语音信号处理实验指导书
实验一 语音信号采集与简单处理
一、实验目的、要求
(1)掌握语音信号采集的方法
(2)掌握一种语音信号基音周期提取方法
(3)掌握短时过零率计算方法
(4)了解Matlab的编程方法
二、实验原理
基本概念:
(a)短时过零率:
短时内,信号跨越横轴的情况,对于连续信号,观察语音时域波形通过横轴的情况;对于离散信号,相邻的采样值具有不同的代数符号,也就是样点改变符号的次数。
对于语音信号,是宽带非平稳信号,应考察其短时平均过零率。
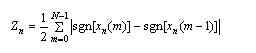
其中sgn[.]为符号函数
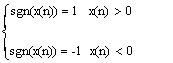
短时平均过零的作用
1.区分清/浊音:
浊音平均过零率低,集中在低频端;
清音平均过零率高,集中在高频端。
2.从背景噪声中找出是否有语音,以及语音的起点。
(b)基音周期
基音是发浊音时声带震动所引起的周期性,而基音周期是指声带震动频率的倒数。基音周期是语音信号的重要的参数之一,它描述语音激励源的一个重要特征,基音周期信息在多个领域有着广泛的应用,如语音识别、说话人识别、语音分析与综合以及低码率语音编码,发音系统疾病诊断、听觉残障者的语音指导等。因为汉语是一种有调语言,基音的变化模式称为声调,它携带着非常重要的具有辨意作用的信息,有区别意义的功能,所以,基音的提取和估计对汉语更是一个十分重要的问题。
由于人的声道的易变性及其声道持征的因人而异,而基音周期的范围又很宽,而同—个人在不同情态下发音的基音周期也不同,加之基音周期还受到单词发音音调的影响,因而基音周期的精确检测实际上是一件比较困难的事情。基音提取的主要困难反映在:①声门激励信号并不是一个完全周期的序列,在语音的头、尾部并不具有声带振动那样的周期性,有些清音和浊音的过渡帧是很难准确地判断是周期性还是非周期性的。②声道共振峰有时会严重影响激励信号的谐波结构,所以,从语音信号中直接取出仅和声带振动有关的激励信号的信息并不容
易。③语音信号本身是准周期性的(即音调是有变化的),而且其波形的峰值点或过零点受共振峰的结构、噪声等的影响。④基音周期变化范围大,从老年男性的50Hz到儿童和女性的450Hz,接近三个倍频程,给基音检测带来了一定的困难。由于这些困难,所以迄今为止尚未找到一个完善的方法可以对于各类人群(包括男、女、儿童及不向语种)、各类应用领域和各种环境条件情况下都能获得满意的检测结果。
尽管基音检测有许多困难,但因为它的重要性,基音的检测提取一直是一个研究的课题,为此提出了各种各样的基音检测算法,如自相关函数(ACF)法、峰值提取算法(PPA)、平均幅度差函数(AMDF)法、并行处理技术、倒谱法、SIFT、谱图法、小波法等等。
三、使用仪器、材料
微机(带声卡)、耳机,话筒。
四、实验步骤
(1)语音信号的采集
利用Windows 语音采集工具采集语音信号,将数据保存wav格式。
采集一组浊音信号和一组清音信号,信号的长度大于3s。
(2)采用短时相关函数计算语音信号浊音基音周期,考虑窗长度对基音周期计算的影响。采用倒谱法求语音信号基音周期。
(3)计算短时过零率,清音和浊音的短时过零率有何区别。
五、实验过程原始记录(数据,图表,计算)
短时过零率
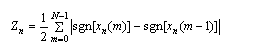
短时相关函数
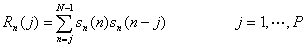
六、实验结果,及分析
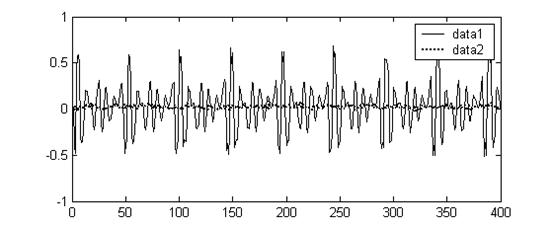
图一 清浊音
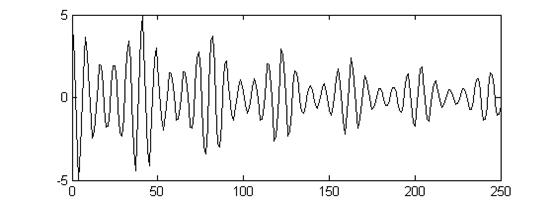
图二 浊音自相关函数
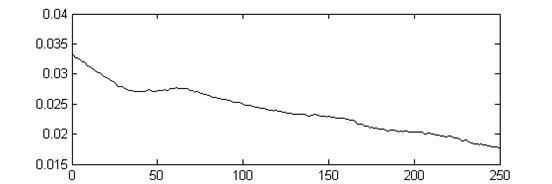
图三 清音自相关函数
实验结果分析:
清音短时过零率高,浊音过零率低。
浊音、清音自相关函数可以看出,浊音存在基音周期,清音不存在基音周期。浊音的基音周期是自相关函数峰值之间的时间差。
七、实验参考程序
1.段时能量
a1=zeros(1,620);K=450;R=zeros(1,250);
duanshnl=0;maxx=0;speech=zeros(1,1000);
sp1=wavread('D:\语音信号处理试验\a.wav');%8000采样频率
maxx=max(sp1);
speech(1:1000)=sp1(1:1000);
duanshnl=speech(1:1000)*speech(1:1000)';
duanshnl=duanshnl/(maxx^2)
plot(sp1(1:400));
hold on
sp=wavread('D:\语音信号处理试验\s.wav');%8000采样频率
