按键扫描处理总结
一、 矩阵按键扫描方法
1、现在的矩阵扫描主要有两种方法:
(1)行列扫描法
(2)反转法。
2、行列扫描法
(1)行列扫描法的基本思想:
行列扫描法是将其中的一行输出为低电平,其他行输出为高电平,列设为输入,然后判断哪一列为低电平,从而确认出是哪一行哪一列有键按下。
(2)行列扫描法举例
如图1所示的2*2矩阵键盘,首先:将PB1,PB2作为行,并设置为输出;PA1,PA2作为列,并设置为输入。
其次:PB1设置为低电平输出,PB2设置为高电平输出,查看此时PA1和PA2的输入状态,假设此时S1按下,则此时PB1输出低电平通过S1传到了PA1上,使得PA1输入为低电平,而PA2仍然为高电平。说明第一行有键按下,并且是第一列有键按下
然后:再将PB1设置为高电平输出,PB2设置为低电平输出,此时PA1,PA2输入都为高电平。说明第二行上没有按键按下。
最后:至此可以判断此时的PA1与PB1上的按键被按下,即第一行第一列的S1被按下。整个按键扫描过程结束。
3、反转法
(1)反转法的基本思想:
将行设为输出为低电平,列设为输入,判断此时列的输入状态;然后在将列设为输出位低电平,行设为输入,判断此时行的输入状态。如果有键按下,则其中的列输入状态必然有其中一列为低,行的输入状态也必然有其中一行为低,记录此时的行列号即可判断出是哪一行哪一列有键按下。
(2)反转法举例:
如图1所示的2*2矩阵键盘,首先:将PB1,PB2作为行,并设置为输出;PA1,PA2作为列,并设置为输入。
其次:将PB1,PB2输出为低,查看PA1,PA2输入状态,假设还是S1被按下,则此时PA1输入为低电平,PA2输入为高电平。说明第一列有键按下。
然后:将PB1,PB2作为行,并设置为输入;PA1,PA2作为列,并设置为输出。 最后:将PA1,PA2输出为低,查看PB1,PB2输入状态,则此时PB1输入为低电平,
PB2输入为高电平。说明第一行有键按下。至此可以判断是第一行第一列有键按下,即S1键被按下,整个反转法扫描过程结束。

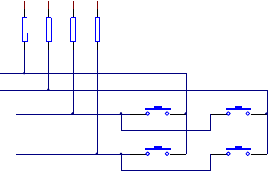
图1 矩阵键盘
二、两种扫描法存在的问题:
1、行列式扫描法存在的问题
行列扫描法虽然能够扫描出多个按键按下的情况,但是行列扫描法在扫描时,如果同一列有两个或者两个以上的按键按下,比如S1和S3被同时按下,这时开始行列扫描,当PB1输出为低电平,PB2输出为高电平时。由于S1和S3被同时按下,相当于PB1和PB2被短接,导致PB1输出的低电平和PB2输出的高电平被短接到了一起,如此一来将会存在高低电平的冲突,这个冲突虽然低电平占优势,但是对整个电路来说是一种隐患。
2、反转法存在的问题
现在反转法只适合单个按键按下的情况,如果一旦遇到多个按键按下,反转法便存在缺陷了。比如S1和S4被同时按下,当进行反转法扫描时,将PB1,PB2输出为低,此时PA1,PA2输入状态都为低;当进行反转法扫描时,将PA1,PA2输出为低,此时PB1,PB2输入状态都为低。此时只能判断出第一行,第二行都有键按下,同时第一列和第二列也有键按下。但是无法具体判断出是哪几个键按下。
3、共同存在的问题
如果如图1所示的矩阵键盘,如果同时有三个按键按下,比如S1,S2,S3被同时按下,则反转法肯定扫描不出来,但是此时的行列扫描法也无法将扫描出来具体是哪几个按键按下。比如当PB1输出为低电平,PB2输出为高电平时,PA1,PA2都输入为低;当PB2输出为低电平,PB1输出为高电平时,PA1,PA2也都输入为低。此时只能判断出第一行,第二行都有键按下,同时第一列和第二列也有键按下。而无法判断具体是哪几个按键按下。而且此时行列扫描存在的电平冲突问题依然存在。
三、改进的行列扫描法
1、改进扫描法的基本思想
由于传统的行列扫描法存在上述的高低电平冲突,所以对普通的行列扫描法做了修改,当其中一行输出为低电平的时候,将其他行设置为输入,这样就不会因为同一列上有多个按键按下的时候造成高低电平的冲突了。
2、改进扫描法的举例
如图1所示的2*2矩阵键盘,首先:将PB1设置为输出;PA1,PA2,PB2并设置为输入。 其次:PB1设置为低电平输出,查看此时PA1和PA2的输入状态,假设此时S1和S3同时被按下,则此时PB1输出低电平通过S1传到了PA1上,使得PA1输入为低电平,而PA2仍然为高电平。说明第一行有键按下,并且是第一列有键按下,即S1被按下。虽然S1和S3同时按下,导致PB1和PB2被短接,但是由于由于此时的PB1设置为输入,就不存在传统行列扫描法所存在的高低电平冲突。
然后:PB2设置为低电平输出,PA1,PA2,PB2并设置为输入。此时PA1输入为低电平。说明说明第二行有键按下,并且是第一列有键按下,即S3被按下。同理也不会出现上述的高低电平冲突。
最后:至此可以判断S1和S3被同时按下。整个按键扫描过程结束。
3、改进式行列扫描法的意义
改进式行列扫描法避免了传统扫描法在扫描过程中,如果同一列有多个按键按下时出现的高低电平冲突,并且程序量不会增加。但是对于上述提到的S1,S2,S3被同时按下的情况,改进式行列扫描法也无法解决,有待进一步探究。(本人写此总结的目的在于和大家共同交流,如果有不对的地方希望各位指正,谢谢!!!)
编写:zhuky 2012.11.24
第二篇:java中处理乱码问题个人总结
[个人总结]java中处理乱码问题个人总结
java乱码的问题的可谓是老生常谈了,自从接触java以来,就不断地与中文乱码的问题打交道,最近的参与的报表工具开发中,遇到的乱码问题更是让人头疼,随着项目工作的进度,自己总结了一下处理乱码的心得,在这里与大家一起分享一下。
Java的内核以及class文件都是采用的unicode的编码,这样java程序就具有了很好的跨平台性,随之也就带来了乱码的问题的麻烦。出现乱码的问题原因主要有两个方面Java及JSP文件本身编译时产生的乱码和Java程序与其他媒介交互产生的乱码。
下面对于这两种情况产生的乱码,分别说明解决方法:
第一种情况:(Java或JSP自身产生的乱码)
Java(包括JSP)源文件中很可能包含有中文,而Java和JSP源文件的保存方式是基于字节流的,如果Java和JSP编译成class文件过程中,使用的编码方式与源文件的编码不一致,就会出现乱码,基于这种乱码,建议在Java文件中尽量不要写中文(注释部分不参与编译,写中文没关系),如果必须写的话,尽量手动带参数-ecoding GBK或-ecoding gb2312编译;对于JSP,在文件头加上
<%@ page contentType="text/html;charset=GBK"%>或
<%@ page contentType="text/html;charset=gb2312"%>基本上就能解决这类乱码问题。这种情况比较简单。呵呵。如果有同事碰到特别的情况不能解决,不妨一起来讨论一下呀。
对于第二类的这种乱码,可能的情况比较多,我们也分别来看:
1、 页面参数传递是出现的乱码
这是因为Jsp获取页面参数时一般采用系统默认的编码方式,如果页面参数的编码类型和系统默认的编码类型不一致,很可能就会出现乱码。解决这类乱码问题的基本方法是在页
面获取参数之前,强制指定request获取参数的编码方式:request.setCharacterEncoding("GBK")或request.setCharacterEncoding("gb2312")。
如果在JSP将变量输出到页面时出现了乱码,可以通过设置
response.setContentType("text/html;charset=GBK")或response.setContentType
("text/html;charset=gb2312")解决。
在 JBoss+Jetty 中开发 JSP 时,当把页面编码设置为 gb2312 时,即
<%@ page contentType="text/html;charset=gb2312">
取参数前需要先设置一下 request 对象的编码, request.setCharacterEncoding("gb2312");
否则取出来的中文会是乱码,必须要手工转换,即:
new String(request.getParameter("click").getBytes("iso8859-1"),"gb2312"); 这样做就麻烦了。需要注意的是设置 request 对象的编码必须要在取所有的参数之前,否则就无效了。
Tomcat 支持 GBK 没有问题,不过 Jetty 缺省只能支持 GB2312。使用:
<%@ page contentType="text/html;CHARSET=utf-8" %> 是没有效果的。 有这个问题是因为在 Jetty 中将 GB2312 作为中国的缺省字符集。解决的方法是修改 Jetty 的代码,将 GB2312 改为 GBK(只有一个 Java 文件)。重新编译就可以支持 GBK 了。jetty4.21 版gbk的问题好象已经解决了,不过request仍然要编码
其实对于这种情况更简洁的处理办法就是使用servlet规范中的过滤器指定编码,在这里也提供一个简单
的配置参考。
Web.xml:
<filter>
<filter-name>CharacterEncodingFilter</filter-name>
<filter-class>com.test.web.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>GBK</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>CharacterEncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
CharacterEncodingFilter.java:
public class CharacterEncodingFilter implements Filter
{
protected String encoding = null;
public void init(FilterConfig filterConfig) throws ServletException
{
this.encoding = filterConfig.getInitParameter("encoding");
}
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException
{
request.setCharacterEncoding(encoding);
response.setContentType("text/html;charset="+encoding);
chain.doFilter(request, response);
}
}
2、 Java与数据库之间的乱码
大部分数据库都支持以unicode编码方式,所以解决Java与数据库之间的乱码问题比较明智的方式是直接使用unicode编码与数据库交互。很多数据库驱动自动支持unicode,可以在驱动的url参数中指定, 如mysql驱动:jdbc:mysql://localhost/WEBCLDB?useUnicode=true&characterEncoding=GBK。
不过像现在在实际的项目中,数据库的编码格式可能我们是没有办法修改的,这样的话,也就只能是针对现在的数据库的编码格式对提取出来的数据进行转码。如果是在中文的环境下,基本上是不需要转码的,因为是从GBK-?GBK,(以报表为例),如果数据库的编码是ISO-8859-1的话,就需要转为GBK来处理,否则就会出现乱码的问题了,在最近的项目中还遇到了一种情况,那就是在SQL语句中存在中文,这种情况在目前的报表工具中还是比较多的,中文环境下不需要坐任何的处理,在ISO-8859-1的环境下,需要将GBK再转换为ISO-8859-1来处理,否则SQL中的中文在页面上看到的就是?,
3、 Java与文件/流之间的乱码
Java读写文件最常用的类是FileInputStream/FileOutputStream和FileReader/FileWriter。其中
FileInputStream和FileOutputStream是基于字节流的,常用于读写二进制文件。
读写字符文件建议使用基于字符的FileReader和FileWriter,省去了字节与字符之间的转换。但这两个类的构造函数默认使用系统的编码方式,如果文件内容与系统编码方式不一致,可能会出现乱码。在这种情况下,建议使用FileReader和FileWriter的父类: InputStreamReader/OutputStreamWriter,它们也是基于字符的,但在构造函数中可以指定编码类型:InputStreamReader(InputStream in, Charset cs) 和OutputStreamWriter (OutputStream out, Charset cs)。
4、其他
上面说的这几种情况可以解决大部分的乱码问题,如果在其他地方出现乱码,可能就需要手工的来进行转码了,解决这类问题的关键就在于字节和字符的转换过程,你必须清楚地知道原来的字节或转换后的字节的编码方式,也就是说转换时采用的编码必须与这个编码方式一致。
在实际的项目碰到了一种情况,就是用servlet直接输出页面的情况,(这种通过servlet输出页面的方式我个人是不推荐使用了,不过以前的项目遗留下来的,那也就没有办法了,呵呵!)这里就说到PrintWriter和ServletOutputStream的区别,个人的建议,如果是涉及到字符的转换强烈推荐使用PrintWriter,虽然会占用一些系统的开销,但是可以很好的帮助解决乱码的问题,更详细的可以参考我的另一篇文章《PrintWriter 与 。
总结:在处理java的编码问题时,要分清楚三个概念:Java采用的编码:unicode,JVM平台默认字符集和外部资源的编码。这样我们在面对乱码的问题时,解决起来就游刃有余了。
这个JVM平台默认字符集在虚拟机启动时决定,通常根据语言环境和底层操作系统的 charset 来确定。可以通过以下方式得到JVM的默认字符集:Charset.defaultCharset();
花了半天的时间总结了一番,自己再回头一想,解决乱码问题的思路就更清晰了,也希望此文能够切实的对其他同事在实际的工作中有所帮助,中间又说的不对的地方也请指正,共同进步!
热切希望此文能够被加为精华!