数据结构实验报告
学院:数理与信息工程学院
姓名:
班级:
学号:
一、线性表
实验一:顺序表的删除
(一)实验目的:
1.掌握使用C++上机调试线性表的基本方法;
2.掌握线性表的基本操作:插入、删除、查找等运算在顺序存储结构上的实现。
(二)实验内容:
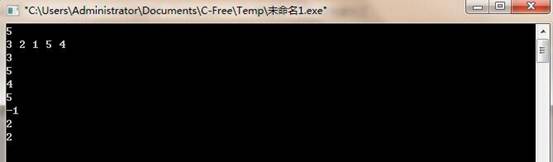
实现一个线性表,对一个n不超过1000的线性表进行删除操作。
(三)实验程序:
#include<stdio.h>
#include<stdlib.h>
typedef struct LNode{
int data;
struct LNode *next;
}LNode,*LinkList;
int main()
{ int n,m;
while(scanf("%d",&n)!=EOF)
{
LinkList L=(LinkList)malloc(sizeof(LNode));
L->next=NULL;
LinkList p=L,q;
for(int i=1;i<=n;i++)
{
q=(LinkList)malloc(sizeof(LNode));
scanf("%d",&q->data);
q->next=NULL;
p->next=q;
p=q;
}
scanf("%d",&m);
for(int j=1;j<=m;j++)
{
int num;
scanf("%d",&num);
p=L;int k;int e=-1;
if(num>=1 && num<=n){
for(k=1;k<num;k++){
p=p->next;
}
q=p->next;
p->next=q->next;
e=q->data;
n--;
free(q);
}
printf("%d\n",e);
}
}
}
(四)运行结果:
(五)实验总结:
初次接触数据结构,心理有些期待,也有些畏惧。因为没学
习过这种程序,心里总担心着能不能把它学好呢?当我们把
该章节学完就尝试着做这个实验,说实话突然从理论到实验还是
消化不了呢,后来,通过慢慢的揣摩和问老师和同学,慢慢的做
完了。
实验二:链表及其多项式相加
(一)实验目的:
1.掌握使用C++上机调试线性表的基本方法;
2.掌握线性表的基本操作:插入、删除、查找等运算在链式存储结构上的实现。
3.掌握基于链表的多项式相加的算法。
(二)实验内容:
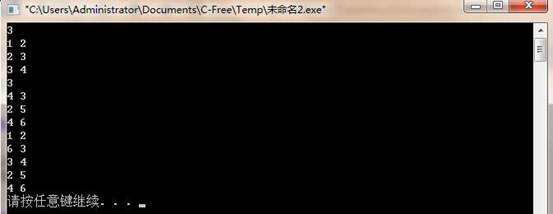
通过有序对输入多项式的各个项,利用单链表存储该一元多项式,并建立的2个存储一元多项式的单链表,然后完成2个一元多项式的相加,并输出相加后的多项式。
(三)实验程序:
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
#include<conio.h>
typedef struct Lnode{
int cof;
int expn;
struct Lnode *next;
}Lnode,*LinkList;
void Creatpolyn(LinkList &La,int m){
int i;
LinkList p,q;
La=(LinkList)malloc(sizeof(Lnode));
La->next=NULL;
p=La;
for(i=1;i<=m;i++){
q=(LinkList)malloc(sizeof(Lnode));
q->next=NULL;
scanf("%d %d",&q->cof,&q->expn);
p->next=q;
p=q;}
}
LinkList addpolyn(LinkList &A,LinkList &B)
{
LinkList pa,pb,pc,Lb,p1,p2;
pc=Lb=A;
pa=A->next;
pb=B->next;
while(pa && pb){
if(pa->expn==pb->expn){
pa->cof=pa->cof+pb->cof;
if(pa->cof!=0){
pc->next=pa;
pc=pa;
p2=pb;
pa=pa->next;
pb=pb->next;
free(p2);
}
else{
p1=pa;
p2=pb;
pa=pa->next;
pb=pb->next;
free(p1);
free(p2);
}
}
else if(pa->expn>pb->expn){
pc->next=pb;
pc=pb;
pb=pb->next;
}
else if(pb->expn>pa->expn){
pc->next=pa;
pc=pa;
pa=pa->next;
}
}
pc->next=pa?pa:pb;
free(B);
return(Lb);
}
void printfpolyn(LinkList &p)
{
while(p->next!=NULL)
{
p=p->next;
printf("%d %d\n",p->cof,p->expn);
}
}
int main()
{
int n1,n2;
LinkList A,B,C;
scanf("%d",&n1);
