
“数据结构与算法”
课程设计报告

(一) 需求和规格说明
课题:K-means(K均值)算法是一种聚类算法。实现K-means算法。要求输入一个班级同学3门以上课程的百分制成绩,通过K-means聚类输出A、B、C、D和E 5级制成绩。
分析:k-means 算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
本课题的目的便是利用K-means算法实现对学生多门成绩的等级划分;因为要求数据中每位同学的学科科目数三门以上,所以,我打算先求出他们的各自平均成绩,以平均成绩作为K-means聚类的实际输入数据;
(二) 设计
根据上述要求,要完成此课题,首先需要解决一下几个问题:
1.如何将原始数据处理成Kmeans聚类所要求的数据AllData
解决方案:利用之前程序设计实验中读取图文件的方法。
2.如何产生初始聚类质心
解决方案:采用产生随机数的方法,随机产生k(K<N)个数据数组的序号。
3.如何计算质心
解决方案:因为本课题处理的数据是一维数据,可以通过计算每簇集合数据的平均值作为其质心。
4.如何控制算法迭代结束(即何时聚类成功)
解决方案::通过保存上次聚类的质心CenterCopy,与本次聚类质心Center相比较;另外设置最大迭代次数MaxIterN,超过最大迭代次数也将停止。
主要算法思想
k-means 算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
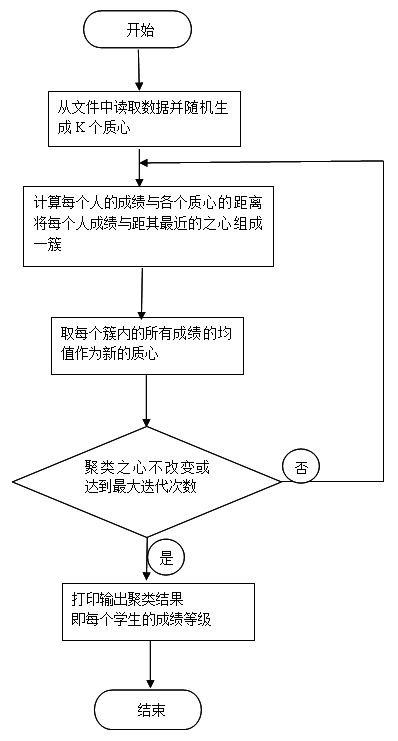
算法流程
1.先从原始数据文件中读取所需的数据
2.对数据进行初始化,产生初始化聚类中心和各个聚类
3.进行循环迭代直到满足质心相等或者达到最大迭代次数
4.打印输出结果

算法流程图如下
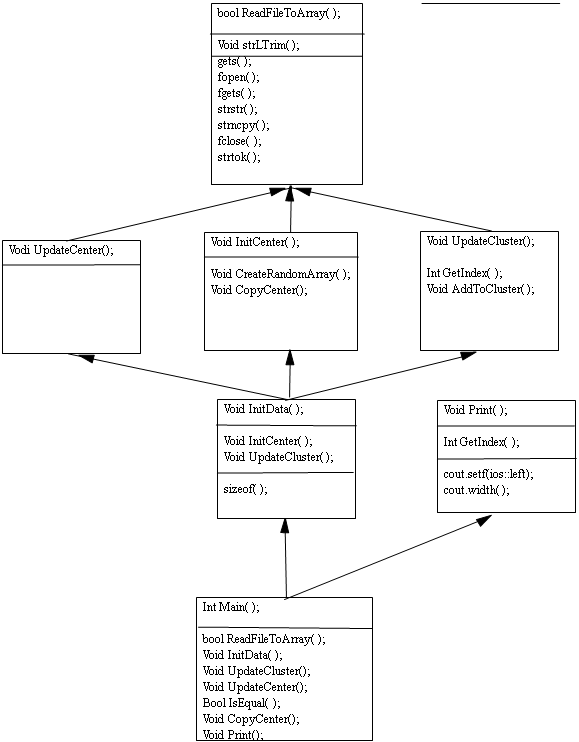
系统图类

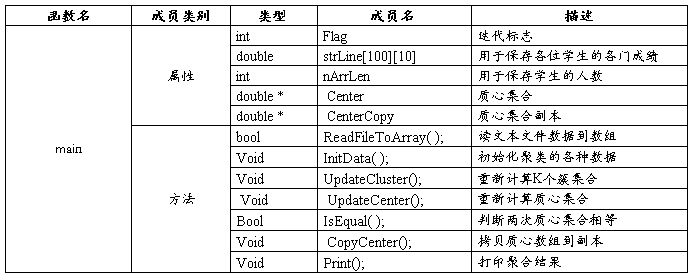
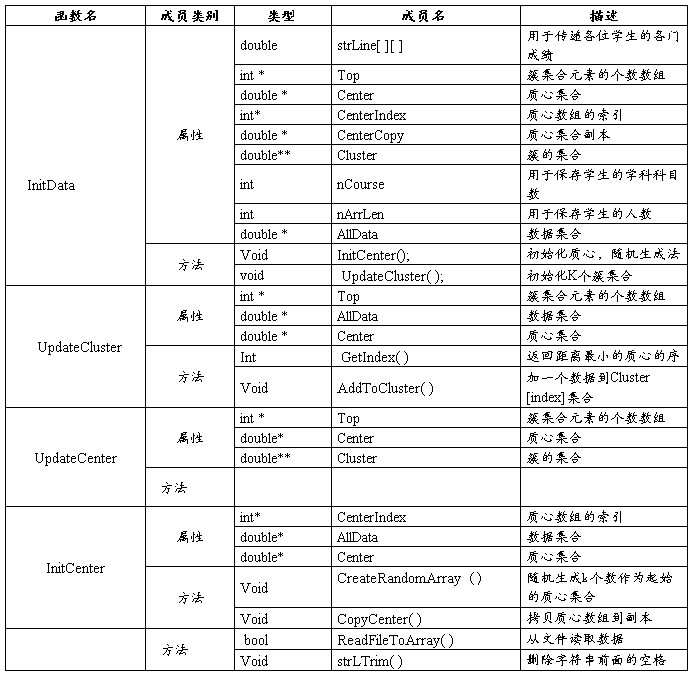
属性和方法定义
(三) 用户手册
程序运行开始:
提示信息1:Please Input fileName(.txt):
请输入需要处理的文件名 (文件扩展名.txt) : 比如 Kmeans.txt或者kmeans1.txt (用户可以根据数据文件格式要求自己创建数据文件)
提示信息2:Please Input Number Of Class:
请输入聚类数(这里指成绩等级数):比如5
(四) 调试及测试
设计中遇到很多问题:
1.如何使输出的数据对齐
解决方法:通过在网上搜索,查到cout.setf(ios::left)可以使输出数据在本域宽度范围内向左对齐,setf是设置输出格式状态的,括号中的就是要求的格式状态;而cout.width()则可以设置输出数据所占用域的宽度
2.如何保存并输出学生的姓名
解决方法:读数据时,成绩和姓名均是以字符串的形式读出来,然后进行分割,在分割姓名时直接将分割出来的字符串保存到姓名的字符串数组即可,分割成绩时,需要用atoi( )将字符串转换成长整形数
程序运行的时空效率分析
时间复杂度:O(tKmn),其中,t为迭代次数,K为簇的数目,m为记录数,n为维数
空间复杂度:O((m+K)n),其中,K为簇的数目,m为记录数,n为维数
(五)运行实例:
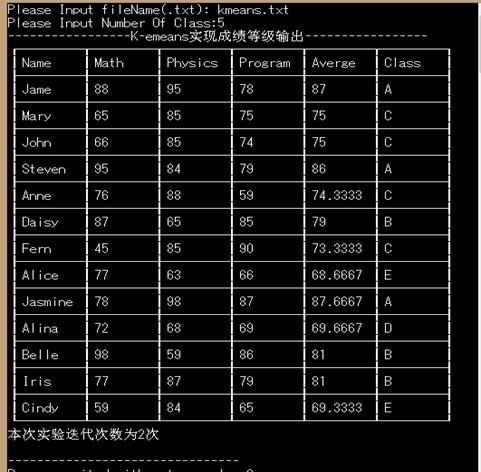
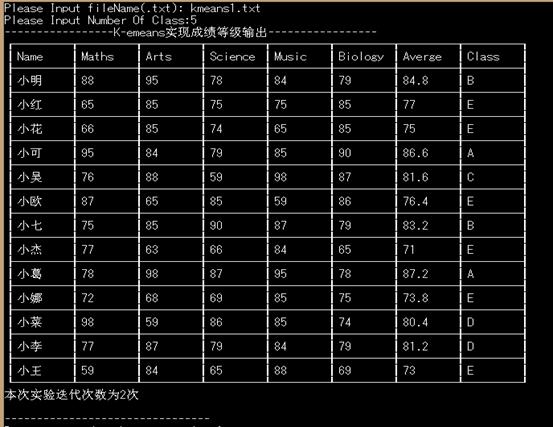
(六)进一步改进
原来的程序只是简单的输出原成绩和对应的成绩等级,但是输出来的数据给人感觉很乱。那么,在这次设计中,我采用表格的方式输出相应的数据,通过记录数据段数,用其来控制循环输出表格的中间环节,从而达到根据数据段的多少输出相应长度的表格的目的。
(七)心得体会
