中科院研究生院统计分析与SAS实现第1次上机实习题
一、定量资料上机实习题
要求:
(1) 先判断定量资料所对应的实验设计类型;
(2) 假定资料满足参数检验的前提条件,请选用相应设计的定量资料的方差分析,并用SAS软件实现统计计算;
(3) 摘录主要计算结果并合理解释,给出统计学结论和专业结论。
【练习1】取4窝不同种系未成年的大白鼠,每窝3只,随机分配到三个实验组中,分别注射不同剂量雌激素,经过一定时间后处死大白鼠测子宫重量,资料见表1。问剂量和窝别的各自水平下子宫重量之间的差别有无统计学意义?若剂量间差别有统计学意义,请作两两比较。
表1 未成年大白鼠注射不同剂量雌激素后的子宫重量
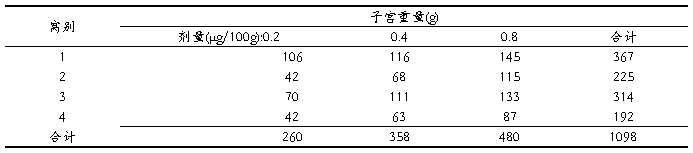
定量资料的随机区组设计(区组因素:窝别;实验因素:剂量)
【SAS程序】:
DATA PGM15G;
DO A=1 TO 4; /*A为窝别*/
DO B=1 TO 3; /*B为雌激素剂量*/
INPUT X @@; /*X为子宫重量*/
OUTPUT;
END;
END;
CARDS;
106 116 145
42 68 115
70 111 133
42 63 87
;
RUN;
ods html; /*将结果输出成网页格式,SAS9.0以后版本可用*/
PROCGLM DATA=PGM15G;
CLASS A B;
MODEL X=A B / SS3;
MEANS A B; /*给出因素A、B各水平下的均值和标准差*/
MEANS B / SNK; /*对因素B(即剂量)各水平下的均值进行两两比较*/
RUN;
ODS HTML CLOSE;
【练习2】一位工程师研究由钻头压力产生的冲力。考察了A(钻孔速度)和B(进料速度),两因素分别取2与3水平,各水平组合下均做了两次独立重复实验,资料见表2。假定资料满足参数检验的前提条件,且两因素对观测结果的影响地位平等,已知冲力越小越好,试作分析,尽可能给出较为明确的统计和专业结论。
表2 在钻孔速度和进料速度取不同水平的条件下冲力的测定结果

钻 孔 冲力(单位)
速 度 进料速度:0.015 0.030 0.045
125 2.70 2.45 2.60
2.78 2.49 2.72
200 2.83 2.85 2.86
2.86 2.80 2.87
两因素2 x 3析因设计
【SAS程序】:
DATA aaa;
DO zs=125,200;
DO repeat=1 TO 2; /*每种试验条件下有2次独立重复试验*/
do js=0.015,0.030,0.045;
INPUT cl @@;
OUTPUT;
END;
END;
END;
CARDS;
2.70 2.45 2.60
2.78 2.49 2.72
2.83 2.85 2.86
2.86 2.80 2.87
;
run;
ods html;
PROCGLM;
CLASS zs js;
MODEL cl=zs js zs*js / SS3;
MEANS zs*js;
LSMEANS zs*js / TDIFF PDIFF; /*对 zs和js各水平组合而成的试验条件进行均数进行两两比较*/
RUN;
ods html close;
二、定性资料上机实习题
要求:
(1)若题目中未给出表格,请列出标准的列联表,并对其命名;
(2)若题目中已列出不规范的表格,先修改,然后对其命名;
(3)根据分析目的或自己提出分析目的、资料的前提条件选用相应的统计分析方法,并用SAS软件实现计算;
(4)将主要计算结果摘录出来,给出统计学和专业结论。
【练习1】某卫生防疫站对屠宰场及肉食零售点的猪肉,检查其表层沙门氏菌带菌情况,结果如下表。试比较屠宰场与肉食零售点猪肉表层沙门氏菌的带菌率之间差别有无统计学意义?
