Java Webʵ��ѧϰ���ܽ�����
һ�����ʹServlet�ڷ���������ʱ�ͱ����ز���ȡ��ʼ��������
*****************************************************************************************
1.Ҫʹ��Servlet�ڷ���������ʱ�ͱ����أ���Ҫ��WebӦ��������web.xml�ļ���
������ֵ
���ò���ָ����WebӦ������ʱ��װ��Servlet�Ĵ������ֵΪ�������㣬Servlet�����ȼ�����ֵС��Servlet�������μ���������ֵ���Servlet��������ֵΪ��������û���趨����ôServlet��������Web�ͻ��״η������Servletʱ������
2.Ҫʹ��Servlet�ڷ���������ʱ�Ͷ�ȡ��ʼ����������Ҫ��WebӦ��������web.xml�ļ���
������
����ֵ
�ò�������Servlet�ij�ʼ��������һ��Ԫ�ؿ����ж������Servlet�����غ���ͨ��Servlet��init()�����IJ���ServletConfig������getInitParameter(������)��ȡ��ʼ��������ֵ
*****************************************************************************************
���������Servlet�ж�ȡXML�ļ���
*****************************************************************************************
Ҫ��Servlet�ж�ȡXML�ļ�������ʹ��JDOM��������İ��ṹ���£�
A.import org.jdom.input.SAXBuilder
B.import org.jdom.Document
C.import org.jdom.Element
D.import org.jdom.JDOMException
SAXBuilder��ʹ���˵������Ĺ���SAX PASER���Ӹ��ָ������ļ���stream��reader��url����SAX InputSouceʵ���д���JDOM �ĵ�����Document�������һ��XML�ĵ���Element�������һ��XML�ĵ��еĽڵ㣬�ṩ����������ڷ��ʽڵ㼰���ӽڵ㡢���ԡ��ı����ݡ�
��ȡXML�ļ��IJ������£�
A.����һ��SAXBuilder����
B.���øö���һ���ĵ�����
C.���ĵ������л�ȡ���ڵ�
D.�Ӹ��ڵ��л�ȡ�����ӽڵ�
E.�Ӹ����ӽڵ�����ȡ��������
���磺
try{
//����һ��SAXBuilder����
SAXBuilder builder = new SAXBuilder(false);
//��ȡ����configURIָ����·���µ�XML�ļ�
Document doc = builder.build(configURI);
//��ȡXML�ļ��ĸ��ڵ�
Element root = doc.getRootElement();
//��ȡ���ڵ��µ�"database"�ڵ���ӽڵ�"url"��ֵ
root.getChild("database").getChild("url").getTextTrim();
}
*****************************************************************************************
������ΰ��ַ���ת����GBK��ASCII��UTF-8�����ʽ��
*****************************************************************************************
1.���ַ���ת����GBK���룺
public String toGBK(String str){
try
{
str=new String(str.getBytes("ISO-8859-1"),"GBK");
}catch (Exception e) {}
return str;
}
2.���ַ���ת����ASCII���룺
public String toGBK(String str){
try
{
str=new String(str.getBytes("GBK"),"ISO-8859-1");
}catch (Exception e) {}
return str;
}
3�����ַ���ת����UTF-8���룺
A.��Stringת����byte����(8bit)
B.����һ����byte����ȳ���char����(16bit)
C.ʹ��ѭ��ÿ��ȡ��byte������һ��byte��ʮ��������0x00FF�����룬��ת����char����
D.ѭ��������char������Ϊ��������һ���ַ���
public String toUtf8String(String src){
byte b[] = src.getBytes();//ʹ�ñ���ƽ̨���룬Ĭ��Ϊ8λ����
char c[] = new char[b.length];//����unicode�����ʾ(16λ)
//��0x00FF����õ��䱾��(8bit)����ת����16bit��char������ֵ
for(int i=0;i
c[i] = (char)b[i]&0x00FF;
}
//��char��ֵ��ΪString���캯���IJ����½�һ��String
return new String(c);
}
*****************************************************************************************
�ġ���θ����ض��ķָ����ָ��ַ�����
*****************************************************************************************
1.ʹ���ַ������ṩ�ķ�����
A.��ԭ�ַ���֮�������Ϸָ���(�ָ����Ӵ�����Ŀ=�ָ������ֵĴ���+1)
B.ʹ��ѭ���ж�ԭ�ַ���Ӧ�ñ��ָ�ɶ��ٸ��Ӵ�
C.ʹ��ѭ����ȡ�ӵ�ǰ�ַ���ʼ���ָ��֮����Ӵ�
D.���ָ���֮����Ӵ���Ϊ��һ��ѭ����ʼ��ԭ�ַ���
public String[] splitStr(String str,char c){
//ԭ�ַ���֮�������Ϸָ�����ȷ���Ӵ�����Ŀ=�ָ�������Ŀ+1
str+=c;
int n = 0;
for(int i=0;i
//������ַָ������Ӵ�����Ŀ��1
if(charAt(i).equalsIgnoreCase(c)) n=n+1;
}
String out[] = new String[n];
for(int j=0;j
int index = str.indexOf(c);//�ָ�����λ��
out[j] = str.substring(0,index);//��ȡ�Ӵ�
str = str.substring(index+1,str.lengt()); //��һ��ѭ����str
}
return out;
}
2.ʹ��java.util.StringTokenizer����ַ������зָ�
public String[] splitStr(String str,char c){
//����һ��StringTokenizer����
StringTokenizer st = new StringTokenizer(new Character(c).toString());
//��ȡtoken����Ŀ�������ڵ�һ�ε���nextToken()֮ǰ����
int num = st.countTokens();
//�½�һ��String�������ڴ�Ÿ����Ӵ�
String out[] = new String[num];
//ȡ��ÿ��token
int i = 0;
while(st.hasMoreTokens()){
out[i] = st.nextToken();
i = i+1;
}
return out;
}
*****************************************************************************************
�塢��λ�ȡ�������Ԫ������Ϣ��
*****************************************************************************************
ResultSetMetaData��һ�����ڴ�ResultSet�л�ȡ�е����ͺ����ԵĶ����õ�API�У�
A.getColumnCount()�� ��ȡResultSet�����е�����
B.getColumnName(int column)�� ��ȡ ResultSet�����е�����
C.getColumnType(int column)���� ��ȡResultSet�����е��е�����(����)
D.getColumnTypeName(int column): ��ȡResultSet�����е��е����͵�����(S)
