电子科技大学
实 验 报 告
课程名称: 数据结构与算法
学生姓名: 陈*浩
学 号: *************
点名序号: ***
指导教师: 钱**
实验地点: 基础实验大楼
实验时间: 2015.5.7
20##-20##-2学期
信息与软件工程学院
实 验 报 告(二)
学生姓名:陈**浩 学号:************* 指导教师:钱**
实验地点: 科研教学楼A508 实验时间:2015.5.7
一、实验室名称:软件实验室
二、实验项目名称:数据结构与算法—树
三、实验学时:4
四、实验原理:
霍夫曼编码(Huffman Coding)是一种编码方式,是一种用于无损数据压缩的熵编码(权编码)算法。1952年,David A. Huffman在麻省理工攻读博士时所发明的。
在计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
例如,在英文中,e的出现机率最高,而z的出现概率则最低。当利用霍夫曼编码对一篇英文进行压缩时,e极有可能用一个比特来表示,而z则可能花去25个比特(不是26)。用普通的表示方法时,每个英文字母均占用一个字节(byte),即8个比特。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。
霍夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的路径长度是从树根到每一结点的路径长度之和,记为WPL=(W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n)。可以证明霍夫曼树的WPL是最小的。
五、实验目的:
本实验通过编程实现赫夫曼编码算法,使学生掌握赫夫曼树的构造方法,理解树这种数据结构的应用价值,并能熟练运用C语言的指针实现构建赫夫曼二叉树,培养理论联系实际和自主学习的能力,加强对数据结构的原理理解,提高编程水平。
六、实验内容:
(1)实现输入的英文字符串输入,并设计算法分别统计不同字符在该字符串中出现的次数,字符要区分大小写;
(2)实现赫夫曼树的构建算法;
(3)遍历赫夫曼生成每个字符的二进制编码;
(4)显示输出每个字母的编码。
七、实验器材(设备、元器件):
PC机一台,装有C或C++语言集成开发环境。
八、数据结构与程序:
/*******************************************************************
** *程序名称:哈夫曼树的相关操作 *
** *程序内容:生成哈夫曼树及其编码表、对字符串进行编码等 *
** *编写作者:陈家浩 *
** *完成时间:2015.5.15 *
*******************************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAXSIZE 10000
char file_address[100]; //全局通用文件地址
typedef struct hnode // 哈夫曼树的节点结构定义
{
int weight;
int lchild, rchild, parent;
}THNode, * TpHTree;
typedef struct huffman_code // 哈夫曼编码表的元素结构定义
{
int weight; // 编码对应的权值
char * pcode; // 指向编码字符串的指针
}THCode, *TpHcodeTab;
//*************************************************************
// ** **声明函数
//*************************************************************
TpHcodeTab build_codesheet( TpHTree pht, int leaves_num);
// 根据哈夫曼树得到编码表
TpHTree create_huffman_tree(int weights[], int n ); // 构造哈夫曼树
void select_mintree(TpHTree , int , int *, int *); // 从森林中选择权值最小的两棵子树
void destroy_codesheet(TpHcodeTab codesheet, int n); // 销毁哈夫曼编码表
int read_file(char file_address[100], char *message); // 从文本文件读入字符串
int calc_freq(char text[], int **freq, char **dict, int n); // 统计字符串text中字符出现的频率
//*************************************************************
// ** **主函数
//*************************************************************
int main(void)
{
int i, msg_num,choose;
char s; //清空缓存
int leaves_num = 0;
do
{
TpHTree pht = NULL; //建立树根
TpHcodeTab codesheet; //建立编码表
char msg[MAXSIZE]; //建立信息数组
int *weights = NULL; //建立频率数组
char *dict = NULL; //建立字符数组
printf(" -------- \n""----------哈夫曼树----------\n"" -------- ");
printf("\n读取文件还是手动输入信息?\n"" 1:手动输入信息\n"" 2:读取文件\n"" 请选择:");
scanf("%d",&choose);
if(choose == 1)
{
printf("请输入信息:\n");
scanf("%c",&s); //清理键盘缓存
gets(msg);
msg_num = strlen(msg);
}
else
{
printf("输入文件地址(例如:F:\\\\filename.txt):\n");
scanf("%c",&s); //清理键盘缓存
gets(file_address); //输入文件地址
msg_num = read_file( file_address, msg); //读取文本文件
}
leaves_num = calc_freq( msg, &weights, &dict, msg_num );//统计文本串中的字符频率,同时得到哈夫曼树的叶节点数
pht = create_huffman_tree( weights, leaves_num ); //创建哈夫曼树
codesheet = build_codesheet( pht, leaves_num ); //构造哈夫曼编码表
printf("\n---字符频率编码表---\n");
printf("符号 -- 频率 -- 编码\n");
for(i = 0; i < leaves_num ; i++)
printf("%4c -- %-3d -- %-6s\n", dict[i], codesheet[i].weight, codesheet[i].pcode);
printf("--------------------\n");
destroy_codesheet( codesheet, leaves_num); //销毁哈夫曼编码表
if(pht) //释放所有临时空间
free(pht);
if(dict)
free(dict);
if(weights)
free(weights);
printf("\n\t0:结束\n\t1:继续\n""\t请选择:");
scanf("%d",&choose);
}while(choose);
return 0;
}
//*************************************************************
// ** **构造哈夫曼编码表
//*************************************************************
TpHcodeTab build_codesheet( TpHTree pht, int leaves_num )
{
int i, cid, pid, cursor, len;
TpHcodeTab sheet;
char * pch = (char *) malloc( leaves_num + 1 );
if( !pch ){
printf("申请空间失败!");
exit(0);
}
memset( pch, 0, (leaves_num + 1) ); // 清零新分配的空间
sheet = ( TpHcodeTab )malloc( sizeof( THCode ) * leaves_num );
if( !sheet )
{
printf("申请编码表内存空间失败!");
exit(0);
}
for( i = 0; i < leaves_num; ++i ){
sheet[i].weight = pht[i].weight;
}
for( i = 0; i < leaves_num; ++i )
{
cursor = leaves_num;
cid = i;
pid = pht[cid].parent;
while( pid!= -1 ) //不为根节点
{
if (pht[pid].lchild == cid)
pch[--cursor] = '0'; // 左分支编码为'0'
else
pch[--cursor] = '1'; // 右分支编码为'1'
cid = pid;
pid = pht[cid].parent;
}
len = leaves_num - cursor + 1;
sheet[i].pcode = ( char * )malloc( len );
if( !sheet[i].pcode )
{
printf("为节点%d的编码申请内存空间失败!", i);
exit(0);
}
memset( sheet[i].pcode, 0, len );
strncpy( sheet[i].pcode, &pch[cursor], strlen(&pch[cursor]) );
}
free(pch);
return sheet;
}
//*************************************************************
// ** **构造哈夫曼树
//*************************************************************
TpHTree create_huffman_tree( int weights[], int n )
{
TpHTree pht;
int minA, minB; // 用于保存权值最小的两棵子树的序号
int i, a = 0;
if( n < 1 ){
printf("没有叶子节点!\n");
return 0;
}
a = (2 * n) - 1;
pht = ( TpHTree ) malloc( sizeof( THNode ) * a );
if( !pht )
{
printf("分配数组空间失败!\n");
exit(0);
}
for( i = 0; i < a; ++i ) // 哈夫曼数组初始化
{
pht[i].weight = (i < n) ? weights[i] : 0;
pht[i].lchild = -1;
pht[i].rchild = -1;
pht[i].parent = -1;
}
for( i = n; i < a; ++i )
{
select_mintree( pht, (i-1), &minA, &minB );
pht[minA].parent = i;
pht[minB].parent = i;
pht[i].lchild = minA;
pht[i].rchild = minB;
pht[i].weight = pht[minA].weight + pht[minB].weight;
}
return pht;
}
//*************************************************************
// ** **选出权值最小的两棵子树
//*************************************************************
void select_mintree(TpHTree pht, int n, int *minA, int *minB)
{
int id, min1 = -1, min2 = -1; //最小值,次小值
int maxa = 10000, maxb = 10000;
for(id = 0; id <= n; id++){
if(pht[id].parent == -1){
if( pht[id].weight < maxa )
{
min2 = min1;
min1 = id;
maxa = pht[id].weight;
}
else if(pht[id].weight < maxb )
{
min2 = id;
maxb = pht[id].weight;
}
}
}
*minA = min1;
*minB = min2;
return;
}
//*************************************************************
// ** **销毁哈夫曼编码表
//*************************************************************
void destroy_codesheet(TpHcodeTab sheet, int n)
{
int i;
for(i = 0; i < n; ++i)
free(sheet[i].pcode);
free(sheet);
return;
}
//*************************************************************
// ** **读取文本文件
//*************************************************************
int read_file(char file_address[100], char *message)
{
int str_len; //字符串长度
FILE * pFile = NULL;
pFile = fopen( file_address, "r"); //打开文件
if(!pFile)
{
printf("打开文件失败!\n");
exit(0);
}
else{
printf("打开文件成功!\n");
}
memset(message, 0, MAXSIZE); //清除缓冲
if( fgets( message, MAXSIZE, pFile ) == NULL)
{
printf( "fgets error\n" );
exit(0);
}
else{
printf( "成功读取文件,内容如下:\n%s\n", message);
}
str_len = strlen(message);
fclose(pFile);
return str_len;
}
//*************************************************************
// ** **统计字符出现的频率
//*************************************************************
int calc_freq(char text[], int **freq, char **dict, int n)//n为字符串长度
{
int i, k;
int char_num = 0;
int * chars; //不同种类的字符
char * fre; //字符的出现频率
int times[256] = {0};
for(i = 0; i < n; ++i) //各个字符出现的频率
times[text[i]]++;
for(i = 0; i < 256; i++) //不同字符的个数
if( times[i] > 0 )
char_num++;
chars = (int*)malloc(sizeof(int)*char_num);
if( !chars )
{
printf("为频率数组分配空间失败!\n");
exit(0);
}
fre = (char *)malloc(sizeof(char)*char_num);
if( !fre )
{
printf("为字符数组分配空间失败!\n");
exit(0);
}
k = 0;
for(i = 0; i < 256; ++i)
{
if( times[i] > 0 )
{
chars[k] = times[i];
fre[k] = (char)i;
k++;
}
}
*freq = chars;
*dict = fre;
return char_num;//不同种类的字符个数
}
九、程序运行结果:
一、手动输入信息
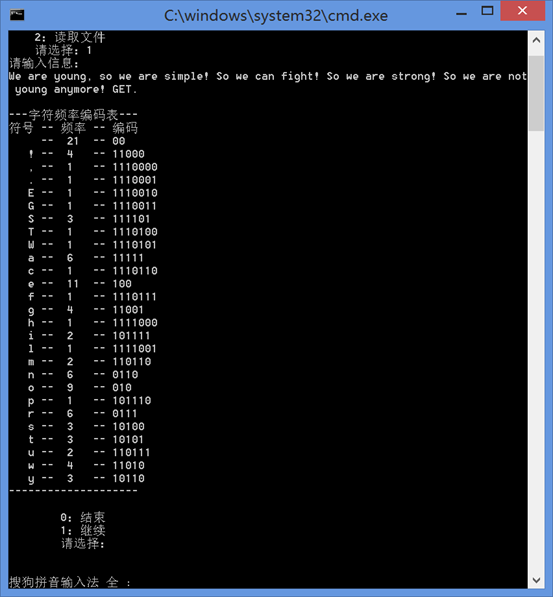
二、从文件读取信息
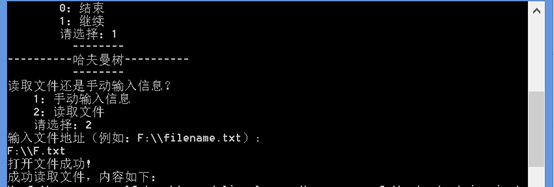
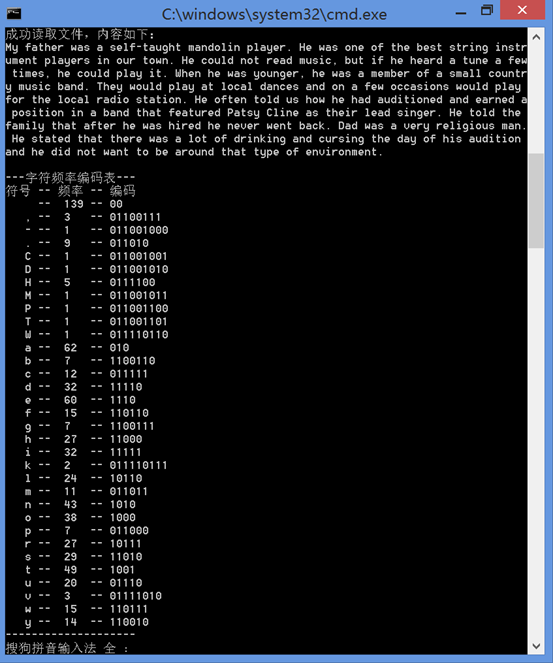

十、实验结论:
本实验通过编程实现赫夫曼编码算法,在实验中掌握了赫夫曼树的构造方法,理解了树这种数据结构的应用价值,并且已经能够熟练运用指针实现构建赫夫曼二叉树,理论联系实际和自主学习的能力得到了培养,对数据结构的原理理解更加深刻,也提高了编程水平。
十一、总结及心得体会:
1、虽然算法很多事现有的,可以用来做参考,不宜照抄。
2、使用指针存储信息之前应为其分配内存空间;
3、scanf()函数读取到空格会自动停止,而gets()函数读取到回车即停止;
4、需要读取单个字符时要考虑到键盘的缓冲区;
5、双重指针的问题应特别注意;
6、文件地址如果输入错误的解决方案没有考虑到;
7、申请了内存的空间应该在程序结束时进行释放,否则可能造成空间浪费;
8、应养成对代码进行注释的习惯,不久之后可能自己的程序自己都不知道是什么意思;
9、实验是培养独立思考、作业的过程,要多思考,不应过多依赖他人。