经过此次课程设计,我深刻体会到自己所学的知识得到实际运用的快感,很开心。也许课程设计的开始让我感觉手足无措,甚至我有所畏惧,不敢下手去做;而且,过程是让人很烦躁的,不停出现各种各样从没有见过的问题,却只能自己解决。自己总是苦恼着难题,然而,苦恼了一天的难题,第二天醒来再去思考时,总会很快就可以解决掉问题,这还是让我很开心的。课程设计给我的整体感觉还是很受益的,毕竟是自己独自完成了一项设计,从头到尾,查找资料,实施方案,不断修正方案,最终实现课题的要求。虽然这只是一点点小成就,但还是感觉自己很棒!
(八)对课程设计的建议
课程设计是项很有效的训练专业能力的方式,那么我觉得,在老师认为学生的能力可以完成相应课题的情况下,尽可能早的让学生接受各种课程设计的训练,可以帮助学生早日成为实践的有能力者而不是纯粹的理论优秀者。
(九)附录¾¾源程序
#include <iostream>
using namespace std;
#include <math.h>
#include <cstring>
#include <stdlib.h>
#include <time.h>
#define PRECIS 0.1 //质心变化需满足此最小精度,才可认为质心不变
#define MaxIterN 10 //最大迭代次数,控制迭代的结束
int N;//数据个数
int K;//集合个数
int* CenterIndex;//初始化质心数组的索引
double * Center;//质心集合
double * CenterCopy;//质心集合副本
double * AllData;//数据集合
double** Cluster;//簇的集合
int * Top;//集合中元素的个数,也会用作栈处理
char fileName[30]; //用于存放kmeans的数据文件名
double strLine[100][10];// 用于保存各位学生的各门成绩
int nArrLen;//用于保存学生的人数
int nCourse;//用于保存学生的学科科目数
string Name[100];//存放各位学生的名字
string item[10];//用于保存项目栏
//随机生成k个数x(0<=x<=n-1)作为起始的质心集合
void CreateRandomArray(int n, int k,int * center) {
int i=0;
int j=0;
srand( (unsigned)time( NULL ) );
for( i=0;i<k;++i)//随机生成k个数
{ int a=rand()%n; //判重
for(j=0;j<i;j++)
{ if(center[j]==a)//重复
{ break;
}
}
if(j>=i)//如果不重复,加入
{ center[i]=a;
}
else { i--; //如果重复,本次重新随机生成
}
}
}
//返回距离最小的质心的序
int GetIndex(double value,double * center) {
int i=0;
int index=i;//最小的质心序号
double min=fabs(value-center[i]);//距质心最小距离
for(i=0;i<K;i++)
{ if(fabs(value-center[i])<min)//如果比当前距离还小,更新最小的质心序号和距离值
{ index=i;
min=fabs(value-center[i]);
}
}
return index;
}
//拷贝质心数组到副本
void CopyCenter() {
int i=0;
for(i=0;i<K;i++)
{
CenterCopy[i]=Center[i];
}
}
//初始化质心,随机生成法
void InitCenter() {
int i=0;
CreateRandomArray(N,K,CenterIndex);//产生随机的K个<N的不同的序列
for(i=0;i<K;i++) {
Center[i]=AllData[CenterIndex[i]];//将对应数据赋值给质心数组
}
