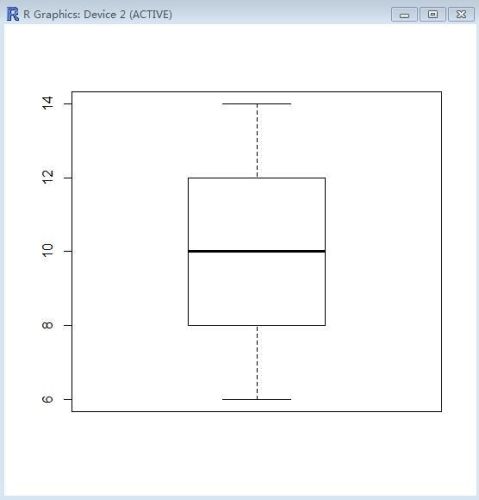
1、绘制 12,6,14,10,9,10,12,13,6,7,9 的箱线图、茎叶图。 解:运用R软件,在R Console中输入如下程序
> x<-c(12,6,14,10,9,10,12,13,6,7,9)
> stem(x)
得到如下结果,茎叶图如下所示:
The decimal point is at the |
6 | 000
8 | 00
10 | 00
12 | 000
14 | 0
下面对茎叶图作出如下解释:
第一个数6.0的个位数为6,十分位数为0,以十分位数为单位,将6—>6 | 0
每一个数都可以这样处理。
输入如下程序,得到箱线图如下所示:
> boxplot(x)
6.0用 | 号分开:
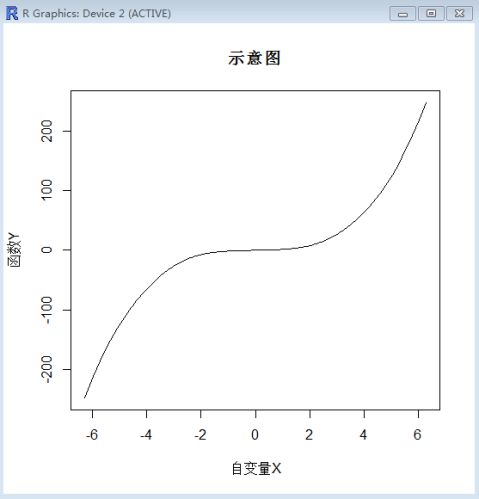
2、绘制y=x3 +sin(x)*cos(x)的函数图,并加注图例“自变量X”、“函数Y”、“示意图”. 解:运用R软件,在R Console中输入如下程序
x1<--100:100
x<- x1*2*pi/100
y<-x*x*x+sin(x)*cos(x)
plot(x,y,type="l",main="示意图", xlab="自变量X",ylab="函数Y")
得到y=x3 +sin(x)*cos(x)的函数图及其标注如下所示:
3、要定义y=f(x)为当x<0时取1-x,否则取1+x;x<-c(1,-3,6,40)
?1?x, x?0解:由题意知,该函数表达式为:y?f(x)?? ?1?x, x?0
故在R软件中输入以下程序:
> x<-c(1,-3,6,40)
> y<-numeric(length(x))
> y[x<0]<-1-x[x<0]
> y[x>=0]<-1+x[x>=0]
> y
软件运行结果如下:
[1] 2 4 7 41
即当x分别取值为1,-3,6和40时,得到的y值分别为2,4,7和41。
4、要定义y=f(x)为当x<3时取x, 3=<x<3.5时取x+10,否则取x+20;x <- c(0.5,-1,1,2,3,4,1,2,3,4); 求y.
?
解:由题意知,该函数表达式为:y?f(x)??x , x?3
?x?10, 3?x?3.5
??x?20, x?3.5
故在R软件中输入以下程序:
> x<-c(0.5,-1,1,2,3,4,1,2,3,4)
> y<-numeric(length(x))
> y[x<3]<-x[x<3]
> y[x>=3&x<3.5]<-10+x[x>=3&x<3.5]
> y[x>=3.5]<-20+x[x>=3.5]
> y
软件运行结果如下:
[1] 0.5 -1.0 1.0 2.0 13.0 24.0 1.0 2.0 13.0 24.0
即当x分别取值为0.5,-1,1,2,3,4,1,2,3和4时,得到的y值分别为0.5,-1.0,1.0,2.0,13.0 ,24.0,1.0,
(1)写出元素为3, -1.5, 3E-10的向量。
> x<-c(3,-1.5,3E-10)
> x
[1] 3.0e+00 -1.5e+00 3.0e-10
,13.0和24.0。 2.0
(2) 写出从3开始每次增加3,长度为100的向量。
> seq(from=3, length=100, by=3)
[1] 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48 51 54 57 60 63 66 69 72 75 78 81 84 87 90 93 96 99 102 105 108 111 114 117 120 123 126
[43] 129 132 135 138 141 144 147 150 153 156 159 162 165 168 171 174 177 180 183 186 189 192 195 198 201 204 207 210 213 216 219 222 225 228 231 234 237 240 243 246 249 252
[85] 255 258 261 264 267 270 273 276 279 282 285 288 291 294 297 300
(3) 写出(0, 2)重复10次的向量。
> x<-c(0,2)
> rep(x,10)
[1] 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2
(4) 对向量x,写出其元素大于等于0小于1的条件。
其中x取任意值
> x<-c(-1,-7,-5,8,4,3,0,0.8,0.5,0)
> x[x>=0&x<1]
[1] 0.0 0.8 0.5 0.0
(5) 对向量x,写出其元素都等于0的条件。
其中x取任意值
> x<-c(-1,-7,-5,8,4,3,0,0.8,0.5,0)
> x[x==0]
[1] 0 0
(6) 写出包含12个月份名称的向量。
>x<-c("January","Feburary","March","April","May","June","July","Augest","September","Octobor","November","December") > x
[1] "January" "Feburary" "March" "April" "May" "June"
[7] "July" "Augest" "September" "Octobor" "November" "December"
(7) 写出包含方程 6 的根的向量,并写出其幅角的余弦和正弦值。
> x <- polyroot(c(-1,0,0,0,0,0,6) ); cos(Arg(x)) ; sin(Arg(x))
[1] 0.5 -0.5 -0.5 1.0 -1.0 0.5
[1] 8.660254e-01 8.660254e-01 -8.660254e-01 -7.742076e-17 -1.224606e-16
[6] -8.660254e-01
2. 设x为一个长100的整数向量。比如,x <- floor(10*runif(100))。
(1) 显示x第21到30号元素。
> x <- floor(10*runif(100))
> x[21:30]
[1] 1 6 8 5 4 4 9 7 7 3
(2) 把x第31,35,39号元素赋值为0。
> x[31] <- 0 ; x[ 35 ] <- 0 ; x[ 39 ] <- 0;
> x[31]
[1] 0
> x[35]
[1] 0 z?1
> x[39]
[1] 0
(3) 显示x中除了第1号和第50号的元素之外的子集。
> x <- floor(10*runif(100))
> y<-c(x[2:49],x[50:100])
> y
[1] 0 8 8 7 1 2 5 0 8 8 2 8 1 3 8 9 0 7 7 9 6 6 5 0 7 1 9 4 4 8 9 9 2 3 0 5
[37] 3 1 5 2 0 5 4 4 3 3 3 2 4 3 8 4 8 6 9 5 5 7 9 9 4 1 4 3 5 6 3 8 1 2 7 4
[73] 0 7 8 8 8 0 2 6 2 2 4 0 8 8 3 1 7 3 4 2 1 0 8 8 0 7 3
(4) 列出x中个位数等于3的元素。
> x <- floor(10*runif(100))
> subset(x,x %% 10 == 3 )
[1] 3 3 3 3 3 3 3 3
(5) 列出x中个位数等于3的元素的下标位置。
> x <- floor(10*runif(100))
> for( i in 1 : length(x) ){ if( x[ i ] %% 10 == 3 ){print(i)} }
[1] 25
[1] 30
[1] 42
[1] 64
[1] 77
[1] 83
[1] 95
(6) 给x的每一个元素加上名字,为x1到x100。
> names(x) <- paste("x",1:100,sep= "" )
> names(x)
[1] "x1" "x2" "x3" "x4" "x5" "x6" "x7" "x8" "x9" "x10"
[11] "x11" "x12" "x13" "x14" "x15" "x16" "x17" "x18" "x19" "x20"
[21] "x21" "x22" "x23" "x24" "x25" "x26" "x27" "x28" "x29" "x30"
[31] "x31" "x32" "x33" "x34" "x35" "x36" "x37" "x38" "x39" "x40"
[41] "x41" "x42" "x43" "x44" "x45" "x46" "x47" "x48" "x49" "x50"
[51] "x51" "x52" "x53" "x54" "x55" "x56" "x57" "x58" "x59" "x60"
[61] "x61" "x62" "x63" "x64" "x65" "x66" "x67" "x68" "x69" "x70"
[71] "x71" "x72" "x73" "x74" "x75" "x76" "x77" "x78" "x79" "x80"
[81] "x81" "x82" "x83" "x84" "x85" "x86" "x87" "x88" "x89" "x90"
[91] "x91" "x92" "x93" "x94" "x95" "x96" "x97" "x98" "x99" "x100"
(7) 求x的平均值并求每一个元素减去平均值后的离差,计算x元素的平方和及离差平方和。 > x <- floor(10*runif(100))
> mean(x)
[1] 4.73
> x-mean(x)
[1] 1.27 2.27 1.27 2.27 -2.73 -0.73 -3.73 -4.73 3.27 -1.73 -4.73
[12] 4.27 0.27 1.27 2.27 1.27 -1.73 4.27 2.27 -3.73 2.27 1.27
[23] 3.27 3.27 0.27 4.27 -0.73 1.27 4.27 2.27 -0.73 -1.73 -2.73
[34] 3.27 -3.73 3.27 -3.73 -1.73 0.27 -3.73 3.27 -1.73 0.27 4.27
[45] 2.27 1.27 2.27 -4.73 -3.73 -2.73 -2.73 0.27 -2.73 -2.73 -4.73
[56] -0.73 -0.73 -4.73 4.27 -0.73 -3.73 2.27 4.27 2.27 3.27 -3.73
[67] 2.27 -1.73 -1.73 3.27 2.27 -3.73 1.27 3.27 0.27 -0.73 -2.73
[78] 2.27 -0.73 3.27 3.27 4.27 2.27 2.27 -1.73 -3.73 3.27 -0.73
[89] -3.73 -4.73 -3.73 -2.73 1.27 -3.73 3.27 -3.73 0.27 3.27 0.27
[100] -4.73
> x^2
[1] 36 49 36 49 4 16 1 0 64 9 0 81 25 36 49 36 9 81 49 1 49 36 64
[24] 64 25 81 16 36 81 49 16 9 4 64 1 64 1 9 25 1 64 9 25 81 49 36
[47] 49 0 1 4 4 25 4 4 0 16 16 0 81 16 1 49 81 49 64 1 49 9 9
[70] 64 49 1 36 64 25 16 4 49 16 64 64 81 49 49 9 1 64 16 1 0 1 4
[93] 36 1 64 1 25 64 25 0
> (x-mean(x))^2
[1] 1.6129 5.1529 1.6129 5.1529 7.4529 0.5329 13.9129 22.3729
[9] 10.6929 2.9929 22.3729 18.2329 0.0729 1.6129 5.1529 1.6129
[17] 2.9929 18.2329 5.1529 13.9129 5.1529 1.6129 10.6929 10.6929
[25] 0.0729 18.2329 0.5329 1.6129 18.2329 5.1529 0.5329 2.9929
[33] 7.4529 10.6929 13.9129 10.6929 13.9129 2.9929 0.0729 13.9129
[41] 10.6929 2.9929 0.0729 18.2329 5.1529 1.6129 5.1529 22.3729
[49] 13.9129 7.4529 7.4529 0.0729 7.4529 7.4529 22.3729 0.5329
[57] 0.5329 22.3729 18.2329 0.5329 13.9129 5.1529 18.2329 5.1529
[65] 10.6929 13.9129 5.1529 2.9929 2.9929 10.6929 5.1529 13.9129
[73] 1.6129 10.6929 0.0729 0.5329 7.4529 5.1529 0.5329 10.6929
[81] 10.6929 18.2329 5.1529 5.1529 2.9929 13.9129 10.6929 0.5329
[89] 13.9129 22.3729 13.9129 7.4529 1.6129 13.9129 10.6929 13.9129
[97] 0.0729 10.6929 0.0729 22.3729
(8) 把x从大到小排序。计算x的10%分位数到90%分位数之间的距离。
> x <- floor(10*runif(100))
> a<-sort( x, decreasing = TRUE )
> a
[1] 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 7 7 7
[37] 7 7 7 7 7 7 6 6 6 6 5 5 5 5 5 5 5 5 5 5 5 4 4 4 4 4 4 4 4 4 4 4 4 4 3 3
[73] 3 3 3 3 2 2 2 2 2 2 2 2 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0
> b<-c((quantile(a,probs=0.9))-(quantile(a,probs=0.1)))
> b
90%
8.1
1、把user.txt数据输入到R中。计算不同性别、不同年龄的人数,并计算不同性别下的平均身高。
> x<-read.table("E:/user.txt",head=T,sep="")
> x
Name Sex Age Height
1 Alice F 13 56.5
2 Becka F 13 65.3
3 Gail F 14 64.3
4 Karen F 12 56.3
5 Kathy F 12 59.8
6 Mary F 15 66.5
7 Sandy F 11 51.3
8 Sharon F 15 62.5
9 Tammy F 14 62.8
10 Alfred M 14 69.0
11 Duke M 14 63.5
12 Guido M 15 67.0
13 James M 12 57.3
14 Jeffrey M 13 62.5
15 John M 12 59.0
16 Philip M 16 72.0
17 Robert M 12 64.8
18 Thomas M 11 57.5
19 William M 15 66.5
> table(x[["Sex"]],x[["Age"]])
11 12 13 14 15 16
F 1 2 2 2 2 0
M 1 3 1 2 2 1
> table(x$Sex,x$Age)
11 12 13 14 15 16
F 1 2 2 2 2 0
M 1 3 1 2 2 1
> tapply(x[["Height"]],x[["Sex"]], mean)
F M
60.58889 63.91000
2. 把语句x <- floor(runif(100))所生成的向量保存到一个文本文件中,数据项分别用空格。然后从此文件中读入数据到向量y中。 > x <- floor(runif(100))
> cat(x,file="E:/ph.txt")
> x<-scan("E:/ph.txt")
Read 100 items
> x
[1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[37] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[73] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
> y <- read.table("E:/ph.txt")
警告信息:
In read.table("E:/ph.txt") :
readTableHeader在读取'E:/tj.txt'时遇到了不完全的最后一行
> y
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14 V15 V16 V17 V18 V19 V20 V21 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 V22 V23 V24 V25 V26 V27 V28 V29 V30 V31 V32 V33 V34 V35 V36 V37 V38 V39 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 V40 V41 V42 V43 V44 V45 V46 V47 V48 V49 V50 V51 V52 V53 V54 V55 V56 V57 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 V58 V59 V60 V61 V62 V63 V64 V65 V66 V67 V68 V69 V70 V71 V72 V73 V74 V75 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 V76 V77 V78 V79 V80 V81 V82 V83 V84 V85 V86 V87 V88 V89 V90 V91 V92 V93 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 V94 V95 V96 V97 V98 V99 V100
1 0 0 0 0 0 0 0
已知两样本:
A:79.98 80.04 80.02 80.04 80.03 80.03 80.04 79.97 80.05 80.03 80.02 80.00 80.02 B: 80.02 79.94 79.98 79.97 79.97 80.03 79.95 79.97
计算两样本的T统计量
解:由题意可知正态总体方差相同且未知
T统计量的计算公式是
T=(mean(x)-mean(y))/[s*sqrt((1/n1)+(1/n2))]
其中 s^2=[(n1-1)s1^2+(n2-1)s2^2]/(n1+n2-2)
可编写R程序如下
> x<-c(79.98,80.04,80.02,80.04,80.03,80.03,80.04,79.97,80.05,80.03,80.02,80.00,80.02)
> y<-c(80.02,79.94,79.98,79.97,79.97,80.03,79.95,79.97)
> T<-function(x,y)
+ {
+ n1<-length(x);
+ n2<-length(y)
+ x1<-mean(x);
+ y1<-mean(y)
+ s1<-var(x);
+ s2<-var(y);
+ s<-((n1-1)*s1+(n2-1)*s2)/(n1+n2-2)
+ (x1-y1)/sqrt(s*(1/n1+1/n2))
+ }
> T(x,y)
[1] 3.472245
> >由上述结果可知,两样本T统计量为3.472245。
1、从数据文件class.txt读入数据存为数据框,给数据框添加名字:name, age, height, weight, sex;在一页中对体重作出qqnorm图、直方图、Boxplot;
对身高和体重作qqplot图,要求给出标题、坐标轴等。
> s<-read.table("E:/class.txt",as.is=T)
> s
V1 V2 V3 V4 V5
1 Lawrence 17 172 78.1 男
2 Jeffery 14 169 51.3 男
3 Edward 14 167 50.8 男 4 Phillip 16 167 58.1 男 5 Kirk 17 167 60.8 男 6 Robert 15 164 58.1 男 7 Jaclyn 12 162 65.8 女 8 Danny 15 162 48.1 男 9 Clay 15 162 47.7 男 10 Henry 14 159 54.0 男 11 Leslie 14 159 64.5 女 12 John 13 159 44.5 男 13 William 15 159 50.4 男 14 Martha 16 159 50.8 女 15 Lewis 14 157 41.8 男 16 Amy 15 157 50.8 女 17 Alfred 14 157 44.9 男 18 Chris 14 157 44.9 男 19 Fredrick 14 154 42.2 男
20 Carol 14 154 38.1 女 21 Joe 13 154 47.7 男 22 Mary 15 152 41.8 女 23 Linda 17 152 52.7 女 24 Mark 15 152 47.2 男 25 Patty 14 152 38.6 女 26 Elizabet 14 152 41.3 女 27 Judy 14 149 36.8 女 28 Louis 12 149 55.8 女 29 Alice 13 149 48.6 女 30 James 12 149 58.1 男 31 Marian 16 147 52.2 女 32 Tim 12 147 38.1 男 33 Barbara 13 147 50.8 女 34 David 13 145 35.9 男 35 Katie 12 145 43.1 女 36 Michael 13 142 43.1 男
37 Susan 13 137 30.4 女
38 Jane 12 135 33.6 女
39 Lillie 12 127 29.1 女
40 Robert 12 125 35.9 男
> names(s)<-c("name","age","sex","height","weight") > s
name age sex height weight
1 Lawrence 17 172 78.1 男
2 Jeffery 14 169 51.3 男
3 Edward 14 167 50.8 男
4 Phillip 16 167 58.1 男
5 Kirk 17 167 60.8 男
6 Robert 15 164 58.1 男
7 Jaclyn 12 162 65.8 女
8 Danny 15 162 48.1 男
9 Clay 15 162 47.7 男
10 Henry 14 159 54.0 男 11 Leslie 14 159 64.5 女 12 John 13 159 44.5 男 13 William 15 159 50.4 14 Martha 16 159 50.8 15 Lewis 14 157 41.8 16 Amy 15 157 50.8 17 Alfred 14 157 44.9 18 Chris 14 157 44.9 19 Fredrick 14 154 42.2 20 Carol 14 154 38.1 21 Joe 13 154 47.7 22 Mary 15 152 41.8 23 Linda 17 152 52.7 24 Mark 15 152 47.2 25 Patty 14 152 38.6 26 Elizabet 14 152 41.3 男 女 男 女 男 男 男 女 男 女 女 男 女 女
27 Judy 14 149 36.8 女 28 Louis 12 149 55.8 女 29 Alice 13 149 48.6 女 30 James 12 149 58.1 31 Marian 16 147 52.2 32 Tim 12 147 38.1 33 Barbara 13 147 50.8 34 David 13 145 35.9 35 Katie 12 145 43.1 36 Michael 13 142 43.1 37 Susan 13 137 30.4 38 Jane 12 135 33.6 39 Lillie 12 127 29.1 40 Robert 12 125 35.9
par(mfrow=c(2,2))
qqnorm(s$weight)
男 女 男 女 男 女 男 女 女 女 男
hist(s$weight)
boxplot(s$weight)
qqplot(s$height,s$weight,main="身高体重图",xlab="身高",ylab="体重")
3、 将屏幕分割为四块,并分别画出
y=sin(x),
z=3*cos(x),
a=sin(x)*cos(x),
b=sin(x)/x。
x<-seq(-10,10,0.01)
> y=sin(x)
> z=3*cos(x)
> a=sin(x)*cos(x)
> b=sin(x)/x
> par(mfrow=c(2,2))
> plot(x,y,type='l',main="y=sinx",xlab="x",ylab="y")
> plot(x,z,type='l',main="z=3*cosx",xlab="x",ylab="z")
> plot(x,a,type='l',main="a=sinx*cosx",xlab="x",ylab="a") plot(x,b,type='l',main="b=sinx/x",xlab="x",ylab="b")
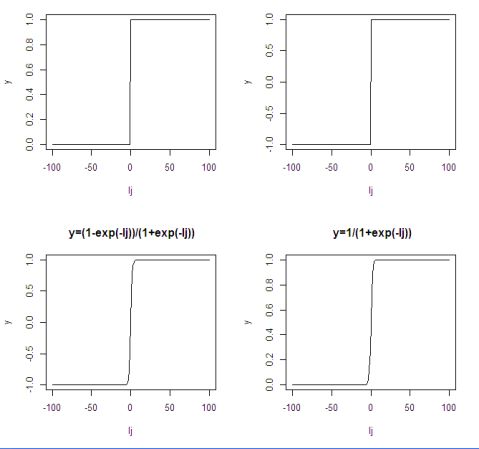
作f(I???1,Ij?0??1,Ij?01?e?Ij
j)??、f(
?0,Ij?0Ij)???,I、f(??1j?0Ij)?1?e?Ij、
(1)f(I??1,Ij?0
j)????0,I
j?0
Ij<-(-100:100);
y=numeric(length(Ij));
y[Ij>=0]<-1;
y[Ij<0]<-0;
plot(Ij,y,type="l")
(2)f(I??1,Ij?0
j)?????1,I
j?0
Ij<-(-100:100);
y=numeric(length(Ij));
f(Ij)?11?e?Ij函数图
y[Ij>=0]<-1;
y[Ij<0]<--1;
plot(Ij,y,type="l")
(3)f(Ij)?1?e1?e?Ij?Ij
Ij<-(-100:100);
y=numeric(length(Ij));
y=(1-exp(-Ij))/(1+exp(-Ij));
plot(Ij,y,type="l",main=" y=(1-exp(-Ij))/(1+exp(-Ij))")
(4)f(Ij)?11?e?Ij
Ij<-(-100:100);
y=numeric(length(Ij));
y=1/(1+exp(-Ij)); plot(Ij,y,type="l",main=" y=1/(1+exp(-Ij))")
将以上程序输入到R软件中得到函数图形如下:
?1,x?0?1,x?011?e?x
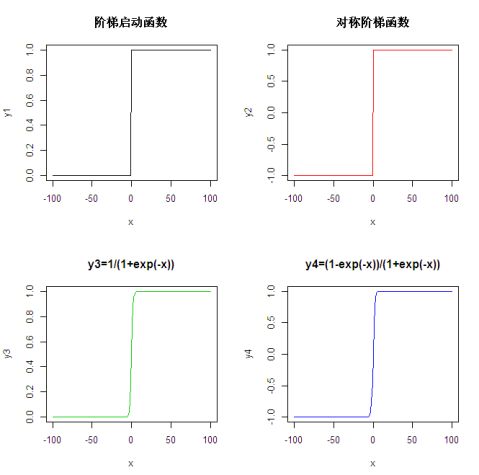
1. 将屏幕分割为四块,并在R软件中分别四个函数y1??,y2??,y3?,y4?的图形。 ?x?x1?e1?e??1,x?0?0,x?0解: 由题意,R软件的程序为:
par(mfrow=c(2,2))#准备画2?2的4个图
#############函数一################
x<-(-100:100);
y1<-numeric(length(x));
y1[x>=0]<-1;
y1[x<0]<-0;
plot(x,y1,main= "阶梯启动函数",type="l",col="1")
#############函数二################
x<-(-100:100);
y2<-numeric(length(x));
y2[x>=0]<-1;
y2[x<0]<--1;
plot(x,y2,main= "对称阶梯函数",type="l",col="2")
#############函数三################
x<-(-100:100);
y3<-numeric(length(x));
y3<-1/(1+exp(-x));
plot(x,y3,main="y3=1/(1+exp(-x))",type="l",col="3") #############函数四################
x<-(-100:100);
y4<-numeric(length(x));
y4<-(1-exp(-x))/(1+exp(-x));
plot(x,y4,main="y4=(1-exp(-x))/(1+exp(-x))",type="l",col="4")软件运行结果为: