信息论基础实验报告

2015 年 7 月 18 日
信源熵值的计算
一、实验目的
1 进一步熟悉信源熵值的计算
2 熟悉 vs2010 使用
二、实验原理
信息论中,熵:随机变量不确定性的度量。
设X为一离散型随机变量,其取之空间为X,概率密度函数为
p(x) = Pr(X = x), x∈X
则离散型随机变量X的熵H(X)定义为
H(X) = -
其中log的底为2,此时熵的单位为比特。
流程:
第一步:打开一个名为“zhangdongdong”的TXT文档,读入一篇英 文歌词 see you again存入一个数组temp,为了程序准确性将所读内容转存 到 另一个数组S,计算该数组中每个字母与空格的出现次数(遇到小写字 母 都将其转化为大写 字母进行计数),每出现一次该字符的计数器+1。
第二步:计算信源总大小计算出每个字母和空格出现的概率;
最后,通过统计数据和信息熵公式计算出所求信源熵值
程序流程图:
开始---->打开文档将英文字母读入数组----->计算每个字母及空格出现 次数,算出频率 ---> 求出信息熵------>输入结果
三、实验内容
1、写出计算自信息量的C 程序
2、已知:信源符号为英文字母(不区分大小写)和空格。
输入:一篇英文的信源文档。
输出:给出该信源文档的中各个字母与空格的概率分布,以及该信源的熵。
四、实验环境
Microsoft Windows 7
VS2010
五、编码程序


六、运行结果

其中文档内容如下:

七、实验总结
在实验中,我进一步了解到信源熵的计算,理论和实践的结合让我对这个知识点了解的更加深刻了。
第二篇:香农编码实验报告
中南大学
《信息论与编码》实验报告
目录
一、香农编码……………………………………….....3
实验目的.................................................................................3
实验要求.................................................................................3
编码算法.................................................................................3
调试过程.................................................................................3
参考代码.................................................................................4
调试验证.................................................................................7
实验总结.................................................................................7
二、哈夫曼编码……………………………………….8
实验目的.................................................................................8
实验原理.................................................................................8
数据记录.................................................................................9
实验心得................................................................................10
一、香农编码
1、实验目的
(1)进一步熟悉Shannon编码算法;
(2)掌握C语言程序设计和调试过程中数值的进制转换、数值与字符串之间的转换等技术。
2、实验要求
(1)输入:信源符号个数q、信源的概率分布p;
(2)输出:每个信源符号对应的Shannon编码的码字。
3、Shannon编码算法
1:procedure SHANNON(q,{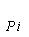 })
})
2: 降序排列{ }
}
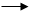 3: for i=1 q do
3: for i=1 q do
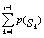
 4: F(
4: F(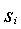 )
)
 5:
5:
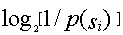
6:将累加概率F()(十进制小数)变换成二进制小数。
7:取小数点后个二进制数字作为第i个消息的码字。
8:end for
9:end procedure
------------------------------------------------------------------------------------------------------------------
4、调试过程
1、fatal error C1083: Cannot open include file: 'unistd.h': No such file or directory
fatal error C1083: Cannot open include file: 'values.h': No such file or directory
原因:unistd.h和values.h是Unix操作系统下所使用的头文件
纠错:删去即可
2、error C2144: syntax error : missing ')' before type 'int'
error C2064: term does not evaluate to a function
原因:l_i(int *)calloc(n,sizeof(int)); l_i后缺少赋值符号使之不能通过编译
纠错:添加上赋值符号
3、error C2018: unknown character '0xa1'
原因:有不能被识别的符号
纠错:在错误处将不能识别的符号改为符合C语言规范的符号
4、error C2021: expected exponent value, not ' '
原因:if(fabs(sum-1.0)>DELTA); 这一行中DELTA宏定义不正确
纠错:# define DELTA 0.000001
5、error C2143: syntax error : missing ';' before '}'
原因:少写了“;”号
纠错:在对应位置添加上“;”号
5、参考代码
# include<stdio.h>
# include<math.h>
# include<stdlib.h>
# include<string.h>
# define DELTA 0.000001/*精度*/
void sort(float*,int);/*排序*/
int main(void)
{
register int i,j;
int n; /*符号个数*/
int temp;/*中间变量*/
float *p_i; /*符号的概率*/
float *P_i; /*累加概率*/
int *l_i; /*码长*/
char * *C; /*码集合*/
/*用sum来检验数据,用p来缓存了中间数据*/
float sum,p;
/*输入符号数*/
fscanf(stdin,"%d",&n);
/*分配内存地址 */
p_i=(float *)calloc(n,sizeof(float));
P_i=(float *)calloc(n,sizeof(float));
l_i=(int *)calloc(n,sizeof(int));
/* 存储信道传输的概率*/
for(i=0;i<n;i++)
fscanf(stdin,"%f",&p_i[i]);
/*确认输入的数据*/
sum=0.0;
for(i=0;i<n;i++)
sum+=p_i[i];
if(fabs(sum-(1.0))>DELTA)
fprintf(stderr,"Invalid input data \n");
fprintf(stdout,"Starting…\n\n");
/*以降序排列概率*/
sort (p_i,n);
/*计算每个符号的码长*/
for(i=0;i<n;i++)
{
p=(float)(-(log(p_i[i])))/log(2.0);
l_i[i]=(int)ceil(p);
}
/*为码字分配内存地址*/
C=(char **)calloc(n,sizeof(char *));
for(i=0;i<n;i++)
{
C[i]=(char *)calloc(l_i[i]+1,sizeof(char));
C[i][0]='\0';
}
/*计算概率累加和*/
P_i[0]=0.0;
for(i=1;i<n;i++)
P_i[i]=P_i[i-1]+p_i[i-1];
/*将概率和转变为二进制编码*/
for(i=0;i<n;i++)
{
for(j=0;j<l_i[i];j++)
{
/*乘2后的整数部分即为这一位的二进制码元*/
P_i[i]=P_i[i]*2;
temp=(int)(P_i[i]);
P_i[i]=P_i[i]-temp;
/*整数部分大于0为1,等于0为0*/
if(temp==0)
C[i]=strcat(C[i],"0");
else
C[i]=strcat(C[i],"1");
}
}
/*显示编码结果*/
fprintf(stdout,"The output coding is :\n");
for(i=0;i<n;i++)
fprintf(stdout,"%s",C[i]);
fprintf(stdout,"\n\n");
/*释放内存空间*/
for(i=n-1;i>=0;i--)
free(C[i]);
free(C);
free(p_i);
free(P_i);
free(l_i);
exit(0);
}
/*冒泡排序法*/
void sort(float *k,int m)
{
int i=1;/*外层循环变量*/
int j=1;/*内层循环变量*/
int finish=0;/*结束标志*/
float temp;/*中间变量*/
while(i<m&&!finish)
{
finish=1;
for(j=0;j<m-i;j++)
{
/*将小的数后移*/
if(k[j]<k[j+1])
{
temp=k[j];
k[j]=k[j+1];
k[j+1]=k[j];
finish=0;
}
i++;
}
}
}
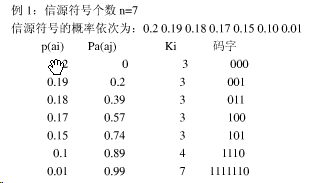
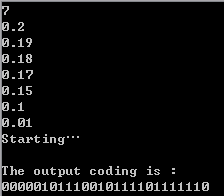
6、调试验证:
程序结果:
7、实验总结
1949年香农在《有噪声时的通信》一文中提出了信道容量的概念和信道编码定理,为信道编码奠定了理论基础。无噪信道编码定理(又称香农第一定理)指出,码字的平均长度只能大于或等于信源的熵。有噪信道编码定理(又称香农第二定理)则是编码存在定理。它指出只要信息传输速率小于信道容量,就存在一类编码,使信息传输的错误概率可以任意小。随着计算技术和数字通信的发展,纠错编码和密码学得到迅速的发展。香农编码定理虽然指出了理想编码器的存在性,但是并没有给出实用码的结构及构造方法,编码理论正是为了解决这一问题而发展起来的科学理论。编码的目的是为了优化通信系统。
香农编码是码符号概率大的用短码表示,概率小的是用长码表示,程序中对概率排序,最后求得的码字就依次与排序后的符号概率对应。
二、哈夫曼编码
1、实验目的和任务
1、 理解信源编码的意义;
2、 熟悉 MATLAB程序设计;
3、 掌握哈夫曼编码的方法及计算机实现;
4、 对给定信源进行香农编码,并计算编码效率;
2、实验原理介绍
1、把信源符号按概率大小顺序排列, 并设法按逆次序分配码字的长度;
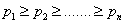
2、在分配码字长度时,首先将出现概率 最小的两个符号的概率相加合成一个概率;
3、把这个合成概率看成是一个新组合符号地概率,重复上述做法直到最后只剩下两个符号概率为止;
4、完成以上概率顺序排列后,再反过来逐步向前进行编码,每一次有二个分支各赋予一个二进制码,可以对概率大的赋为零,概率小的赋为1;
5、从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
3、实验内容和步骤
对如下信源进行哈夫曼编码,并计算编码效率。

(1)计算该信源的信源熵,并对信源概率进行排序
(2)首先将出现概率最小的两个符号的概率相加合成一个概率,把这个合成概率与其他的概率进行组合,得到一个新的概率组合,重复上述做法,直到只剩下两个概率为止。之后再反过来逐步向前进行编码,每一次有两个分支各赋予一个二进制码。对大的概率赋“1”,小的概率赋“0”。
(3)从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
(4)计算码字的平均码长得出最后的编码效率。
4、实验数据记录
>> clear all
>> p=[0.20 0.18 0.15 0.17 0.19 0.10 0.01];
l=0;
H=0;
N=length(p);
for i=1:N
H=H+(-p(i)*log2(p(i)));
end
fprintf('信源信息熵:\n');
disp(H);
for i=1:N-1
for j=i+1:N
if p(i)<p(j)
m=p(j);
p(j)=p(i);
p(i)=m;
end
end
end
for i=1:N-1
c(i,:)=blanks(N*N);
end
c(N-1,N)='0';
c(N-1,2*N)='1';
for i=1:N-1 %对字符数组c码字赋值过程,记下沿路径的“1”和"0";
c(N-i,1:N-1)=c(N-i+1,N*(find(m(N-i+1,:)==1))-(N-2):N*(find(m(N-i+1,:)==1)));
c(N-i,N)='0';
c(N-i,N+1;2*N-1)=c(N-i,1:N-1);
c(N-i,2*N)='1';
for j=1:i-1
c(N-i,(j+1)*N+1:(j+2)*N)=c(N-i+1,N*(find(m(N-i+1,:)==j+1)-1)+1:N*find(m(N-i+1,:)==j+1));
end
end
for i=1:N
h(i,1:N)=c(1,N*(find(m(1,:)==i)-1)+1:find(m(1,:)==i)*N);%码字赋值
ll(i)=length(find(abs(h(i,:))~=32));%各码字码长
end
l=sum(p.*ll);%计算平均码长
n=H/l;%计算编码效率
fprintf('编码的码字:\n');
disp(h)%按照输入顺序从大到小排列后的码字
fprintf('平均码长:\n');
disp(l)%输出平均码长
fprintf('编码效率:\n');
disp(n)%输出编码效率

5、实验心得
由于我们的知识浅薄,经验不足及阅历颇浅,因此,在该程序的设计方面还有很多的不足,会在以后的学习过程中,根据所学的知识不断的修改、完善,争取慢慢趋于完美。