CopyCenter();//拷贝到质心副本
}
//加入一个数据到一个Cluster[index]集合
void AddToCluster(int index,double value) {
Cluster[index][Top[index]++]=value;//这里同进栈操作
}
//重新计算簇集合
void UpdateCluster()
{ int i=0;
int tindex; //将所有的集合清空,即将TOP置0
for(i=0;i<K;i++){
Top[i]=0;
}
for(i=0;i<N;i++){
tindex=GetIndex(AllData[i],Center);//得到与当前数据最小的质心索引
AddToCluster(tindex,AllData[i]); //加入到相应的集合中
}
}
//重新计算质心集合,对每一簇集合中的元素加总求平均即可
void UpdateCenter() {
int i=0;
int j=0;
double sum=0;
for(i=0;i<K;i++) {
sum=0; //计算簇i的元素和
for(j=0;j<Top[i];j++) {
sum+=Cluster[i][j];
}
if(Top[i]>0)//如果该簇元素不为空
{ Center[i]=sum/Top[i];//求其平均值
}
}
}
//判断2数组元素是否相等
bool IsEqual(double* center1 ,double * center2) {
int i;
for(i=0;i<K;i++)
{
if(fabs(center1[i]!=center2[i])>PRECIS)
{
return false;
}
}
return true;
}
//打印聚合结果
void Print() {
int i=0,j=0,r=0;
/* printf("-------------------------------------- \n");
for(i=0;i<K;i++)
{
printf("第%d组: 质心(%f)",i,Center[i]);
for(j=0;j<Top[i];j++)
{
printf("%f ",Cluster[i][j]);
}
printf("\n");
}
*/ for(i=0;i<nArrLen;i++)
strLine[i][nCourse]='A';
for(i=0;i<nArrLen;i++){
int m=GetIndex(AllData[i],Center);
for(j=0;j<K;j++)
if(Center[m]<Center[j]){
strLine[i][nCourse]++;
}
}
cout.setf(ios::left); //控制输出的数据左对齐
cout<<"-----------------K-emeans实现成绩等级输出-----------------"<<endl;
cout<<"┌————┬";
for(r=0;r<nCourse+1;r++)
cout<<"————┬";
cout<<"————┐"<<endl;
cout<<"│";cout.width(8);cout<<item[0];
for(r=0;r<nCourse+1;r++){
cout<<"│";cout.width(8);cout<<item[r+1];}
cout<<"│";cout.width(8);cout<<item[nCourse+2]<<"│"<<endl;
cout<<"├————┼";
for(r=0;r<nCourse+1;r++)
cout<<"————┼";
cout<<"————┤"<<endl;
for(i=0;i<nArrLen;i++){
cout<<"│";cout.width(8);cout<<Name[i];
for(j=0;j<nCourse;j++){
cout<<"│";cout.width(8);cout<<strLine[i][j];
}
cout<<"│";cout.width(8);cout<<AllData[i];
