数据分析
实验指导书
理学院实验中心
数学专业实验室编写
实验一 SAS系统的使用
【实验类型】(验证性)
【实验学时】2学时
【实验目的】 使学生了解SAS系统,熟练掌握SAS数据集的建立及一些必要的SAS语句。
【实验内容】
1. 启动SAS系统,熟悉各个菜单的内容;在编辑窗口、日志窗口、输出窗口之间切换。
2. 建立数据集
表1

1)通过编辑程序将表1读入数据集sasuser.score;
2)将下面记事本中的数据读入SAS数据集,变量名为code name scale share price:
000096 广聚能源 8500 0.059 1000 13.27
000099 中信海直 6000 0.028 2000 14.2
000150 ST麦科特 12600 -0.003 1500 7.12
000151 中成股份 10500 0.026 1300 10.08
000153 新力药业 2500 0.056 2000 22.75
3)将下面Excel表格中的数据导入SAS数据集work.gnp;
4)使用VIEWTABLE格式新建数据集earn,输入如表所示数据
Year earn
1981 125000
1982 136000
1983 122350
1984 65200
1985 844600
1986 255000
1987 265000
1988 280000
1989 136000
3. 将sasuser.score数据集的内容复制到一个临时数据集test,要求只包含变量name, sex, math。
4.将sasuser.score数据集中的记录按照math的高低拆分到3个不同的数据集:math大于等于90的到good数据集,math在80到89之间的到normal数据集,math在80以下的到bad数据集。
5.将4题中得到的数据集good,normal,bad合并为数据集combine,并将数据集combine按照数学成绩排序,然后打印排序后的数据集。
【实验报告要求】1. 写出2. 1) 2) 3), 3,4,5的程序设计;
2. 附上5题打印程序运行的结果。
【实验方法或步骤】
1.SAS系统的启动:2种方法
1)双击桌面上的SAS快捷方式;
2)单击屏幕左下角的“开始”菜单,在菜单中选择“程序”,在程序中选择The SAS System,最后选择The SAS System for Windows V8。
2.数据的输入与输出
1)在SAS程序窗口下,直接输入数据以建立一个SAS数据集,其基本语句形式为:

输出数据集的内容,可用

2)将其他格式的数据文件导入数据集.
3.能够利用已有的SAS数据集建立新的SAS数据集
1)两个数据集的合并
两数据集的串接:将A和B两个数据集串接成为一个名为“name”的新的SAS数据集.

两数据集的并接:若两个数据集的数据行数(即观测向量个数)相同且按相同顺序排列,可将两数据集并接以形成新的SAS数据集,其中数据集中变量的个数为原两数据集中的变量个数之和.

2)两个数据集的复制

3)两个数据集的拆分
示例:将记录学生成绩的//数据集按性别分成两个数据集,即一个记录男生的成绩,一个记录女生的成绩。程序如下:
Data scorem scoref;
Set sasuser.score;
Select (sex);
When (‘m’) output scorem;
When (‘f’) output scoref;
End;
Run;
实验二 1991年全国各省、区、市城镇居民
月平均收入的数据分析
【实验类型】(综合性)
【实验学时】6学时
【实验目的】通过对1991年全国各省、区、市城镇居民月平均收入进行数据描述性分析、判别分析、聚类分析和主成分分析,培养和提高学生应用统计软件SAS分析处理数据的能力,为以后的学习及应用打下良好的基础。
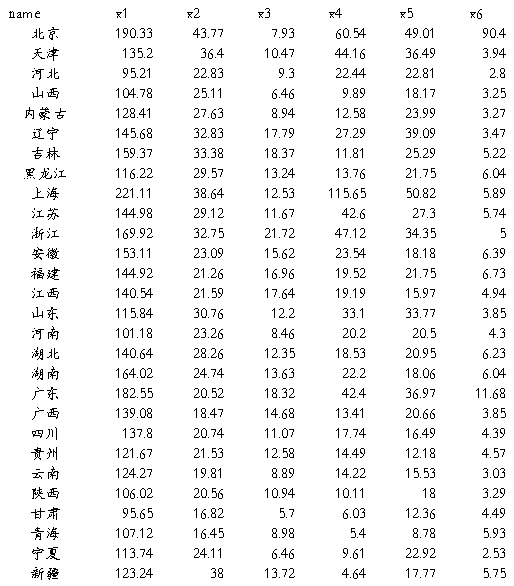
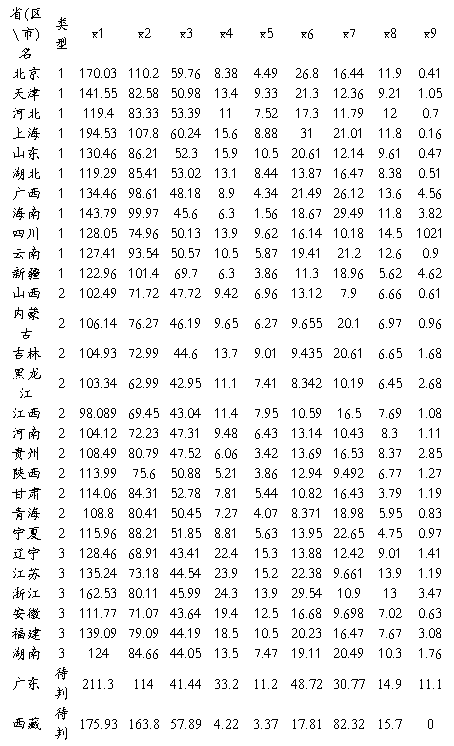
【实验内容】1991年全国各省、区、市城镇居民月平均收入情况见下表,变量含义如下:X1-人均生活费收入(元/人);X2-人均全民所有制职工工资(元/人);X3-人均来源于全民标准工资(元/人);X4-人均集体所有制工资(元/人);X5-人均集体职工标准工资(元/人);X6-人均各种奖金及超额工资(元/人);X7-人均各种津贴(元/人);X8-职工人均从工作单位得到的其他收入(元/人);X9-个体劳动者收入(元/人)。
1、对变量x1作如下计算:
1)计算均值、方差、标准差、变异系数、偏度、峰度;
2)计算中位数,上、下四分位 数,四分位极差,三均值;
3)作出直方图;
4)作出茎叶图;
5)进行正态性检验(正态W检验);
6)计算协方差矩阵,Pearson相关矩阵;
7)计算Spearman相关矩阵;
8)分析各指标间的相关性。
2、1)判定广东、西藏两省区属于哪种收入类型,并用回代法及交叉确认法对误判率作出估计。
2)进行Bayes判别,并用回代法与交叉确认法验证判别结果。
3、1)用最短距离法、最长距离法与类平均法聚类,画出谱系图,并写出分3类的结果;
2)快速聚类法聚类,并写出分3类的结果。
4、1)求前两个标准化主成分及其累计贡献率;
2)解释1)中两个主成分的意义;
3)基于第一样本主成分的得分对各地区排序,这与你从原始数据得到的直观看法是否基本吻合?
【实验前的预备知识】
1、SAS系统的使用;
2、1)数据的数字特征:均值、方差、中位数、三均值与极差等;
2)数据的分布:直方图、茎叶图、箱线图、正态性检验等;
3)多元数据的数字特征与相关性分析:均值向量与协方差矩阵等。
3、1)距离判别的原理及判别准则的评价;
2)Bayes判别的原理;
3)逐步判别;
4、1)样品间的相似性度量——距离和变量间的相似性度量——相似系数;
2)谱系聚类法:最短距离法、最长距离法、类平均法、重心法、中间距离法和WARD最小方差法等;
3)快速聚类法:
5、1)总体主成分的定义、求法、性质和标准化变量的主成分;
2)样本主成分。
【实验方法或步骤】
1、1)PROC MEANS过程