Creatpolyn(A,n1);
scanf("%d",&n2);
Creatpolyn(B,n2);
C=addpolyn(A,B);
printfpol
(四)运行结果:
(五)实验总结:
在学习C语言的时候,我就对指针类型概念很模糊,更加不用说怎样运用他了。这个线性表的链式存储也是这样的。掌握了指针应该怎么指向,做实验并不是想像中的这么难,只要你自己理清楚了自己的思绪,一步一步的来,不要太急于成功了,那么,到了最后,你就会发现真的很容易。
二、栈
实验三:括号匹配判断算法
(一)实验目的:
1.掌握使用C++上机调试栈的基本方法;
2. 深入了解栈的特性,掌握栈的各种基本操作。
(二)实验内容:
假设在表达式中([]())或[([ ][ ])]等为正确的格式,[( ])或([( ))或 (( )])均为不正确的格式。基于栈设计一个判断括号是否正确匹配的算法。
(三)实验程序:
#include<stdio.h>
#include<stdlib.h>
typedef struct snode{
char data;
struct snode *next;
}snode,*Linkstack;
void Linkstackpush(Linkstack *ls,char e){
Linkstack p=(Linkstack)malloc(sizeof(snode));
p->data=e;
p->next=*ls;
*ls=p;
}
int Linkstackpop(Linkstack *ls){
Linkstack p;
p=*ls;
if(*ls==NULL)
return 0;
(*ls)=(*ls)->next;
free(p);
return 1;
}
int Linkstackgettop(Linkstack ls,char *e){
if(ls==NULL)
return 0;
*e=(ls)->data;
return 1;
}
void initLinkstack(Linkstack *ls){
*ls=NULL;
}
void matching(char str[]){
char e;
int k,flag=1;
Linkstack s;
initLinkstack(&s);
for(k=0;str[k]!='\0' && flag;k++){
if(str[k]!='('&&str[k]!=')'&&str[k]!='['&&str[k]!=']'&&str[k]!='{'&&str[k]!='}')
continue;
switch(str[k]){
case'(':
case'[':
case'{':Linkstackpush(&s,str[k]);break;
case')':if(s){
Linkstackgettop(s,&e);
if(e=='(') Linkstackpop(&s);
else flag=0;
}
else flag=0; break;
case']':if(s){
Linkstackgettop(s,&e);
if(e=='[')Linkstackpop(&s);
else flag=0;
}
else flag=0; break;
case'}':if(s){
Linkstackgettop(s,&e);
if(e=='}')Linkstackpop(&s);
else flag=0;
}
else flag=0; break;
}
}
if(flag==1 && s==NULL){
printf("yes\n");
}
else printf("no\n");
}
int main(){
char str[8000];
while(gets(str)){
matching(str);
}
return 0;
}
(四)运行结果:
实验五:四则运算表达式求值
(一)实验目的:
1.掌握顺序栈的实现;
2.掌握顺序栈的应用;
3.利用栈实现算法优先算法。
(二)实验内容:
按中缀形式输入一个四则运算的表达式,利用算法优选算法把其转换为后缀表达式输出,并求表达式的值。
(三)实验程序:
#include<stdio.h>
#include<stdlib.h>
#define STACK_INIT_SIZE 10000
#define STACKINCREMENT 10
#define TURE 1
#define FALSE 0
#define INFEASIBLE -1
#define OVERFLOW -2
#define OK 1
#define ERROR 0
typedef int Selemtype;
typedef int Status;
typedef struct{
Selemtype *base;
Selemtype *top;
int stacksize;
}Sqstack;
Status initstack(Sqstack &s) {
s.base=(Selemtype*)malloc(STACK_INIT_SIZE*sizeof(Selemtype));
if(!s.base) exit(OVERFLOW);