cout<<"│";cout.width(8);cout<<(char)strLine[i][nCourse]<<"│"<<endl;
if(i!=nArrLen-1) {
cout<<"├————┼";
for(r=0;r<nCourse+1;r++)
cout<<"————┼";
cout<<"————┤"<<endl;
}
else {
cout<<"└————┴";
for(r=0;r<nCourse+1;r++)
cout<<"────┴";
cout<<"————┘"<<endl;
}
}
}
//初始化聚类的各种数据
void InitData(double strLine[100][10]){
int i=0,j=0; int a; double sum;
N=nArrLen;
cout<<"Please Input Number Of Class:";
cin>>K;
if(K>N){
exit(0);
}
Center=(double *)malloc(sizeof(double)*K);
//为质心集合申请空间
CenterIndex=(int *)malloc(sizeof(int)*K);
//为质心集合索引申请空间
CenterCopy=(double *)malloc(sizeof(double)*K);
//为质心集合副本申请空间
Top=(int *)malloc(sizeof(int)*K);
AllData=(double *)malloc(sizeof(double)*N);
//为数据集合申请空间
Cluster=(double**)malloc(sizeof(double *)*K);
//为簇集合申请空间
//初始化K个簇集合
for(i=0;i<K;i++)
{
Cluster[i]=(double *)malloc(sizeof(double)*N);
Top[i]=0;
}
for(i=0;i<N;i++){
sum=0;
for(j=0;j<nCourse;j++)
sum+=strLine[i][j];
AllData[i]=sum/nCourse;
}
InitCenter();//初始化质心集合
UpdateCluster();//初始化K个簇集合
}
//删除字符串、字符数组左边空格
void strLTrim(char* str)
{
int i,j;
int n=0;
n=strlen(str)+1;
for(i=0;i<n;i++)
{
if(str[i]!=' ') //找到左起第一个非空格位置
break;
}
//以第一个非空格字符为首字符移动字符串
for(j=0;j<n;j++)
{
str[j]=str[i];
i++;
}
}
//文本文件数据读入到数组中,同时返回结点数量
bool ReadFileToArray(double strLine[100][10], int & nArrLen)
{
//读文本文件数据到数组,返回数组及其长度
FILE* pFile; //定义kmeans的文件指针
char str[1000]; //存放读出一行文本的字符串
char strTemp[10]; //判断是否注释行
printf("Please Input fileName(.txt): ");
gets(fileName); // 输入文件名.txt
pFile=fopen(fileName,"r");
if(!pFile)
{
cout<<"错误:文件"<<fileName<<"打开失败。"<<endl;
return false;
}
while(fgets(str,1000,pFile)!=NULL) //跳过空行和注释行
{
//删除字符串左边空格
strLTrim(str);
if (str[0]=='\n') //空行,继续读取下一行
continue;
strncpy(strTemp,str,2);
if(strstr(strTemp,"//")!=NULL) //跳过注释行
continue;
else //非注释行、非空行,跳出循环
break;
}
//循环结束,str中应该已经是kmeans数据标识"kmeans",判断文件格式
if(strstr(str,"kmeans")==NULL) //判断是否是kmeans数据文件
{
printf("错误:打开的文件格式错误!\n");
fclose(pFile); //关闭文件
return false;
}
while(fgets(str,1000,pFile)!=NULL) //跳过空行和注释行
{
//删除字符串左边空格
strLTrim(str);
if (str[0]=='\n') //空行,继续读取下一行
continue;
strncpy(strTemp,str,2);
if(strstr(strTemp,"//")!=NULL) //跳过注释行
continue;
else //非注释行、非空行,跳出循环
break;
}
//开始读取kmeans数据的项目栏
int j=0;
char* token=strtok(str," "); //分割下一个项目
item[j]=token; //保存分割出来的项目
j++;
while((token = strtok( NULL, " "))!=NULL){ //分割下一个项目
item[j]=token; //保存分割出来的项目
j++;
}
nArrLen=0; //数组行号初始化为0
int i=0;
while(fgets(str,1000,pFile)!=NULL)
{ i=0;
//删除字符串左边空格
strLTrim(str);
if (str[0]=='\n') //空行,继续读取下一行
continue;
strncpy(strTemp,str,2);
if(strstr(strTemp,"//")!=NULL) //注释行,跳过,继续读取下一行
continue;
token=strtok(str," "); //以空格为分隔符,分割出学生的姓名
if(token==NULL) //分割为空串,失败退出
{
printf("错误:读取数据失败!\n");
fclose(pFile); //关闭文件
return false;
}
Name[nArrLen]=token; //保存学生姓名
while((token = strtok( NULL, " "))!=NULL){ //读取下一个子串,即此学生的下一门成绩
strLine[nArrLen][i]=atoi(token); //获取此学生的下一门成绩
i++;
}
nArrLen++; //数组行号加1
}
nCourse=i; //保存学生的科目数
fclose(pFile); //关闭文件
return true;
}
/* 算法描述:
K均值算法:
给定类的个数K,将N个对象分到k个类中去,使得类内对象之间的相似性最大,而类之间的相似性最小。
*/
int main() {
int Flag=true; //迭代标志,若为false,则迭代结束
int Iter=0; //计算迭代次数,控制迭代结束
int i=0;
if(!ReadFileToArray(strLine,nArrLen))//fileName,
exit(0);
InitData(strLine);//初始化数
while(Flag&&Iter<MaxIterN)//开始迭代
{
UpdateCluster();//更新各个聚类
UpdateCenter();//更新质心数组
if(IsEqual(Center,CenterCopy))//如果本次迭代与前次的质心聚合相等,即已收敛,结束退出
{ Flag=0;
}
else //否则将质心副本置为本次迭代得到的的质心集合
{ CopyCenter();//将质心副本置为本次迭代得到的的质心集合
}
Iter++;
}
Print();//输出结果
cout<<"本次实验迭代次数为"<<Iter<<"次"<<endl;
getchar();
return 0;
}