其中“options”包含下列内容的部分或全部:
a. DATA=SAS data set:指明所要分析的SAS数据集名称.若省略此选项,则对最新建立的数据集作分析.
b. MAXDEC= :其中为介于0与8之间的一个正整数,该选项指明在输出数据时小数点后保留位.
:其中为介于0与8之间的一个正整数,该选项指明在输出数据时小数点后保留位.
c. 关键词:逐个列出要计算其值的统计量名称的关键词,最常用的有N(变量的观测值个数)、MEAN(均值)、STD(标准差)、VAR(方差)、MIN(各变量观测值的最小值)、MAX(各变量观测值的最大值)、RANGE(极差)、SUM(总和)、USS(平方和)、CSS(中心化平方和)、SKEWNESS(偏度)、KURTOSIS(峰度)、T(对每个变量的均值是否为零进行双边 检验)、PRT(双边的
检验)、PRT(双边的 值).
值).
2)PROC UNIVARIATE 过程

其中“options”包含下列内容的部分或全部:
a. DATA=SAS data set:指明所要分析的SAS数据集名称.
b. PLOT:要求对所分析的各变量的观测值产生一个茎叶图(或水平直方图)、一个箱线图和一个正态QQ图.若某区间的观测值超过48,则不绘制茎叶图,而改绘水平直方图,在正态QQ图中,以“*”号标示正态QQ图上的点,以“+”标示相应的参考直线.
c. FREQ:要求生成包括变量值、频数、百分数和累计百分数的表.
d. NORMAL:要求对分析的各变量的观测值是否来自正态分布总体做检验,并输出检验的值.
3)PROC CORR 过程

其中“options”包含下列内容的部分或全部:
a. DATA=SAS data set:指明所要分析的SAS数据集名称.
b. PEARSON:要求输出Pearson相关系数矩阵(为默认输出结果).
c. SPEARMAN:要求输出Spearman秩相关系数矩阵.
d. COV:要求计算协方差矩阵.
e. NOSIMPLE:指明不输出每个变量的简单描述性统计量的值.
VAR variables:该语句指出要计算相关系数矩阵或协方差阵的变量名称,可以是数据集中数值变量的一部分.
WITH variables:此语句和“VAR variables”语句合用,可以得到变量间特殊组合的相关系数矩阵,即“VAR”后的各变量与“WITH”后的各变量间的相关系数矩阵。
2、判别分析过程
▲ 分类判别