s.top=s.base;
s.stacksize=STACK_INIT_SIZE;
return 0;
}
Status travelstack(Sqstack s){
Selemtype *p;
p=s.base;
printf("%c",*p++);
while(p!=s.top) {
printf(" %c",*p++);
}
return 0;
}
Status Gettop(Sqstack s){
if(s.base==s.top) return ERROR;
return *(s.top-1);
}
Status push(Sqstack &s,Selemtype e){
if(s.top-s.base>=s.stacksize)
{
s.base=(Selemtype*)realloc(s.base,(s.stacksize+STACKINCREMENT)*sizeof(Selemtype));
if(!s.base) exit(OVERFLOW);
s.top=s.base+s.stacksize;
s.stacksize+=STACKINCREMENT;
}
*s.top=e;
s.top++;
return OK;
}
Status pop(Sqstack &s,Selemtype &e){
if(s.base==s.top) return ERROR;
s.top--;
e=*s.top;
return OK;
}
Status bijiao(Selemtype a,Selemtype b){
switch(a)
{
case '+':
switch(b)
{
case '+':
case ')':
case '#':
case '-':return '>';
case '*':
case '/':
case '(':return '<';
}
case '-':
switch(b)
{
case '+':
case ')':
case '#':
case '-':return '>';
case '*':
case '/':
case '(':return '<';
}
case '*':
switch(b)
{
case '(':return '<';
case '+':
case ')':
case '#':
case '-':
case '*':
case '/':return '>';
}
case '/':
switch(b)
{
case '(':return '<';
case '+':
case '#':
case ')':
case '*':
case '-':
case '/':return '>';
}
case '(':
switch(b)
{
case ')':return '=';
case '(':
case '+':
case '-':
case '*':
case '/':return '<';
}
case ')':
switch(b)
{
case ')':
case '+':
case '#':
case '-':
case '*':
case '/':return '>';
}
case '#':
switch(b)
{
case '#':return '=';
case '(':
case '+':
case '-':
case '*':
case '/':return '<';
}
}
}
Status operate(Selemtype a,Selemtype c,Selemtype b) {
switch(c)
{
case '+':return a+b;
case '-':return a-b;
case '*':return (a)*(b);
case '/':return (a)/(b);
}
}
Status qiuzhi() {
Selemtype c,a,b,x,theta;
Sqstack optr,opnd,houzhui;
initstack(optr);
initstack(opnd);
initstack(houzhui);
push(optr,'#');
c=getchar();
while(c!='#'||Gettop(optr)!='#')
{
if(c=='\n') c='#';
if(c>='0'&&c<='9') {push(opnd,c-48);push(houzhui,c);c=getchar();}
else
{
switch(bijiao(Gettop(optr),c))
{
case '<':push(optr,c);c=getchar();break;
case '=':if(c=='#') break;
else{pop(optr,x);c=getchar();break;}
case '>':pop(optr,theta);pop(opnd,b);pop(opnd,a);
push(houzhui,theta);
push(opnd,operate(a,theta,b));
break;
}
}
}
travelstack(houzhui);
printf("\n");