E.getTableName(int column)�� ��ȡ�����ڵı��ı���
F.isNullable(int column)�� �жϸ����Ƿ����Ϊ��
*****************************************************************************************
������λ�ȡ���ݿ�Ľṹ��Ϣ��
*****************************************************************************************
1. ʹ������ӿڵ��û��ڴ��������¶���Ϊ�˽��һЩ��DBMS�йصĵײ����⣬���磺���Ҫʹ��CREATE TABLE���������һ�����ṹ����ô������Ҫʹ��getTypeInfo�������ҳ�������ݿ�֧�ֵ��������ͣ������û�����ͨ������supportsCorrrelatedSubqueries�������ж��Ƿ���������ݿ�ʹ��Ƕ���Ӳ�ѯ��ͨ������supportsBatchUpdates�������ж��Ƿ���������ݿ���ִ���������ĸ��²���
2. DatabaseMetaData���һЩ��������ResultSet����ʽ���ع������ݿ����Ϣ�б���ResultSet��ĺܶ��������getString��getInt���������������Ի�ȡ���ݣ����������metadata�ĸ�ʽ������Ч�ģ���ResultSet����Щgetter�������׳�һ��SQLException
3. DatabaseMetaData���һЩ���������д����ַ�����ʽ�IJ���������Щ��ʽ�ַ����У�"%"��ʾƥ���κ�����������ַ��Ӵ�����"_"��ʾƥ��һ���ַ������ҽ���ƥ���Ԫ���ݱ����أ���������ĸ�ʽ�ַ���������Ϊ�գ�������ȫ����Ԫ����
4.���õ�API��
A. String getCatalogSeparator()���������ݿ��Ŀ¼�ͱ���֮��ķָ���
B. ResultSet getColumns(String catalog, //Ŀ¼
String schemaPattern, //���ݿ��ģʽ��ͨ�����û���Ϊһ��ģʽ
String tableNamePattern, //���ݿ�����ݱ�����
String columnNamePattern) //���ݱ���������
throws SQLException
C. String getDatabaseProductName()����ȡ���ݿ�IJ�Ʒ����
D. String getDriverName()����ȡ���ݿ��������������
E. int getMaxConnections()����ȡ��ǰ���ݿ��������������
F. ResultSet getPrimaryKeys(String catalog, //Ŀ¼
String schema, //���ݿ��ģʽ��ͨ�����û���Ϊһ��ģʽ
String table) //���ݿ�����ݱ�����
throws SQLException
G. ResultSet getTables(String catalog, //Ŀ¼
String schemaPattern, //���ݿ��ģʽ��ͨ�����û���Ϊһ��ģʽ
String tableNamePattern, //���ݿ�����ݱ�����
String[] types) //���ݱ������ͣ�����TABLE��VIEW��
throws SQLException
H��ResultSet getTypeInfo()����ȡ�����ݿ������б�֧�ֵ���������
I. String getUserName()����ȡ�����ݿ���������֪���û���
*****************************************************************************************
�ߡ���ζ�̬��ƴװ����SQL��䣺
*****************************************************************************************
1.˼·��Ҫ��̬��ƴװINSERT��䣬�ؼ����ڻ�ȡÿһ���ֶε����ơ�ֵ�����ͣ�����ֻҪ��ÿһ���ֶε����ơ�ֵ�����Ͷ���װ��һ����Ӧ��Vector�У�����ѭ��ÿ��ȡ��һ���ֶε�Vecotr���Ϳ��Ը����ֶ����ƶ�̬��ƴװ�ֶ��б�������ֵ������������Ӧ��ת����̬��ƴװֵ�б���
2.������

[0] [1] [2]
3.���裺
A.��Vector��ȡ����һ��Ԫ�أ�tableName
B.��Vector��ȡ���ڶ���Ԫ�أ�columnName/columnValue/columnType
C.�����ʱ�ֶ��б�����Ϊ�գ���Ϊ�ֶ��б�������ֵ”(”
D.�����ʱ�ֶ��б�������Ϊ�գ������ֶ��б�����������”,”
E.���ֶ��б�����������cloumnName
F.�����ʱֵ�б�����Ϊ�գ���Ϊֵ�б�������ֵ”(”
G.�����ʱֵ�б�������Ϊ�գ�����ֵ�б�����������“��”
H.����columnType��ֵ����columnValue��ֵ������Ӧ��ת��
I.��ֵ�б�����������ת�����columnValue
J.�ظ�����Bֱ�����е��ֶα��������
4.��Ҫ���룺
//ȡ��ÿ���ֶ��е�field��value��type����ƴװ
Vector v_t = (Vector)vect.get(i);
field = (String)v_t.get(0);
value = (String)v_t.get(1);
type = (String)v_t.get(2);
//����ֶ�SQL
if(sqlField.equals(""))
sqlField = " (";
else
sqlField = sqlField + ",";
sqlField = sqlField + field;
//���ֵSQL
if(sqlValue.equals(""))
sqlValue = "(";
else
sqlValue = sqlValue + ",";
if(value.equals("")){ //Ϊ��ʱ
sqlValue = sqlValue + "null";
}
else if(type.equals("CHAR")){ //�ַ���
sqlValue = sqlValue + "'" + value + "'";
}
else if(type.equals("NUM")){ //��ֵ
sqlValue = sqlValue + value;
}
else if(type.equals("TIME")){ //����
sqlValue = sqlValue + "to_date('yyyy-MM-dd HH:mm:ss','" + value + "')";
}
//ƴװ����
sqlField = sqlField + ")";
sqlValue = sqlValue + ")";
String sql = "insert into " + (String)vect.get(0) + sqlField + " values" + sqlValue;
*****************************************************************************************
�ˡ���ζ�̬��ƴװ���µ�SQL��䣺
*****************************************************************************************
1.˼·���Ͷ�̬��ƴװ�����SQL�����ͬ����ͬ��ֻ�Dz����Ľṹ��ͬ�������˸��µ���������
2.������

3.���裺
��������Ͷ�̬��ƴװ�����SQL�����ͬ��ֻ����ȡ���µ��ֶ��б�ʱ�Ǵ�Vector�ĵڶ���Ԫ�ؿ�ʼֱ�������ڶ�������������ټ���condition�ֶ���Ϊ���µ�����
4.���룺
//��ȡ����SQL���ĸ�ֵ����
��String sql = "update " + (String)vect.get(0) + " set " + sqlSet;
//��ȡ����SQL������������
��String sqlWhere = (String)vect.get(vect.size()-1);
��if(!sqlWhere.equals("")){ //ƴװ����
sql = sql + " where " + sqlWhere;
��}
*****************************************************************************************
�š���ζ����ݿ�IJ�ѯ������з�ҳ��ʾ��
*****************************************************************************************
1.˼·��Ҫ��ȡ��ǰҳ�����ݣ�����Ҫ�ľ���Ҫ��ȡ����������ֵ���ܼ�¼����ÿһҳ�ļ�¼������ǰҳ��ҳ�룬�ɴ˿���ȷ����ҳ��ҳ������λ����ǰҳ�ĵ�һ����¼
2.������Ҫ��ѯ�ĵ�ǰҳҳ�룬ÿҳ�ļ�¼��
3.���裺A.ִ��SQL��ѯ��䣬��ȡ�����з��������ļ�¼����ɵļ�¼��
��������B.ͳ�Ƽ�¼���еļ�¼����
��������C.���ݼ�¼������ÿһҳ�ļ�¼��ȷ����ҳ��ҳ��
D.���ݷ�ҳ��ҳ���Ե�ǰҳ����������Ӧ�ĵ���
E.���ݵ�ǰҳ��ҳ�붨λ����ǰҳ��������¼
F.��ÿһ����¼���ֶ���/ֵ��key/value�Ե���ʽ�洢��Hashtable��
G.��������ǰ��¼��Hashtable���ӵ�Vector��
H.�ظ�����Bֱ����¼���е��������ݱ�ȫ�����ӵ�Vector��
4.�����

Vector
5.���룺
rs = pstm.executeQuery();
//��ȡ��¼���еļ�¼����
while (rs.next()){
rows++;
}
//��ȡ��ҳ������:�������������ҳ��������1ҳ
int sum = rows / records;
if(rows % records != 0 || rows == 0){
sum++;
}
//���ݷ�ҳ�������Ե�ǰҳ��������Ӧ�ĵ���
if (page==0){
page = 1;
}
else if (page��sum)
{
page = sum;
}
//��λ����ǰ��¼
index = (page - 1) * records;
rs.absolute(index+1);
//�ӵ�ǰҳ�ĵ�һ����¼��ʼ����ǰҳ�����м�¼�洢��Vector��
int j = 0;
do
{ // ���������û�����ݡ�����ȡ�����˳���ѯ
if(rs==null||j == records||rs.getRow()==0){
break;
}
j++;
ResultSetMetaData rsmd = rs.getMetaData();
int cols = rsmd.getColumnCount();
Hashtable hash = new Hashtable();
//����ǰ��¼�������ֶ�����/ֵ�Ե���ʽ���浽Hashtable��
for(int i = 1; i ��= cols; i++){
String field = ds.toString(rsmd.getColumnName(i));
String value = ds.toString(rs.getString(i));
hash.put(field, value);
}
//����ǰ��¼���ӵ�Vector��ĩβ
vect.add(hash);
}while(rs.next());
*****************************************************************************************
ʮ�����ͬʱ�����ѯ���ֶκ�ֵ��
*****************************************************************************************
1.Ҫ��ȡ�ֶε���Ϣ������ʹ��java.sql.ResultSetMetaData�ӿڣ�������ӿ��ж�����һϵ�еĹ����ֶ���Ϣ�Ļ�ȡ�����õ�API
2.Ҫͬʱ�����ѯ���ֶκ�ֵ������ʹ��java.uti.Hashtable�࣬Hashtable�ǹ�ϣ�����洢�����е�Ԫ�ض���key/value�Ե���ʽ��ʾ��Hashtable�о���put��get���������Խ��������͵�������idΪ��ʶ��ŵ����У�Ҳ���Դ���ȡ��keyΪid�Ķ���
ResultSetMetaData rsmd = rs.getMetaData();
Hashtable hash = new Hashtable();
int cols = rsmd.getColumnCount();
for (int i=1;i��=cols;i++){
String colName = rsmd.getColumnName(i);
String colValue= rs.getString(i);
hash.put(colName,colValue);
}
*****************************************************************************************
ʮһ����ν�HTML��ʽ���ļ�����Ϊ��ͨ��ʽ���ı��ļ���
*****************************************************************************************
1.˼·��Ҫ��HTML��ʽ���ļ�����Ϊ��ͨ��ʽ���ı��ļ���Ҫע����Ҫ�����е�һЩ�����HTML���ת������Ӧ���ı���ʽ������”&”��”��”��”��”��”"”
2.���裺A.��ȡ��������·�����ļ������ļ����ݡ�������
��������B.���ļ������е�ijЩHTML��ǽ����ʵ���ת��
C.�ж��ļ�����Ӧ���ļ��Ƿ��Ѿ�����
��������D.������������ļ����ַ�����ʽд�����ش�����
3.���룺
//��ȡ�ļ������ļ�����
String file = (String)hashtable.get(“file”);
String content = (String)hashtable.get(“content”);
//��HTML�IJ��ֱ�ǽ����滻
content = content.replaceAll(“&”,”&”);
content = content.replaceAll(“��”,”��”);
content = content.replaceAll(“��”,”��”);
content = content.replaceAll(“"”,”\””);
//�ж��ļ�����Ӧ���ļ��Ƿ��Լ�����
String f = file.substring(file.lastIndexOf(“/”)+1,file.length());
String sql = “select * from art where file = ‘”+f+”’”;
if (getResultSetData(selectRecord(sql)).size()!=0) {
return 1;
}
else{
//����Unicode�ַ���
OutputStreamWriter osw = new OutputStreamWriter(os);
PrintWriter bw = new PrintWriter(osw);
//дUnicode�ַ���
bw.print(str,0,str.length());;
bw.newLine();
}
*****************************************************************************************
ʮ������δ��ı��ļ��ж�ȡ���ݲ�ת����HTML��ʽ��
*****************************************************************************************
//����Unicode�ַ���
InputStreamReader isw = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isw);
//��Unicode�ַ���
String s = "";
while((s=br.readLine())!=null){
if(!str.equals(""))str = str + "\r\n" + s;
else str = str + s;
}
*****************************************************************************************
ʮ����File��ij��÷�����
*****************************************************************************************
1. public boolean canRead()���ܷ��
2.public boolean canWrite():�ܷ�д
3.public int compareTo(File pathname):�Ƚ�����File������Ƿ�Ϊͬһ��
4.public boolean createNewFile() throws IOException:�����µ��ļ�
5.public boolean delete():ɾ���ļ�
6.public String getAbsolutePath():��ȡFile�����ij���·������Ӧ�ľ���·��
7.public String getName():��ȡFile�������ļ���(������·��)
8.public String getParent():��ȡFile�������������·������һ��Ŀ¼
9.public File getParentFile()����ȡFile�����ĸ�Ŀ¼����
10. public long length():
11.public boolean isAbsolute():�жϸ�·���Ƿ�Ϊ����·��
12.public boolean isDirectory():�жϸ�File������Ƿ�ΪĿ¼
13.public boolean isFile()���жϸ�File������Ƿ�Ϊ�ļ�
14.public long lastModified():��ȡ��File�����������ʱ��
15.public String[] list(FilenameFilter filter):�г���File���������Ŀ¼�µ�Ŀ¼���ļ���
16.public boolean mkdir():������Ŀ¼
17.public boolean renameTo(File dest):��File�����������
18.public boolean setLastModified(long time):���ø�File�����������ʱ��
19.public boolean setReadOnly():���ø�File����������Ϊֻ��
20. public URL toURL()throws MalformedURLException:��File�����·��ת��ΪURL
*****************************************************************************************
ʮ�ġ����ʹ��I/0�������ļ���
*****************************************************************************************
1.˼·��Ҫʹ��I/O�������ļ�������Ҫ�ľ���Ҫ��ȡһ�������ļ���������ļ�����Ȼ��ͨ�� InputStream��Reader�������ļ��а��ֽڻ��ַ���ȡ���ݣ���ͨ��OutputStream��Writer д������ļ��Ϳ�����
2.���룺
FileInputStream fis = new FileInputStream(infile);
FileOutputStream fos = new FileOutputStream(outfile);
1./**�����ļ�����fis-��fos*/
public void movefile_FileStream(){
try{
File f = new File(infile); //����һ���ļ�����
byte b[]=new byte[(int)(f.length())]; //����һ������Ϊ�ļ����ȵ�byte����
fis.read(b); //��ȡbyte���鳤�ȵ��ֽڵ�������
fos.write(b); //��byte�����е��ֽ�ȫ��������ļ���
}catch(IOException ioe){
System.out.println("����DealFile.movefile_FileStream()��������:\r\n"+ioe);}
��}
2./**�����ļ�����fis-��fos*/
public void movefile_BufferedByteStream(){
try{
BufferedInputStream in = new BufferedInputStream(fis);
BufferedOutputStream out = new BufferedOutputStream(fos);
int c;
//ÿ�δ��ļ��ж�ȡһ���ֽڵ����ݣ�����ֵΪ��ȡ����Ч�ֽ������ļ�������-1
while((c=in.read())!=-1){
out.write(c);
}
in.close();
out.close();
}catch(IOException ioe){
System.out.println("����DealFile.movefile_BufferedByteStream()������ ��:\r\n"+ioe);
�� }
}
3./**�����ļ�����infile-��outfile*/
public void movefile_BufferedCharStream(){
try{
BufferedReader in = new BufferedReader(new FileReader(infile));
PrintWriter out = new PrintWriter(new FileWriter(outfile));
int c;
while((c=in.read())!=-1){//ÿ�ζ���һ���ַ����ļ������أ���
out.print(c); //ÿ��дһ���ַ�
}
in.close();
out.close();
}catch(IOException ioe){
System.out.println("����DealFile.movefile_BufferedCharStream()������ ��:\r\n"+ioe);
}
}
*****************************************************************************************
ʮ�ġ����ʹ��RandomAccessFile���/д���ݣ�
*****************************************************************************************
1.RandomAccessFile���飺
RandomAccessFile���ʵ��֧�ִ�һ����������ļ��ж���д�ļ��IJ���������һ�����������
�������Ǵ洢���ļ�ϵͳ�е�һ������ֽ����飬�������������һ���������α�����±�Ķ�
�������dz�֮Ϊ�ļ�ָ�룻
��ȡ�ļ�ʱ�ӵ�ǰ�ļ�ָ���λ�ÿ�ʼ���ļ�ָ�벻�ϵش���Ҫ��ȡ���ֽڣ������������ļ���
�Զ�/д��ģʽ�����ģ����ļ����������Ҳ�������ġ�д�ļ��Ǵӵ�ǰ�ļ�ָ���λ�ÿ�ʼ���ļ�
ָ�벻�ϵĴ���Ҫд���ֽڡ��ļ�ָ�����ͨ��getFilePointer������ȡ��Ҳ����ͨ��seek����
��������
2.RandomAccessFile��ij���API��
1.public RandomAccessFile(String name, String mode):��ָ����ģʽ������������ļ�
2.public long getFilePointer()����ȡ����������ļ����ļ�ָ��
3.public long length()����ȡ����������ļ���ʵ�ʳ���
4.public int read()������������ļ��ж�ȡһ���ֽڵ�����
5.public final char readChar()������������ļ��ж�ȡһ���ַ�
6.public final int readInt()������������ļ��ж�ȡһ������
7.public final String readLine()������������ļ��ж�ȡһ���ı�
8.public final String readUTF()������������ļ��ж�ȡһ��UTF-8���ַ���
9.public void seek(long pos)�����ø���������ļ����ļ�ָ���λ��
10.public void setLength(long newLength)�����ø���������ļ��ij���
11.public int skipBytes(int n)�������ɲ���ָ�����ֽ���������
12.public void write(byte[] b)�����ļ���д����Ϊb�ij��ȵ�����
13.public final void writeBytes(String s)�����ַ���s���ֽ�������ʽ���
14.public final void writeChars(String s)�����ַ���s���ַ�����ʽ���
3.ʹ��RadndomAccessFile���ļ���ĩβ�����ݣ�
public void appendCHStr(String outfile,String str) {
try {
RandomAccessFile rf = new RandomAccessFile(outfile,"rw");
rf.seek(rf.length()); //��λ���ļ�ĩβ
rf.writeBytes(str); //�ӵ�ǰ�ļ�ָ���λ�ÿ�ʼ������
rf.close();
}catch(IOException ioe){
System.out.println("����DealFile.appendCHStr()��������:\r\n"+ioe);
}
}
*****************************************************************************************
ʮ�塢������ļ��н���ȫ��������
*****************************************************************************************
1.˼·��ȫ��������Ҫ�������漸�����ͣ�
A.�����µĿ�ʼ�����ַ�����һ�γ��ֵ�λ��
B.��ָ����λ�������ַ�����һ�γ��ֵ�λ��
�� C.��ָ�����ַ�����ʼ������һ�ַ�����һ�γ��ֵ�λ��
Ҫʵ��ȫ������������֧��������������ط����ļ��е����ݣ���ͨ����stream��reader�� writer�ȶ�����ʵ��������ʵĹ��ܣ�ֻ����ǰ��/д������������/д��������������� ��һ����λ����������ļ������ʱ��ֻ��ʹ��RandomAccessFile��ʵ��������ʡ�A��C�� ���������ͨ������B���������
2.���裺
A.�ж�������λ���Ƿ���ļ��ij��ȴ��������ִ����������
B.����ʹ��RandomAccessFileֱ�Ӷ�λ�������Ŀ�ʼλ�ô����ж�ʣ����Ƿ�С���ַ�������
C.�������ִ����������������ӵ�ǰλ�ÿ�ʼ��ȡ�������ַ����ȳ������ݽ��бȽ�
D.����ȽϽ����ͬ���˳��������ַ�����λ�ã����ز���C������һ�αȽ�ֱ���ļ�����
3.���룺
/**��λ��cur��ʼ������һ��str��λ��*/
public long seekStrPos(long cur,String str) {
long fcur = cur;
try {
RandomAccessFile file = new RandomAccessFile(new File(infile),"r");
long flen = file.length(); //�ļ��ij���
int slen = str.length(); //�Ƚ��ַ����ij���
byte []b = new byte[slen]; //��ʱ���������Դ�Ŷ�ȡ���ַ���
for(;fcur
file.seek(fcur); //ʹ���ļ�ָ��ֱ�Ӷ�λ�������Ŀ�ʼλ��
//�ļ�βʣ��Ȳ��ٹ�ʱ
if((flen-fcur)
fcur = -1;
break;
}
//�ж϶�ȡ���ַ����ͱȽ��ַ����Ƿ���ͬ���������������
file.read(b,0,slen); //��ȡ�ͱȽ��ַ����ȳ����ַ�����������
String bstr = new String(b);
if(str.equals(bstr)) break;
}
file.close(); //ע���������Ҫ�ر��ļ�
}catch(IOException ioe){
System.out.println("����DealFile.seekStrPos()��������:\r\n"+ioe);
}
return fcur;
}
*****************************************************************************************
ʮ���������Java��ʹ���������ʽ��
*****************************************************************************************
*****************************************************************************************
ʮ�ߡ������JSP����ʾ”��ҳ����һҳ����һҳ��ĩҳ”�����ӣ�
*****************************************************************************************
1.˼·��Ҫ��JSP����ʾ“��ҳ����һҳ����һҳ��ĩҳ”�����ӣ��ؼ���Ҫ֪������������
A.ִ��SQL��ѯ����ܼ�¼��
B.ִ��SQL��ѯ��ķ�ҳ����
C.��ǰ����IJ�ѯҳ��
������ʱ�������ж��Ƿ���ҳ��IJ��������û����Ϊ�״β�ѯ��Ĭ��Ϊ��ѯ��һҳ���� ��Ļ����÷�ҳģ���ȡ�����3������������ǰ�����ҳ���ǰ�����������бȽϾͿ���ȷ ���Ƿ�Ҫ��ʾ�⼸��������
2.���裺
A.��ȡ��ǰ����IJ�ѯҳ�����
B.�������Ϊ�գ���Ϊ��һ�β�ѯ��Ĭ�ϲ�ѯ��һҳ��������ת��Ϊ��������
C.��Ҫ��ѯ��ҳ���ÿҳ��ʾ��¼����Ϊ�������ò�ѯ��ҳ��ģ�飬��ȡһ��Vector
D.��Vector�л�ȡ��ѯ������ܼ�¼�����ܷ�ҳ����ResultSet
E.�����ǰҳ���1������ʾ��һҳ
F.�����ǰҳ����ܷ�ҳ��С������ʾ��һҳ
3.���룺
//ȡ�ô���ʾҳ��
strPage = request.getParameter("page");
if(strPage==null){
//������һ����ʾ��ҳ�棬��ʱ��ʾ��һҳ����
intPage = 1;
}
else{
//���ַ���ת��������
intPage = java.lang.Integer.parseInt(strPage);
if(intPage��1) intPage = 1;
}
//��λ����ѯҳ��ĵ�һ����¼��������״η�����λ����1����¼
int recno=(intPage-1)*intPageSize+1;
//ȡ�õ�ǰҳ������:�ܵļ�¼��+�ܵ�ҳ��+������¼��Hashtable�ṹ
Vector vect = myBean.getCurPage(intPage,intPageSize);
//��ȡ��¼����:rows
intRowCount = Integer.parseInt((String)vect.get(0));
//������ҳ��:sums
intPageCount = Integer.parseInt((String)vect.get(1));
//��������ʾ��ҳ��
if(intPage��intPageCount) intPage = intPageCount;
��!--��ʾ��ǰҳ����ܹ���ҳ������¼��--��
�ڣ�%=intPage%��ҳ ����%=intPageCount%��ҳ(��%=intRowCount%����)
��!--��ʾ��ҳ����--��
��a href="user.jsp?"����ҳ��/a��
��!--��ʾ��һҳ������--��
��%if(intPage��1){%��
��a href="user.jsp?&page=��%=intPage-1%��"����һҳ��/a��
��%}%��
��!--��ʾ��һҳ������--��
��%if(intPage��intPageCount){%��
��a href="user.jsp?&page=��%=intPage+1%��"����һҳ��/a��
��%}%��
��!--��ʾδҳ������--��
��a href="user.jsp?&page=��%=intPageCount%��"��βҳ��/a��
*****************************************************************************************
ʮ�ˡ���θ������ݱ��еļ�����ϵ�ó��ļ��ľ���·����
*****************************************************************************************
1.˼·�������ݿ��У��������ü����ķ�ʽ��ʾһ���ļ���·��������Ŀ¼�ı��б�������֮��Ӧ�ĸ� Ŀ¼��id��name��ÿ�θ����ļ��IJ�δ���Ӧ�ı��л�ȡ��һ��Ŀ¼�����ƣ�����·���ָ� �������ϵ�ǰ��Ŀ¼���ƾͿ��Եõ��ļ��ľ���·���ˣ�ѭ��ֱ������Ŀ¼����
2.���裺
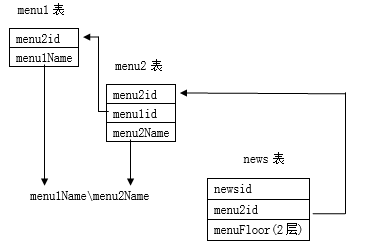
3.���룺
if(menufloor.equals("2")){
//��menu2���л�ȡmenu2id����news����menu2id�ļ�¼��menu2Name
menuname = myBean.toName("menu2","id","name",menuid);
//��menu2���л�ȡmenu2id����news����menu2id�ļ�¼��menu1id
menuid = myBean.toID("menu2","id","id1",menuid) + "";
//��menu1���л�ȡmenu1id����menu2����menu1id��¼��menu1Name
menuname = myBean.toName("menu1","id","name",menuid)+ "\\" + menuname;
}
*****************************************************************************************
ʮ�š���ζ�̬����ʾ…��ֵ��
*****************************************************************************************
��% for(int i = 0;i ����%=city[i]%�� ��% } %��
*****************************************************************************************
��ʮ�������JSP��ʵ�����������б����������
*****************************************************************************************
1.˼·��Ҫʵ�����������б��������������ʹ�������б����onChange�¼������û�ѡ���˵�һ�������б����ij��ѡ��ʱ�ͻᴥ��onchange�¼�����ʱҪ�Ƚ�ԭ���ڶ����б����е��� ��ѡ������գ��ڽ���һ���б���ѡ��������Ӧ������Ŀ���ӵ��ڶ����б�����
2.���룻
*****************************************************************************************
��ʮһ�������ҳ���ж�̬������ͼƬ�ȵ���������ӣ�
*****************************************************************************************
1.˼·��Ҫʵ����ͼƬ�϶�̬�趨�ȵ���������ӣ���Ҫ������ԱԤ�ȶ���ͼƬ���ȵ����꣬�����ݿ���������ļ�����ʽ���룬�ڼ���ҳ���ʱ������ݿ��л��������ļ��ж�ȡ�ȵ���������� ʹ��(����shape��ʾ�ȵ������ ��״��coords��ʾ�ȵ���������꣬href��ʾ�ȵ����������)
2.���裺
A.����ҳ��ʱ�ȶ���ͼƬ
B.�����ݿ��ж�ȡ�ȵ����������ֵ
C.�����ȵ�����
3.���룺
��!--����һ���˵���ͼƬ������ʹ��ͼƬӳ��--��
��img src="../images/left.gif" usemap="#Map" width="161" height="401" border="0"��
//��ȡһ���˵������в˵����id���ȵ����ӵ�����
public Vector getMenu1List()
{
String sql = "select id,rect from menu1 where isuse='1' order by id";
return getDataBySql(sql);
}
��!--һ���˵���ͼ��ӳ��--��
��map name="Map"��
��%
Vector v1 = myBean.getMenu1List();
for(int i=0;i��v1.size();i++){
Hashtable h = (Hashtable)v1.get(i);
%��
��!--��ȡһ���˵�ͼƬ��ÿһ���ȵ���������--��
��area shape="rect" coords="��%=h.get("rect")%��" //��ȡ���ȵ����������ֵ
href="javascript:gomenu1('��%=h.get("id")%��');"�� //��ȡ����������Ķ���
��%}%��
��/map��
*****************************************************************************************
��ʮ���������ҳ���ж�̬�����ò˵���Ŀ��ͼƬ������ɫ���������ɫ��
*****************************************************************************************
1.˼·������Ԥ������N��ͼ��ͼƬ������˵���Ŀ�ĸ���С��N����ֱ��������ʾ���������N���� ����Ҫѭ����ȡͼƬ��ͬ�����˵���Ŀ������ɫ������Ҳ��N�����������N������ֱ�Ӱ�˳ ��������ɫ���������N������Ҫ����ѭ������
2.���裺
A.ȡ���ò˵��µ�������Ŀ�洢��Vector��
B.����ѭ��ÿ��ȡ��һ����Ŀ
C.���ݸ���Ŀ����ź�N֮��Ĺ�ϵȷ��Ҫ���õ�ͼƬ������ɫ��������ɫ
3.���룺
��%
//ȡ��menu2�������п��õĶ����˵���Ŀ
Vector v2 = myBean.getMenu2List();
if (v2.size()!=0){
%��
��table width="100%" border=0 cellspacing=0��
��tr��
��%
for(int i=0;i��v2.size();i++){
Hashtable h = (Hashtable)v2.get(i);
//���ݸ���Ŀ����źͻ���N�Ĺ�ϵȷ������ͼƬ�ͱ���ɫ
String img = "../upload/t"+(i+1)%4+".gif";
String bg = "../upload/t_"+(i+1)%4+".gif";
//���ݸ���Ŀ����źͻ���N�Ĺ�ϵȷ���������ɫ
String color = "#936b09"; //��һ��ͼƬ��������ɫ
if ((i+1)%4==2) color = "#0C4699"; //�ڶ���ͼƬ��������ɫ
if ((i+1)%4==3) color = "#58B8DA"; //������ͼƬ��������ɫ
if ((i+1)%4==0) color = "972B9A"; //������ͼƬ��������ɫ
//����Ŀ����Ÿպ���N�ı���
if (img.equals("../upload/t0.gif")){
img = "../upload/t4.gif";
bg = "../upload/t_4.gif";
}
%��
��td background="��%=img%��" height=24 width=21����/td��
��td background="��%=bg%��" height=24 clor:��%=color%������%=h.get("name")%����/td��
��%}%��
��/tr��
��/table��
��%}%��
*****************************************************************************************
��ʮ��������ڶ�㼶���˵�����ʾ���£�
*****************************************************************************************
1.˼·��������N��IJ˵����û�Ҫ�鿴��ص����£�����ͨ����ѡ���²�˵�ֱ������N���
����Ϊ��ʹ���û�ÿ�ε����i��IJ˵�ʱ������Ӧ��������ʾ��������ÿһ��IJ˵�����һ ƪ������֮���Ӧ�����û�����˵�ʱ������ʾ��ƪ��Ӧ�����£�����û�ѡ��ò˵�����Ӧ ���Ӳ˵���������ʾ��Ӧ������
���⣬�û�������ͨ������ҳ��ij��������ӵ���ǰҳ�棬��ʱ����IJ���ֻ�����µ�id����û�в˵��IJ�κ�id�������ͨ�������ݿ��в��Ҹ����¶�Ӧ�IJ˵�id�����ȷ��Ҫ��ʾ ��ҳ��
2.���裺
A.�û����ij�˵�ʱ����JS���ڣ��Ե�ǰ�˵�id���и�ֵ���ύ����
B.��ȡ�û�����IJ˵���id
C.���ݲ˵���id��ȡ��ò˵���Ӧ����������
D.�������µ����ݰ�������ǰҳ����
E.����Ǵ�����ҳ�����Ӷ�������������µ�id��ȡ��Ӧ�IJ˵�id���������ʾ��Ӧҳ��
3.���룺
DealString ds = new DealString();
String menu1id = ds.toString(request.getParameter("menu1id"));
String menu2id = ds.toString(request.getParameter("menu2id"));
String menu3id = ds.toString(request.getParameter("menu3id"));
String child = ds.toString(request.getParameter("child"));
//�״����Ĭ��Ϊ1���˵���ֱ����ʾһ���˵��µ�����
if(menu1id.equals(""))menu1id="1";
if(!child.equals("")) {��//ͨ����ҳ���ڲ������Ӷ�λ����search.jsp
//������ҳ�����Ӵ��ݶ����IJ���ֻ��child��Ҫ�������µ����ƻ�ȡ���Ӧ��Ŀ¼������
String menufloor = myBean.toName("art","file","menufloor",child);
String menuid = myBean.toName("art","file","menuid",child);
//һ��
if(menufloor.equals("1")){
menu1id = menuid;
menu2id = "";
menu3id = "";
}
//����
if(menufloor.equals("2")){
menu2id = menuid;
menu1id = myBean.toName("menu2","id","id1",menu2id);
menu3id = "";
}
//����
if(menufloor.equals("3")){
menu3id = menuid;
menu2id = myBean.toName("menu3","id","id2",menu3id);
menu1id = myBean.toName("menu2","id","id1",menu2id);
}
}
else
{ //ͨ���˵���λ���絥��һ���������������˵��������¼�
//ֱ����ʾ�ҿ�����Ӧ�˵��µ�����
if(!menu1id.equals("")&&menu2id.equals("")){��//ֻ��һ��
child = myBean.toName("menu1","id","href",menu1id);
}
if(!menu2id.equals("")&&menu3id.equals("")){��//ֻ�ж���
child = myBean.toName("menu2","id","href",menu2id);
}
if(!menu3id.equals("")){��//ֻ������
child = myBean.toName("menu3","id","href",menu3id);
}
}
%��
*****************************************************************************************
��ʮ�ġ��������Collection��List��Set��Map�Ŀ�ܺͼ�飺
*****************************************************************************************
1.��ܣ�
Collection
|-List
| |-LinkedList
| |-ArrayList
| |-Vector
| |-Stack
|-Set
Map
|-Hashtable
|-HashMap
2.��飺
A.Collection�ӿڣ�
һ��Collection�ӿڴ���һ��Object��JDK���ṩֱ�Ӽ̳���Collection���࣬JDK�ṩ�� ��Ǽ̳���Collection��“�ӽӿ�”����:List��Set���ࡣ��֧��һ��iterator()�ķ� �����÷�������һ�������ӣ�ʹ�øõ����Ӽ�����һ����Collection�е�ÿһ��Ԫ�ء�
B.List�ӿڣ�
List�������Collection��ʹ������ӿ��ܹ���ȷ�Ŀ���ÿ��Ԫ�ز����λ�á��û��ܹ�ʹ ������������List�е�Ԫ�أ����˾���Collection�ӿڱر���iterator()�����⣬List�� �ṩ��һ��listIterator()����������һ��ListIterator�ӿڣ�������һЩadd()֮��ķ� �����������ӣ�ɾ�����趨Ԫ�أ�������ǰ����������
C.Set�ӿڣ�
Set�ӿ���һ�ֲ������ظ�Ԫ�ص�Collection�������������Ԫ��e1��e2����e1.equals(e2) Ϊ�٣�Set�����һ��nullԪ�ء������ԣ�Set�Ĺ��캯����һ��Լ�������������Collection �������ܰ����ظ���Ԫ�أ�ÿ�������Setʵ����������Ӷ����equals()���������һ ����
D.Map�ӿڣ�
Map�ṩ��Key��Value��ӳ�䣬һ��Map�в����ܰ� ����ͬ��Key,ÿ��Keyֻ��ӳ��һ�� Value��
*****************************************************************************************
��ʮ�塢LinkedList�ࡢArrayList�����������ó��ϣ�
*****************************************************************************************
1.LinkedList�ࣺ
LinkedList��ʵ����List�ӿڣ�����nullԪ�أ����Ա�������ջ�����л���˫����У���ͬ��
2.ArrayList�ࣺ
ArrayListʵ���˿ɱ��С�����顣����������Ԫ�أ�����null��ArrayList�Ƿ�ͬ���ģ�ÿ�� ArrayListʵ������һ������(Capacity)�������ڴ洢Ԫ�ص�����Ĵ�С����������������Ų��� ������Ԫ�ض��Զ����ӡ�
3.��������ó��ϣ�
A.����IJ�������һ�����ݵ������������ݶ�������ǰ����м䣬������Ҫ����ķ������е�Ԫ�� ʱ��ʹ��ArrayList���ṩ�ȽϺõ�����
B.����IJ�������һ�����ݵ�ǰ����м����ӻ�ɾ�����ݣ���������˳���������е�Ԫ��ʱ���� Ӧ��ʹ��LinkedList
C.�������У�A��B��������������������ǣ����Կ���ʹ��List������ͨ�ýӿ��������ù��� �������ʵ�֣��ھ���������£����������ɾ����ʵ������֤
*****************************************************************************************
��ʮ����Vector�ࡢStack���ʹ�ã�
*****************************************************************************************
1.Vector�ࣺ
Vector�dz�������ArrayList������Vector��ͬ��������Vector������Iterator����Ȼ��ArrayList ������Iterator��ͬһ�ӿڣ�������ΪVector��ͬ���ģ���һ��Iterator�������������ڱ�ʹ �ã���һ���̸߳ı���Vector��״̬(�������ӻ�ɾ����һЩԪ��)����ʱ����Iterator�ķ����� �׳�ConcurrentModificationException����˱��벶����쳣��
2.Stack�ࣺ
Stack�̳���Vector,ʵ����һ������ȳ��Ķ�ջ��Stack�ṩ��5������ķ���ʹ��Vector���� ��������ջʹ�á�������push��pop����������peek�����õ�ջ����Ԫ�أ�empty��������ջ �Ƿ�Ϊ�գ�search�������һ��Ԫ���ڶ�ջ�е�λ�á�Stack�մ������ǿ�ջ
*****************************************************************************************
��ʮ�ߡ�Hashtable�ࡢHashMap�����������ó��ϣ�
*****************************************************************************************
1.Hashtable�ࣺ
Hashtable�̳�Map�ӿڣ�ʵ��һ��key-valueӳ��Ĺ�ϣ�����κηǿյĶ�������Ϊkey�� ��value������������put(key,value)��ȡ��������get(key)��Hashtable��ͬ����
2.HashMap�ࣺ
HashMap��Hashtbale���ƣ���֮ͬ������HashMap�Ƿ�ͬ���ģ���������null��key,value
3.��������ó��ϣ�
A.Hashtable��ͬ���ģ��Ҳ�����nullԪ��
B.HashMap�Ƿ�ͬ���ģ�������nullԪ�ء�
*****************************************************************************************
��ʮ�ˡ�Vector��ArrayList������
*****************************************************************************************
1�� Vector�ķ�����ͬ����(Synchronized)���̰߳�ȫ��(thread-safe)����ArrayList�ķ������ǣ������̵߳�ͬ����ȻҪӰ�����ܣ����ArrayList�����ܱ�Vector�á�
2.����Vector��ArrayList�е�Ԫ�س������ij�ʼ��Сʱ��Vector�Ὣ����������������ArrayList ֻ����50%�Ĵ�С������ArrayList�������ڽ�Լ�ڴ�ռ�
*****************************************************************************************
��ʮ�š�ʲôʱ����Ҫʹ�ö��̵߳�ͬ����
*****************************************************************************************
ֻҪ�ڼ����߳�֮�乲���� final �������ͱ���ʹ�� synchronized���� volatile����ȷ��һ���߳̿��Կ�����һ���߳����ĸ��ġ��ɼ���ͬ���Ļ�������������������б���ͬ����
· ��ȡ��һ�ο���������һ���߳�д��ı���
· д����һ�ο�������һ���̶߳�ȡ�ı���
ͬ����final �ֶζ����߳�Ҳ���Ѻá���Ϊ final �ֶ��ڳ�ʼ��֮�����ǵ�ֵ�Ͳ��ܸ��ģ�����
�����߳�֮�乲�� final �ֶ�ʱ������Ҫ����ͬ����
*****************************************************************************************
��ʮ��ʲôʱ����Ҫʹ�ö��̵߳�ͬ����
*****************************************************************************************
��ijЩ����У���������ͬ���������ݴ�һ���̴߳��ݵ���һ������Ϊ JVM �Ѿ�������Ϊ��ִ��ͬ
���������������
· �ɾ�̬��ʼ�������ھ�̬�ֶ��ϻ� static{} ���еij�ʼ��������ʼ������ʱ
· ���� final �ֶ�ʱ
· �ڴ����߳�֮ǰ��������ʱ
· �߳̿��Կ�������Ҫ�����Ķ���ʱ
*****************************************************************************************
��ʮһ��ʹ��Synchronized��ԭ��
*****************************************************************************************
·��ʹ����鱣�ּ�̡�Synchronized ��Ӧ�ü�� — �ڱ�֤������ݲ����������Ե�ͬʱ�������� �̡��Ѳ����̱߳仯��Ԥ�����ͺ����Ƴ� synchronized �顣
· ��Ҫ��������Ҫ�� synchronized ����е��ÿ������������ķ�������InputStream.read()��
· �ڳ�������ʱ��Ҫ������������÷�������������������Щ���ˣ����������������������
*****************************************************************************************
��ʮ����Java���̵߳ij���API��
*****************************************************************************************
1. sleep() ������
sleep() ����ָ���Ժ���Ϊ��λ��һ��ʱ����Ϊ��������ʹ���߳���ָ����ʱ���ڽ�������״̬�����ܵõ�CPU ʱ�䣬ָ����ʱ��һ�����߳����½����ִ��״̬�����͵أ�sleep() �����ڵȴ�ij����Դ���������Σ����Է�����������������߳�����һ��ʱ������²��ԣ�ֱ����������Ϊֹ��
2. suspend() �� resume() ������
������������ʹ�ã�suspend()ʹ���߳̽�������״̬�����Ҳ����Զ��ָ����������Ӧ��resume() �����ã�����ʹ���߳����½����ִ��״̬�����͵أ�suspend() �� resume() �����ڵȴ���һ���̲߳����Ľ�������Σ����Է��ֽ����û�в��������߳���������һ���̲߳����˽������ resume() ʹ��ָ���
3. yield() ������
yield() ʹ���̷߳�����ǰ�ֵõ� CPU ʱ�䣬���Dz�ʹ�߳����������߳��Դ��ڿ�ִ��״̬����ʱ�����ٴηֵ� CPU ʱ�䡣���� yield() ��Ч���ȼ��ڵ��ȳ�����Ϊ���߳���ִ�����㹻��ʱ��Ӷ�ת����һ���̡߳�
4. wait() �� notify() ������
������������ʹ�ã�wait() ʹ���߳̽�������״̬������������ʽ��һ������ָ���Ժ���Ϊ��λ��һ��ʱ����Ϊ��������һ��û�в�����ǰ�ߵ���Ӧ�� notify() �����û��߳���ָ��ʱ��ʱ�߳����½����ִ��״̬������������Ӧ�� notify() �����á�
*****************************************************************************************
��ʮ����wait()��notify()��suspend()��resume()����������
*****************************************************************************************
��������wait()��notify()�� suspend() �� resume() ������û��ʲô�ֱ𣬵�����ʵ�������ǽ�Ȼ��ͬ�ġ�����ĺ������ڣ�ǰ�����������з���������ʱ�������ͷ�ռ�õ��������ռ���˵Ļ���������һ�Է������෴��
�����ĺ�����������һϵ�е�ϸ���ϵ�����
�������ȣ�ǰ�����������з����������� Thread �࣬������һ��ȴֱ�������� Object �࣬Ҳ����˵�����ж���ӵ����һ�Է���������������ʮ�ֲ���˼�飬����ʵ����ȴ�Ǻ���Ȼ�ģ���Ϊ��һ�Է�������ʱҪ�ͷ�ռ�õ������������κζ����еģ������������� wait() ���������߳����������Ҹö����ϵ������ͷš���������������notify()������������øö���� wait() �������������߳������ѡ���һ�������������Ҫ�ȵ���������������ִ�У���
������Σ�ǰ�����������з����������κ�λ�õ��ã�������һ�Է���ȴ������ synchronized ��������е��ã�����Ҳ�ܼ�ֻ����synchronized ��������е�ǰ�̲߳�ռ�����������������ͷš�ͬ���ĵ�����������һ�Է����Ķ����ϵ�������Ϊ��ǰ�߳���ӵ�У����������������ͷš���ˣ���һ�Է������ñ�������������� synchronized ��������У��÷�����������������ǵ�����һ�Է����Ķ�������������һ�������������Ȼ���ܱ��룬��������ʱ�����IllegalMonitorStateException �쳣��
����wait() �� notify() �������������Ծ��������Ǿ�����synchronized �������һ��ʹ�ã������ǺͲ���ϵͳ�Ľ��̼�ͨ�Ż�����һ���ȽϾͻᷢ�����ǵ������ԣ�synchronized��������ṩ�������ڲ���ϵͳԭ��Ĺ��ܣ����ǵ�ִ�в����ܵ����̻߳��Ƶĸ��ţ�����һ�Է������൱�� block ��
wakeup ԭ���һ�Է���������Ϊ synchronized�������ǵĽ��ʹ�����ǿ���ʵ�ֲ���ϵͳ��һϵ�о���Ľ��̼�ͨ�ŵ��㷨�����ź����㷨���������ڽ�����ָ��ӵ��̼߳�ͨ�����⡣
������ wait() �� notify() ���������˵�����㣺
������һ������ notify() �������½���������߳��Ǵ�����øö���� wait() �������������߳������ѡȡ�ģ�������Ԥ����һ���߳̽��ᱻѡ�����Ա��ʱҪ�ر�С�ģ����������ֲ�ȷ���Զ��������⡣
�����ڶ������� notify()������һ������ notifyAll() Ҳ�����������ã�Ψһ���������ڣ����� notifyAll() ������������øö���� wait() �����������������߳�һ����ȫ�������������Ȼ��ֻ�л��������һ���̲߳��ܽ����ִ��״̬��
����̸���������Ͳ��ܲ�̸һ̸��������һ�������ܷ��֣�suspend() �����Ͳ�ָ����ʱ���� wait() �����ĵ��ö����ܲ����������ź����ǣ�Java ���������Լ�����֧�������ı��⣬�����ڱ���б���С�ĵر���������
*****************************************************************************************