表1 屠宰场及肉食零售点猪肉表层沙门氏菌抽检结果

横断面研究设计
【SAS程序】:
DATA PGM19A;
DO A=1 TO 2;
DO B=1 TO 2;
INPUT F @@;
OUTPUT;
END;
END;
CARDS;
2 26
8 21
;
run;
ods html;
PROCFREQ;
WEIGHT F;
TABLES A*B / CHISQ;
RUN;
ods html close;
【练习2】有人对某部门22707名雇员中,普查了HBsAg,其中3454名阳性,19253名为阴性。从1975年起,追踪了3年,发现在阳性组有40名患了肝癌,阴性组仅一名患肝癌。试选用合适的方法对资料进行全面分析。
队列研究设计2 x 2表
【SAS程序】:
DATA PGM19B;
DO A=1 TO 2;
DO B=1 TO 2;
INPUT F @@;
OUTPUT;
END;
END;
CARDS;
40 3414
1 19252
;
run;
ods html;
PROCFREQ;
WEIGHT F;
TABLES A*B / CHISQ cmh;
RUN;
ods html close;
【练习3】APOE-4等位基因与老年痴呆性的关联研究:以600名晚发及散发老年痴呆患者和400名正常对照为研究对象,分析APOE-4等位基因与老年痴呆性的关系。
表4 APOE-4等位基因与老年痴呆性病例对照关联研究

病例对照研究设计2 x 2表
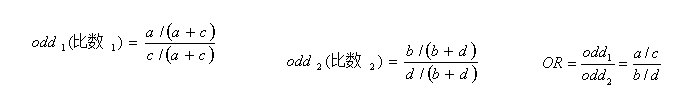
【SAS程序】:
ATA PGM20;
DO A=1 TO 2;
DO B=1 TO 2;
INPUT F @@;
OUTPUT;
END;
END;
CARDS;
240 60
360 340
;
run;
ods html;
PROCFREQ;
WEIGHT F;
TABLES A*B / CHISQ cmh;
RUN;
ods html close;
【练习4】请分析下表资料。已从专业上认定培养的阳性结果就是“真阳性”,而不会出现假阳性。
表3 两种培养基对同一批痰液标本同时培养的结果
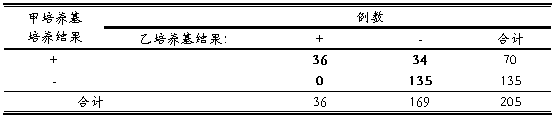
隐含金标准配对设计2 x 2表
配对设计2×2列联表资料总体率差异性检验统计量的计算公式
若b+c≥40时
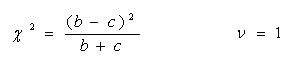
若b+c<40时

【SAS程序】:
DATA PGM19F;
INPUT b c;
chi=(ABS(b-c)-1)**2/(b+c);
p=1-PROBCHI(chi,1);
chi=ROUND(chi, 0.001);
IF p>0.0001 THEN p=ROUND(p,0.0001);
FILE PRINT;
PUT #2 @10 'Chisq' @30 'P value'
#4 @10 chi @30 p;
CARDS;
34 0
;
run;
(甲培养基的阳性数大于乙培养基的阳性数)
【练习5】请分析下表资料。
表6 两法检查室壁收缩运动的符合情况
━━━━━━━━━━━━━━━━━━━
对比法测 冠心病人数
定的结果核素法∶正常 减弱 异常
───────────────────
正 常 58 2 3
减 弱 1 42 7
异 常 8 9 17
───────────────
合计 67 53 27
━━━━━━━━━━━━━━━━━━━
双向有序且属性相同R x C列联表(Kappa检验)
【SAS程序】:
data aaa;
do a=1 to 3;
do b=1 to 3;
input f @@;
output;
end;
end;
cards;
58 2 3
1 42 7
8 9 17
;
run;
ods html;
*简单kappa检验;
procfreq data=aaa;
weight f;
tables a*b;
test kappa;
run;
*加权kappa检验;
procfreq;
weight f;
tables a*b;
test wtkap;
run;
ods html close;
(两种方法的一致性检测有统计学意义)
简单kappa检验和加权kappa检验这两种方法都是用来检验两种评价方法是否具有一致性的方法。其主要的区别是两种方法计算的公式不一样,更具体地说是对两个变量的打分不一样,简单kappa检验主要是利用对角线上的信息,加权kappa检验除了利用对角线上的数据外,还将对角线外的数据进行加权打分,将对角线外的信息也充分利用。所以在选择方法时应根据专业知识,如果两个变量取值的界线比较明确,如“+”“++”“+++”等,这时可以选用简单的kappa检验,如果两个变量的取值不十分明确,人为的因素较多时,就可选用加权kappa检验。
【练习6】请分析下表资料。
表5 某地6094人按2种血型系统划分的结果
━━━━━━━━━━━━━━━━━━━
ABO 人 数
血型 MN血型:M N MN
───────────────────
O 431 490 902
A 388 410 800
B 495 587 950
AB 137 179 325
───────────────
合计 1451 1666 2977
━━━━━━━━━━━━━━━━━━━
双向无序R x C列联表(卡方或Fisher精确检验)
【自由度=(行数-1)X(列数-1】
【SAS程序】:
DATA PGM20A;
DO A=1 TO 4;
DO B=1 TO 3;
INPUT F @@;
OUTPUT;
END;
END;
CARDS;
431 490 902
388 410 800
495 587 950
137 179 325
;
run;
ods html;
PROCFREQ;
WEIGHT F;
TABLES A*B / CHISQ;*exact;
RUN;
ods html close;
(行变量与列变量相互独立,……)
分析方法选择
不超过1/5的格子理论频数<5时,此类资料应采用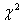 检验处理。
检验处理。
其他情形,可采用Fisher精确检验处理。
