,请考虑额外的索引对更新性能有什么样的影响。 当对适当的列定义了索引时,索引将极大地提高查询的性能。
第 1 页(共
3 页) 结束语
本教程讨论了 DB2 通用数据库中定义的数据类型、表、视图和索引的特性。它还向您演示了如何使用 CREATE、ALTER 和 DROP 语句来管理这些对象。
DB2 提供了一组丰富而又灵活的数据类型。数据类型分为内置数据类型和用户定义的数据类型。由 DB2 提供的内置数据类型有:
?
?
?
? 数字型:INTEGER、BIGINT、SMALLINT、DECIMAL、REAL、DOUBLE 和 FLOAT 字符串型:CHAR、VARCHAR、LONG VARCHAR、CLOB、GRAPHIC、VARGRAPHIC、LONG VARGRAPHIC、DBLOB 和 BLOB 日期时间型:DATE、TIME 和 TIMESTAMP 数据链接:DATALINK
DB2 还提供用于创建高级数据类型的工具:
?
?
? 用户定义的单值类型 用户定义的结构化类型 用户定义的引用类型
DB2 Extender 是用户定义的类型的应用程序。可以从 IBM 和其它软件供应商那里获得各种 DB2 Extender。一些可用的扩展器可用于文本、音频、视频、图像和 XML。
表保存着数据库中的数据。表的列由数据类型定义。可为表定义一些约束以提供数据验证。DB2 提供三种约束:
?
?
? 唯一性约束用于确保列中的值是唯一的。 参照完整性约束用于定义表之间的关系,并确保这些关系持续有效。 表检查约束用于验证列数据没有违反为列定义的规则。
视图允许不同的用户或应用程序以不同的方式查看同一数据。它不仅使数据更易于访问,而且可以利用它限制某些用户能够查看或更新的行和列。用 WITH CHECK OPTION 定义视图就是告诉 DB2 检查对视图的更新是否满足视图的条件。即使指定了嵌套视图,也能强制执行这种数据验证。
索引是表中一列或多列的键值的有序列表。创建索引是为了确保一列或多列中值的唯一性和/或提高对表进行查询的性能。DB2 优化器选择在执行查询时使用索引,以便更快地找到所需的行。DB2 提供 Index Advisor 来帮助确定要为指定的工作量创建哪些索引。
第六部分 数据并发性
在本教程中,您将了解:
?
?
?
?
?
? 数据一致性是什么 事务是什么以及如何启动和终止它们 在多用户环境中如何将事务彼此隔离开来 DB2 通用数据库如何通过使用锁来提供并发性控制 可以使用哪种类型的锁以及如何获取锁 哪些因素会影响锁定
要理解本教程所提供的一些内容,您应该熟悉下列术语:
?
? 对象:数据库中可以用 SQL 创建或操作的任何东西(例如,表、视图、索引、包)。 表:一种逻辑结构,用来将数据表示为有固定列数的无序行的集合。每个列都包含一组
值,列中所有的值都具有相同的数据类型(或是列数据类型的子类型);列的定义组成了表结构,而行包含实际表数据。
?
?
?
? 记录:表中一行的存储表示。 字段:表中一列的存储表示。 值:具体的数据项,位于数据库表中行与列的每个交叉点上。 结构化查询语言(Structured Query Language,SQL):用来在关系数据库中
定义对象和操作数据的标准化语言。(有关 SQL 的更多信息,请参阅本系列教程的第四篇。)
? 调用级接口(Call-Level Interface,CLI):用作 SQL 替代项的可调用应用程序
编程接口(Application Programming Interface,API)。与嵌入式 SQL 不同,CLI 不需要经过用户的预编译或绑定,而是提供了标准函数集,用来在应用程序运行时处理 SQL 语句和执行相关服务。
? DB2 优化器:SQL 预编译器的一个组件,它通过对几个不同的存取方案的执行成本进
行建模,并选择估计成本最低的一种来为数据操作语言(Data Manipulation
Language,DML)SQL 语句选择存取方案。
第一章 事务
1. 如果用户忘记了进行所有必要的更改(正如在我们的饭店示例中一样)、如果在用户进行更改的过程中系统崩溃了或者如果一个数据库应用程序由于某种原因过早地停止了,数据库中的数据都会变得不一致。当几个用户同时访问相同的数据库表时,也可能发生不一致。为了努力防止数据的不一致(尤其是在多用户环境中),DB2 通用数据库的开发人员将下列数据一致性支持机制合并到其设计中:
?