(1)PROC DISCRIM options;
此语句中,“options”部分可包含下列内容:
1)待分析的数据集选择:
①DATA=SAS data set:指定用以建立判别函数的SAS数据集(即训练样本数据集).若省略此句,则最新建立的数据集被用于建立判别函数.
②TESTDATA:SAS data set:指定用以检验判别准则的SAS数据集名称,除分类变量外,该数据集中的变量应和训练样本数据集中的变量一致.
2)输出数据集的选择:
①OUTSTAT=SAS data set:定义一个输出SAS数据集名称,该数据集中包括原训练样本集中各变量的均值、标准差及相关系数等.若METHOD:NORMAL(见后)被使用,该数据集中还包括判别函数的系数.
②OUT=SAS data set:命名一个输出SAS数据集,其中包括训练样本集的数据及变量、后验概率及回判结果.
⑧OUTCROSS=SAS data set:定义一个输出的SAS数据集,其中包括训练样本数据及变量、后验概率以及由交叉确认法所得的回判结果等.
④TESTOUT=SAS data set:定义一个输出的SAS数据集,其中包括检验数据集中的变量和数据、后验概率以及利用所建立的判别准则对检验数据集的判别结果.此项当“options”中有“TESTDATA:SAS data set”时运用.
3)判别分析方法的选择:
①METHOD=NORMAL(或NPAR):指出建立判别函数的方法.当“METHOD=NORMAL”被指定,则在各总体为正态分布的假定下通过利用训练样本估计各总体均值向量和协方差矩阵,并视各总体的协方差矩阵是否相等而分别建立线性及二次判别函数;当指定“METHOD=NPAR”,则使用非参数方法建立判别函数.前者是SAS系统默认的方法.
②POOL=YES(或NO,TEST):在选择"METHOD:NORMAL”的前提下,“POOL=YES”意味着假定各总体的协方差矩阵相等,而用各训练样本的样本协方差矩阵联合估计公共的协方差矩阵,这时建立的判别函数是线性的;若选择 “POOL=NO”,则意味着假定各总体的协方差矩阵不等而建立二次判别函数;“POOL=TEST"即要求首先利用修正的Bartlett似然比方法检验各总体的协方差矩阵是否相等,若检验结果在由语句“SLPOOL=p”(见后)所指定的显著水平p下显著,则建立二次判别函数,否则利用联合协方差矩阵估计建立线性判别函数.对线性判别函数,输出结果中才给出判别函数的系数.
③SLPOOL=p:指定检验协方差矩阵是否相等的显著水平.只有当选择 “POOL=TEST"时,才可出现此语句,若省去此语句,则SAS系统默认p:0.10,
4)回判结果输出选择:
①LIST:打印出每个样品的回判结果.
②LISTERR:仅打印出回判中判错的样品信息.
③NOCLASSIFY:不需要对训练样本数据作回判分析.
5)交叉确认法回判结果的输出选择:
当下列语句出现时,则交叉确认法被使用对训练样本作回判分析.
①CROSSVALIDATE:要求对训练样本数据集进行交叉确认回判分析.
②CROSSLISTERR:仅打印出使用交叉确认法判别而判错的样品信息.
⑧CROSSLIST:打印出每个样品的交叉确认法回判分析结果.
6)检验数据集判别结果的输出选择
①TESTLIST:列出对检验数据集的判别结果.
②TESTLISTERR:仅列出对检验数据集中判错的样品信息.
7)控制打印选择
①WCORR;打印各总体(组内)的训练样本相关矩阵.
②PCORR:打印由各总体的样本相关矩阵所得的联合相关矩阵估计.
类似地,WCOV,PCOV则要求打印出相应于①、②的训练样本协方差矩阵估计.
⑧ALL:打印出所有的相关结果.
④SHORT:只打印一些主要结果,
(2)CLASS variable;
其中的“variable”即描述各类别的变量名称.该变量可以是数值化的变量,也可以是非数值变量.该语句是进行判别分析所必需的语句.
(3)VAR variables;
其中“variables”即列出参与分析的描述各样品特征的变量名称,省略时即数据集中所有的数值变量.
(4)PRIORS probabilities;
此语句的功能即指出总体的先验概率分布.其中的“probabilities”应是下列三种选择之一:
1)EQUAL,即各总体的先验概率相等.
2)PROPORTIONAL(或PROP):即各总体的先验概率与各总体的训练样
本容量成比例,设有三个总体 ,训练样本容量分别为
,训练样本容量分别为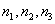 ,则各总体的先验概率分布为
,则各总体的先验概率分布为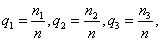 这里
这里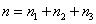 。
。
3)具体指定各总体的先验概率.通常有两种方式:
①若描述各总体类别的变量(即“CLASSvariable"中的变量)是非数值变量,则在各类取值后给出先验概率并用等号连起来.例如,描述各总体类别的变量 “GRADE”取A,B,C,D四个值(每个值代表一类总体),各总体先验概率分布为0.1,0.3,0.5和0.1,则“PRIORS”语句为
PRIORS A=0.1 B=0.3 C=0.5 D=0.1;
②若描述各总体类别的变量是数值化变量或者是小写字母时,这时要将这些值用“ ”引起来写在上式等号前.例如,若前述变量“GRADE”取值为1,2,3,4,则指定先验概率的语句形式应为
”引起来写在上式等号前.例如,若前述变量“GRADE”取值为1,2,3,4,则指定先验概率的语句形式应为
PRIORS  =0.1
=0.1 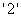 =0.3
=0.3 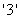 =0.5
=0.5  =0.1
=0.1
若“GRADE”的取值为a,b,c,d,则指定先验概率的语句应为
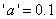
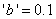
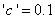
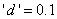
若指定的先验概率之和非1,则SAS系统自动用其和除各值而使各概率之和为1.
在以上三种指定总体出现的先验分布的形式中,“EQUAL”是SAS系统默认的形式.
(5)TESTCLASS variable;
其中“variable”是描述检验数据集中的各总体类别的变量名,它可以和原训练样本数据集中的类别变量相同,也可以不同,但二者必须是同类型的(即同为数值或非数值变量).若变量采用格式化输入,则二者的输入格式也应相同.
▲ 逐步判别——PROCSTEPDISC过程
PROCSTEPDISC过程用以逐步判别分析.逐步判别的思想和逐步回归类似,即通过逐个引入或剔除变量挑选判别力最强的变量.此过程用Wilks的A似然比统计量判断一个变量的判别能力的强弱.逐步判别包括向前选入,向后剔除和逐步选择三种方法,并且假定各总体均服从协方差矩阵相等的正态分布.该过程的主要语句形式为

①DATA=SAS data set:指定被分析的SAS数据集名称.
②METHOD=name:指定逐步判别的方法,其中的“name”可以是下列三种之一,即FORWARD(或FW),BACKWARD(或BW)及STEPWISE(或SW),分别表示向前选入,向后剔除和逐步选择方法.若省略此句,则默认方法为STEP—WISE.
③SLENTRY=level(或SLE=level):在向前选入方法中,指定选入变量的显著水平.默认值为level=0.15.
④SLSTAY=level(或SLS=level):在向后剔除方法中,指定保留变量的显著水平.默认值为level=0.15.对于STEPWISE方法,要同时指定SLENTRY和SLSTAY,通常取为相等.
⑤PR2ENTRY=level(或PR2E=level):在向前选择方法中,指定选入变量的R*R值·
⑥PR2STAY=level(或PR2S=level):在向后剔除方法中,指定保留变量的R’值.
除以上选项外还包括打印选项,如打印各总体的样本相关矩阵,联合样本相关矩阵及相应的样本协方差矩阵等等(与PROCDISCRIM过程相应选项基本相同).
(2)CLASS variable;
这—语句和"VAR variables”语句与PROC DISCRIM过程相应语句的用法完全相同。
3、聚类分析
▲ 谱系聚类法
PROC CLUSTER过程的基本语句为:

Options通常包括下面一些内容:
1) DATA=SAS data set:该语句指出要进行聚类分析的数据集名称,它可以是含个观测向量的原始数据集,也可以是“距离”矩阵(这时要在数据集名后加上(TYPE=DISTANCE).
2) OUTTREE=SAS data set;生成一个用于画聚类谱系图的输出数据集.
3) METHOD=name;指出具体使用的聚类方法.主要有:
a. SINGLE(或SIN):最短距离法.
b. COMPLETE(或COM): 最长距离法.
c. AVERAGE(或AVE):类平均法.
d. CENTROID(或CEN):重心法.
e. MEDIAN(或MED):中间距离法.
f. WARD(或WAR):WAR最小方差法.
4) NOSQUARE:阻止过程在METHOD=AVERAGE、CENTROID、MEDIAN或WARD方法中将输入的距离平方.
5) NONORM:阻止将距离规范化.
6) PSEUDO:要求打印伪F统计量及伪 统计量的值.只有当输入数据是原始观测数据(但“METHOD”选项不能是SIN)或者“METHOD”选项为AVE、CEN或WAR时,才可选此项.
统计量的值.只有当输入数据是原始观测数据(但“METHOD”选项不能是SIN)或者“METHOD”选项为AVE、CEN或WAR时,才可选此项.
7) RSQUARE(或RSQ):要求打印出 统计量和半偏相关统计量SPRSQ的值.当输入数据是原始观测数据且“METHED”选项是AVE或CEN时,才可选此项.
统计量和半偏相关统计量SPRSQ的值.当输入数据是原始观测数据且“METHED”选项是AVE或CEN时,才可选此项.
进一步若要画出聚类的谱系图,可用下列语句:

在“options”中除用DATA=SAS data set指定画图的SAS数据集名称外,可以是:
a. HORIZONTAL:表示谱系图水平放置.
b. VERTICAL:表示谱系图垂直放置.
c. SPACES= :表示ID变量值的间隔单位,这里是正整数.
:表示ID变量值的间隔单位,这里是正整数.
d. GRAPHICS:要求画高分辨率的聚类谱系图.
e. NCLUSTERS=:指定在输出分类结果数据集中所分成的类的个数.
f. OUT=SAS data set:按e中要求输出分类结果.
▲ 快速聚类法

Options通常包括下面一些内容:
a. MAXCLUSTER(或MAXC)=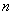 :指定所允许的最大分类个数.
:指定所允许的最大分类个数.
b. RADIUS=:为选择新的“聚点”指定的最小距离准则.
c. DATA=SAS data set:指出用以分析的SAS数据集名称,要求数据性质是原始观测数据.
d. MEAS=SAS data set:生成一个输出数据集,其中包括每个类的均值和其他统计量的值.
e. OUT=SAS data set:生成一个输出数据集,其中包括原始数据及两个新变量CLUSTER(用以指示观测属于哪个类的变量)和距离DISTANCE.
f. CLUSTER=name:规定在d和f的输出数据集中用以指示观测属于哪一类的变量名称.
g. DISTANCE:要求打印类均值之间的距离.
h. LIST:要求列出所有观测的ID变量值,观测所归入类的类号及观测与最终“聚点”之间的距离。
i. LEAST=:表明用 准则进行聚类,
准则进行聚类,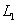 是绝对距离,LEAST=MAX是Chebyshev距离.
是绝对距离,LEAST=MAX是Chebyshev距离.
“VAR variables”和“ID variables”语句与PROC CLUSTER过程的相应语句用法相同.
4、主成分分析过程的主要语句形式为:

(1)PROC PRINCOMP options;
此语句意味着执行主成分分析,其中的“options”可包括以下内容的部分或全部:
①DATA=SAS data set:指出要分析的SAS数据集名称.这个数据集可以是原始观测值的SAS数据集,也可以是相关矩阵或协方差矩阵.若是后者,需要在数据集名称后加上“(TYPE=CORR)”或“(TYPE=COV)”.若省略数据集选项,则自动使用最新建立的SAS数据集.
②OUT=SAS data set:命名一个输出的SAS数据集,其中包含原始数据以及各主成分的得分(即各主成分的观测值).
⑧OUTSTAT=SAS data set:命名一个包含各变量的均值、标准差、相关矩阵或协方差矩阵、特征值和特征向量的输出SAS数据集.
④COVARIANCE(或COV):要求从协方差矩阵出发作主成分分析.若省略此选项,则从相关矩阵出发进行分析.除非各变量的度量单位是可比较的或已经过某种方式的标准化,否则不宜使用此选项,应从相关矩阵出发作主成分分析.
⑤N=n:指定要计算的主成分个数“n”.其默认值为参与分析的变量个数.
⑥PREFIX=name:规定各主成分的名称的前缀.省略此句则SAS系统自动赋予各主成分名称分别为PRIN1,PRIN2,….若“name=A”,则各主成分名称分别为A1,A2,….前缀的字符个数加上后面数字位数应不超过8个字符.
(2)VAR variables;
此语句中的“variables”部分列出数据集中参与主成分分析的变量名称.若省略此句,则被分析数据集中所有数值变量均参与分析.
【实验报告要求】
1. 简述实验原理;
2. 写出程序设计;
3. 按程序附上分析的结果,结合数据背景对结果给出合理的解释。