【练习7】请分析下表资料。
表7 3种药物疗效的观察结果
━━━━━━━━━━━━━━━━━━━
疗 人 数
效 药物∶ A B C
───────────────────
治愈 15 4 1
显效 49 9 15
好转 31 50 45
无效 5 22 24
───────────────
合计 100 85 85
━━━━━━━━━━━━━━━━━━━
结果变量为有序变量的单向有序R x C列联表
【SAS程序】:
*方法1;
DATA PGM20C;
DO A=1 TO 4;
DO B=1 TO 3;
INPUT F @@;
OUTPUT;
END;
END;
CARDS;
15 4 1
49 9 15
31 50 45
5 22 24
;
run;
ods html;
PROCNPAR1WAY WILCOXON;
FREQ F;
CLASS B;
VAR A;
RUN;
*方法2;
procfreq data=PGM20C;
weight f;
tables b*a/cmh scores=rank;
run;
ods html close;
【练习8】请分析下表资料。
表8 眼晶状体混浊度与年龄之关系
━━━━━━━━━━━━━━━━━━━
晶状体混 眼 数
浊 程度 年龄∶20~ 30~ 40~
───────────────────
+ 215 131 148
++ 67 101 128
+++ 44 63 132
───────────────
合计 326 295 408
━━━━━━━━━━━━━━━━━━━
双向有序且属性不同R x C列联表 (spearman秩相关)
【SAS程序】:
DATA PGM20E;
DO A=1 TO 3;
DO B=1 TO 3;
INPUT F @@;
OUTPUT;
END;
END;
CARDS;
215 131 148
67 101 128
44 63 132
;
run;
ods html;
PROCCORR SPEARMAN;
VAR A B;
FREQ F;
RUN;
ods html close;
第二篇:SAS系统上机
SAS上机指导
一、SAS系统的熟悉与了解.... 4
二、SAS编程.... 5
1.创建数据集.... 5
1.1 自由格式... 5
1.2列方式.... 5
1.3规定格式... 5
2.数据集的整理.... 6
2.1建立新变量、累加、选择变量... 6
2.2条件语句... 6
2.3循环语句... 6
2.4数据集的连接与合并... 7
2.5 SAS与外部数据的交换.... 8
三、Means和Univariate过程.... 10
1.计算统计量.... 10
2.图形概括.... 10
四、随机数的产生与模拟.... 11
1. 非均匀随机数的产生.... 11
1.1逆变换法... 11
1.2合成法... 11
1.3筛选抽样法... 11
2. Monte Carlo方法在解确定性问题中的应用.... 12
3. 随机模拟方法在随机服务系统中的应用.... 14
4. 随机模拟方法在理论研究中的应用.... 14
五、区间估计和假设检验.... 17
1. 正态总体的均值、方差的区间估计.... 17
2. 均值、方差的假设检验.... 18
3.正态性检验.... 19
4. 非参数秩和检验.... 20
六、方差分析.... 21
七、回归分析.... 23
八、附录:insight简介.... 24
SAS系统上机
一、SAS系统的熟悉与了解
1起动SAS系统
2 SAS系统的窗口 PGM、LOG、OUTPUT、KEY、DIR、VAR、LIB
3 SAS菜单条(不同的窗口其内容有所不同)
4工具栏
5 命令条:在里面输入显示管理(DM)命令后回车或点击前面的对号
6状态栏 其左边显示一些重要的帮助信息或提示。右边有一个用于更改工作目录的图标,双击它可改变SAS的当前的工作目录,
7了解菜单栏
8 在程序窗口输入以下程序,
data bodyfat;
inPUt sex $ fatpct @@;
fat=fatpct/100;
cards;
M 13.3 F 22 M 19 F 26 M 20 F 16 M 8 F 12 M 18 F 21.7
M 22 F 23.2 M 20 F 21 M 31 F 28 M 21 F 30 M 12 F 23
M 16 M 12 M 24
RUN;
PROC means data=bodyfat;
var fatpct;
run;
(1)执行该程序,看看LOG窗、OUTPUT窗的表示,并将这两个窗口的内容保存
(2)回到程序窗口,将原程序调回,并将该程序保存到磁盘
(3)三个窗口的切换
(4)退出SAS系统,并重新启动,在程序窗口中打开刚才保存的SAS程序。
(5)建立SAS数据库(用菜单的方式以及程序方式),并将数据集存放到该数据库下。
二、SAS编程
1.创建数据集
1.1 自由格式
输入以下程序:
data A;
input sex $ fatpct;
cards;
M 13.3 /*一个数据一行*/
F 22
M 19
F 26
run;
proc print data=A;
run;
还可改变数据的存放格式
data A;
input sex $ fatpct @@;/*可以多个数据一行*/
cards;
M 13.3 F 22 M 19 F 26
run;
1.2列方式
data b;
input name$ 1-6 dmy$ 7-13 sex$ 14-15 math 16-17 phy 18-19 eng 20-21;
/*用下面一个语句看结果如何*/
/* input name$ 1-6 sex$ 14-15 dmy$ 7-13 phy 18-19;*/
cards;
张 军01MAR75男807984
王卫红24JUL78女959689
run;
1.3规定格式
data c;
input @1 name$ 6. dmy date7. sex$ 2. math 2. phy 2. eng 2.;
/*input name$ 6. @14 sex$ 2. @7 dmy date7. +4 phy 2.;*/
/*用这个语句可替换上一个语句,看看结果*/
cards;
张 军01MAR75男807984
王卫红24JUL78女959689
run;
2.数据集的整理
2.1建立新变量、累加、选择变量
data B;
input name$ 1-6 dmy 7-13 sex$ 14-15 math 16-17 phy 18-19 eng 20-21;
total=sum(math,phy);/*新变量*/
teng+eng;/*累加变量*/
drop dmy sex;/*此句亦可用KEEP NAME MATH PHY ENG TOTAL TENG;替代。*/
cards;
张 军01MAR75男807984
王卫红24JUL78女959689
run;
2.2条件语句
data CM CF;
input name$ 1-6 dmy 7-13 sex$ 14-15 math 16-17 phy 18-19 eng 20-21;
if sex='男' then output CM;
if sex='女' then output CF;
drop dmy sex;/*此句亦可用KEEP NAME MATH PHY ENG TOTAL TENG;替代。*/
cards;
张 军01MAR75男807984
王卫红24JUL78女959689
run;
2.3循环语句
data e;
seed=789;
do I=1 to 50 ;
x=rannor(seed);
y=2+3*x;
output;
end;
run;
proc gchart data=e;
vbar y;
run;
2.4数据集的连接与合并
连接
data A;
input no name$ math phy eng;
cards;
9701 wanglei 90 86 79
9702 wanghao 98 97 90
9703 gudexian 87 86 94
9706 zhuming 96 87 86
run;
data B;
input no name$ math phi chem geo;
cards;
9701 wanglei 90 86 89 76
9702 wanghao 98 97 69 72
9704 zhuzhun 88 76 78 68
9705 chaoyin 64 85 76 66
run;
data C;/*连接两个数据集*/
set A(drop=eng) B(drop=chem geo rename=(phi=phy));
run;
合并
一对一合并
data AA;
input x1 x2 ;
cards;
1 2
7 8
4 5
;
data BB;
input x1 y1 y2;
cards;
11 22 33
44 55 66
run;
data aabb;
merge AA BB;
run;
匹配合并
data A;
input no name$ math phy eng;
cards;
9701 wanglei 90 86 79
9702 wanghao 98 97 90
9703 gudexian 87 86 94
9706 zhuming 96 87 86
run;
data B;
input no name$ math phi chem geo;
cards;
9701 wanglei 90 86 89 76
9702 wanghao 98 97 69 72
9704 zhuzhun 88 76 78 68
9705 chaoyin 64 85 76 66
run;
proc sort data=a;
by no;
run;
proc sort data=b;
by no;
run;
data C;
merge A B;
by no;
run;
2.5 SAS与外部数据的交换
事先在e:\example 目录下准备以下三个文件EX1.DBF、EX2.XLS、EX3.TXT,则三者分别与SAS之间进行文件转换如下。
1 DBF文件转换为SAS文件。
filename ex1 'e:\example\ex1.dbf;
proc dbf db3=ex1 OUT=DBF2SAS;
run;
将e:\example 目录下EX1.DBF文件转换成SAS数据集DBF2SAS,存放在临时数据库WORK中.
2 SAS文件转换为DBF文件。
filename ex11 'e:\example\sas2dbf.dbf';
proc dbf db3=ex11 data=DBF2SAS;
run;
将SAS数据集DBF2SAS转换成DBF数据库文件SAS2DBF.DBF,存放在e:\example 目录下.
3 EXCEL文件转换为SAS文件
filename ex2 'e:\example\ex2.xls;
proc dbf db3=ex2 OUT=XLS2SAS;
run;
将EXCEL文件EX2.XLS转换为SAS文件XLS2SAS,并存放在SAS的临时库WORK中.
4 SAS文件转换为EXCEL文件
filename ex22 'e:\example\SAS2XLS.xls';
proc dbf db3=ex22 data=XLS2SAS;
run;
则将SAS文件XLS2SAS转换为EXCEL文件SAS2XLS.xls
5 文本文件转换为SAS文件,并设其内容为如下形式
9701 wanglei 90 86
9702 wanghao 98 97
9703 gudexian 87 86
9706 zhuming 96 87
filename ex3 'e:\example\ex3.txt';
data txt2sas;
infile ex3;
input no name$ math phy;
run;
则将EX3.TXT文本文件转换为SAS文件TXT2SAS.
6 SAS文件转换为文本文件
DATA _null_; /*表示不建数据集, _null_为SAS的关键词 */
SET TXT2SAS;
FILE 'E:\EXAMPLE\SAS2TXT.TXT';/*指出存放的文件位置*/
PUT NO 4. NAME8. MATH 2. PHY2. ;/*存在文件中的变量及格式*/
RUN;
则将TXT2SAS转换成了文本文件SAS2TXT.TXT,并存放在目录e:\example下.
三、Means和Univariate过程
1.计算统计量
1.熟悉两个过程的格式(语法)
2输入以下程序,并改变相应的参数,看输出的结果
data stat;
input x@@;
cards;
0.86 0.78 0.83 0.84 0.77 0.84 0.81 0.84 0.81 0.81 0.80 0.81
0.79 0.74 0.82 0.78 0.82 0.78 0.81 0.80 0.81 0.74 0.87 0.78
0.82 0.75 0.78 0.79 0.80 0.85 0.81 0.78 0.87 0.74 0.81 0.71
0.77 0.88 0.78 0.82 0.77 0.76 0.78 0.85 0.77 0.73 0.77 0.78
0.77 0.81 0.71 0.79 0.95 0.77 0.78 0.78 0.81 0.81 0.79 0.87
0.80 0.83 0.77 0.65 0.76 0.64 0.82 0.78 0.80 0.75 0.82 0.82
0.84 0.80 0.79 0.80 0.90 0.77 0.82 0.81 0.79 0.75 0.82 0.83
0.79 0.90 0.86 0.80 0.76 0.85 0.78 0.81 0.83 0.77 0.75 0.78
0.82 0.82 0.78 0.84 0.73 0.85 0.83 0.84 0.81 0.82 0.81 0.85
0.83 0.84 0.89 0.82 0.81 0.85 0.86 0.84 0.82 0.78 0.82 0.78
;
proc means data=stat mean var std stderr range cv skewness kurtosis;/*means可换为Univariate*/
var x;
run;
3.并结果用数据集的形式保存。
2.图形概括
用上例数据,输入以下程序
proc chart data=stat;/*chart可换为gchart*/
vbar x;
vbar x/type=percent;
vbar x/type=cpercent;
run;
四、随机数的产生与模拟
1. 非均匀随机数的产生
1.1逆变换法
例1 已知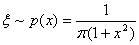 (柯西分布),试给出其抽样方法。
(柯西分布),试给出其抽样方法。
data ex1;
seed=678;
do I=1 to 100;
r=ranuni(seed);
x=tan(3.14159*(r-0.5));
output;
end;
run;
1.2合成法
例2 设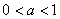 时梯形分布的密度函数为
时梯形分布的密度函数为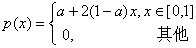 ,试用合成法产生其随机数。
,试用合成法产生其随机数。
data ex2;
seed=789;a=0.3;
do I=1 to 100;
r=ranuni(seed); r3=ranuni(seed);
if r1<=a then do; u=ranuni(seed); x=u; end;
else do; u=ranuni(seed); v=ranuni(seed); x=max(u,v);end;
output;
end;
run;
1.3筛选抽样法
例3 设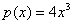 ,
,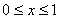 ,试用筛选法抽取其随机数。
,试用筛选法抽取其随机数。
data ex3;
seed=789;
do I=1 to 100;
r1=ranuni(seed);r2=ranuni(seed);
if r1<=r2**3 then do; x=r2; output; end;
end;
run;
2. Monte Carlo方法在解确定性问题中的应用
例4:计算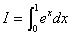 ,
,
(1)随机投点法
SAS程序如下:
data E1;
Do k= 1 to 1000;
m=0;
Do h= 1 to 1000;
a=ranuni(32789);
b=ranuni(32789);
if b<=(exp(a)-1)/(exp(1)-1) then m=m+1;
end;
I1=m/1000*(exp(1)-1)+1;
output;
E1=abs(I1-(exp(1)-1));
end;
run;
proc means data=e1 Mean Var;
var I1;
run;
(2)平均值估计法
data E2;
Do k= 1 to 1000;
s=0;
Do i=1 to 1000;
x=ranuni(32789);
fx=exp(x);
s=s+fx;
end;
I2=s/1000;
output;
E2=abs(I2-(exp(1)-1));
end;
run;
proc means data=e2 Mean Var;
var I2;
run;
(3)重要抽样法
data E3;
do k=1 to 1000;
s=0;
Do i=1 to 1000;
r=ranuni(32789);
x=(3*r+1)**(1/2)-1;
s=s+exp(x)/(1+x);
end;
I3=3/(2*1000)*s;
output;
E3=abs(I3-(exp(1)-1));
End;
run;
proc means data=e3 Mean Var;
var I3;
run;
(4)分层抽样法
data E4;
Do k= 1 to 1000;
s1=0;
s2=0;
Do i= 1 to 400;
ri=ranuni(32789);
r1=0.5*ri;
f1=exp(r1);
s1=s1+f1;
end;
Do j= 1 to 600;
rj=ranuni(32789);
r2=0.5+0.5*rj;
f2=exp(r2);
s2=s2+f2;
end;
I4=s1*(1/800)+s2*(1/1200);
output;
E4=abs(I4-(exp(1)-1));
end;
run;
proc means data=e4 Mean Var;
var I4;
run;
3. 随机模拟方法在随机服务系统中的应用
例5 某服务系统有三个服务员,输入流为泊松流,服务时间为指数分布。每个顾客服务时间等于0.5分钟。求在T=4分钟内被服务顾客的数学期望。
解:设 表示第
表示第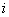 个顾客到达的时刻,
个顾客到达的时刻,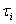 表示第个顾客到达的时间间隔。则有
表示第个顾客到达的时间间隔。则有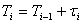 。SAS程序为
。SAS程序为
data ex7;
s1=0;s2=0;s3=0;
T=0;
Do until(T>4);
R=ranuni(-1);
P=0.2*(-log(R));
T=T+p;
Ss1=s1; ss2=s2; ss3=s3;
If (T<=ss1) and (T<=ss2) and (T<=ss3) then d=0;
Else d=1;
If (T>ss1) then do; s1=T+0.5; end;
If(T<=ss1) and (T<=ss2) and (T>ss3) then do; s3=T+0.5;end;