speech(1:1000)=sp(1:1000);
qduanshnl=speech(1:1000)*speech(1:1000)';
qduanshnl=qduanshnl/(maxx^2)
plot(sp(1:400),'r')
2 短时过零率
close all
a1=zeros(1,620);K=450;R=zeros(1,250);
duanshnl=0;maxx=0;speech=zeros(1,1000);
sp1=wavread('D:\语音信号处理试验\a.wav');%11000采样频率
sp=wavread('D:\语音信号处理试验\f.wav');%11000采样频率
L=mean(sp);sp=sp-L;L2=mean(sp1);sp1=sp1-L2;
%以下程序计算短时过零率
m1=0;m2=0;
for i=1:2000
if sp1(i)>0
spp1(i)=1;
else
spp1(i)=-1;
end
end
for i=1:2000
if sp(i)>0
spp(i)=1;
else
spp(i)=-1;
end
end
for i=2:2000
m1=m1+0.5*abs(spp1(i)-spp1(i-1));
m2=m2+0.5*abs(spp(i)-spp(i-1)); % m2 >> m1
end
plot(sp1(1:2000),'r');
hold on
plot(sp(1:2000));
3 相关函数法计算基音周期
a1=zeros(1,620);K=450;R=zeros(1,250);
sp=wavread('e:\E\letter\a1.wav');%11000采样频率
for i=1:250
for j=1:601-1-i
R(i)=R(i)+sp(j)*sp(j+i);
end
end
plot(R/14)
hold on
R=zeros(1,250);
sp=wavread('e:\E\letter\f1.wav');%11000采样频率
f1=sp(3300:4000);%11000采样频率
for i=1:250
for j=1:601-1-i
R(i)=R(i)+f1(j)*f1(j+i);
end
end
plot(R/14,'r')
4 倒谱法计算基音周期
close all
a1=zeros(1,620);K=500;
sp=wavread('D:\a1.wav');%11000采样频率
sound=zeros(1,K);speech=zeros(1,K);tt=zeros(1,K);hanning=zeros(1,K);
for number=1:K
hanning(number)=(1/2)*(1-cos((2*pi)*(number-1)/(K-1)));
end
sound=sp(K:2*K-1);
tt=abs(fft(sound(1:K)));
for i=1:K
speech(i)=logm(tt(i));
end
speech=real(ifft(speech));
plot(speech,'g')
hold on
sound=sound.*hanning';
tt=abs(fft(sound(1:K)));
for i=1:K
speech(i)=logm(tt(i));
end
speech=real(ifft(speech));
plot(speech,'r');
sp=wavread('D:\f1.wav');%11000采样频率
f1=sp(3000:4000);%11000采样频率
%f1=sp(K:4000);
sound=f1(K:2*K-1);
tt=abs(fft(sound(1:K)));
for i=1:K
speech(i)=logm(tt(i));
end
speech=real(ifft(speech));
figure
plot(speech,'g')
hold on
sound=sound.*hanning';
tt=abs(fft(sound(1:K)));
for i=1:K
speech(i)=logm(tt(i));
end
speech=real(ifft(speech));
plot(speech,'r');
实验二 语音信号的频域处理
一、实验目的、要求
(1)掌握语音信号频域分析方法
(2)了解语音信号频域的特点
(3)了解谱减法作为频域语音增强的原理与编程实现
(3)了解谱减法的缺点,并分析产生该缺点的原因
二、实验原理
语音虽然是一个时变、非平稳的随机过程。但在短时间内可近似看作是平稳的。因此如果能从带噪语音的短时谱中估计出“纯净”语音的短时谱,即可达到语音增强的目的。由于噪声也是随机过程,因此这种估计只能建立在统计模型基础上。利用人耳感知对语音频谱分量的相位不敏感的特性,这类语音增强算法主要针对短时谱的幅度估计。
短时话幅度估计概述
设一帧加窗后的带噪语音为
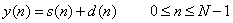 (2.1)
(2.1)
其中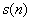 为纯净语音,
为纯净语音, 假设为平稳加性高斯噪声。
假设为平稳加性高斯噪声。
将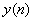 在一组基
在一组基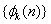 上展开,使展对系数为各不相关的随机变量。设的相关函数为
上展开,使展对系数为各不相关的随机变量。设的相关函数为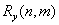 ,由K-L展开得知满足
,由K-L展开得知满足
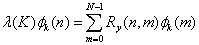 (2.2)
(2.2)
则的展开式为
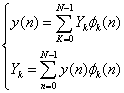 (2.3)
(2.3)
如果的相关长度小于帧长N,则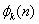 的近似函数为
的近似函数为
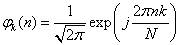 (2.4)
(2.4)
可见的展开过程实际上相当于离散博里叶交换,其展开系数(为傅里叶变换系数。由 ,则有:
,则有: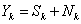 。
。
其中 、
、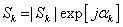 、
、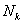 分别为、及的傅里叶交换系数。由于假设噪声是高斯分布的,其傅里叶系数相当于多个高斯样本的加权和,故可认为仍然为高斯分布。其均值为0,方差可通过无语音时对噪声的分析而获得。
分别为、及的傅里叶交换系数。由于假设噪声是高斯分布的,其傅里叶系数相当于多个高斯样本的加权和,故可认为仍然为高斯分布。其均值为0,方差可通过无语音时对噪声的分析而获得。
语音增强的任务就是利用已知的噪声功率谱信息,从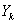 中估计出
中估计出 。由于人耳对相位不敏感,故只需估计出
。由于人耳对相位不敏感,故只需估计出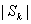 ,然后借用带噪语音的相位,进行傅里叶逆变换就可得到增强的语音。基于短时谱幅度估计的方法的原理图如图2.1所示。
,然后借用带噪语音的相位,进行傅里叶逆变换就可得到增强的语音。基于短时谱幅度估计的方法的原理图如图2.1所示。
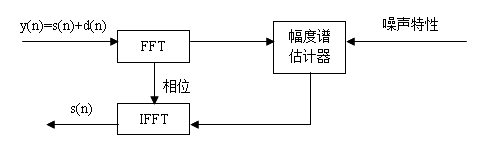

图2.1 短时谱估计原理图
在短时谱幅(STSA)估计基础上,人们提出了许多语音增强算法。基本思想是利用输入带噪语音短时谱幅来估计清洁语音短时谱幅,结合带噪语音相位信息,得到增强信号。
运用短时傅里叶变换(STFT)和重叠相加是短时谱估计技术中最常用的方法。输入信号的短时谱幅 与一个修正因子相乘,得到增强信号谱幅度
与一个修正因子相乘,得到增强信号谱幅度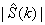 (通常修正因子与噪声信号谱幅估计密切相关);或将含噪语音谱幅减去噪声谱幅估计,得到增强信号谱幅,这些方法统称为相减类型算法(subtractive-type algorithms)。噪声谱幅估计可以通过有声、无声检测获取。一般认为噪声与信号不相关,增强信号谱幅是清洁语音信号的谱幅估计。通常假设人耳对含噪语音相位产生的畸变不敏感,所以进行IDFT恢复成时域信号时,含噪语音的相位一般不作处理。
(通常修正因子与噪声信号谱幅估计密切相关);或将含噪语音谱幅减去噪声谱幅估计,得到增强信号谱幅,这些方法统称为相减类型算法(subtractive-type algorithms)。噪声谱幅估计可以通过有声、无声检测获取。一般认为噪声与信号不相关,增强信号谱幅是清洁语音信号的谱幅估计。通常假设人耳对含噪语音相位产生的畸变不敏感,所以进行IDFT恢复成时域信号时,含噪语音的相位一般不作处理。
三、使用仪器、材料
微机(带声卡)、耳机,话筒。
四、实验步骤
(1) 分析含噪语音信号的频谱(幅度谱和相位谱)
(2) 获取噪声信号频谱(幅度谱)
(3) 对含噪语音信号进行分帧并进行加窗处理
(4) 将含噪语音信号谱和噪声谱作为输入,进行谱减法
(5) 回复增强语音信号帧.
(6) 对比输入信号与增强信号波形,分析算法对其产生的影响.
五、实验过程原始记录(数据,图表,计算)
假设为含噪语音离散时间序列,由清洁语音信号和非相关加性噪声信号组成。可表示为
=+ (2.5)
将输入信号按帧处理,前后帧之间重叠(一般为50%),对每帧含噪语音进行加窗处理,然后进行FFT变换,变换到频率域。含噪语音的能量谱可以表示为
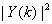
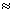
 +
+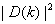 (2.6)
(2.6)
其中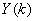 为
为
= =
=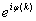 (2.7)
(2.7)
其中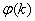 为含噪语音的相位。
为含噪语音的相位。
由于没法直接得到含噪语音中噪声能量谱,一般将无声阶段的数帧噪声信号进行能量谱加权平均得到噪声能量谱估计。假设噪声与语音信号不相关,语音能量谱估计为
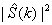 =-
=-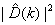 (2.8)
(2.8)
其中清洁语音能量谱估计由含噪语音能量谱减去噪声能量谱估计得到。由于噪声能量谱估计与含噪语音中噪声能量谱之间存在差异,式(3.4)可能出现负值,为了避免能量谱出现负值,将这些负值设为零,这一处理称为半波整流(half-wave rectification)。通过半波整流,清洁语音能量谱估计可表示为
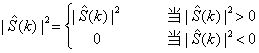 (2.9)
(2.9)
结合含噪语音相位信息,通过逆离散傅里叶变换(IDFT)得到时域清洁语音信号的估计信号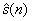 。
。
=IDFT(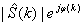 ) (2.10)
) (2.10)
其中增强语音信号频谱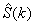 也可以通过时变滤波器
也可以通过时变滤波器 重建
重建
= (2.11)
式中时变滤波器(或称为增益函数)可表示为
 (2.12)
(2.12)
六:实验结果,及分析

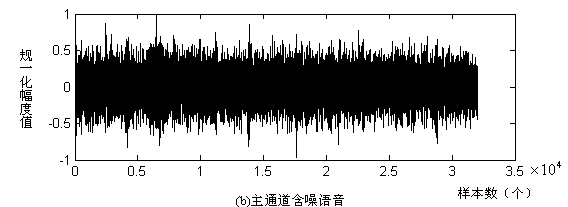

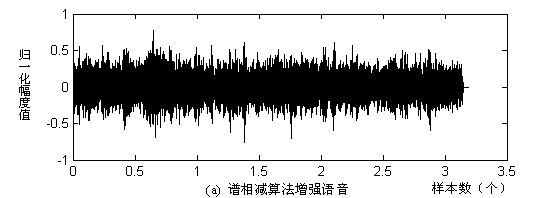

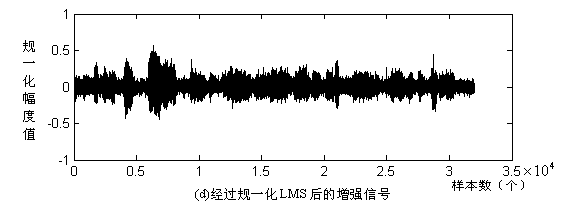

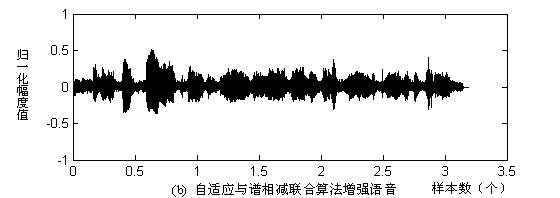
图2.2 谱减法结果分析
实验结果:图2.2中(a),(c)为不同信噪比输入含噪语音信号,图2.2中(b),(d)为对应增强语音信号。当信噪比较低时,降噪效果较差。并且引入音乐噪声。
算法缺陷分析:
(1)不可避免的引入音乐噪声。要有效地滤除含噪语音中的噪声,需要准确地估计含噪语音中噪声的频谱。噪声谱估计越准确,增强信号谱中音乐噪声越小。然而,由于不能直接得到噪声谱,在绝大多数谱相减算法中,通过加权平均无声阶段噪声谱得到噪声谱估计,这种噪声谱估计与含噪语音中的瞬时噪声谱存在差异,噪声平稳性越差,差异越大,由于这种差异的存在,谱相减不可避免地引入音乐噪声。
(2) 半波、全波整流
式(3.4)中负能量值的产生是由于噪声谱估计发生了错误。这些负值用半波整流(被设定为0)或全波整流(被设定为绝对值),这样处理并没有纠正这种错误,可能导致时域信号更进一步的失真。
(3) 用含噪语音的相位作为增强语音的相位
