模式识别实验二报告
非参数概率密度函数估计
一、 实验目的:
了解非参数估计的两种估计方法:Kn-近邻估计,Parzen窗估计。
二、实验条件:
matlab软件
三、实验原理:
对于被估计点x:
根据公式P(x)=k/(V*N);
当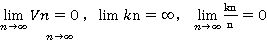 时
时
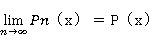
Kn-近邻估计是通过确定Kn ,计算出Vn,来估计P(x);
Parzen窗估计则是通过确定核函数K(x,xi)来计算每个样本对估计点x处概率密度P(x)的贡献,从而估计P(x)
其中K(x,xi)满足:
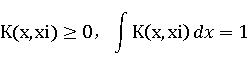
四、实验内容
1、给出Parzen窗估计的程序框图,并编写程序;
2、编写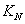 -近邻估计程序;
-近邻估计程序;
五、实验步骤:
1.Parzen窗估计的程序框图:
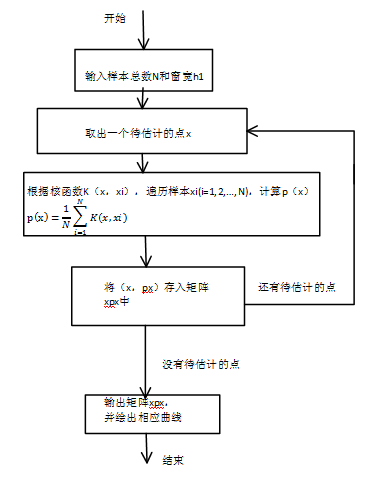
1的程序:KN.m exp2KN.m
2的程序:Parzen.m exp2Parzen.m
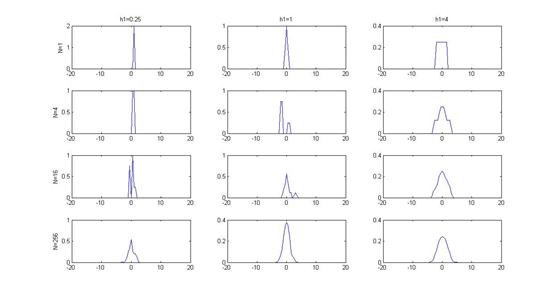
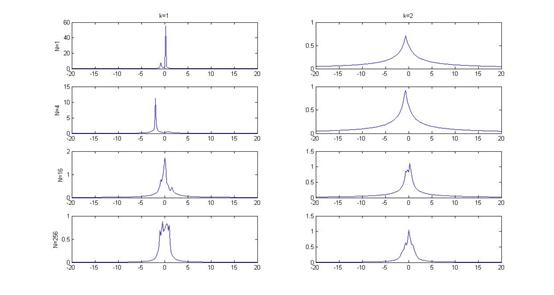
其中KN.m 和Pazen.m 为算法的实现,它们所采用的样本均服从标准正态分布,Parzen窗估计所用核函数为方窗。
而以exp2为前缀的程序为使用不同参数时的实验结果。
六、实验结果
Parzen窗估计:
Kn-近邻估计
七、实验心得
通过本次试验,我进一步了解非参数估计的概念,了解并实现了两种非参数估计办法。
第二篇:K-均值聚类算法实验报告-模式识别-C++
040930520 吴非 模式识别实验报告
K-均值聚类算法实验报告
试验目的
通过对K-均值算法的编程实现,加强对该算法的理解和认识。提高自身的知识水平和编程能力,认识模式识别在生活中的应用。
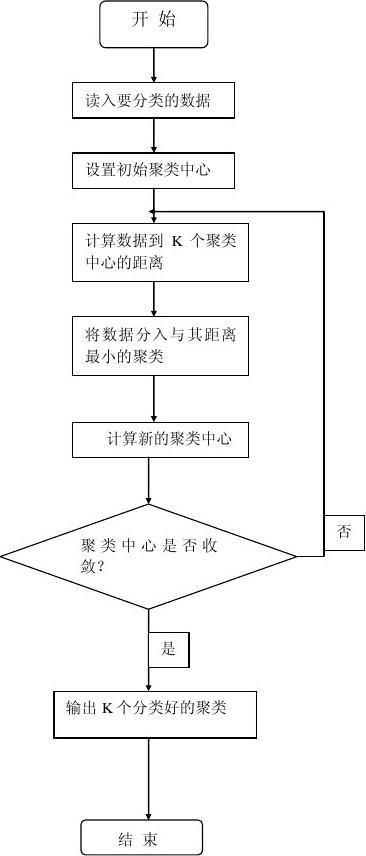
算法思想
K-均值算法的主要思想是先在需要分类的数据中寻找K组数据作为初始聚类中心,然后计算其他数据距离这三个聚类中心的距离,将数据归入与其距离最近的聚类中心,之后再对这K个聚类的数据计算均值,作为新的聚类中心,继续以上步骤,直到新的聚类中心与上一次的聚类中心值相等时结束算法。
子函数
int judge(float i,float j,float k)
judge用来判断元素属于哪个聚类,返回元素所在的聚类值(1,2,3).
算法流程图
040930520 吴非 模式识别实验报告
实验代码
040930520 吴非 模式识别实验报告 #include<iostream.h>
#include<fstream.h>
#include<stdlib.h>
#define COUNT 150 //数据个数
struct data {
int time=0;//记录迭代次数
int judge(float i,float j,float k){//判断数据属于哪个分类
if((i<=j)&&(i<=k)) return 1; float dx; float dy; float dz; float dm; int symbol;//标号 }data[150],Zdata[3],Cz[3];
else if((j<i)&&(j<=k))
return 2;
else
} return 3;
void main(){
int z1=0,z2=0,z3=0;// 存放每个聚类的元素个数 float a=0,b=0,c=0,d=0,e[3],t[12];
float sum=1;
int count;
fstream outputFile;
outputFile.open("Iris.txt",ios::in);
//cout<<"文件中的数据如下"<<endl;
if(!outputFile)
{
cout<<"Can't open the File!"<<endl;
exit(0);
040930520 吴非 模式识别实验报告 }
for(count=0;count<COUNT;count++)
{
outputFile>>data[count].dx;
outputFile>>data[count].dy;
outputFile>>data[count].dz;
outputFile>>data[count].dm;
data[count].symbol=0; } {cout.setf(ios::showpoint); /* for(count=0;count<COUNT;count++)//输出文件中的数据
cout<<data[count].dx<<' ';
cout<<data[count].dy<<' ';
cout<<data[count].dz<<' ';
cout<<data[count].dm<<' '; cout<<endl; } */ outputFile.close(); for(count=0;count<3;count++){//初始化聚类
Zdata[count].dx=data[count].dx;
Zdata[count].dy=data[count].dy;
Zdata[count].dz=data[count].dz;
Zdata[count].dm=data[count].dm;
Zdata[count].symbol=data[count].symbol;
}
do { Cz[0].dx=0;//初始化 Cz[0].dy=0; Cz[0].dz=0; Cz[0].dm=0; Cz[1].dx=0; Cz[1].dy=0; Cz[1].dz=0; Cz[1].dm=0; Cz[2].dx=0; Cz[2].dy=0; Cz[2].dz=0;
040930520 吴非 模式识别实验报告
Cz[2].dm=0; for(count=0;count<COUNT;count++){//判断每个元素属于哪个聚类 a=(Zdata[0].dx-data[count].dx); b=(Zdata[0].dy-data[count].dy); c=(Zdata[0].dz-data[count].dz); d=(Zdata[0].dm-data[count].dm); e[0]=a*a+b*b+c*c+d*d; a=(Zdata[1].dx-data[count].dx); b=(Zdata[1].dy-data[count].dy); c=(Zdata[1].dz-data[count].dz); d=(Zdata[1].dm-data[count].dm); e[1]=a*a+b*b+c*c+d*d; a=(Zdata[2].dx-data[count].dx); b=(Zdata[2].dy-data[count].dy); c=(Zdata[2].dz-data[count].dz); d=(Zdata[2].dm-data[count].dm); e[2]=a*a+b*b+c*c+d*d; data[count].symbol=judge(e[0],e[1],e[2]);
//cout<<data[count].symbol;
}
z1=0;z2=0;z3=0;
for(count=0;count<COUNT;count++)//计算每个聚类的元素个数
{if(data[count].symbol==1){ Cz[0].dx+=data[count].dx; Cz[0].dy+=data[count].dy; Cz[0].dz+=data[count].dz; Cz[0].dm+=data[count].dm; z1++;} else if(data[count].symbol==2){ Cz[1].dx+=data[count].dx; Cz[1].dy+=data[count].dy; Cz[1].dz+=data[count].dz; Cz[1].dm+=data[count].dm; z2++;}
else{
Cz[2].dx+=data[count].dx;
Cz[2].dy+=data[count].dy; Cz[2].dz+=data[count].dz; Cz[2].dm+=data[count].dm;
040930520 吴非 模式识别实验报告
z3++;} } //cout<<z1<<' '<<z2<<' '<<z3<<' '<<endl;
//计算新的聚类中心
Cz[1].dx=Cz[1].dx/z2; Cz[1].dy=Cz[1].dy/z2; Cz[1].dz=Cz[1].dz/z2; Cz[1].dm=Cz[1].dm/z2; Cz[2].dx=Cz[2].dx/z3; Cz[2].dy=Cz[2].dy/z3; Cz[2].dz=Cz[2].dz/z3; Cz[2].dm=Cz[2].dm/z3; Cz[0].dx=Cz[0].dx/z1; Cz[0].dy=Cz[0].dy/z1; Cz[0].dz=Cz[0].dz/z1; Cz[0].dm=Cz[0].dm/z1;
++time;
sum=0;
t[0]=(Zdata[0].dx-Cz[0].dx)*(Zdata[0].dx-Cz[0].dx);
t[1]=(Zdata[0].dy-Cz[0].dy)*(Zdata[0].dy-Cz[0].dy);
t[2]=(Zdata[0].dz-Cz[0].dz)*(Zdata[0].dz-Cz[0].dz);
t[3]=(Zdata[0].dm-Cz[0].dm)*(Zdata[0].dm-Cz[0].dm);
t[4]=(Zdata[1].dx-Cz[1].dx)*(Zdata[1].dx-Cz[1].dx);
t[5]=(Zdata[1].dy-Cz[1].dy)*(Zdata[1].dy-Cz[1].dy);
t[6]=(Zdata[1].dz-Cz[1].dz)*(Zdata[1].dz-Cz[1].dz);
t[7]=(Zdata[1].dm-Cz[1].dm)*(Zdata[1].dm-Cz[1].dm);
t[8]=(Zdata[2].dx-Cz[2].dx)*(Zdata[2].dx-Cz[2].dx);
t[9]=(Zdata[2].dy-Cz[2].dy)*(Zdata[2].dy-Cz[2].dy);
t[10]=(Zdata[2].dz-Cz[2].dz)*(Zdata[2].dz-Cz[2].dz);
t[11]=(Zdata[2].dm-Cz[2].dm)*(Zdata[2].dm-Cz[2].dm);
for(count=0;count<12;count++)
{
sum+=t[count];
}
//cout<<endl<<sum<<endl;//迭代的判定sum
040930520 吴非 模式识别实验报告
Zdata[0].dx=Cz[0].dx; Zdata[0].dy=Cz[0].dy; Zdata[0].dz=Cz[0].dz; Zdata[0].dm=Cz[0].dm; Zdata[1].dx=Cz[1].dx; Zdata[1].dy=Cz[1].dy; Zdata[1].dz=Cz[1].dz; Zdata[1].dm=Cz[1].dm; Zdata[2].dx=Cz[2].dx; Zdata[2].dy=Cz[2].dy; Zdata[2].dz=Cz[2].dz; Zdata[2].dm=Cz[2].dm;
}
while(sum!=0);
cout<<"(下标从1到150)"<<endl;
cout<<"分类成功!"<<endl;
cout<<"****************************************"<<endl;
for(count=0;count<COUNT;count++)
{
if(data[count].symbol==1)
cout<<count+1<<' ';
}
cout<<endl<<"共"<<z1<<"个元素属于第一类"<<endl;
cout<<"****************************************"<<endl;
for(count=0;count<COUNT;count++)
{
if(data[count].symbol==2)
cout<<count+1<<' ';
}
cout<<endl<<"共"<<z2<<"个元素属于第二类"<<endl;
cout<<"****************************************"<<endl;
040930520 吴非 模式识别实验报告 for(count=0;count<COUNT;count++)
{
if(data[count].symbol==3)
cout<<count+1<<' ';
}
cout<<endl<<"共"<<z3<<"个元素属于第三类"<<endl;
cout<<"****************************************"<<endl;
cout<<endl<<"迭代次数为 "<<time<<" 次"<<endl<<endl;
}
实验过程
执行程序结果如下
令前三个数据作为初始聚类中心

040930520 吴非 模式识别实验报告 以第2,3,4个数据作为初始聚类中心
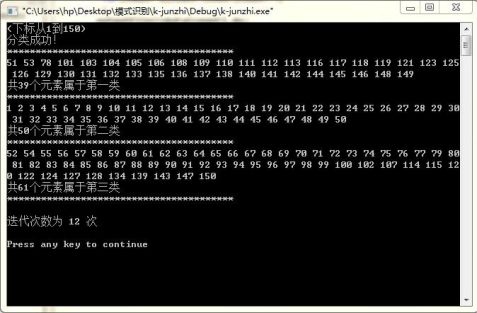
以第100,101,102组数据为初始聚类中心
040930520 吴非 模式识别实验报告
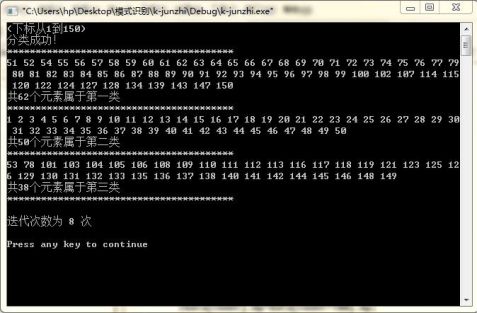
发现聚类的结果基本一样,只是有很少数的数据的聚类会发生变化(如第51个数据),聚类的产生次序变化了(这是显然的),但是迭代的次数变了,分别为11,12和8次。
再改变输入数据的顺序,我把前50个数据放到了最后面,结果如下:
040930520 吴非 模式识别实验报告
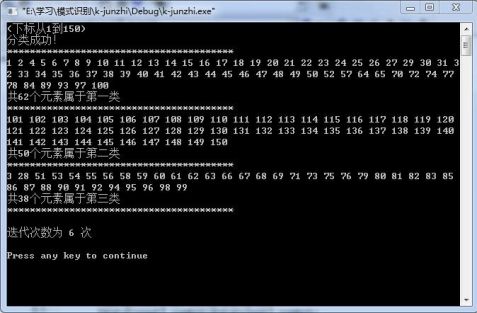
发现迭代次数减少到了6次,而且数据的聚类结果也发生了一些细微的变化(比如第1个数据,即变化前的第51个数据)。
实验心得
初始的聚类中心的不同,对聚类结果没有很大的影响,而对迭代次数有显著的影响。
数据的输入顺序不同,同样影响迭代次数,而对聚类结果没有太大的影响。