return Gettop(opnd);
}
int main() {
printf("%d\n",qiuzhi());
return 0;
}
(四)运行结果:

(五)实验总结:
在这两个实验中,主要是要分析清楚出现不同情况下要进行的操作,调理清晰了才能编写好程序。我刚开始也不是很分得清。后来在同学的帮助下,对这点有了进一步的了解。而我的耐心所以在出现的指向的问题上总是很烦,这一点需要改正。
三、队列
实验四:循环队列插入与删除操作
(一)实验目的:
1. 深入了解队列的特性,掌握队列的各种基本操作
(二)实验内容:
实现环形队列(MAXN不超过100001),能够进行进队出队操作
(三)实验程序:
#include<stdio.h>
#include<string.h>
#define M 100001
int a[M];
int tou,wei,geshu;
int main(){
int T,k;
int s;
char mingl[100];
while(scanf("%d%*c",&T)!=EOF){
tou=wei=geshu=0;
for(k=1;k<=T;k++){
scanf("%s",mingl);
if(strcmp(mingl,"enqueue")==0){
scanf("%d%*c",&s);
geshu++;
a[tou++]=s;
if(tou==M)tou=0;
}
if(strcmp(mingl,"dequeue")==0){
if(tou==wei && geshu==0) printf("-1");
else{
printf("%d",a[wei++]);
if(wei==M) wei=0;
geshu--;
}
printf("\n");
}
}
}
}
(四)运行结果:

(五)实验总结:
通过这个实验的上机操作,我从实质上了解了队列的实现和存储方式,对于队列有了更深的理解。并且学会了队列的插入和删除操作。
四、树和二叉树
实验八:二叉树建立及其先序遍历
(一)实验目的:
本次实验的目的是熟悉树的各种物理表示方法及各种遍历方式(其中以二叉树为侧重点),解树在计算机科学及其他工程中的应用。
(二)实验内容:
按先序遍历顺序输入二叉树的各个结点值,采用二叉链表的存储结构存储该二叉树,并按先序遍历输出二叉树的各结点的值及深度。
(三)实验程序:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define ERROR 0
#define OK 1
#define OVERFLOW -2
#define MAX 100000000
int k;
char str[MAX];
typedef int status;
typedef struct Binode{
char data;
int deep;
Binode *parent;
Binode *lchild;
Binode *rchild;
}*Bitree;
status prebitree(Bitree T){
if(T){
printf("%c(%d)",T->data,T->deep);
prebitree(T->lchild);
prebitree(T->rchild);
}
return OK;
}
status depthbitree(Bitree &T){
if(T){
if(T->lchild!=NULL)
T->lchild->deep=T->deep+1;
if(T->rchild!=NULL)
T->rchild->deep=T->deep+1;
depthbitree(T->lchild);
depthbitree(T->rchild);
}
return OK;
}
status creatbitree(Bitree &T){
k++;
if(str[k]=='#') T=NULL;
else{
T=(Bitree)malloc(sizeof(Binode));
if(!T) exit(OVERFLOW);
T->data=str[k];
creatbitree(T->lchild);
creatbitree(T->rchild);
}
return OK;
}
int main(){
k=-1;
scanf("%s",str);
Bitree T;
creatbitree(T);
T->parent=NULL;
T->deep=1;
depthbitree(T);
prebitree(T);
printf("\n");
return 0;
}
(四)运行结果:
 实验十:中序线索二叉树
实验十:中序线索二叉树
(一)实验目的:
1.理解线索的含义,掌握线索二叉树的算法;
2.了解中序线索及其遍历的实现过程。
(二)实验内容:
建立中序线索二叉树,并按中序遍历该二叉树。
(三)实验程序:
#include<stdio.h>
#include<stdlib.h>
#define OK 1
#define ERROR 0
#define OVERFLOW -1
typedef int status;
typedef enum PointerTag{Link,Thread};
typedef struct BiThrNode{
char data;
struct BiThrNode *lchild,*rchild;
PointerTag LTag,RTag;
}BiThrNode,*BiThrTree;
BiThrTree pre;
status CreateThrTree(BiThrTree &T){
char ch;
ch=getchar();
if(ch=='#')T=NULL;
else {
T=(BiThrTree)malloc(sizeof(BiThrNode));
T->data=ch;
T->LTag=Link;
T->RTag=Link;
CreateThrTree(T->lchild);
CreateThrTree(T->rchild);
}
return OK;
}
status InThreading(BiThrTree T){
if(T){
InThreading(T->lchild);
if(!T->lchild){
T->LTag=Thread;
T->lchild=pre;
}
if(!pre->rchild){
pre->RTag=Thread;
pre->rchild=T;
}
pre=T;
InThreading(T->rchild);
}
return OK;
}
status InOrderThreading(BiThrTree &Thrt,BiThrTree T){
Thrt=(BiThrTree)malloc(sizeof(BiThrNode));
Thrt->LTag=Link;
Thrt->RTag=Thread;
Thrt->rchild=Thrt;
if(!T)Thrt->lchild=Thrt;
else {
Thrt->lchild=T;
pre=Thrt;
InThreading(T);
pre->RTag=Thread;
pre->rchild=Thrt;
Thrt->rchild=pre;
}
return OK;
}
status InOrderTraverse_Thr(BiThrTree Thrt){
BiThrTree p=Thrt->lchild;
while(p!=Thrt){
while(p->LTag==Link)p=p->lchild;
printf("%c",p->data);
while(p->RTag==Thread && p->rchild!=Thrt){
p=p->rchild;
printf("%c",p->data);
}
p=p->rchild;
}
return OK;
}
int main(){
BiThrTree Thrt,T;
CreateThrTree(T);
InOrderThreading(Thrt,T);
InOrderTraverse_Thr(Thrt);
puts("");
return 0;
}
(四)运行结果:

(五)实验总结:
1. 问题与解决方法 在编写程序时, 遇到了一个程序保存后编译正确却运行不了, 之后请教了我们班的同学, 才知道是第一个函数出了问题,改了之后就好了。 2. 收获和体会 做程序编写时,必须要细心,有时候问题出现了,可能会一直查不出来。自己也不容易 发现。在编写这个程序时,我就出现了这个问题,之后一定要尽量避免此类问题出现。 3. 尚存在的问题 这几个子函数的名称都是边看着书边写的, 还没有完全脱离书本, 真正变成自己建的东 西。还要加强记忆。
五、图
实验十二:图的建立与遍历
(一)实验目的:
1、掌握图的意义;
2、掌握用邻接矩阵和邻接表的方法描述图的存储结构;
3、理解并掌握深度优先遍历和广度优先遍历的存储结构。
(二)实验内容:
按邻接矩阵的方法创建图,分别用深度优先和广度优先方法遍历图。
(三)实验程序:
#include<stdio.h>
#include<string.h>
int n,m,tou,wei,team[1000],biao[200],ji[200];
struct node{
int a[105],sum;
}e[105];
void DFS(int x) {
int i,j,p,q;
for(i=0;i<e[x].sum;i++){
if(ji[e[x].a[i]]==0){
ji[e[x].a[i]]=1;
printf(" %d",e[x].a[i]);
DFS(e[x].a[i]);
}
}
}
void BFS() {
int i,j,p,q;
for(i=0;i<n;i++){
if(biao[i]==0) {
biao[i]=1;
team[tou++]=i;
if(i==0)
printf("%d",i);
else
printf(" %d",i);
}
while(tou>wei){
p=team[wei++];
for(j=0;j<e[p].sum;j++){
if(biao[e[p].a[j]]==0) {
biao[e[p].a[j]]=1;
printf(" %d",e[p].a[j]);
team[tou++]=e[p].a[j];