?
? 事务 隔离级别 锁
2. 事务(也称为工作单元)是一种将一个或多个 SQL 操作组合成一个单元的可恢复序列,通常位于应用程序进程中。事务的启动和终止定义了数据库一致性点;要么将事务中执行的所有 SQL 操作的结果都应用于数据库,要么彻底取消并丢弃已执行的所有 SQL 操作的结果。 在大多数情况下,通过执行 COMMIT 或 ROLLBACK 语句来终止事务。当您执行 COMMIT 语句时,您从事务启动以来对数据库所作的一切更改就成为永久性的了 — 也即,它们是已提交的。当您执行 ROLLBACK 语句时,您从事务启动以来对数据库所作的一切更改都被撤消,而数据库返回 — 或回滚 — 到事务开始之前所处的状态。不管哪种情况,数据库在事务完成时都保证能回到一致状态。
注意:虽然事务通过确保对数据的更改仅在事务被成功提交之后才成为永久性的,从而提供了一般的数据库一致性,但还是需要用户或应用程序来确保每个事务中的 SQL 操作序列始终会产生一致的数据库(即逻辑正确性),这一点很重要。
3. 提交或回滚操作只影响本该提交或回滚操作所结束的事务内作出的更改。只要数据更改未被提交,其它用户和应用程序通常就无法看见它们(也有例外情况,稍后我们将进行研究),并可以用回滚操作取消它们。但是,一旦数据更改被提交了,其它用户和应用程序就可以访问它们,并且再也不能通过回滚操作来取消它们了。
4.但是如果在事务完成前出现系统故障,那会发生什么情况呢?在此类情况下 DB2 数据库管理器会取消所有未提交的更改,以便恢复到在事务启动时的数据库一致性(假定存在这样的一致性)。这是通过使用事务日志文件完成的,这些文件包含关于事务所执行的每个 SQL 语句的信息,以及关于该事务是否被成功提交或回滚的信息。
第二章 并发性和隔离级别
1. 在多用户数据库环境下,多个事务可以同步执行,并且每个事务都有可能与其它正在运行的事务发生冲突。在多用户环境下,如果不将事务彼此隔离开来,就会发生四种现象:
? 丢失更新(Lost update):这种事件发生在两个事务读取和尝试更新同一数据时,其
中一个更新会丢失。例如:事务 1 和事务 2 读取同一行数据,并都根据所读取的数据计算出该行的新值。如果事务 1 用其新值更新该行以后,事务 2 又更新了同一行,则事务 1 所执行的更新操作就丢失了。由于设计的方法,DB2 通用数据库不允许发生此类现象。
? 脏读(Dirty read):当事务读取尚未提交的数据时,就会发生这种事件。例如:事务 1
更改了一行数据,而事务 2 在事务 1 提交更改之前读取了已更改的行。如果事务 1 回滚该更改,则事务 2 就会读取被认为是不曾存在的数据。
? 不可重复的读(Nonrepeatable read):当一个事务两次读取同一行数据,但每次获
得不同的数据值时,就会发生这种事件。例如:事务 1 读取了一行数据,而事务 2 在
更改或删除该行后提交了更改。当事务 1 尝试再次读取该行时,它会检索到不同的数据值(如果该行已经被更新的话),或发现该行不复存在了(如果该行被删除的话)。 ? 幻像(Phantom):当最初没有看到某个与搜索条件匹配的数据行,而在稍后的读操作
中又看到该行时,就会发生这种事件。例如:事务 1 读取满足某个搜索条件的一组数据行,而事务 2 插入了与事务 1 搜索条件匹配的新行。如果事务 1 再次执行产生原先行集的查询,则会检索到不同的行集。
维护数据库一致性和数据完整性,但又允许多个应用程序同时访问同一数据,这样的特性称为并发性。DB2 通用数据库尝试用来强制执行并发性的方法之一是通过使用隔离级别,它决定在第一个事务访问数据时,如何对其它事务锁定或隔离该事务所使用的数据。DB2 通用数据库使用下列隔离级别来强制执行并发性:
?
?
?
? 可重复的读(Repeatable Read) 读稳定性(Read Stability) 游标稳定性(Cursor Stability) 未提交的读(Uncommitted Read)
2. 当使用可重复的读隔离级别时,在单个事务执行期间锁定该事务引用的所有行。使用这种隔离级别时,同一事务多次发出的同一个 SELECT 语句将始终产生同一结果;丢失更新、脏读、不可重复的读、幻像都不会发生。
使用可重复的读隔离级别的事务可以多次检索同一行集,并可以对它们执行任意次操作,直到由提交或回滚操作终止事务;不允许其它事务执行插入、更新或删除操作,因为这些操作会在隔离事务存在期间影响正在被使用的行集。
那么在现实环境中这个隔离级别是如何工作的呢?假定您拥有一家大型旅馆,并有一个网站,该网站按―先到先服务‖的原则接受客户的房间预订。如果您的旅馆预订应用程序是在―可重复的读‖隔离级别下运行的,当客户检索某个日期段内的所有可用房间列表时,您将无法更改那些房间在指定日期范围内的费用,而其他客户也将无法进行或取消将会更改该列表的预订,直到生成该列表的事务终止为止。(对于第一个客户的查询所指定范围之外的任何房间,您都可以更改房价,其他客户也都可以进行或取消房间预订。)
3. 当使用读稳定性隔离级别时,在单个事务执行期间,会锁定该事务所检索的所有行。当使用这种隔离级别时,直到隔离事务终止之前,其它事务不能更改隔离事务读取的所有行。此外,其它事务对其它行所作的更改,在提交之前对于运行在―读稳定性‖隔离级别下的事务而言是不可见的。因此,当使用―读稳定性‖隔离级别时,在同一事务中多次发出 SELECT 语句可能会产生不同的结果。丢失更新、脏读和不可重复的读都不会发生;但是,有可能出现幻像。
使用―可重复的读‖隔离级别时,隔离事务引用的每一行都被锁定;但是,在―读稳定性‖隔离级别下,只锁定隔离事务实际检索和/或修改的行。因此,如果一个事务扫描了 1000 行但只检索 10 行,则只有被检索到的 10 行(而不是所扫描的 1000 行)被锁定。
那么,这种隔离级别会如何改变旅馆预订应用程序的工作方式呢?现在,当一个客户检索某个日期段内的所有可用房间列表时,您可以更改旅馆中任何房间的房价,而其他客户也可以取消在第
一个客户的查询所指定的日期段内所保留房间的预订。因此,如果在终止提交查询的事务之前再次生成列表,则产生的新列表中有可能包含新的房价或第一次产生列表时不可用的房间。 4. 当使用游标稳定性隔离级别时,只要隔离事务所用的游标定位在某一行上,就会锁定该游标所引用的这一行。所获取的锁一直有效,直到游标重定位(通常通过调用 FETCH 语句)或隔离事务终止为止。因此,当使用这种隔离级别时,在同一事务中多次发出 SELECT 语句可能会产生不同的结果。丢失更新和脏读不会发生;但有可能出现不可重复的读和幻像。
当使用―游标稳定性‖隔离级别的事务通过可更新游标从表中检索行时,在游标定位在该行上时,其它事务不能更新或删除该行。但是,如果被锁定的行本身不是用索引访问的,那么其它事务可以将新的行添加到表,并对位于被锁定行前后的行进行更新和/或删除操作。此外,如果隔离事务修改了它检索到的任何行,那么在隔离事务终止之前,即使在游标不再位于这个被修改的行,其它事务不能更新或删除该行。
其它事务在其它行上进行的更改,在提交之前对于使用―游标稳定性‖隔离级别的事务是不可见的。缺省情况下,大多数事务都使用―游标稳定性‖隔离级别。