Output;
End;
Run;
Proc means data=ex7;
Var d;
Output out=result sum=dsum;
Run;
Proc print data=result;
Run;
4. 随机模拟方法在理论研究中的应用
例8:
假设数据来自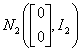 和
和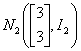 的总体,用SAS来计算,比较系统聚类法的八种常用方法在分类时之间的分类效果的好坏。
的总体,用SAS来计算,比较系统聚类法的八种常用方法在分类时之间的分类效果的好坏。
其SAS程序为(以average为例):
%macro createdata(mdata=, leixing=, mv1=, mv2=, mvar1=, mvar2=, mvar3= );
data &mdata;
drop i u1 u2 ;
fenlei=&leixing.;
do i=1 to 50;
u1=rannor(0);
u2=rannor(0);
x1=&mv1.+sqrt(&mvar1.)*u1; x2=&mv2.+(&mvar2.*u1+sqrt(&mvar1.*&mvar3.-&mvar2.*&mvar2.)*u2)/sqrt(&mvar1.);
output;
end; /*产生来自两元正态总体的随机数据*/
run;
%mend createdata;
%macro datacluster(mdata=,method=);
data &mdata.;
set a b;
run;
proc cluster data=&mdata. method=&method. outtree=c noprint;
var x1 x2;
copy fenlei x1 x2;
run; /*对两个来自不同两元正态总体的随机数据进行聚类*/
proc tree data=c out=abc ncl=2 noprint;
copy fenlei x1 x2;
run;
data result1;
set abc;
result=0;
if fenlei^=cluster then result=1;
run;
proc sort data=result1;
by fenlei;
run;
proc means data=result1 noprint;
var result;
by fenlei;
output out=result sum=errorsum;
run; /*计算出错分的个数*/
proc append base=r_result data=result;
run;
%mend datacluster;
%macroanalyze;
%do i=1 %to 50;
%createdata(mdata=a,leixing=1, mv1=0, mv2=0, mvar1=1, mvar2=0, mvar3=1);
%createdata(mdata=b,leixing=2, mv1=3, mv2=3, mvar1=1, mvar2=0, mvar3=1);
%datacluster(mdata=ab,method=average);
%end;
%mend analyze;
%analyze;
data rr;
set r_result;
if errorsum>25 then errorsum=50-errorsum;
errorratio=errorsum/50;
run; /*计算错分率*/
procsort data=rr;
by fenlei;
run;
procmeans data=rr noprint;
output out=r mean=err_ratio;
var errorratio;
by fenlei;
run; /*计算平均错分率*/
procprint data=r;
var fenlei err_ratio;
title '总错判率:';
run;
在运用SAS进行计算时,只需将“method=average”中的“average”用其它七种聚类方法进行替换即可。
五、区间估计和假设检验
1. 正态总体的均值、方差的区间估计
例1:设某厂一车床生产的钮扣,其直径据经验服从正态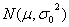 ,
,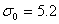 。为了判断其均值的置信区间,现抽取容量n=100的子样,其子样均值
。为了判断其均值的置信区间,现抽取容量n=100的子样,其子样均值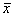 =26.56,求其均值的95%的置信区间.
=26.56,求其均值的95%的置信区间.
SAS程序为
data val1;
xbar=26.56;
sigma=5.2;
n=100;
u=probit(0.975);
delta=u*sigma/sqrt(n);
lcl=xbar-delta;
ucl=xbar+delta;
proc print data=val1;
var lcl xbar ucl;
run;
例2(t检验的置信区间) 检验某种型号玻璃纸的横向廷伸率。测得的数据如下:

现在要检验假设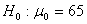 ,并求出其95%的置信区间。
,并求出其95%的置信区间。
SAS程序为:
data var22;
input x fx@@;
y=x-65;
cards;
35.5 7 37.5 8 39.5 11 41.5 9 43.5 9 45.5 12 47.5 17 49.5 14
51.5 5 53.5 3 55.5 2 57.5 0 59.5 2 61.5 0 63.5 1
;
proc means data=var22 t prt clm;
var y;
freq fx;
run;
例3 假定初生婴儿(男孩)的体重服从正态分布,随机抽取12名新生婴儿,测其体重为3100,2520,3000,3000,3600,3160,3560,3320,2880,2600,3400,2540。试给出新生婴儿体重方差的置信区间(置信度为95% )。
SAS程序为
data val2;
input weight@@;
cards;
3100 2520 3000 3000 3600 3160
3560 3320 2880 2600 3400 2540
;
proc means data=val2;
output out=tval1 css=ss n=n;
data tval2;
set tval1;
df=n-1;
xlchi=cinv(0.025,df);
xuchi=cinv(0.975,df);
lchi=ss/xuchi;
uchi=ss/xlchi;
proc print data=tval2;
var lchi uchi;
run;
2. 均值、方差的假设检验
例1 单总体的U检验。见例1,不过将问题改为检验假设 。data val3;
。data val3;
xbar=26.56;
mu=26;
sigma=5.2;
n=100;
u=sqrt(n)*abs(xbar-mu)/sigma;
p=2*(1-probnorm(u));
proc print data=val3;
var u p;
run;
例2 成组数据的假设检验和区间估计。
在一台自动车床上加工直径为2.050毫米的轴,现每隔二小时,各抽取容量为10的子样,所得数据如下:
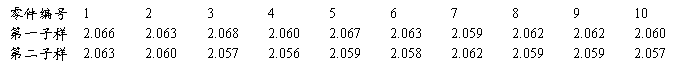
要考察这两个子样的均值是否相同?