}
}
}
}
printf("\n");
}
int main () {
while(scanf("%d%d",&n,&m)!=EOF){
memset(team,0,sizeof(team));
memset(biao,0,sizeof(biao));
memset(ji,0,sizeof(ji));
tou=0,wei=0;
for(int i=1;i<=m;i++){
int a,b;
scanf("%d%d",&a,&b);
e[a].a[e[a].sum++]=b;
e[b].a[e[b].sum++]=a;
}
for(int i=0;i<n;i++)
if(ji[i]==0){
if(i==0)
printf("%d",i);
else
printf(" %d",i);
ji[i]=1;
DFS(i);
}
printf("\n");
BFS();
printf("\n");
}
}
(四)运行结果:
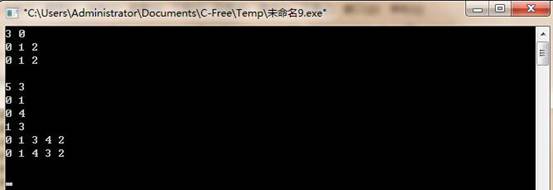
(五)实验总结:图的存储结构相比表和树都要复杂,其操作过程也较难进行掌握。仅仅是创建图的存储结构便分为矩阵、临接链表、十字链表等,对于每一种存储结构又分为有向与无向之分。然而,深度优先和广度优先是两种算法,其算法思想并不依赖与元素的存储方式,也就是说算法思想不会因为存储结构的改变而发生改变,当然对于不同的存储结构仅仅是代码的表现形式不同而已,正所谓一同百通,只要熟悉存储结构的特点又对算法思想烂熟于心便可无往不胜。
实验十三:最小生成树Prim算法
(一)实验目的:
1.理解构造无向连通图的最小生成树的Prim算法;
2.能用Prim算法求出最小生成树。
(二)实验内容:
农民约翰被选为他们镇的镇长!他其中一个竞选承诺就是在镇上建立起互联网,并连接到所有的农场。当然,他需要你的帮助。 约翰已经给他的农场安排了一条高速的网络线路,他想把这条线路共享给其他农场。为了用最小的消费,他想铺设最短的光纤去连接所有的农场。 你将得到一份各农场之间连接费用的列表,你必须找出能连接所有农场并所用光纤最短的方案。 每两个农场间的距离不会超过100000。
(三)实验程序:
#include<stdio.h>
#include<stdlib.h>
#define OK 1
#define ERROR 0
#define OVERFLOW -1
#define MAX_VERTEX_NUM 100
typedef int Status;
typedef struct {
int vexs[MAX_VERTEX_NUM];
int arcs[MAX_VERTEX_NUM][MAX_VERTEX_NUM];
int vexnum;
}MGraph;
struct{
int adjvex;
int lowcost;
}closedge[MAX_VERTEX_NUM];
Status CreateGraph(MGraph &G){
int i,j;
scanf("%d",&G.vexnum);
for(i=0;i<G.vexnum;i++){
G.vexs[i]=i;
for(j=0;j<G.vexnum;j++){
scanf("%d",&G.arcs[i][j]);
}
}
return OK;
}
Status mininum(int num){
int i,w=1;
for(i=1;i<num;i++)
if(closedge[i].lowcost) {w=i;break;}
for(i++;i<num;i++)
if(closedge[i].lowcost && (closedge[w].lowcost>closedge[i].lowcost))w=i;
return w;
}
Status MiniSpanTree_PRIM(MGraph &G,int v){
int i,j,w,sum=0;
for(i=0;i<G.vexnum;i++){
closedge[i].adjvex=v;
closedge[i].lowcost=G.arcs[v][i];
}
for(i=1;i<G.vexnum;i++){
w=mininum(G.vexnum);
sum+=closedge[w].lowcost;
closedge[w].lowcost=0;
for(j=1;j<G.vexnum;j++){
if(closedge[j].lowcost && (G.arcs[w][j]<closedge[j].lowcost)){
closedge[j].adjvex=w;
closedge[j].lowcost=G.arcs[w][j];
}
}
}
printf("%d\n",sum);
return OK;
}
int main(){
MGraph G;
CreateGraph(G);
MiniSpanTree_PRIM(G,0);
return 0;
}
(四)运行结果:
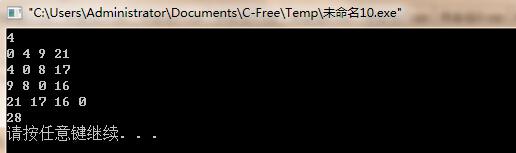
(五)实验总结:
通过此次实验后我深刻地学习了最小生成树的Prim算法,通过分析实验目的和实验内容;阐述不同方法的原理;分析不同方法的特点和区别以及时空复杂度;分析和调试测试数据和相应的结果.明白了Prim算法是设计思想:设图G =(V,E),其生成树的顶点集合为U。 把v0放入U。;在所有u∈U,v∈V-U的边(u,v)∈E中找一条最小权值的边,加入生成树;把②找到的边的v加入U集合。如果U集合已有n个元素,则结束,否则继续执行②。Prim算法实现:一方面利用集合,设置一个数组set(i=0,1,..,n-1),初始值为 0,代表对应顶点不在集合中(注意:顶点号与下标号差1) 。从算法、输入方便、存储安全等角度,我采用数组作为数据结构,即采用邻接矩阵的存储方式来存储无向带权图。另一方面,图用邻接矩阵或邻接表表示。通过本次的试验我大体掌握了图的基本操作设计与实现并学会利用Prim算法求网络的最小生成树。虽然本次试验做起来是比较成功的,但是我感觉还有不足试验效率很低,很难理解参考代码,所以测试时有一部分用了参考代码。然而我感觉自还是很有收获的,基本上读懂了参考代码,领悟了一些编程思想。
实验十五:单源最短路Dijkstra算法
(一)实验目的:
1、理解单源最短路的Dijkstra算法;
2、能用Dijkstra算法求出两点之间的最短路。
(二)实验内容:
某省自从实行了很多年的畅通工程计划后,终于修建了很多路。不过路多了也不好,每次要从一个城镇到另一个城镇时,都有许多种道路方案可以选择,而某些方案要比另一些方案行走的距离要短很多。这让行人很困扰。
现在,已知起点和终点,请你计算出要从起点到终点,最短需要行走多少距离。
(三)实验程序:
#include<stdio.h>
#include<stdlib.h>
#define ERROR 0
#define OK 1
#define true 1
#define false 0
#define oo 10000000
#define N 205
#define M 1005
int visited[N];
int dist[N];
int a;
int b;
typedef int status;
typedef struct{
int c;
}AlGraph[N][N];
typedef struct{
int vernum;
AlGraph arc;
}MGraph;
MGraph G;
status inidtvisited(){
for(int i=0;i<G.vernum;i++)
visited[i]=false;
return OK;
}
status ShortestPath_DIJ(){
int i,j,k,t;
for(i=0;i<G.vernum;i++)
dist[i]=G.arc[a][i].c;
visited[a]=true;
for(i=0;i<G.vernum;i++){
t=oo;
for(j=0;j<G.vernum;j++)
if(!visited[j]&&dist[j]<t)
{
t=dist[j];
k=j;
}
if(dist[k]==oo)break;
visited[k]=true;
for(j=0;j<G.vernum;j++)
if(!visited[j]&&dist[j]>dist[k]+G.arc[k][j].c)
dist[j]=dist[k]+G.arc[k][j].c;
}
if(dist[b]==oo)return -1;
else return dist[b];
}
int main(){
int n,m,i,j,k;
scanf("%d%d",&n,&m);
G.vernum=n;
for(i=0;i<n;i++){
for(j=0;j<n;j++){
if(i==j)G.arc[i][j].c=0;
else G.arc[i][j].c=oo;
}
}
while(m--&&scanf("%d%d%d",&i,&j,&n))
if(G.arc[i][j].c>n){
G.arc[i][j].c=G.arc[j][i].c=n;
}
scanf("%d%d",&a,&b);
k=ShortestPath_DIJ();
printf("%d\n",k);
return 0;
}
(四)运行结果:
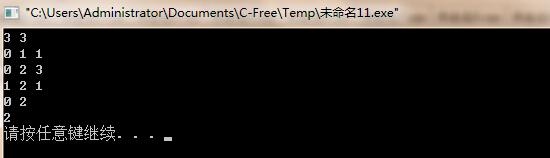 (五)实验总结:
(五)实验总结:
这个实验稍微复杂些,在实现算法时遇到好多问题,首先要实现距离的算法。通过这个算法,我明白了,你有了一个算法,要通过程序去实现它非常复杂,以后需要勤学苦练,加以熟练才能将算法变成程序。
六、查找
实验十八:BST树的构建与应用
(一)实验目的:
1、掌握BST的定义和基本性质;
2、实现BST树的建立、查找算法。
(二)实验内容:
实现BST查找及建立以及遍历算法,根据查询的数,建一颗BST树,初始树为空,重复的数不用插入树中。
(三)实验程序:
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
int a[50000];
int t;
typedef struct BiTNode{
int data;
