关于Oracle中执行计划稳定性深入研究 (1)
来源:数据库技术网 编辑:若水 时间:2008-05-14
什么是执行计划
所谓执行计划,顾名思义,就是对一个查询任务,做出一份怎样去完成任务的详细方案。举个生活中的例子,我从珠海要去英国,我可以选择先去香港然后转机,也可以先去北京转机,或者去广州也可以。但是到底怎样去英国划算,也就是我的费用最少,这是一件值得考究的事情。同样对于查询而言,我们提交的SQL仅仅是描述出了我们的目的地是英国,但至于怎么去,通常我们的SQL中是没有给出提示信息的,是由数据库来决定的。
我们先简单的看一个执行计划的对比:
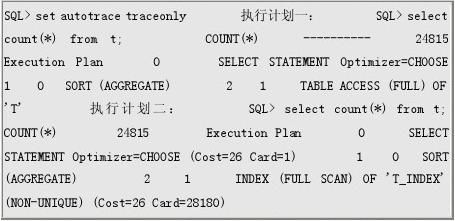

这两个执行计划中,第一个表示求和是通过进行全表扫描来做的,把整个表中数据读入内存来逐条累加;第二个表示根据表中索引,把整个索引读进内存来逐条累加,而不用去读表中的数据。但是这两种方式到底哪种快呢?通常来说可能二比一快,但也不是绝对的。这是一个很简单的例子演示执行计划的差异。对于复杂的SQL(表连接、嵌套子查询等),执行计划可能几十种甚至上百种,但是到底那种最好呢?我们事前并不知道,数据库本身也不知道,但是数据库会根据一定的规则或者统计信息(statistics)去选择一个执行计划,通常来说选择的是比较优的,但也有选择失误的时候,这就是这次讨论的价值所在。
Oracle优化器模式
Oracle优化器有两大类,基于规则的和基于代价的,在SQLPLUS中我们可以查看init文件中定义的缺省的优化器模式。
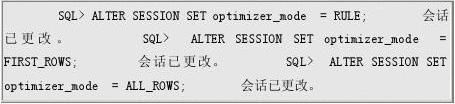
这是Oracle8.1.7 企业版,我们可以看出,默认安装后数据库优化器模式为CHOOSE,我们还可以设置为 RULE、FIRST_ROWS,ALL_ROWS。可以在init文件中对整个instance的所有会话设置,也可以单独对某个会话设置:
基于规则的查询,数据库根据表和索引等定义信息,按照一定的规则来产生执行计划;基于代价的查询,数据库根据搜集的表和索引的数据的统计信息(通过analyze 命令或者使用dbms_stats包来搜集) 1
综合来决定选取一个数据库认为最优的执行计划(实际上不一定最优)。RULE是基于规则的,CHOOSE表示如果查询的表存在搜集的统计信息则基于代价来执行(在CHOOSE模式下Oracle采用的是 FIRST_ROWS),否则基于规则来执行。在基于代价的两种方式中,FIRST_ROWS指执行计划采用最少资源尽快的返回部分结果给客户端,对于排序分页页显示这种查询尤其适用,ALL_ROWS指以总体消耗资源最少的方式返回结果给客户端。
基于规则的模式下,数据库的执行计划通常比较稳定。但在基于代价的模式下,我们才有更大的机会选择最优的执行计划。也由于Oracle的很多查询方面的特性必须在基于代价的模式下才能体现出来,所以我们通常不选择RULE(并且Oracle宣称从 Oracle 10i版本数据库开始将不再支持 RULE)。既然是基于代价的模式,也就是说执行计划的选择是根据表、索引等定义和数据的统计信息来决定的,这个统计信息是根据 analyze 命令或者dbms_stats包来定期搜集的。首先存在着一种可能,就是由于搜集信息是一个很消耗资源和时间的动作,尤其当表数据量很大的时候,因为搜集信息是对整个表数据进行重新的完全统计,所以这是我们必须慎重考虑的问题。我们只能在服务器空闲的时候定期的进行信息搜集。这说明我们在一段时期内,统计信息可能和数据库本身的数据并不吻合;另外就是Oracle的统计数据本身也存在着不精确部分(详细参考Oracle DOCUMENT),更重要的一个问题就是及时统计数据相对已经比较准确,但是Oracle的优化器的选择也并不是始终是最优的方案。这也倚赖于Oracle对不同执行计划的代价的计算规则(我们通常是无法知道具体的计算规则的)。这好比我们决定从香港还是从北京去英国,车票、机票等实际价格到底是怎么核算出来的我们并不知道,或者说我们现在了解的价格信息,在我们乘车前往的时候,真实价格跟我们的预算已经发生了变化。所有的因素,都将影响我们的整个开销。
执行计划稳定性能带给我们什么
Oracle存在着执行计划选择失误的可能。这也是我们经常遇见的一些现象,比如总有人说我的程序在测试数据库中跑的很好,但在产品数据库上就是跑的很差,甚至后者硬件条件比前者还好,这到底是为什么?硬件资源、统计信息、参数设置都可能对执行计划产生影响。由于因素太多,我们总是对未来怀着一种莫名的恐惧,我的产品数据库上线后到底跑的好不好?于是Oracle提供了一种稳定执行计划的能力,也就是把在测试环境中的运行良好的执行计划所产生的OUTLINES移植到产品数据库,使得执行计划不会随着其他因素的变化而变化。
那么OUTLINES是什么呢?先要介绍一个内容,Oracle提供了在SQL中使用HINTS来引导优化器产生我们想要的执行计划的能力。这在多表连接、复杂查询中特别有效。HINTS的类型很多,可以设置优化器目标(RULE、CHOOSE、FIRST_ROWS、ALL_ROWS),可以指定表连接的顺序,可以指定使用哪个表的哪个索引等等,可以对SQL进行很多精细的控制。通过这种方式产生我们想要的执行计划的这些HINTS,Oracle可以存储这些HINTS,我们称之为OUTLINES。通过STORE OUTLINES可以使得我们拥有以后产生相同执行计划的能力,也就是使我们拥有了稳定执行计划的能力。
这里想给出一个附加的说明就是,实际上,我们通过工具改写SQL,比如使用SQL EXPERT改写后的SQL,这些不仅仅是加了HINTS而且文本都已经发生了变化的SQL,也可以存储OUTLINES,并可被应用到应用中。但这不是一定生效,我们必须测试检查是否生效。但由于就算给了错误的OUTLINES,数据库在执行的时候,也只是忽略过去重新生成执行计划而不会返回错误,所以我们才敢放心的这么使用。当然在Oracle文档中并没有指明可以这样做,文档中只是说明,如果存在OUTLINES的同时又在SQL中加了HINTS,则会使用OUTLINES而忽略HINTS。这个功能在LECCO将发布的产品中会使用这一功能,这样可以将SQL EXPERT的改写SQL的能力和稳定执行计划的能力结合起来,那么我们就对不能更改源代码的应用具有了相当强大的SQL优化能力。
也许我们会有疑问,假如稳定了执行计划,那还搜集统计信息干吗?这是因为几个原因造成的,首先,现在的执行计划对于未来发生了变化的数据未必就是合适的,存在着当前的执行计划不满足未来数据的变化后的效率,而新的统计信息的情况下所产生的执行计划也并不是全部都合理的。那这个时候,我们可以采用新搜集的统计信息,但是却对新统计信息下不良的执行计划采用Oracle提供的执行计划稳定性这个能力固定执行计划,这样结合起来我们可以建立满意的高效的数据库运行环境。
2
我们还需要关注的一个东西,Oracle提供的dbms_stats包除了具有搜集统计信息的能力,还具有把数据库中统计信息(statistics)export/import的能力,还具有只搜集统计信息而使得统计信息不应用于数据库的能力(把统计信息搜集到一个特定的表中而不是立即生效),在这个基础上我们就可以把统计信息export出来再import到一个测试环境中,再运行我们的应用,在测试环境中我们观察最新的统计信息会导致哪些执行计划发生变化(DB EXPERT的Plan Version Tracer是模拟不同环境并自动检查不同环境中执行计划变化的工具),是变好了还是变差了。我们可以把变差的这一部分在测试环境中使用hints或者利用工具(SQL EXPERT是在重写SQL这一领域目前最强有力的工具)产生良好的执行计划的SQL,利用这些SQL可以产生OUTLINES,然后在产品数据库应用最新的统计信息的同时移植进这些OUTLINES。
最后说一下我们不得不使用执行计划稳定性能力的场合。我们假定Oracle的优化器的选择都是准确的,但是优化器选择的基础就是我们的SQL,这些SQL才从根本上决定了运行效率,这是更重要的一个优化的环节。SQL是基础(当然数据库的设计是基础的基础),一个SQL写的好不好,就相当于我们同样是要想去英国,但是我的起点在珠海,你的起点却在西藏的最边缘偏僻的一个地方,那不管你做怎样的最优路线选择,你都不如我在
利用Oracle执行计划机制提高查询性能
消耗在准备利用Oracle执行计划机制提高查询性能新的SQL语句的时间是Oracle SQL语句执行时间的最重要的组成部分。但是通过理解Oracle内部产生执行计划的机制,你能够控制Oracle花费在评估连接顺序的时间数量,并且能在大体上提高查询性能。
准备执行SQL语句
当SQL语句进入Oracle的库缓存后,在该语句准备执行之前,将执行下列步骤:
1) 语法检查:检查SQL语句拼写是否正确和词序。
2) 语义分析:核实所有的与数据字典不一致的表和列的名字。
3) 轮廓存储检查:检查数据字典,以确定该SQL语句的轮廓是否已经存在。
3
4) 生成执行计划:使用基于成本的优化规则和数据字典中的统计表来决定最佳执行计划。
5) 建立二进制代码:基于执行计划,Oracle生成二进制执行代码。
一旦为执行准备好了SQL语句,以后的执行将很快发生,因为Oracle认可同一个SQL语句,并且重用那些语句的执行。然而,对于生成特殊的SQL语句,或嵌入了文字变量的SQL语句的系统,SQL执行计划的生成时间就很重要了,并且前一个执行计划通常不能够被重用。对那些连接了很多表的查询,Oracle需要花费大量的时间来检测连接这些表的适当顺序。
评估表的连接顺序
在SQL语句的准备过程中,花费最多的步骤是生成执行计划,特别是处理有多个表连接的查询。当Oracle评估表的连接顺序时,它必须考虑到表之间所有可能的连接。例如:六个表的之间连接有720(6的阶乘,或6 * 5 * 4 * 3 * 2 * 1 = 720)种可能的连接线路。当一个查询中含有超过10个表的连接时,排列的问题将变得更为显著。对于15个表之间的连接,需要评估的可能查询排列将超过1万亿(准确的数字是1,307,674,368,000)种。
使用optimizer_search_limit参数来设定限制
通过使用optimizer_search_limit参数,你能够指定被优化器用来评估的最大的连接组合数量。使用这个参数,我们将能够防止优化器消耗不定数量的时间来评估所有可能的连接组合。如果在查询中表的数目小于optimizer_search_limit的值,优化器将检查所有可能的连接组合。
例如:有五个表连接的查询将有120(5! = 5 * 4 * 3 * 2 * 1 = 120)种可能的连接组合,因此如果optimizer_search_limit等于5(默认值),则优化器将评估所有的120种可能。optimizer_search_limit参数也控制着调用带星号的连接提示的阀值。当查询中的表的数目比optimizer_search_limit小时,带星号的提示将被优先考虑。
另一个工具:参数optimizer_max_permutations
初始化参数optimizer_max_permutations定义了优化器所考虑组合数目的上限,且依赖于初始参数optimizer_search_limit。optimizer_max_permutations的默认值是80,000。
参数optimizer_search_limit和optimizer_max_permutations一起来确定优化器所考虑的组合数目的上限:除非(表或组合数目)超过参数optimizer_search_limit 或者 optimizer_max_permutations设定的值,否则优化器将生成所有可能的连接组合。一旦优化器停止评估表的连接组合,它将选择成本最低的组合。
使用ordered提示指定连接顺序
你能够设定优化器所执行的评估数目的上限。但是即使采用有很高价值的排列评估,我们仍然拥有使优化器可以尽早地放弃复杂的查询的重要机会。回想一下含有15个连接查询的例子,它将有超过1万亿种的连接组合。如果优化器在评估了80,000个组合后停止,那么它才仅仅评估了0.000006%的可能组合,而且或许还没有为这个巨大的查询找到最佳的连接顺序。
在Oracle SQL中解决此问题的最好的方法是手工指定表的连接顺序。为了尽快创建最小的解决方案集,这里所遵循的规则是将表结合起来,通常优先使用限制最严格的WHERE子句来连接表。
4
5

作为一个Oracle专业人员,你应该知道在SQL语句第一次进入库缓存时可能存在重大的启动延迟。但是聪明的Oracle DBA和开发人员能够改变表的搜索限制参数或者使用ordered提示来手工指定表的连接顺序,从而显著地减少优化和执行新查询所需的时间。
RBO/CBO是如何工作的
RBO只借助少量的信息来决定一个sql语句的执行计划。
1)sql语句本身
2)sql中涉及到的table、view、index等的基本信息
3)本地数据库中数据字典中的信息(远程数据库数据字典信息对RBO是无效的)
在oracle7以前,主要是使用RBO。Oracle在基于rule的优化器中采用启发式的方法或规则来生成执行计划。eg:如果一个查询的where条件包含一个谓词(predicate),也就是一个判断条件如“=”,“<”,“>”等。而且该谓词上引用的列上有有效索引,那么优化器就使用该索引访问这个表而不考虑其他的因素。表的大小,数据多少,表中数据的易变性和索引的选择性等等。 就像这条sql:select * from emp where deptno=10; 对于这个查询来说,如果是使用RBO,而且deptno字段上有有效的索引,则它会通过deptno的索引访问emp表。当然在大多数情况下这是我们所期望的,这是高效的。但在一些特殊的情况下使用索引会比不使用索引性能低下。例如:
1) emp表比较小时。该表的数据只放在几个数据块中,此时使用FTS(FULL TABLE SCAN)比使用index性能高,这是因为表比较小,数据有可能全在内存中,做FTS此时最快。而使用index则先从索引中找到符合条件记录的rowid,然后再根据这些rowid从emp中读数据,不但增加了磁盘i/o,效率也会比FTS低很多。2)emp表比较大时。当符合deptno=10的条件有表数据的50%,如果共有4000W行数据,共放在50W个数据块中,每个数据块8K,则这张表共有4G大小,不可能全放在内存中,绝大部分需要放在硬盘上,此时如果该查询通过index,那么噩梦就开始了,首先假设你的: 6
db_file_multiblock_read_count=200,既一次能从硬盘中读取200个数据块。使用FTS则
50W/200=2500次i/o。但如果你使用了index,假设deptno列上的索引都已经cache到内存中,这可以把访问index的开销忽略不计(有时事实并非如此哦)。因为要读4000W*50%=2000W数据,假设读这2000W数据的命中率为99.9%,则还要2000W*0.001=20000次i/o(这只是理想情况,实际中命中率等各种因素可能比这还要糟糕),因此可以看出使用index比使用FTS代价更高。
CBO:
CBO通过代价引擎来估计每个执行计划所需的代价,该代价将每个执行计划所耗费的资源进行量化,CBO根据这个代价选择出最优的执行计划。一个查询所耗费的资源可分为三部分:I/O代价、CPU代价、NETWORK代价。I/O是指把数据从磁盘读入内存时所需代价(该代价是查询所需最主要的,所以在优化时一个基本原则就是降低I/O总次数);CPU代价是指处理内存中数据所需的代价,数据一旦读入内存,当我们识别出我们所要的数据后,会在这些数据上执行排序(sort)或连接(join)操作,这需要消耗CPU资源;对于访问远程节点来说,network代价的花费也是很大的。
在使用CBO时,需要表和索引的统计数据(分析数据)作为基础数据,有了这些数据,CBO才能为各个执行计划算出相对准确的代价。所以需要定期对表和索引进行分析(一星期一次)。dbms_stat包.analyze
通过分析SQL语句的执行计划优化SQL(12)
要为一个语句生成执行计划,可以有3种方法:
1.最简单的办法
Sql> set autotrace on
Sql> select * from dual;
执行完语句后,会显示explain plan 与 统计信息。
这个语句的优点就是它的缺点,这样在用该方法查看执行时间较长的sql语句时,需要等待该语句执行成功后,才返回执行计划,使优化的周期大大增长。
如果不想执行语句而只是想得到执行计划可以采用:
Sql> set autotrace traceonly
这样,就只会列出执行计划,而不会真正的执行语句,大大减少了优化时间。虽然也列出了统计信息,但是因为没有执行语句,所以该统计信息没有用处,
如果执行该语句时遇到错误,解决方法为:
(1)在要分析的用户下:
Sqlplus > @ ?
dbmsadminutlxplan.sql
(2) 用sys用户登陆
Sqlplus > @ ?sqlplusadminplustrce.sql
Sqlplus > grant plustrace to user_name;
- - user_name是上面所说的分析用户
2.用explain plan命令
(1) sqlplus > @ ?
dbmsadminutlxplan.sql
7
(2) sqlplus > explain plan set statement_id =’???’
for select ??????
注意,用此方法时,并不执行sql语句,所以只会列出执行计划,不会列出统计信息,并且执行计划只存在plan_table中。所以该语句比起set autotrace traceonly可用性要差。需要用下面的命令格式化输出,所以这种方式我用的不多:
set linesize 150
set pagesize 500
col PLANLINE for a120
SELECT EXECORD EXEC_ORDER, PLANLINE
FROM (SELECT PLANLINE, ROWNUM EXECORD, ID, RID
FROM (SELECT PLANLINE, ID, RID, LEV
FROM (SELECT lpad(' ',2*(LEVEL),rpad(' ',80,' '))
||OPERATION||' '|| -- Operation
DECODE(OPTIONS,NULL,'','('||OPTIONS || ') ')
|| -- Options
DECODE(OBJECT_OWNER,null,'','OF '''|| OBJECT_OWNER
||'.')|| -- Owner
DECODE(OBJECT_NAME,null,'',OBJECT_NAME|| ''' ')
|| -- Object Name
DECODE(OBJECT_TYPE,null,'','('||OBJECT_TYPE|| ') ')
|| -- Object Type
DECODE(ID,0,'OPT_MODE:')|| -- Optimizer
DECODE(OPTIMIZER,null,'','ANALYZED','', OPTIMIZER)||
DECODE(NVL(COST,0)+NVL(CARDINALITY,0)+NVL(BYTES,0),
0,null,' (COST='||TO_CHAR(COST)||',CARD='||
TO_CHAR(CARDINALITY)||',BYTES='||TO_CHAR(BYTES)||')')
PLANLINE, ID, LEVEL LEV,
(SELECT MAX(ID)
FROM PLAN_TABLE PL2
CONNECT BY PRIOR ID = PARENT_ID
AND PRIOR STATEMENT_ID = STATEMENT_ID
START WITH ID = PL1.ID
AND STATEMENT_ID = PL1.STATEMENT_ID) RID
FROM PLAN_TABLE PL1
CONNECT BY PRIOR ID = PARENT_ID
AND PRIOR STATEMENT_ID = STATEMENT_ID
START WITH ID = 0
AND STATEMENT_ID = 'aaa')
ORDER BY RID, -LEV))
ORDER BY ID;
上面这2种方法只能为在本会话中正在运行的语句产生执行计划,即我们需要已经知道了哪条语句运行的效率很差,我们是有目的只对这条SQL语句去优化。其实,在很多情况下,我们只会听一个客户抱怨说现在系统运行很慢,而我们不知道是哪个SQL引起的。此时有许多现成的语句可以找出耗费资源比较多的语句,如:
8
SELECT ADDRESS,
substr(SQL_TEXT,1,20) Text,
buffer_gets,
executions,
buffer_gets/executions AVG
FROM v$sqlarea
WHERE executions>0
AND buffer_gets > 100000
ORDER BY 5;
从而对找出的语句进行进一步优化。当然我们还可以为一个正在运行的会话中运行的所有SQL语句生成执行计划,这需要对该会话进行跟踪,产生trace文件,然后对该文件用tkprof程序格式化一下,这种得到执行计划的方式很有用,因为它包含其它额外信息,如SQL语句执行的每个阶段(如Parse、Execute、Fetch)分别耗费的各个资源情况(如CPU、DISK、elapsed等)。
3.用dbms_system存储过程生成执行计划
因为使用dbms_system存储过程可以跟踪另一个会话发出的sql语句,并记录所使用的执行计划,而且还提供其它对性能调整有用的信息。因其使用方式与上面2种方式有些不太一样,所以在附录中单独介绍。这种方法是对SQL进行调整比较有用的方式之一,有些情况下非它不可。
详介oracle的RBO/CBO优化器
【IT168 技术文档】Oracle的优化器有两种优化方式,即基于规则的优化方式(Rule-Based Optimization,简称为RBO)和基于代价的优化方式(Cost-Based Optimization,简称为CBO),在Oracle8及以后的版本,Oracle强列推荐用CBO的方式
RBO方式:优化器在分析SQL语句时,所遵循的是Oracle内部预定的一些规则。比如我们常见的,当一个where子句中的一列有索引时去走索引。
CBO方式:它是看语句的代价(Cost),这里的代价主要指Cpu和内存。优化器在判断是否用这种方式时,主要参照的是表及索引的统计信息。统计信息给出表的大小、有少行、每行的长度等信息。这些统计信息起初在库内是没有的,是做analyze后才出现的,很多的时侯过期统计信息会令优化器做出一个错误的执行计划,因些应及时更新这些信息。
注意:走索引不一定就是优的,比如一个表只有两行数据,一次IO就可以完成全表的检索,而此时走索引时则需要两次IO,这时全表扫描(full table scan)是最好
优化模式包括Rule、Choose、First rows、All rows四种方式:
Rule:基于规则的方式。
Choolse:默认的情况下Oracle用的便是这种方式。指的是当一个表或或索引有统计信息,则走CBO的方式,如果表或索引没统计信息,表又不是特别的小,而且相应的列有索引时,那么就走索引,走RBO的方式。
First Rows:它与Choose方式是类似的,所不同的是当一个表有统计信息时,它将是以最快的方式返回查询的最先的几行,从总体上减少了响应时间。
All Rows:也就是我们所说的Cost的方式,当一个表有统计信息时,它将以最快的方式返回表的所有的行,从总体上提高查询的吞吐量。没有统计信息则走RBO的方式。
设定选用哪种优化模式:
9
A、Instance级别我们可以通过在initSID.ora文件中设定
OPTIMIZER_MODE=RULE/CHOOSE/FIRST_ROWS/ALL_ROWS如果没设定OPTIMIZER_MODE参数则默认用的是Choose方式。
B、Sessions级别通过ALTER SESSION SET OPTIMIZER_MODE=RULE/CHOOSE/FIRST_ROWS/ALL_ROWS来设定。
C、语句级别用Hint(/*+ ... */)来设定
为什么表的某个字段明明有索引,但执行计划却不走索引?
1、优化模式是all_rows的方式
2、表作过analyze,有统计信息
怎样看oracle查询语句执行计划
SQLPLUS的AutoTrace是分析SQL的执行计划,执行效率的一个非常简单方便的工具,在绝大多数情况下,也是非常有用的工具。
1。如何设置和使用AUTOTRACE
SQL> connect / as sysdba
SQL> @?/rdbms/admin/utlxplan.sql
Table created.
SQL> create public synonym plan_table for plan_table;
Synonym created.
SQL> grant select,update,insert,delete on plan_table to public;
Grant succeeded.
SQL> @?/sqlplus/admin/plustrce.sql
SQL>grant plustrace to public.
10
2. 理解和使用AutoTrace
对于SQL 调整,使用Autotrace是最简单的方法了,我们只需要做:
SQL>SET AUTOTRACE ON
我们就可以看到我们SQL的执行计划,执行成本(PHYSICAL READ/CONSISTENT READ...)
加上SET Timing On或者Set Time On,我们可以得到很多我们需要的数据。
然后在toad里面对某一条sql语句按下Ctrl+e就可以看到这条语句的执行计划了
CBO,RBO在ORACLE中的应用
上一篇 / 下一篇 2008-03-13 09:30:18 / 个人分类:学习
查看( 156 ) / 评论( 0 ) / 评分( 0 / 0 )
ORACLE 提供了CBO、RBO两种SQL优化器。CBO在ORACLE7 引入,但在ORACLE8i 中才成熟。ORACLE 已经明确声明在ORACLE9i之后的版本中(ORACLE 10G ),RBO将不再支持。因此选择CBO 是必然的趋势。
CBO和 RBO作为不同的SQL优化器,对SQL语句的执行计划产生重大影响,如果要对现有的应用程序从RBO向CBO移植,则必须充分考虑这些影响,避免SQL 语句性能急剧下降;但是,对新的应用系统,则可以考虑直接使用CBO,在CBO模式下进行SQL语句编写、分析执行计划、性能测试等工作,这需要开发者对 CBO的特性比较熟悉。
以下小结几点在CBO下写SQL语句的注意事项:
1、 RBO自ORACLE 6版以来被采用,有着一套严格的使用规则,只要你按照它去写SQL语句,无论数据表中的内容怎样,也不会影响到你的“执行计划”,也就是说对数据不“敏感”;CBO计算各种可能“执行计划”的“代价”,即cost,从中选用cost最低的方案,作为实际运行方案。各“执行计划”的cost的计算根据,依赖于数据表中数据的统计分布,ORACLE数据库本身对该统计分布并不清楚,必须要分析表和相关的索引(使用ANALYZE 命令),才能搜集到CBO所需的数据。
2、使用CBO 时,编写SQL语句时,不必考虑"FROM" 子句后面的表或视图的顺序和"WHERE" 子句后面的条件顺序;ORACLE自7版以来采用的许多新技术都是基于CBO的,如星型连接排列查询,哈希连接查询,函数索引,和并行查询等。
11
3、一般而言,CBO所选择的“执行计划”都不会比RBO的“执行计划”差,而且相对而言,CBO对程序员的要求没有RBO那么苛刻,节省了程序员为了从多个可能的“执行计划”中选择一个最优的方案而花费的调试时间,但在某些场合下也会存在问题。
较典型的问题有:有时,表明明建有索引,但查询过程显然没有用到相关的索引,导致查询过程耗时漫长,占用资源巨大,这时就需要仔细分析执行计划,找出原因。例如,可以看连接顺序是否允许使用相关索引。假设表emp的deptno列上有索引,表dept的列deptno上无索引,WHERE语句有
emp.deptno=dept.deptno条件。在做NL连接时,emp做为外表,先被访问,由于连接机制原因,外表的数据访问方式是全表扫描, emp.deptno上的索引显然是用不上,最多在其上做索引全扫描或索引快速全扫描。
4、如果一个语句使用 RBO的执行计划确实比CBO 好,则可以通过加 " rule" 提示,强制使用RBO。
5、使用CBO 时,SQL语句 "FROM" 子句后面的表,必须全部使用ANALYZE 命令分析过,如果"FROM" 子句后面的是视图,则此视图的基础表,也必须全部使用ANALYZE 命令分析过;否则,ORACLE 会在执行此SQL语句之前,自动进行ANALYZE 命令分析,这会极大导致SQL语句执行极其缓慢。
6、使用CBO 时,SQL语句 "FROM" 子句后面的表的个数不宜太多,因为CBO在选择表连接顺序时,会对"FROM" 子句后面的表进行阶乘运算,选择最好的一个连接顺序。假如"FROM" 子句后有6个表,则其可选择的连接顺序就是6*5*4*3*2*1 = 720 种,CBO 选择其中一种,而如果"FROM" 子句后有12个表,则其可选择的连接顺序就是2*11*10*9*8*7*6*5*4*3*2*1= 479001600 种,可以想象从中选择一种,会消耗多少CPU 时间?如果实在是要访问很多表,则最好使用 ORDER 提示,强制使用"FROM" 子句表固定的访问顺序。
7、使用CBO 时,SQL语句中不能引用系统数据字典表或视图,因为系统数据字典表都未被分析过,可能导致极差的“执行计划”。但是不要擅自对数据字典表做分析,否则可能导致死锁,或系统性能严重下降。
8、使用CBO 时,要注意看采用了哪种类型的表连接方式。ORACLE的共有Sort Merge Join(SMJ)、Hash Join(HJ)和Nested Loop Join(NL)。CBO有时会偏重于SMJ 和 HJ,但在OLTP 系统中,NL 一般会更好,因为它高效的使用了索引。
在两张表连接,且内表的目标列上建有索引时,只有Nested Loop才能有效地利用到该索引。SMJ即使相关列上建有索引,最多只能因索引的存在,避免数据排序过程。HJ由于须做HASH运算,索引的存在对数据查询速度几乎没有影响。
9、使用CBO 时,必须保证为表和相关的索引搜集足够的统计数据。对数据经常有增、删、改的表最好定期对表和索引进行分析,可用SQL语句“analyze table xxx compute statistics for all indexes;"ORACLE掌握了充分反映实际的统计数据,才有可能做出正确的选择。
10、使用CBO 时,要注意被索引的字段的值的数据分布,会影响SQL语句的执行计划。例如:表emp,共有一百万行数据,但其中的emp.deptno列,数据只有4种不同的值,如10、20、30、40。虽然emp数据行有很多,ORACLE缺省认定表中列的值是在所有数据行均匀分布的,也就是说每种deptno值各有25万数据行与之对应。假设SQL搜索条件DEPTNO=10,利用eptno列上的索引进行数据搜索效率,往往不比全表扫描的高,ORACLE理所当然对索引“视而不见”,认为该索引的选择性不高。
我们考虑另一种情况,如果一百万数据行实际不是在4种deptno值间平均分配,其中有99万行对应 12
着值10,5000行对应值20,3000行对应值30,2000行对应值40。在这种数据分布图案中对除值为10外的其它deptno 值搜索时,毫无疑问,如果索引能被应用,那么效率会高出很多。我们可以采用对该索引列进行单独分析,或用analyze语句对该列建立直方图,对该列搜集足够的统计数据,使ORACLE在搜索选择性较高的值能用上索引。
——————————————————————————————
show parameter optimizer_mode --看ORACLE处于何种模式,Oracle V7以来缺省的设置应是"choose",即如果对已分析的表查询的话选择CBO,是否选择RBO.如果该参数设置为"rule",则不论表是否分析过,一概选用RBO,除非在语句中用hint强制.
analyze table xxx compute statistics for all indexes --对表进行分析。
Oracle的RBO和CBO
Oracle的优化器有两种优化方式,即基于规则的优化方式(Rule-Based Optimization,简称为RBO)和基于代价的优化方式(Cost-Based Optimization,简称为CBO),在Oracle8及以后的版本,Oracle强列推荐用CBO的方式
RBO方式:优化器在分析SQL语句时,所遵循的是Oracle内部预定的一些规则。比如我们常见的,当一个where子句中的一列有索引时去走索引。
CBO方式:它是看语句的代价(Cost),这里的代价主要指Cpu和内存。优化器在判断是否用这种方式时,主要参照的是表及索引的统计信息。统计信息给出表的大小、有少行、每行的长度等信息。这些统计信息起初在库内是没有的,是做analyze后才出现的,很多的时侯过期统计信息会令优化器做出一个错误的执行计划,因些应及时更新这些信息。
注意:走索引不一定就是优的,比如一个表只有两行数据,一次IO就可以完成全表的检索,而此时走索引时则需要两次IO,这时全表扫描(full table scan)是最好
优化模式包括Rule、Choose、First rows、All rows四种方式:
Rule:基于规则的方式。
Choolse:默认的情况下Oracle用的便是这种方式。指的是当一个表或或索引有统计信息,则走CBO的方式,如果表或索引没统计信息,表又不是特别的小,而且相应的列有索引时,那么就走索引,走RBO的方式。
First Rows:它与Choose方式是类似的,所不同的是当一个表有统计信息时,它将是以最快的方式返回查询的最先的几行,从总体上减少了响应时间。
All Rows:也就是我们所说的Cost的方式,当一个表有统计信息时,它将以最快的方式返回表的所有的行,从总体上提高查询的吞吐量。没有统计信息则走RBO的方式。
设定选用哪种优化模式:
13
A、Instance级别我们可以通过在initSID.ora文件中设定OPTIMIZER_MODE=RULE/CHOOSE/FIRST_ROWS/ALL_ROWS如果没设定OPTIMIZER_MODE参数则默认用的是Choose方式。
B、Sessions级别通过ALTER SESSION SET OPTIMIZER_MODE=RULE/CHOOSE/FIRST_ROWS/ALL_ROWS来设定。
C、语句级别用Hint(/*+ ... */)来设定
为什么表的某个字段明明有索引,但执行计划却不走索引?
1、优化模式是all_rows的方式
2、表作过analyze,有统计信息(最可能的就是统计信息有误)
3、表很小,上文提到过的,Oracle的优化器认为不值得走索引。
我们可以查看一下一个表或索引是否是统计信息
SELECT * FROM user_tables
WHERE table_name=<table_name>
AND num_rows is not null;
SELECT * FROM user_indexes
WHERE table_name=<table_name>
AND num_rows is not null;
当我们使用CBO的方式,就应当及时去更新表和索引的统计信息,以免生形不切合实的执行计划。 ANALYZE table table_name COMPUTE STATISTICS;
ANALYZE INDEX index_name ESTIMATE STATISTICS
14