中南林业科技大学
课程论文
院 系 理学院
专 业 信息与计算科学
课程名称 数据挖掘
论文题目 面向社会网络分析的数据挖掘方法
姓 名 王磊
学 号 20104255
指导教师 孙玉荣
20##年 10月
面向社会网络分析的数据挖掘方法
摘 要
随着信息技术的发展,越来越多的社会关系数据被收集。如果能够有效地对它们进行分析,必将加深人们对社会学的理解,促进社会学的发展。但是数据量的增大同时对分析技术提出了巨大的挑战。如今社会网络的规模早已超出了原有分析手段的处理能力,必须借助更为有效的工具才能完成分析任务。数据挖掘作为一种帮助人们从海量数据中发现潜在有用的知识的工具,在很多领域发挥了重要的作用。社会网络分析又称为链接挖掘,是指用数据挖掘的方法处理社会网络中的关系数据。本文对数据挖掘和社会网络分析中的一些方法进行了介绍并对数据挖掘算法在社会网络分析的应用进行了概括。
关键词:设会网络分析;数据挖掘;链接挖掘
1.引言
传统的机器学习处理的社会学中的对象是单独的数据实例,这些数据实例往往可以用一个包含多个属性值的向量来表示,同时这些数据实例之间假设是统计上独立的。例如要训练一个疾病诊断系统,它的任务是诊断一个被试者是否患有某种传染病。传统的学习算法用一个向量来表示一个被试者,同时假设两个被试者之间的患病情况是相互独立的,即知道一个确诊病人对于诊断其他被试者是否患病不能提供任何帮助。直观经验告诉我们这种假设是不合理的。直到二十世纪 30 年代,Jacob Moreno 和哈佛大学的一组研究人员分别提出了社会网络模型来分析社会学中的现象和问题。现代社会学主要研究现代社会的发展和社会中的组织性或者团体性行为。社会学家发现社会实体之间存在着相互的依赖和联系,并且这种联系对于每个社会实体有着重要的影响。基于这样的观察,他们通过网络模型来刻画社会实体之间的关系,并进一步用来分析社会关系之间的模式和隐含规律。为了更好的研究这个问题,他们试图用图结构来刻画这种社会网络结构。一个社会网络由很多节点(node)和连接这些节点的一种或多种特定的链接(link)所组成。节点往往表示了个人或团体,也即传统数据挖掘中的数据实例,链接则表示了他们之间存在的各种关系(relation),如朋友关系、亲属关系、贸易关系、性关系等。
由于数据收集方式的限制,早期的社会网络局限于一个小的团体之内,往往仅包含几十个结点。借助于图论和概率统计的知识,人工处理可以从中分析出一些简单的性质和模式。但是,随着现代的通信技术的发展,越来越多的数据被收集和整合在一起,建立一个大的社会网络成为可能。例如,可以通过电子邮件的日志来建立使用者之间的联系网络,或者通过网络日志及网络通讯录等方式将用户提交的联系人信息建立社会网络。所以,现在的社会网络规模比早期网络庞大,通常包含几千或者几万的结点,甚至有多达百万个结点的网络。面对这样庞大复杂的网络,简单的数学知识和原始的人工处理已经不可能进行有效的分析。数据挖掘是从巨量数据中发现有效的、新颖的、潜在有用的并且最终可理解的模式的非平凡过程。数据挖掘就是为了解决当今拥有大量数据,但缺乏有效分析手段的困境而出现的研究领域。目前,已经在包括生物信息学,自然语言处理等许多方面发挥了巨大的作用。
与传统的数据挖掘只关注数据实例不同,社会网络分析对链接同样关注。从数据挖掘角度,社会网络分析又称为链接挖掘(link mining)。通过对链接的挖掘我们可以获得关于实例更丰富(如某个实例在整个网络中的重要性)、更准确(如预测某个实例所属的类别)的关系数据(relational data)。
社会网络分析是关系数据挖掘的主要应用。关系数据挖掘的发展为社会网络分析提供了更有力的工具,促进了社会网络分析的发展。本文分析了社会网络分析数据的方法以及任务和需求,介绍了几类适于社会网络分析的数据挖掘算法。
2.社会网络和数据挖掘方法介绍
2.1社会网络分析方法
社会网络分析是一套用来分析多个个体通过相互联系构成的网络的结构,性质以及其他用于描述这个网络的属性的分析方法的集合。如社会网络分析方法提供了根据网络中节点的联系紧密情况将网络分层的方法,网络中节点相互作用模式识别,将网络分块,给用户评级,信息扩散,对社会网络提供图形描述,中心度的分布等。下面我们介绍社会网络分析最重要的两个模型,用户——用户网络模型和用户——事件网络模型
2.2数据挖掘方法
数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。与数据挖掘相近的同义词有数据库中的知识发现(KDD Knowledge Discovery in Database)、数据分析、数据融合以及决策支持等。这个定义包括好几层含义:数据源必须是真实的、大量的、含噪声的;发现的是用户感兴趣的知识;发现的知识要可接受、可理解、可运用;并不要求发现放之四海皆准的知识,仅支持特定的发现问题。即所有发现的知识都是相对的,是有特定前提和约束条件,面向特定领域的,同时还要能够易于被用户理解。最好能用自然语言表达所发现的结果。数据挖掘的任务是从数据中发现模式。模式有很多种,按功能可分为两大类:预测型模式和描述型模式。第一种是预测型模式,即可以根据数据项的值精确确定某种结果的模式。挖掘预测型模式所使用的数据也都是可以明确知道结果的。第二种是描述型模式,即对数据中存在的规则做一种描述,或者根据数据的相似性把数据分组。描述型模式不能直接用于预测。数据挖掘涉及多学科技术的集成,包括数据库技术、统计学、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像于信息处理和空间数据分析[1]。这里主要介绍关联规则分析和聚类分析。
2.2.1关联规则分析
在Jiawei Han的《数据挖掘概念与技术》中将关联规则的定义如下:设I={I1,I2,…,Im} 是项的集合。设任务相关的数据D是数据库事务的集合,其中每个事物T是项的集合,使得T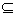 I。每一个事务有一个标识符,称作TID。设A是一个项集,事务T包含A当且仅当AT。关联规则是形如A
I。每一个事务有一个标识符,称作TID。设A是一个项集,事务T包含A当且仅当AT。关联规则是形如A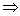 B的蕴涵式,其中A
B的蕴涵式,其中A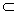 I,BI,并且A
I,BI,并且A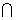 B=Ø。规则AB在事务D中成立,具有支持度s,其中s是D中事务包含A
B=Ø。规则AB在事务D中成立,具有支持度s,其中s是D中事务包含A B(即集合A与B的并或A和B二者)的百分比。它是概率P(AB)。规则AB在事务D中具有置信度c,其中c是D中包含A的事务同时包含B的百分比这是条件概率P(B
B(即集合A与B的并或A和B二者)的百分比。它是概率P(AB)。规则AB在事务D中具有置信度c,其中c是D中包含A的事务同时包含B的百分比这是条件概率P(B A)[5]。即
A)[5]。即
Support(AB)=P(AB)
Confidence(AB)= P(BA)
同时满足最小支持度阈值和最小置信度阈值的规则称为强关联规则。也说这样的关联规则是有趣的。
一般来说关联规则的挖掘可以看成两步的过程:
找出所有的频繁项集:根据定义,这些项集的每一个出现的频繁性至少与预定义的最小支持计数一样。
由频繁项集产生的强关联规则:根据定义,这些规则必须满足最小支持度和最小置信度。
关联规则的主要算法有Apriori算法
Apriori算法是一种以概率为基础的具有影响的挖掘布尔型关联规则频繁项集的算法。其利用循序渐进的方式,找出数据库中项目的关系,以形成规则。其过程分为两步:一为连接(类矩阵运算),二为剪枝(去掉那些没必要的中间结果)。在此算法中常出现项集的概念。项集 (itemset)简单地说就是项的集合。包含K个项的集合为k项集。项集的出现频率是包含项集的事务数,称为项集的频率。如果项集满足最小支持度,则称它为频繁项集。频繁k项集的集合计作LK.
2.2.2聚类分析
聚类分析将数据划分成有意义或有用的组。聚类分析仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组。其目标是,组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。组内的相似性越大,组间差别越大,聚类就越好。
聚类的方法通常有 K 均值算法,凝聚层次聚类,DBSCAN。
K 均值是基于原型的,划分的聚类技术。它试图发现用户指定个数(K)的簇。
3.数据挖掘在社会网络分析中的应用
在2.2中已经说过,数据挖掘任务可分为描述型(descriptive)任务和预测型(predictive)任务两类:描述型数据挖掘任务试图刻画和归纳数据库中数据的总体特性;而预测型数据挖掘任务则试图根据以往数据中包含的经验,预测新的条件下发生的事件。社会网络分析的任务也不过这两种,一类从社会网络中发现社会的特性,另一类利用已经建好的网络模型,对某些情况进行预测。对于这两类任务,传统的数据挖掘算法已经有许多方法,关系数据挖掘的方法中既有从 ILP 中发展而来的算法,也有通过将原有算法改进后形成的算法。特别是关于连接挖掘(Link Mining)的算法能够很好地解决社会网络分析的任务。
下面简单介绍几类适用于社会网络分析的数据挖掘算法:
3.1基于相似度度量方法
数据挖掘中的许多方法基于相似度度量,例如 k-近邻算法和一些聚类算法,以及在一些排序任务之中给出一个评价准则。相似度的定义是这类算法中的核心步骤。相似度的定义是和问题相关的,同一个的数据集在不同的任务下最佳的相似度的定义很有可能是不同的。很多的时候很难选取一个适合的相似度度量,尤其当属性数目多,并且和目标任务的关系不明确的时候。但是,如果能够给出合适的相似度度量,这类算法具有很好的直观解释。
相似性度量在联系预测中应用
联系预测是判断两个行动者之间是否存在某种联系。在社会网络 G 中,相似度度量函数对于每个结点对<x, y>给出一个存在联系的可能性 score(x, y)。在有些应用中,该函数可以看作是根据网络 G 的拓扑结构,对每个结点 x 和 y 计算了他们之间的相似程度。而在有些社会网络分析任务中,这个权重并非是计算结点间的相似程度,而是为了特别的目标进行适当的修改。这些权重有的基于结点的临近结点(node neighborhoods),有的基于所有路径的集成(Ensemble of all paths)。
3.2基于统计的方法
现阶段统计关系学习方面的主要针对于在关系数据中的学习概率模型带来的挑战的研究。特别地,我们经常要进行研究究竟关系数据特征如何影响由精确学习所带来的统计推断,研究者们我们提出集中连接度(concentrated linkage),程度差异(degree disparity),关系自相关(relational autocorrelation)三方面的特征,并且从这三方面来探讨他们如何在学习算法中产生的病态行为[1]。
为了更加充分解释这一研究,关系数据特征如下:
集中连接度(concentrated linkage)—真正的关系数据集能够表示连接度在不同类型的对象中的显著非一致性。在不同的情形下在关系数据集中有着不同的集中连接度,比如在电影中就会有许多电影连接许多的演员,如图3.1左。但是在上市公司中每个上市公司只可能连接到极少数的会计事务所,如3.1右。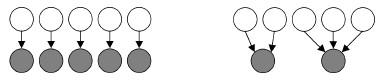
低连接度 高连接度
图3.1集中连接度
程度差异(degree disparity)— 另一个关系数据集的特性便是程度差异。这一特性的产生往往是不同类的对象有交大的差异程度。图3.2直观的显示了程度差异。在不同的数据集中均发现了相似的程度差异。例如在不同行业中贸易公司的法人数量差异和大学网站中不同类型网页中的超连接数量的不同。

无程度差异 高程度差异
图3.2 程度差异
关系自相关(relational autocorrelation)— 自相关是在不同关联对象中相同属性的价值相关性。例如,在时间t+1的属性值对于在时间t的该属性值就具有很高的相关性。类似,我们定义了关系自相关来描述在邻近表中的变量值的相关性。例如票房收入与导演关系紧密(关联系数为0.65),但与演员关系较小(关联系数为0.17)。图3.3直观的显示了关系相关性。

低相关性 高相关性
图3.3 关系相关性
关系数据的这三个特征使得建立出优秀的统计模型需要考虑更多的方面。
统计关系学习(Statistical Relational Learning)是将统计的方法和数据的关系表示结合起来的一类算法,它关注数据的联合概率分布。统计关系学习发展很快,很多模型被提出,主要有 PRM(Probabilistic Relational Models), RMN(Relational Markov Networks), SLR(Structural Logic Regression), RDM(Relational Dependency Networks), MLN(Markov Logic Networks)。这些统计关系学习的模型就是针对关系数据建立的,因而可以很好地描述社会网络,进而完成所需的分析任务。基于统计的算法往往因为需要优化的参数较多,计算开销相对较大。
MLN(Markov Logic Networks)[3]
Richardson 和 Domingos 希望通过 MLN 将概率和以及逻辑整合在同一个表示之中。因为概率模型能够很好处理不确定性,而逻辑表示能够简洁地表示知识。MLN 将马尔可夫网和一阶逻辑结合起来。
马尔可夫网描述了一组随机变量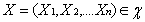 的联合概率分布。通常,采用log-linear 模型表示为:
的联合概率分布。通常,采用log-linear 模型表示为:

其中,Z 是规范化项,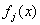 是状态x的特征属性,(即定义域为
是状态x的特征属性,(即定义域为 的函数)。
的函数)。
马尔可夫逻辑中的一个公式由一个一阶逻辑公式及相应的权重组成。一组马尔可夫逻辑公式所做成的集合就被称为马尔可夫逻辑网络,它定义了所有可能的变元取值组合的概率分布。下面给出它的形式化定义:
一个马尔可夫逻辑网络 L 是一组二元组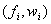 ,其中
,其中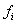 是一个一阶逻辑公式,
是一个一阶逻辑公式,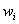 是一个实数值。它同一个有限的常量集合
是一个实数值。它同一个有限的常量集合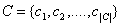 通过下面的两条准则共同定义了一个马尔可夫网
通过下面的两条准则共同定义了一个马尔可夫网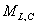 :
:
1. L 中出现的所有谓词的每个可能的取值对应于中的一个二值结点。结点值为 1 表示其对应的谓词取真。
2. L 中的每一个公式 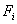 的每一种取值对应应于中的一个特征属性。该特征属性取 1 表示其对应的公式值为真。该特征属性的权重就是 L中所对应的。
的每一种取值对应应于中的一个特征属性。该特征属性取 1 表示其对应的公式值为真。该特征属性的权重就是 L中所对应的。
有些社会网络模型可以看作是一个马尔可夫网络,而且可以简单地用类似
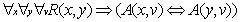
的语句来表示,其中 x,y 表示行动者,R(x, y)表示它们之间的关系,A(x, v)表示 x 的一个属性,语句的权重表示了结点间的关系和该属性相似性之间的关联程度。例如,一个表达朋友之间倾向于有相同的吸烟习惯就可以简单地表达为

3.3基于频繁模式挖掘的方法
频繁项集,即在数据集中出现频率超过每个预定的值的模式,能够在一定程度上反应数据集的特性。挖掘频繁项集是关联规则挖掘中的重要步骤,找到社会网络中的频繁子图也是社会网络分析中的重要任务。
Apriori是频繁项集挖掘中一种非常有影响的算法。它得名于算法使用了关于频繁项集性质的先验知识。Apriori 采用了层次式搜索的迭代方法,利用频繁 k-项集来生成频繁(k+1)-项集。首先,从数据库中找到频繁 1-项集,记作 L1,以此类推见2.2.1介绍。
AGM(Apriori-based Graph Mining)算法就是使用邻接矩阵作为图的表示,先生成候选项,然后剪除其中非频繁子图的方法来有效地在图结构的数据中挖掘出频繁出现的子结构[2]。
4.总结
社会网络分析由于不满足数据的独立同分布假设,因而给数据挖掘的研究提出了新的挑战,并产生了一个新的方向:链接挖掘。近来在数据挖掘和机器学习领域针对关系数据模型的准确性研究取得了很大进步。但是这些研究对于其他学科应用并不广泛。致力于针对交叉学科的有效算法和数据表示依然有待发展。
Han
随着现代的通信技术的发展越来越多的社会网络数据的被整理到一起,这样既给该领域带了前所未有的机会,也同时对数据分析技术提出了巨大的挑战。数据挖掘作为一种帮助人们从大量数据中发现有用的知识的工具,经过不断地发展,已经能够处理像社会网络这种结构化的网络数据,并在社会网络构建过程中发挥越来越重要的作用。同时,社会网络分析也可以有助于完成一些其它数据挖掘应用。加强在不同领域之间应用的交流,对数据挖掘和各个领域的发展都十分有利。
参考文献
[1]D.Jensen, J.Neville, Data mining in social networks, In the National Academy of Sciences Workshop on Dynamic Social Network Modeling and Analysis, 2003.
[2]Inokuchi A, Washio T., Motoda H., An apriori-based algorithm for mining frequent substructures from graph data.In Proceedings of the 4th European Conference on Principles of Data Mining and Knowledge Discovery, Lyon, France, 2000, 13-23.
[3] 眭俊明, 数据挖掘在社会网络分析中的应用概述[J], Assignment of Data Mining Course.
[4] 张引, 社会网络分析中的数据挖掘综述[J].
[5] JW.Han, M.Kamber, 数据挖掘概念与技术[M],机械工业出版社 范明 孟小峰 译.
[6] 林聚任, 社会网络分析:理论,方法与应用[M],北京师范大学出版集团.
[7] 艾伯特·拉斯洛·巴拉巴西,链接网络新科学[M],湖南科学技术出版社.