这种隔离级别对旅馆预订应用程序有什么影响呢?现在,当一个客户检索某个日期段内的所有可用房间列表,然后查看关于所产生的列表上每个房间的信息时(每次查看一个房间),您可以更改旅馆中任何房间的房价,而其他客户可以对任何日期段的任何房间进行或取消预订;唯一的例外是第一个客户当前正在查看的房间。当第一个客户查看列表中另一个房间的信息时,对于这个新房间也是一样;您现在可以更改第一个客户刚才查看的房间的房价,其他客户也可以预订该房间,但不能对第一个客户当前正在查看的房间进行这些操作。
5. 在使用未提交的读隔离级别的情况中,当单个事务检索行时,仅当另一个事务试图删除或更改被检索的行所在的表时,才会在单个事务期间锁定这些行。因为在使用这种隔离级别时,行通常保持未锁定状态,所以丢失更新、脏读、不可重复的读和幻像都可能会发生。
在大多数情况下,其它事务对行所作的更改,在提交或回滚之前对于使用―未提交的读‖隔离级别的事务是可见的。但是,此类事务不能看见或访问其它事务所创建的表、视图或索引,直到那些事务被提交为止。
―未提交的读‖隔离级别通常用于那些访问只读表的事务和/或某些执行 SELECT 语句的事务,这些语句对其它事务的未提交数据没有负面效果。
那么这种隔离级别对旅馆预订应用程序有什么影响呢?现在,当一个客户检索某个日期段内的所有可用房间列表时,您可以更改旅馆中任何房间的房价,而其它客户也可以对任何日期段内的任何房间进行或取消预订。此外,如果其它客户取消了预订,即使他们还没有终止其事务并将那些取消提交到数据库,所生成的列表就可以包含这些取消预订的房间了。
6. 选择用于事务的适当隔离级别是非常重要的。隔离级别不仅影响数据库如何很好地支持并发性;而且影响包含该事务的应用程序的整体性能。这是因为获取和释放锁所需的资源因隔离级别而异。
通常,使用的隔离级别越严格,对并发性提供的支持就越少,而整体性能可能会越低,因为要获取并占有更多的资源。但是,当您确定将要使用的最佳隔离级别时,应该通过确定哪些现象可接受而哪些现象不可接受来进行决策。下列推断可以用来帮助您确定在特定环境中使用哪种隔离级别:
?
?
?
? 如果您正在只读数据库上执行查询,或者正在执行查询而不考虑是否有未提交的数据值返回,则使用―未提交的读‖隔离级别。(需要是只读事务 — 不需要较高的数据稳定性。) 如果您希望在不看见未提交数据值的情况下获得最大的并发性,则使用―游标稳定性‖隔离级别。(需要是读/写事务 — 不需要较高的数据稳定性。) 如果您希望获得并发性,并希望限定的行在单个事务执行期间保持稳定,则使用―读稳定性‖隔离级别。(需要是只读或读/写事务 — 需要较高的数据稳定性。) 如果您正在执行查询,并且不希望看到对产生的结果数据集进行更改,则使用―可重复
的读‖隔离级别。(需要是只读事务 — 需要极高的数据稳定性。)
第三章 锁
1. 锁是一种用来将数据资源与单个事务关联起来的机制,其用途是当某个资源与拥有它的事务关联在一起时,控制其它事务如何与该资源交互。如果一个事务尝试访问数据资源的方式与另一个事务所持有的锁不兼容(稍后我们将研究锁兼容性),则该事务必须等待,直到拥有锁的事务终止为止。这被称为锁等待。当锁等待事件发生时,尝试访问数据资源的事务所要做的只是停止执行,直到拥有锁的事务终止和不兼容的锁被释放为止。
2.所有的锁都有下列基本属性:
?
? Object:object 属性标识了要锁定的数据资源。DB2 数据库管理器在需要时锁定数据资源(如表空间、表和行)。 Size:size 属性指定要锁定的数据资源部分的物理大小。锁并不总是必须控制整个数
据资源。例如,DB2 数据库管理器可以让应用程序独占地控制表中的特定行,而不是让该应用程序独占地控制整个表。
?
? Duration:duration 属性指定了锁被持有的时间长度。事务的隔离级别通常控制了锁的持续时间。 Mode:mode 属性指定了锁的拥有者所允许的访问类型,以及对锁定数据资源的并发
用户许可的访问类型。这个属性通常称为锁状态。
3.锁状态确定了对锁的所有者允许的访问类型,以及对锁定数据资源的并发用户许可的访问类型。下面的列表说明了可用的锁状态,按照递增控制排序:
锁状态(模式):
适用对象:
描述: 意向无(Intent None,IN) 表空间和表 锁的拥有者可以读取锁定表中的数据(包括未提交数据),但不能更改这些数据。在这种模式中,锁的拥有者不获取行级别的锁;
因此,其它并发应用程序可以读取和更改表中的数据。
锁状态(模式): 适用对象: 描述:
锁状态(模式): 适用对象: 描述:
锁状态(模式): 适用对象: 描述:
锁状态(模式): 适用对象: 描述:
锁状态(模式): 适用对象: 描述:
锁状态(模式):
适用对象: 意向共享(Intent Share,IS) 表空间和表 锁的拥有者可以读取锁定表中的数据,但不能更改这些数据。同样,因为锁的拥有者不获取行级别锁;所以,其它并发的应用程序仍可以读取和更改表中的数据。(当事务拥有表上的意向共享锁时,就在它所读取的每个行上进行共享锁定。)当事务不传达更新表中行的意图时,就获取这种锁。 下一键共享(Next Key Share,NS) 行 锁拥有者和所有并发的事务都可以读(但不能更改)锁定行中的数据。这种锁用来在使用“读稳定性”或“游标稳定性”事务隔离级别读取的数据上代替共享锁。 共享(S) 表和行 锁拥有者和任何其它并发的事务都可以读(但不能更改)锁定的表或行中的数据。只要表不是使用共享锁锁定的,那么该表中的单个行可以使用共享锁锁定。但是,如果表是用共享锁定的,则锁拥有者不能在该表中获取行级别的共享锁。如果表或行是用共享锁锁定的,则其它并发事务可以读取数据,但不能对它进行更改。 意向互斥(Intent Exclusive,IX) 表空间和表 锁拥有者和任何其它并发的应用程序都可以读取和更改被锁定表中的数据。当锁拥有者从表读取数据时,它在所读取的每一行上获取一个共享锁,而在它更新的每一行上获取更新和互斥锁。其它并发的应用程序可以读取和更新锁定的表。当事务传达更新表中行的意图时,就获取这种锁。(SELECT FOR UPDATE、UPDATE ... WHERE 和 INSERT 语句传达更新的意图。) 带意向互斥的共享(Share With Intent Exclusive,SIX) 表 锁拥有者可以读取和更改被锁定表中的数据。锁拥有者在它更新的行上获取互斥锁,但不获取它读取的行上的锁;因此,其它并发的应用程序可以读取但不能更新被锁定表中的数据。 更新(Update,U) 表和行
锁的拥有者可以更新被锁定表中的数据,并且锁的拥有者在它所
描述: 更新的任何行上自动获得互斥锁。其它并发的应用程序可以但不
能更新被锁定表中的数据。
下一键互斥(Next Key Exclusive,NX)
行
锁的拥有者可以读取但不能更新被锁定的行。当在表的索引中插
入或删除行时,表中的下一行上将获得这种锁。
下一键弱互斥(Next Key Weak Exclusive,NW)
行
锁的拥有者可以读取但不能更新被锁定的行。当向非目录表的索
引插入行时,表中下一行上就获得这种锁。
互斥(Exclusive,X)
表和行
锁的拥有者可以读取和更改被锁定的表或行中的数据。如果获取
描述: 了互斥锁,则只允许使用“未提交的读”隔离级别的应用程序访
问被锁定的表或行(多行)。对于用 、 和/或 语句操作
的数据资源,将获取互斥锁。
弱互斥(Weak Exclusive,WE)
行
锁的拥有者可以读取和更改被锁定的行。当向非目录表中插入行
时,该行上将获得这种锁。
超级互斥(Super Exclusive,Z)
表空间和表
锁的拥有者可以更改表、删除表、创建索引或删除索引。当事务
描述: 尝试执行上述任何一种操作时,表上就自动获得这种锁。在除去
这个锁之前,不允许其它并发事务读取或更新该表。
3.如果数据资源上的一种锁状态允许在同一资源上放置另一个锁,就认为这两种锁(或两种状态)是兼容的。每当一个事务持有数据资源上的锁,而第二个事务请求同一资源上的锁时,DB2 数据库管理器检查两种锁状态以确定它们是否兼容。如果锁是兼容的,则将锁授予第二个事务(假定没有其它事务在等待该数据资源)。但是,如果锁不兼容,则第二个事务必须等待,直到第一个事务释放它的锁为止,然后才可以获取对资源的访问权并继续处理。 锁状态(模式): 适用对象: 描述: 锁状态(模式): 适用对象: 描述: 锁状态(模式): 适用对象: 锁状态(模式): 适用对象: 描述: 锁状态(模式): 适用对象:
4.当事务尝试访问它已经持有锁的数据资源,并且所需的访问模式需要比已持有的锁更严格的锁时,则所持有的锁的状态更改成更严格的状态。将已经持有的锁的状态更改成更严格状态的操作称为锁转换。锁转换的发生是因为一个事务同一时间内只能在一个数据资源上持有一个锁。 5.所有的锁都需要存储空间;因为可用空间并不是无限的,所以 DB2 数据库管理器必须限制锁可以使用的空间(这是通过 maxlocks 数据库配置参数完成的)。为了防止特定数据库代理超过已建立的锁空间限制,当获取的(任意类型的)锁过多时,会自动执行称为锁升级的进程。锁升级是一种转换,它将同一表内几个单独的行级锁转换成一个单独的表级锁。因为锁定升级是在内部处理的,所以唯一可从外部检测到的结果可能只是对一个和多个表的并发访问减少了。 以下是锁定升级的工作原理:当事务请求锁,而锁存储空间已满时,就选定与该事务相关联的一个表,帮它获取一个表级锁,释放所有该表的行级锁(以在锁列表数据结构中创建空间),并将表级锁添加到锁列表。如果这个过程所释放的空间不够,则选定另一个表,重复这个过程,直到释放了足够的可用空间为止。这时,事务将获取所请求的锁并继续执行。但是,如果在该事务的所有行级锁都已经升级之后,仍然没有获得必要的可用锁空间,则(通过 SQL 错误代码)要求事务提交或回滚它启动以来所作的所有更改,然后事务终止。
6.DB2 通用数据库用于处理死锁的工具是称为死锁检测器的异步系统后台进程。死锁检测器的唯一职责是定位和解决在锁定子系统中找到的任何死锁。死锁检测器在大多数时间处于休眠状态,但会在预置的时间间隔被―唤醒‖,以确定是否存在死锁状况。如果死锁检测器在锁定子系统中发现死锁,则选择死锁涉及的一个事务、终止并回滚它。(被终止和回滚的事务收到一个 SQL 错误代码,它所获得的所有锁都被释放。)通常,剩下的一个或多个事务就可以继续执行了。 7.任何时候当一个事务在特定数据资源(例如,表或行)上持有锁时,直到持有锁的事务终止并释放它所获取的所有锁之前,其它事务对该资源的访问都可能被拒绝。如果没有某种适当的锁超时检测机制,则事务可能无限期地等待锁的释放。要避免发生此类情况时阻碍其它应用程序的执行,可以在数据库的配置文件中指定锁超时值(通过 locktimeout数据库配置参数)。使用之后,该参数就控制任何事务将等待获取所请求的锁的时间。如果在指定的时间间隔过去之后还未获得想要的锁,则等待的应用程序接收一个错误,并回滚请求该锁的事务。分布式事务应用程序环境特别容易产生此类超时;可以通过使用锁超时避免它们。
8.在大多数情况下,DB2 数据库管理器在需要锁时隐式地获取它们,因此锁在 DB2 数据库管理器的控制之下。除了使用―未提交的读‖隔离级别的情况外,事务从不需要显式地请求锁。实际上,唯一有可能被事务显式地锁定的数据库对象是表对象。
下面的图说明了所引用的对象是用何种逻辑确定获取什么类型的锁的:

DB2 数据库管理器总是尝试获取行级锁。但是,可以通过执行特殊形式的 ALTER TABLE 语句来修改这种行为,如下所示:
ALTER TABLE [TableName] LOCKSIZE TABLE
其中 TableName 标识一个现有表的名称,所有事务在访问它时都要获取表级锁。
也可以通过执行 LOCK TABL 语句,强制 DB2 数据库管理器为特定事务在表上获取表级锁,如下所示:
LOCK TABLE [TableName] IN [SHARE | EXCLUSIVE] MODE
其中 TableName 标识了现有表的名称,对于这种表应该获取表级锁(假定其它事务在该表上没有不兼容的锁)。如果在执行这个语句时指定了共享(SHARE)模式,就会获得一个允许其它事务读取(但不能更改)存储在其中的数据的表级锁;如果执行时指定了互斥(EXCLUSIVE)模式,就会获得一个不允许其它事务读取或修改存储在表中的数据的表级锁。
9. 正如我们先前提到的,任何时候当一个事务在特定数据资源上持有锁时,在持有锁的事务终止之前,其它事务对该资源的访问都可能被拒绝。因此,为了进行优化以获取最大并发性,行级锁通常比表级锁更好,因为它们所限制访问的资源要小得多。但是,因为所获取的每个锁都需要一定数量的存储空间,并需要处理时间才能进行管理,所以单个表级锁需要的开销比几个单独的行级锁少。除非另有指定,否则缺省情况下获取行级锁。
可以通过使用 ALTER TABLE ... LOCKSIZE TABLE、ALTER TABLE ... LOCKSIZE ROW 和 LOCK TABLE 语句控制锁的颗粒度(获取行级锁还是表级锁)。ALTER TABLE ... LOCKSIZE TABLE 语句提供了确定颗粒度的全局方法,它使得所有访问特定表中行的事务都获取表级锁。
第四章 影响锁定的因素
从锁定的角度来看,所有事务一般都可以归为以下几类:
?
?
?
? 只读:这是指这样的事务,它们包含 SELECT 语句(它原本就是只读的)、指定了 FOR READ ONLY 子句的 SELECT 语句或意义虽不明确但因为在预编译和/或绑定过程中指定了 BLOCKING 选项而可以看作是只读的 SQL 语句。 倾向于更改:这是指这样的事务,它们包含指定了 FOR UPDATE 子句的 SELECT 语句或者那些意义虽不明确但因为 SQL 预编译器解释它的方式而可以看作是倾向于进行更改的 SQL 语句。 更改:这是指这样的事务,它们包含 INSERT、UPDATE 和/或 DELETE 语句,但不包括 UPDATE ... WHERE CURRENT OF ... 或 DELETE ... WHERE CURRENT OF ... 语句。 游标控制:这是指这样的事务,它们包含 UPDATE ... WHERE CURRENT OF ... 和 DELETE ... WHERE CURRENT OF ... 语句。
―只读‖事务通常使用意向共享(IS)和/或共享(S)锁。另一方面,―倾向于更改‖的事务将更新(U)、意向互斥(IX)和互斥(X)锁用于表,将共享(S)、更新(U)和互斥(X)锁用于行。―更改‖事务则往往使用意向互斥(IX)和/或互斥(X)锁,而―游标控制‖的事务通常使用意向互斥(IX)和/或互斥(X)锁。
存取计划可以使用两种方法之一来访问表中的数据:通过直接地读取表(称为执行表或关系扫描)或通过读取该表上的索引,然后检索特定索引项所引用表中的行(称为执行索引扫描)。