SAS程序:
data sta2;
do len=1 to 2;
do i=1 to 10;
input y@@;
output;
end;
end;
cards;
2.066 2.063 2.068 2.060 2.067 2.063 2.059 2.062 2.062 2.060
2.063 2.060 2.057 2.056 2.059 2.058 2.062 2.059 2.059 2.057
;
proc ttest data=sta2;
class len;
var y;
run;
3.正态性检验
分布拟合优度检验和Q-Q检验
SAS程序为:
data score;
input x@@;
cards;
56 23 59 74 49 43 39 51 37 61
43 51 61 99 23 56 49 49 75 20
;
proc univariate data=score normal plot;
var x;
run;
偏度、峰度检验
data score;
input x@@;
cards;
56 23 59 74 49 43 39 51 37 61
43 51 61 99 23 56 49 49 75 20
;
proc univariate data=score;
var x;
output out=score1 skewness=skew kurtosis=kurt n=n;
data score2;
set score1;
uskew=2*sqrt(6/n);
lskew=-uskew;
tkurt=2*sqrt(24/n);
lkurt=-tkurt;
ukurt=tkurt;
proc print data=score2;
var skew lskew uskew kurt lkurt ukurt;
run;
图形法(拟合分布法,概率密度函数法)
data score;
input x@@;
cards;
56 23 59 74 49 43 39 51 37 61
43 51 61 99 23 56 49 49 75 20
;
proc capability data=score graphics ;
histogram x/normal;/*这句也可用下句替代*/
/* cdfplot x/normal;*/
run;
4. 非参数秩和检验
例 (成组数据的秩和检验) 实验室用局部温热治疗小鼠移植性肿瘤的疗效,以生存日数为观察指标,实验结果见表,问这两组小鼠生存日数有无差别?
表 小鼠发癌后生存日数

90*表示是截尾数据
data numdate;
do I=1 to 2;
input num;
do j=1 to num;
input y@@;
output;
end;
end;
cards;
10
10 12 15 15 16 17 18 20 23 90
12
2 3 4 5 6 7 8 9 10 11 12 13
;
proc npar1way data=numdate wilcoxon;
class I;
var y;
run;
六、方差分析
例1 设有三个小麦品种,经试种得第公顷产量的数据如下(单位: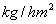 )
)
品种1:4350 4650 4080 4275
品种2:4125 3720 3810 3960 3930
品种3:4695 4245 4620
现问不同品种的小麦产量之间有无显著的差异?
data var1;
input kind$ yield@@;
cards;
1 4350 1 4650 1 4080 1 4275
2 4125 2 3720 2 3810 2 3960 2 3930
3 4695 3 4245 3 4620
;
proc glm;
class kind;
model yield=kind;
means kind/snk t alpha=0.05
means kind;
run;
例2 不考虑交互作用的两因素方差分析 为了考察蒸馏水的pH值和硫酸铜溶液浓度对化验血清中白蛋白与球蛋白的影响。pH值(A)取四种水平其值为5.40 5.60 5.70 5.80,记为A1、A2、A3和A4,硫酸铜浓度(B)取三种水平其值分别为0.04 0.08 0.10,记为B1、B2和B3,采用两因素的全面试验,所得结果如下:

SAS程序如下:
ata var2;
do B=1 to 3;
do A=1 to 4;
input y@@;
output;
end;
end;
cards;
3.5 2.6 2.0 1.4
2.3 2.0 1.5 0.8
2.0 1.9 1.2 0.3
;
proc anova ;
class A B;
model y=A B;
means A B/snk;
run;
例3为提高某化工产品的转化率,选择了三个有关的因素,反应温度(A),反应时间(B),用碱量(C),选取的水平如下

现按三因素正交表L9(34)表进行实验,所得的实验数据如下,请给出相应的分析。

data var5;
input A B C y;
cards;
1 1 1 31
1 2 2 54
1 3 3 38
2 1 2 53
2 2 3 49
2 3 1 42
3 1 3 57
3 2 1 62
3 3 2 64
;
proc anova;
class A B C;
model y=A B C;
run;
问题:为了诊断某种疾病,需要测量一个指标,并且在四种不同的条件下(记为A1,A2,A3,A4)来测量一个指标以增加诊断的可靠性。今对四位健康人测得的数据如下

要检验这四种条件有无显著的差异,若无显著的差异也就没有必要每人测四次。以此为例给出方差齐性的诊断。
七、回归分析
1. 熟悉REG过程
2. 以下例给出回归分析的过程
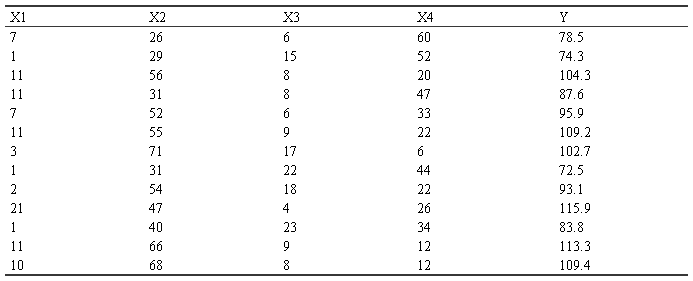
例:给出以下数据,请建立y与x1,x2,x3,x4间的线性回归方程
八、附录:insight简介
Sas/insight介绍
为一交互式的数据探索和分析的工具
功能:
1. 探索数据
2. 研究分布
3. 变量间的相关性分析
启动(三种方式)
1. 菜单(solutions/analysis/interactive data analysis)
2. 在命令窗口直接键入insight,并回车
3. 在程序窗口键入以下程序:proc insight; run;并运行即可
数据的输入和检查
新建数据集:
1. 新建数据集:提示打开数据集时,选new,即进行新建数据集。
2. 数据的类型为数值型(INTERVAL)和字符型(NOMINAL)
3. 编辑:可用光标键及TAB键在单元格中移动并输入数据;选中变量名或观测号来加亮变量或观测;
4. 右键中的菜单(数据的上托菜单,其中还有一个选项,显示标签)
5. 增加变量和观测
6. 定义变量
数据的保存(File/save/Data)
整理数据:
1. 整理变量(将某变量移到指定位置)方法一,选中某变量,右键/move to first
方法二:Edit/Windows/Tool/选手形图标,再选中某一变量名,按住左键,拖到指定位置即可。
2. 对观测排序 右键/Sort
3. 查找观测 Edit/Observations/Find 在值栏中可多选(用ctrl-或shift-)(选中观测)
右键/move to first(将所选观测移到观测的开头)
右键/Find Next(将所选观测显示到数据窗口的顶部,其所在的位置并没有移动)
4. 查看观测值: Edit/Observations/Examine
5. 关闭数据窗口 File/End
直方图、盒形图、分布的检验
直方图和条形图
一、生成条形图
1.生成直方图。Analyze/Histogram/Bar Chart(Y)
2.显示数据。点击某个条形,一方面可在条形上显示频数数据,另一方面在数据窗口中显示对应该条形图的观测。还可查看这些观测值:Edit/Observations/Examine
3.在图形上显示数据。点击图形区中的三角形,则弹出一个托菜单,(含有Tick..,Axes Observations Values)单击Values,则每个条形图显示出频数值。
4.图形的关联(图形、图形、数据三者间的关联)。若同时生成了两个图形,则二者间即形成关联(与打开的图形亦如此)。
盒形图的画法与条形图相仿。只是其图上的上托菜单有些区别,其中有mean(均值),serifs(盒须线)
分布的检验:
1.画直方图,Analyze/Distribution(Y)
2.增加密度函数。Curves/Parametric Density(or Kernel Density)
3.检验分布:Curves/CDF Confidence Band
Curves/Test for Distribution(or Test for a specific Distribution)
散点图、连线图和曲线拟合
散点图和连线图
散点图
1. 生成散点图 Analyze/Scatter Plot(Y X) 然后选Y和X变量。或在数据集上,先选中某两个变量,然后Analyze/Scatter Plot(Y X),则直接生成散点图。
2. 图形上的操作与直方图时一致。
散点图矩阵
1.方法同散点图
2.刷子
连线图(折线图)
1. 生成折线图 Analyze/Line Plot(Y X) 可在一幅图生成多个折线图,点击不同的变量名(Y轴方向),即可将该变量所示曲线加亮。
2. 添加折线 Edit/Windows/Renew 再在此处添加Y变量即可。
曲线拟合
拟合参数回归
1. 拟合曲线的步骤
Analyze/Fit(Y X) 选择Y变量和X变量。
注意Output选项。
2. 改变多项式的阶次 改变多项式阶次的滑块。
3. 增加曲线
法一:Curves
法二:Edit/Windows/Renew
4. 线段的颜色、线型和宽度
选中曲线,然后调用Edit/Windows/tool
非参数拟合
Curves/Kernel(or spline or loess or local polynomial)
多元回归
建立回归分析
Analyze/Fit(Y X) 选择Y变量和X变量
1. 模型信息(回归方程)
2. 拟合的概括
3. 方差分析
4. 类型III检验(类型III平方和一般称为偏平方和或部分平方和)
5. 参数估计
6. 残差对预测的图形
增加表格和图形
1.共线性诊断表 Tables/Collinearity Diagnostics(发现变量间的共线性)
2.部分杠杆图 Graphs/Partial Leverage(发现变量对Y变量的作用,斜率几乎为零表示该变量对Y没有作用)
3.残差诊断图 Vars/Dffits 作散点图Y为H_Y,X为F_Y。若值大于2,则说明这些点为强影响点。
修改模型
删除说明能力小的变量
扩充自变量
旋转图和主分量分析
旋转图
生成旋转图
Analyze/Rotatiing Plot(Z Y X)
旋转时所用工具:
图形左边的按钮
手形工具(Edit/windows/tool)
图形四角下的隐藏的手形图标
主分量分析
计算主分量
Analyze/Multivariate(Y’s)