struct BiTNode *lchild,*rchild;
} BiTNode ,*BiTree;
int SearchBST(BiTree T,int key,BiTree f,BiTree *p)
{
if(!T)
{
*p=f;
return 0;
}
else if(key==T->data)
{
*p=T;
return 1;
}
else if (key<T->data)
{
return SearchBST(T->lchild,key,T,p);
}
else {
return SearchBST(T->rchild,key,T,p);
}
}
int InsertBST(BiTree *T,int key)
{
BiTree p,s;
if(!SearchBST(*T,key,NULL,&p))
{
s=(BiTree)malloc(sizeof(BiTNode));
s->data=key;
s->lchild=s->rchild=NULL;
if(!p)
*T=s;
else if(key<p->data)
p->lchild=s;
else p->rchild=s;
return 1;
}
else{
t++;
return 0;
}
}
void PreOrderTraverse(BiTree T)
{
if(T==NULL)
return;
printf("%d ",T->data);
PreOrderTraverse(T->lchild);
PreOrderTraverse(T->rchild);
}
int main()
{
int i,n,m,j;
BiTree T=NULL;
t=0;
scanf("%d",&n);
for(i=0;i<n;i++)
{
scanf("%d",&a[i]);
InsertBST(&T,a[i]);
}
printf("%d\n",n-t);
PreOrderTraverse(T);
printf("\n");
}
(四)运行结果:

七、排序
实验十九:快速排序
(一)实验目的:
1、了解快速排序算法的算法及复杂度;
2、实现快速排序算法。
(二)实验内容:
对已知的数据进行快速排序
(三)实验程序:
#include<iostream>
#include<cstring>
#include<cstdio>
#include<algorithm>
using namespace std;
int a[20001];
int main() {
int i,k;
scanf("%d",&k);
for(i=0;i<k;i++)
scanf("%d",&a[i]);
sort(a,a+k);
for(i=0;i<k;i++)
printf("%d ",a[i]);
printf("\n");
}
(四)运行结果:
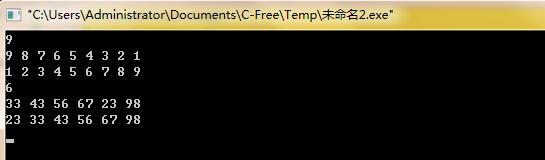
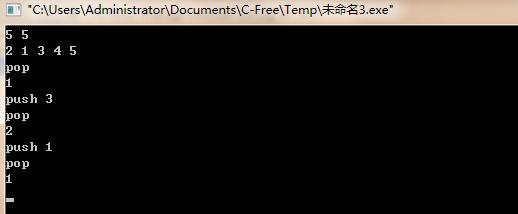
实验二十:堆的建立和维护
(一)实验目的:
1、了解堆的建立及其复杂度;
2、实现堆的建立、删除、插入操作。
(二)实验内容:
用已知的数据建立一个小顶堆,再对询问输出相应的结果。
(三)实验程序:
#include<stdio.h>
#include<string.h>
#define M 50005
int heap[M],n;
void sink(int now){
int son=now*2,a=heap[now];
while(son<=n){
if(son<n && heap[son+1]<heap[son]) son++;
if(heap[son]>=a)break;
heap[now]=heap[son];
now=son;
son=now*2;
}
heap[now]=a;
}
void swim(int now){
int fa=now/2,a=heap[now];
while(fa && a<heap[fa]){
heap[now]=heap[fa];
now=fa;
fa=now/2;
}
heap[now]=a;
}
void push(int a){
heap[++n]=a;
swim(n);
}
int pop(){
int r=heap[1];
heap[1]=heap[n--];
sink(1);
return r;
}
void build(){
for(int i=n/2;i>0;i--)
sink(i);
}
int main(){
int m,i,x;
while(scanf("%d%d",&n,&m)!=EOF){
for(i=1;i<=n;i++){
scanf("%d",&heap[i]);
}
build();
while(m--){
char str[10];
scanf("%s",str);
if(strcmp(str,"pop")==0)
printf("%d\n",pop());
else {
scanf("%d",&x);
push(x);
}
}
}
return 0;
}
(四)运行结果: