哈夫曼树实验报告
一、需求分析
(1)输入输出形式
输入数组的组数n:整形变量组数(回车)
请依次输入n组权值与字符,中间用空格隔开。如“2 a”:按右提示格式输入(回车)
请输入待编译文本:随机输入字符(回车)
输出:编译出的代码
请输入待编译代码:随机输入一串代码(回车)
输出:编译出的代码
(2)程序功能
1.用C语言实现二叉树的说明
2.输入n个权值,并生成n个二叉树
3.对n个二叉树逐步生成Huffman树
4.对Huffman树的每个叶子结点生成编码
5. 用哈夫曼树编码。
6. 解码哈夫曼编码。
(3)测试用例设计
Example1:输入3
25 a
15 b
60 c
abbacc
0100000111
输出 0100000111
abbacc
Example2:输入 5
10 a
20 b
30 c
20 d
10 e
ababcde
10000100001101101
输出 10000100001101101
ababcde
二、概要设计
1.根据给定的n个权值(w1, w2, …, wn)构成n棵二叉树的集合F={T1, T2, …, Tn},其中每棵二叉树Ti中只有一个带树为Ti的根结点
2.在F中选取两棵根结点的权值最小的树作为左右子树构造一棵新的二叉树,且置其根结点的权值为其左右子树权值之和
3.在F中删除这两棵树,同时将新得到的二叉树加入F中
4.重复2, 3,直到F只含一棵树为止
5.将给定的字符串通过程序编码成哈夫曼编码,并打印结果在屏幕上。
6.翻译给定的哈夫曼编码变成可读字符串,并将结果打印在屏幕上。
三、详细设计

四、调试分析
(1)编译代码、运行代码所遇到的问题及其解决办法
问题1:编译代码过程中有遇到循环体的循环次数不对,导致二叉树生成得不对
解决办法:通过小数字的演算,检验循环,再进行更改
(2)算法的时空分析
(3)心得体会
五、用户使用说明
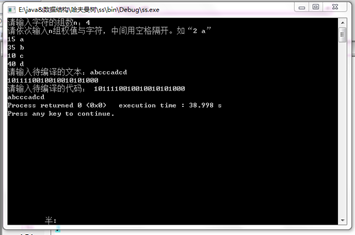
如上图所示,依次输入组数、权值及全值所对应字符。再根据用户自身需求输入需编译的文本及代码。
六、测试结果
Example1
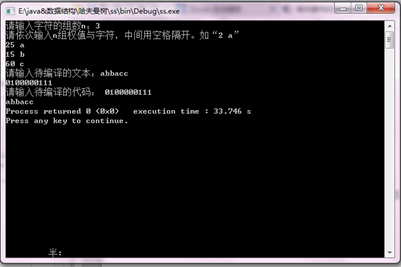
Example2

七、附录
#include <iostream>
#include <stdio.h>
#include <string.h>
using namespace std;
struct Node
{
int weight,parent,lchild,rchild;
char ch;
} HT[1000];
struct node
{
int len;
char co[1000];
} code[1000];
int s1,s2,n,m;
char text[1000];
int Select(int end)
{
s1=1000;
s2=1000;
for(int i=1;i<=end;i++)
{
if(HT[s1].weight>HT[i].weight&&HT[i].parent==0)
{
s1=i;
}
}
for(int i=1;i<=end;i++)
{
if(i!=s1&&HT[i].parent==0)
if(HT[s2].weight>HT[i].weight)s2=i;
}
return 0;
}
int Initialization()
{
printf("请输入字符的组数n:");
cin>>n;
printf("请依次输入n组权值与字符,中间用空格隔开。如“2 a”\n");
for(int i=1;i<=n;i++)
{
cin>>HT[i].weight;
getchar();
HT[i].ch=getchar();
HT[i].lchild=-1;
HT[i].rchild=-1;
HT[i].parent=0;
}
m=2*n-1;
for(int i=n+1;i<=m;i++)
{
Select(i-1);
HT[s1].parent=i;
HT[s2].parent=i;
HT[i].lchild=s1;
HT[i].rchild=s2;
HT[i].weight=HT[s1].weight+HT[s2].weight;
}
return 0;
}
int BuildCode()
{
int key,i=1;
while(i<=n)
{
key=i;
code[i].len=0;
while(key!=m)
{
Node mother=HT[HT[key].parent];
if(mother.lchild==key)
{
code[i].co[code[i].len++]='0';
}
else if(mother.rchild==key)
{
code[i].co[code[i].len++]='1';
}
key=HT[key].parent;
}
code[i].len=strlen(code[i].co);
for(int j=0;j<code[i].len/2;j++)
{
char m;
m=code[i].co[j];
code[i].co[j]=code[i].co[code[i].len-j-1];
code[i].co[code[i].len-j-1]=m;
}
i++;
}
}
int Encoding()
{
printf("请输入待编译的文本:");
getchar();
gets(text);
int l=strlen(text);
for(int i=0;i<l;i++)
{
int cha=text[i];
for(int j=1;j<=n;j++)
{
if(cha==HT[j].ch)
cout<<code[j].co;
}
}
cout<<endl;
}
int Decoding()
{
char codes[1000];
int len;
cout<<"请输入待编译的代码: ";
scanf("%s",codes);
len=strlen(codes);
int flag=m,point=0;
while(point<len)
{
if(codes[point]=='0')
{
flag=HT[flag].lchild;
point++;
}
else if(codes[point]=='1')
{
flag=HT[flag].rchild;
point++;
}
if(HT[flag].lchild==-1&&HT[flag].rchild==-1)
{
printf("%c",HT[flag].ch);
flag=m;
}
}
}
int main()
{
HT[1000].weight=1000000;
Initialization();
BuildCode();
Encoding();
Decoding();
return 0;
}
第二篇:数据结构-哈夫曼树实验报告(包含文件压缩)
北京邮电大学信息与通信工程学院
2008级数据结构实验报告
实验名称: 实验三——实现哈夫曼树
学生姓名: ***
班 级: **********
班内序号: **
学 号: ********
日 期: 20xx年11月14日
1.实验要求
利用二叉树结构实现赫夫曼编/解码器。
基本要求:
1、 初始化(Init):能够对输入的任意长度的字符串s进行统计,统计每个字符的
频度,并建立赫夫曼树
2、 建立编码表(CreateTable):利用已经建好的赫夫曼树进行编码,并将每个字符
的编码输出。
3、 编码(Encoding):根据编码表对输入的字符串进行编码,并将编码后的字符串
输出。
4、 译码(Decoding):利用已经建好的赫夫曼树对编码后的字符串进行译码,并输
出译码结果。
5、 打印(Print):以直观的方式打印赫夫曼树(选作)
6、 计算输入的字符串编码前和编码后的长度,并进行分析,讨论赫夫曼编码的压
缩效果。
测试数据:
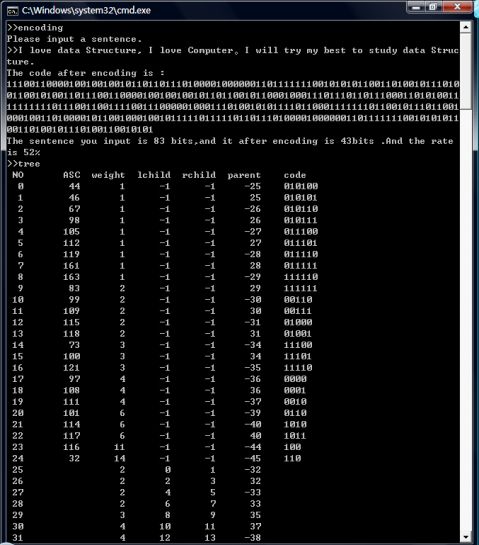
I love data Structure, I love Computer。I will try my best to study data Structure.
提示:
1、用户界面可以设计为“菜单”方式:能够进行交互。
2、根据输入的字符串中每个字符出现的次数统计频度,对没有出现的
字符一律不用编码。
2. 程序分析
2.1 存储结构
在哈夫曼树编码这个程序中,所有数据用的存储结构都是顺序存储结构,其中包括顺序表和树(三叉树)。
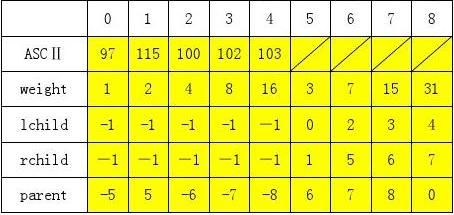
树的存储结构如下:(输入的字符串为 assddddffffffffgggggggggggggggg)
第1页
北京邮电大学信息与通信工程学院
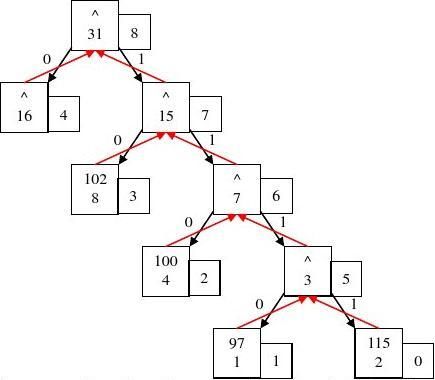
上结构图中,填充为黄色的部分为写入内存中的部分。每一行的部分为数组的下标,左边部分为所定义的结构的成员。其中有的结点的父节点的下标是一个负数,用来说明该节点是该节点的父节点的左孩子,正数说明的是该节点的父节点的右孩子。父节点这零的节点说明该节点是该哈夫曼树的根节点。画出树的结构如下画所示:(结点中第一个数表示这个字符的ASCⅡ编码,第二个数字表示权值)
红色箭头表示父指针,黑色箭头表示孩子指针
由上面的图可知,原字符串编码后的二进制编码为
11xxxxxxxxxxxx11xxxxxxxxxxxx10101010100000000000000000 字符串中出现的所有的字符的编码如下:
a 1110 ; s 1111 ; d 110 ; f 10 ; g 0
第2页
北京邮电大学信息与通信工程学院
2.2 关键算法分析
算法1:哈夫曼树的构造
这个算法分两个部分,每一个部分是对一个字符串中每个字符出现次数的统计,并为每一个出现的字符建立一个叶子节点;第二个部分是以上面的统计的数据为依据建立起一棵哈夫曼树。
问题的规模由两部分组成,一是字符串中总的字符的个数m,二是这个字符串中出现的所有的不同的字符的个数n。
算法的第一部分须要对输入的字符串进行一次遍历,故其时间复杂度为O(m),为了对每一个字符出现的次数进行计数,程序在开始的时候初始化了一个整形数组 Asc[256] 用256个元素的存储空间来分别计算可能出现的256个字符在字符串中出现的频数,因此这个算法的空间复杂度是一个常数,即O(1)。
算法的第二部分是构造一棵哈夫曼树,这算法首先在之前每个出现过的字符的频数的统计的依据下,为每一个字符建立一个节点。并按每一个叶子节点的权值进行一次从大到小的排序(这里的排序所用的算法是冒泡算法),排序后的结果进行哈夫曼树的构造(实际上就是为数组 hft 填入相关的数据)。现在对审一部分的每一个小的部分进行时间和空间复杂度的分析。对于建立节点这一部分,程序中并没有用到额外的存储空间,只用到之前所申请的511个节点空间的数组,故其空间复杂度为O(1),遍历了数组Asc,差为出现过的n个字符各自建立起了一个叶子节点,故其时间复杂度为O(n)。
对于冒泡排序这个算法,无论输入的问题规模有多大,其调用的额外的存储空间都是一个常数,易知其空间复杂度为O(1);对于冒泡算法,其时间复杂度为
2O(n)。
最后的一部分就是树的构造,对于一棵有n个叶子节点树,须要进行n-1次的复合,而每一次进行复合所要运行的语句数都是一个常数。故其时间复杂度是O(n),其空间复杂度仍然是O(1)。
该算法的自然描述如下:
先对输入的字符串进行每一个所出现的字符出行频数的统计,再为每一个字符建立一个叶子节点,并按每个叶子节点的权值进行从小到大的排序。再从所存在的节点当中寻找两个权值之和最小的节点进行复合,作为一个新的节点的左右孩子,并把这个节点加入到节点数组之中,一直到数组中只剩下一个节点(这个结点最后作为哈夫曼树的根节点用在捕的编码之中)
下面的
伪代码描述如下:
1、统计字符串出每个出现的符号出现的次数,把统计后的结果留在数组Asc之路;
2、为每一个在字符串中出现的结点建立一个叶子节点,并将每一个叶子节点 的左右孩子及父节点设为-1,但未写入权值(后面的排序须要用到其权值,只要按这个叶子节点所存储的字符找到其在数组Asc中的位置即能找到其权值);
3、按每一个叶子节点的权值的大小进行从小到大的排序,即要值小的叶子节点放在前面;
4、写入每一个叶子节点的权值;
5、在节点数组中找到两个节点(包括叶子节点和非叶子节点),使他们的权值之和最小。并将这两个节点作为一个新的节点(非叶子节点)的左右孩子,并将这
第3页
北京邮电大学信息与通信工程学院
两个结点的权值之和作这个新的节点的权值,再将这两个复合的节点的父节点指向这一个新的节点,若这个节点是该节点的父节点的左叶孩子,则将这个父节点在数组中的下标的相反数写入其父指针中,若是右孩子,则直接写到其父指针中。一直到数组中只剩下一个没有进行过复合的节点,并将这个节点作为哈夫曼树的根节点。 算法二:写编码表
这个算法的目的是按之前所建立的哈夫曼树,为每一个所出现的字符进行二进
制编码,并写入编码表。
这个算法从节点数组中找到所有在字符串中出现过的字符,并一一为其进行编
码,再写到编码表里。该程序中的编码表由一个string类的动态数组组成,它根据叶子节点的个数申请足够大的内存空间,再根据其在哈夫曼树中的位置进行编码。
编码的过程是自下而上的,因而二进制的编码是从后面开始的,为了实现这一
编码,程序中使用的类的一个成员函数 operator+ (即加法运算符的重载)把新的一位二进制数字加到该string类字符串的前面。一直加到哈夫曼树的根节点为止。这个算法要对出现的n个字符进行编码,由于每一个编码的长度不一样,故不易从这里直接得到其时间复杂度。但考虑到两种极端的情况,即所有编码的长度加
2起来最长和最短的时候,其所用的空间复杂度分别为n(nlog2n),n(n),由于每增
加一个字符的空间,则就得调用一次string的成员operator+,故其时间复杂度
2也分别为n(nlog2n),n(n)。
该算法的自然语言描述为:对节点数组中的每一个叶子节点进行编码,查看其
父节点,若其父节点是一个负数,则在这个字符的二进制编码前面加一个0,若是一个负数,则加一个1。然后再查看其父节点的父节点的正负,一直走到根节点,再对下一个字符进行编码。
伪代码:
1、根据节点数组中叶子节点的个数,为编码表申请足够大的内存空间;
2、对节点数组中的每一个叶子节点进行编码,进行下面的操作
2.1、用一个带型变量p指向叶子节点位置;
2.2、若这个节点的父节点是一个负数,则在这个字符的编码前加一个0,
若是一个负数,则加一个1;
2.3、将这个节点父节点的位置的绝对值赋给p,循环2.2和2.3的操作,
直到p指向的是根节点;
2.3 其他
在构造哈夫曼树的时选取两个权值之和最小的结点的时候,这个程序使用了一点小技巧,即先对叶子节点进行了一次排序,使权值小的节点放在数组的前面。这是为了在后面构造树的时候免得再在节点数组中遍历一次寻找符合要求的两个节点。
这种方法的具体实现如下:每一次复合有三种选择:在叶子节点中取出最靠前的两个叶子节点进行复合、在非叶子节点中取出最靠前的两个节点进行复合、在叶子节点和非叶子节点中各取出一个最靠前的节点进行复合。每次复合只要找到三种方法中其复合节点权值最小的一种,再把复合后的节点放到非叶子节点的尾部。
为了更好说明这个办法的可行性,在这里假设程序中将叶子节点和非叶子节点放在两个
第4页
北京邮电大学信息与通信工程学院
不同的数组中,每次复合节点时在这两个数组中找到合适的两个节点进行复合,并放到非叶子节点数组的尾部(这个非叶子节点的数组看起来就像是一个队列)。下面用数学归纳法简单地证明一下这种方法在每次进行复合的时候选择的都是权值之和最小的两节点:
为了达到上面的证明,只要证明每次复合后的节点的权值都不小于上一次复合即可。 已知叶子节点的数组中的节点的权值是从小到大排列的,开始的时候从叶子节点数组中取出两个节点进行复合,并把复合后的节点放到非叶子节点的数组中去。因为非叶子节点数组中只有一个元素,所以我们现在可以认为这个数组也是从小到大排序的,以这一条作为归纳假设开始证明:
假设现在已经对节点进行了n次复合,且这n次复合成的非叶子节点的权值都是非递减排列的,并且前n次复合的方法严格按照前面所说的方法进行。由于第n次复合的方法有三种可能性,而第n+1次复合的方法也有三种,现在要对这九种情况进行分析。
首先先肯定这两次算命选取方法一样的三种情况,因为这两个数组都是从小到大进行排列的,因为第n+1次选择的两个节点的权值都不小于前两次选择的两个节点。然后就是第n次选择第一种方法,每n+1次选二种方法的,以及第n次选择第二种方法,每n+1次选一种方法的。因为在进行第n次复合的时候已经对叶子节点数组前两个节点和非叶子节点前两个节点的权值之和进行了一次比较,并在第n次的时候选择了比较小的一组,所以第n+1复合之后的节点的权值之和必然会大于每n次的。现在就只剩下四种情况了。再来就是第n次选择第三种,第n+1次选择第一种(或第二种,由于两种情况是对称的,这里就只说明其中的一种)用把证法会比较容易说明 ,设 a1、a2、a3为叶子节点最靠前的三个节点,b1为非叶子节点最靠前的一个节点。则第n次取的是a1和b1,第二次选的是a2和a3若a2+a3<a1+b1,又a1<=a2<=a3,由上两式可得a1+a2<=a2+a3<a1+b1,即第n次选择的并不不是两个权值之和最小的两个节点,故第二次不符合上面的选择的方法;用同样的方法可以证明剩下的两种情况也是不符合情况的。证毕。
3. 程序运行结果
程序运行的界面如下,通过用户输入指令运行。可用的指令有如下几条:encoding(对一个字符串进行编码),decoding(通过之前已经建立过的哈夫曼树,让助用户输入一个由0和1组成的字符串,解释用户输入的字符串),cls(清除之前输入的所有数据),tree(打印出哈夫曼树),code(打印出最近一次输入的字符串的哈夫曼编码),fileencoding(用哈夫曼编码对一个文件进行压缩),filedecoding(对一个用哈夫曼编码压缩后的文件解压),quit(停止运行程序)
对于输入的字符串,可以任意输入长度(当然,在内存允许的范围之内!不然的话会出现一些无法预料的后果,由于作者还没试过这样浩大的工程,不能给出做这样操作的后果)。对于对一个文件进行压缩,效果不一定很好(甚至还会越压越大??),毕竟在压缩的文件里还必须得写入一些额外的数据(解压钥匙),所以对一些每一个字符出现概率都一样的文件,根本没有压缩效果。但对于程序中测试的那个文件来说,压缩效果还是挺不错的(虽然别的压缩算法压的效果会更好??)
程序运行的结果如下截图:
第5页
北京邮电大学信息与通信工程学院
4. 总结
对于写这一个程序,最难的地方就是对一个文件的压缩。因为这里涉及到很多输入输出流,而且是我第一次写关于文件操作的程序,在很多地方也是现学现做。在这里首先要感谢一下一本对我很重要的书 《C++ programming primer plus》,从这本书学到了很多关于文件操作的,比如如何进行二进制的写入和读入,如何进行退格等。在这里,遇到过的最难的一个问题就是EOF,在写入的文件中,由于不知道如何识别文件尾,在写代码的时候遇到了很多问题,甚至有一次一直钻研到晚上三点??最后才发现原来系统库里已经有了很好的实现方法——利用cin.fail()来识别,之前用过cin.eof()但还是失败,甚至有一段时间还怀疑自己能否完成对一个文件的操作。还好,在primer的帮助下,我坚持下来了,并很出色地完成了这一任务。
第6页