在生成增强时域信号时,含噪语音的相位并没有作任何修改。这是基于这样一个事实,相位的失真对语音质量下降造成的影响不大。当信噪比比较高(>5dB)时,相位失真确实对语音质量的影响不大,然而,当信噪比较低时(<0dB)这种由于相位失真造成的语音质量下降是可以感觉得到的。
七、实验参考程序代码
谱相减原程序代码
hanning=zeros(1,256);
speech=zeros(1,32000);
dd=wavread('D:\语音信号处理实验2\noise.wav');%噪声;
sp=wavread('D:\语音信号处理实验2\speech.wav');%纯语音;
hanning=zeros(1,256);
noise=dd(10000:45000);
speech=sp(25000:60000);
e2=noise+speech;
szeros=zeros(1,32000);
soutput1=zeros(1,32000);
j=sqrt(-1);
a=3,b=0.01;
Snoise=zeros(1,256);
phase=zeros(1,256);
for n=1:256
hanning(n)=(1/2)*(1-cos((2*pi)*(n-1)/255));
end
% to get noise spectral
Noise=zeros(1,256);Noise1=zeros(1,256);
for i=1:3
Noise1(1:256)=abs(fft(e2(1+i*256:256*(i+1)).*hanning'));
Noise=Noise+Noise1/3;
end
% spectral subtraction algrithm
for i=1:245 %%第i帧
snoise=e2((i-1)*128+1:(i-1)*128+256).*hanning';
phase=angle(fft(snoise)); % to get noisy signal spectral phase
Snoise=abs(fft(snoise)); % to get noisy signal spectral amplitude
for n=1:256
if(Snoise(n)^2-Noise(n)^2)<0 %the power of enhanced speech must be positive
Sout0(n)=0.1*Snoise(n);
else
Sout0(n)=(Snoise(n)^2-(Noise(n)*1.5)^2)^0.5; %power type spectral subtraction
end
S0(n)=Sout0(n)*(cos(phase(n))+j*sin(phase(n))); % to get enhanced speech spectral amplitude
end
sout0=ifft(S0);
szeros(((i-1)*128+1):((i-1)*128+256))=real(sout0);
soutput1=soutput1+szeros;
szeros=zeros(1,32000);
end
%the following is for SNR calculation
sp_energe=zeros(1,256);sn_energe=zeros(1,256);SN=zeros(1,256);
in_SNR1=zeros(1,125);out_SNR1=zeros(1,125);snoise=zeros(1,256);
for i=1:240
snoise=speech((i-1)*128+1:(i-1)*128+256).*hanning';%第i帧清洁语音存放到snoise
SN=noise((i-1)*128+1:(i-1)*128+256).*hanning'; %第i帧清洁语音存放到SN
%in_SNR1(i)
sp_energe(i)=snoise(1:256)'*snoise(1:256);%第i帧清洁语音snoise的能量存放到sp_energe(i)
sn_energe(i)=SN(1:256)'*SN(1:256);%第i帧皂声SN的能量存放到sn_energe(i)
in_SNR1(i)=10*log10(sp_energe(i)/sn_energe(i));%第i帧含噪语音信号输入信噪比in_SNR1(i)
SN=soutput1((i-1)*128+1:(i-1)*128+256).*hanning; %第i帧输出信号存放SN
sn_energe1(i)=SN(1:256)*SN(1:256)';%第i帧输出信号SN能量
out_SNR1(i)=10*log10(sp_energe(i)/abs(sn_energe1(i)-sp_energe(i)));%第i帧增强信号输出信噪比
end
plot(e2);
hold on
plot(soutput1,'r');
plot(speech,'g');
figure
plot(in_SNR1)
hold on
plot(out_SNR1,'r')
figure
plot(hanning);
%sound(speech);
%sound(e2);
sound(soutput1);
实验三 语音信号进行倒谱分析
一、实验目的、要求
1. 理解倒谱分析的作用
2. 掌握倒谱分析求基音周期的方法
3. 了解LPC倒谱分析方法
二、实验原理
1.倒谱分析原理
同态信号处理也称为同态滤波,实现将卷积关系变换为求和关系的分离处理,即解卷。
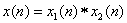 如
如
进行如下3步处理
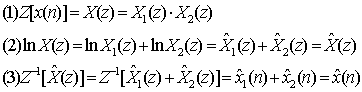
对于语音信号进行解卷,可将语音信号的声门激励信息及声道响应信息分离开来,从而求得声道共振特征和基音周期,用于语音编码、合成和识别。
同态信号处理的基本原理
(1)第一个子系统D*[](特征系统)完成将卷积信号转化为加性信号的运算。

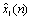 和
和 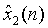 信号也均是时域序列,但它们所处的离散时域显然不同于x(n)所处的离散时域,故把它称之为复倒频谱域。
信号也均是时域序列,但它们所处的离散时域显然不同于x(n)所处的离散时域,故把它称之为复倒频谱域。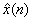 是x(n)的复倒频谱,简称为复倒谱,有时也称为对数复倒谱。复倒谱具体计算公式
是x(n)的复倒频谱,简称为复倒谱,有时也称为对数复倒谱。复倒谱具体计算公式
其中倒谱计算公式为:
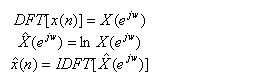
2 线性预测原理
线性预测分析的基本思想
由于语音样点之间存在相关性,所以可以用过去的样点值来预测现在或未来的样点值。通过使实际语音抽样和线性预测抽样之间的误差在某个准则下达到最小值来决定唯一的一组预测系数,而这组系数就能反映语音信号的特性,可以作为语音信号特征参数来用于语音编码、语音合成和语音识别等应用中去。
线性预测分析的基本原理
每个采样值由前面的p个采样值线性组合所构成。记为x¢(n),有:
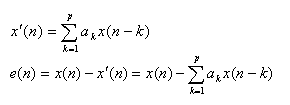
要提高预测精度,就是要预测系数{ }的取值使e(n)最小。理论上通常采用均方误差E[e2(n)]最小的准则。
}的取值使e(n)最小。理论上通常采用均方误差E[e2(n)]最小的准则。
根据e(n)均方误差最小的原则来求解,有三种方法:自相关法(Levinson-Durbin算法)、协方差法和格型合成滤波算法。
自相关法,就是先解出Yule-Walker 方程,再计算G。Levinson-Durbin算法是自相关算法中的一种,形成递推算法。
三、使用仪器、材料
微机(带声卡)、耳机,话筒。
四、实验步骤
(1)采集语音(浊音,轻音)信号
(2)分帧计算语音信号倒谱
(3)倒谱作FFT并加短时窗,取大于25以上的样值,进行IFFT,得到基音周期的倒谱。
(3)运用Levinson-Durbin计算一帧语音信号线形预测系数
(4)对该帧语音信号进行逆滤波处理
(5)对逆滤波后的信号进行倒谱分析确定基音周期
五、实验过程原始记录(数据,图表,计算)
1.倒谱计算公式为:
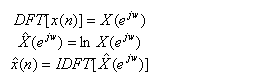
2.线形预测系数计算公式为:
1)
2) 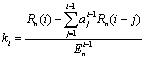
3) 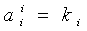
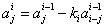 4)
4)
5) 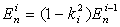
if i<p go to 1)
6) 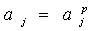
1£j£p
LPC倒谱流程如下
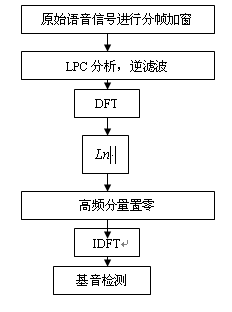
六:实验结果,及分析
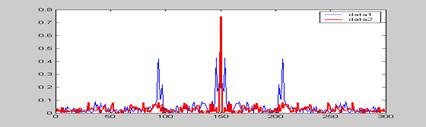
倒谱分析
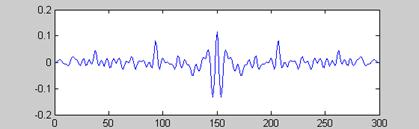
LPC倒谱分析波形图
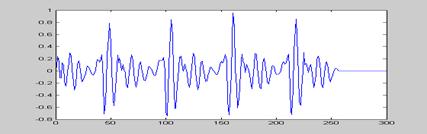
逆滤波后波形图
分析
倒谱分析可以观察倒浊音的基音周期。相邻两个峰值之间的距离为基音周期。
七、实验参考程序
N=256;R=zeros(1,N);
p=12;a=zeros(p,p);En=zeros(1,p);
K=zeros(1,p);
sp=wavread('D:\语音信号处理试验\a1.wav');%11000采样频率
qq=max(sp);
sp=sp-qq;
%相关函数
for j=1:p
for n=j:N-1
R(j)=R(j)+sp(n)*sp(n-j+1);
end
end
% (Levinson-Durbin算法)预测系数
完成程序部分
% 逆滤波
for k=1:256
if k<p
for m=1:k
mm1(k)=mm1(k)+mm(p-k+m)*source(m);
end
else
if k<256
for m=1:p
mm1(k)=mm1(k)+mm(m)*source(m+k-p);
end
else
for m=k-p+1:256
mm1(k)=mm1(k)+mm(m-k+p)*source(m);
end
end
end
end
DFTmm=abs(fft(mm1));
Ln=zeros(1,300);
%取对数,高频风量置零
for i=1:60
Ln(i)=logm(DFTmm(i));
end
% IDFT
ifftLn=real(ifft(Ln));
mm=ifftLn;
for i=1:150
daopu1(i)=mm(151-i);
end
for i=1:150
daopu1(150+i)=mm(301-i);
end
plot(daopu1)
实验四 语音信号的数字回声处理
一、实验目的
1、掌握SEED-DTK-VPM642实验箱的使用;
2、掌握CCS的使用;
3、大致了解DSP/BIOS操作系统,以及SIO/DIO流模型;
4、掌握数字语音信号的回声编程处理。
二、实验内容
本次实验主要利用SEED-DTK-VPM642实验箱,使用TI公司的TMS320DM642DSP芯片为核心处理器,利用AIC23语音芯片实现语音数据的采集与回放。本次实验软件架构以TI公司的DSP/BIOS操作系统为基础,使用SIO/DIO流模型,实现语音信号的数字回声处理。
三、实验过程
首先正确连好实验箱,并且设置好CCS软件。另外,输入信号从实验箱面板上方的模拟接口的Ain0输入,从耳机J3接口输出,编写程序,编译链接,下载调试。
四、实验目的以及要求
完成数字语音信号回声处理的编程和下载调试等,对经过不同的延迟参数处理之后的不同回声效果进行分析比较。
五、 实验报告要求
简要描述数字语音回声处理过程,能够通过编程实现回声处理,得到最终的实验结果。
根据实验结果分析性能。