英文标题:Mining Frequent Patterns without Candidate Generation
中文标题:不产生候选项集的频繁模式挖掘
文献来源:Special Interest Group On Management Of Data , 2000
一、主要内容:
(1)论文研究的问题概述
关联规则在数据挖掘是一个重要的研究内容。而产生频繁集则是产生关联规则的第一步。在大多数以前的实现中,人们普遍采用了类似于Apriori的算法。这种算法受两种非平凡开销的影响:一是需要产生指数级的候选项集,二是需要重复地扫描整个数据库,通过模式匹配检查一个很大的候选集合。检查数据库中每个事务来确定候选项集支持度的开销是非常可观的。
针对Apriori算法的缺陷,Jiawei Han提出FP-growth算法,该算法仅须扫描数据库两遍且无须生成候选项目集,避免了产生“知识的组合爆炸”,提高了频繁模式集的挖掘效率。
(2)论文研究的理论意义及其应用前景
之前的由频繁项集产生关联规则的发现算法都基于Apriori算法框架,在高密度数据库上的执行性能不佳。FP-growth算法提出利用了高效的数据结构FP-tree,直观并且容易实现,它只需要两次扫描数据库,极大地减小了I/O操作次数,并且无须生成候选项目集,因而在时间和空间上都提高了处理效率。此算法执行效率比基于 Apriori的算法高一个数量级。
FP-growth 算法将发现长频繁模式的问题转换成在较小的条件数据库中递归地搜索一些较短频繁模式,然后连接后缀。它使用最不频繁的模式后缀,提供了好的选择性,显著的降低了搜索开销。
(3)论文所述系统或算法的过程描述
FP-growth采用如下分治策略:首先,将代表频繁项集的数据库压缩到一棵频繁模式树(FP树),该树仍保留项集的关联信息。然后,把这种压缩的数据库划分成一组条件数据库(一种特殊类型的投影数据库),每个数据库关联一个频繁项或“模式段”,并分别挖掘每个条件数据库。对每个“模式片段”,只需要考察与它相关联数据集。因此,随着被考察模式的“增长”,这种方法可以显著的压缩被搜索的数据集的大小。
算法的具体过程描述如下:
数据库的第一次扫描导出频繁项(1项集)的集合,并得到它们的支持度计数。频繁项的集合按支持度计数的递减排序,结果集或表记为L。
然后,FP 树的构造过程可描述为:首先创建树的根结点,用“null”标记。第二次扫描数据库D,每个事务中的项目按照支持度递减排序,并对每个事务创建一个分枝。一般地,当为一个事务考虑增加分枝时,沿共同前缀上的每个结点的计数值增加1 ,为跟随在前缀之后的项目创建结点并链接。为了方便树的遍历,创建一个频繁项目头表,使得每个项目通过一个结点头指针指向它在树中的位置。这样,数据库频繁模式的挖掘问题就转换成挖掘FP树的问题。
FP 树挖掘过程可描述为:从项头表开始挖掘,由频率低的节点开始,因此选取长度为1 的频繁模式(初始后缀模式)开始,沿循每个频繁项的链接来遍历FP树,通过积累该项的前缀路径来构造它的条件模式基(一个“子数据库”,由FP树中与该后缀模式一起出现
的前缀路径集组成)。对每个条件模式基,对基中的每一项积累计数,为模式基中的频繁项构建条件FP树,并递归地在该树上进行挖掘。从条件FP-tree中找到所有长路径,对该路径上的节点找出所有组合方式,然后合并计数。与该频繁项合并,得到频繁项集。模式增长通过后缀模式与条件FP 树产生的频繁模式连接实现。
算法的伪代码如下:
算法:FP-Growth。使用FP树,通过模式增长挖掘频繁模式。
输入:
? D:事物数据库
? min_sup:最小支持度阈值
输出:频繁模式的完全集。
方法:
1. 按一下步骤构造FP树:
(a)扫描数据库D一次。手机频繁项的集合F和它们的支持度计数。对F按支持度计数降
序排序,结果为频繁项列表L。
(b)创建FP树的根节点,以“null”标记它。对于D中每个事物Trans,执行:
选择Trans中的频繁项,并按L中的次序排序。设Trans排序后的频繁项列表为[p|P],其中p是第一个元素,而P是剩下的元素列表。调用insert_tree([p|P],T)。该过程执行情况如下。如果T有子女N使得N.item-name=p.item-name,则N的计数增加1;否则,创建一个新节点N,将其计数设置为1,链接到它的父节点T,并且通过节点链结构将其链接到具有相同item-name的结点。如果P非空,则递归地调用insert_tree(P,N)。
2. FP树的挖掘通过调用FP-growth(FP_tree,null)实现。该过程实现如下。
Procedure FP_growth(Tree,α)
(1)if Tree包含单个路径P then
(2)for 路径P中结点的每个组合(记作β)
(3)产生模式β∪α,其中支持度计数support_count等于β中结点的最小支持度计数;
(4)else for Tree的表头中的每一个αi{
(5)产生一个模式β=α∪αi,其中支持度计数support_count=αi.support_count;
(6)构造β的调减模式基然后构造β的条件FP树Treeβ;
(7)if Treeβ≠? then
(8)调用FP_growth(Treeβ,β);}
(4)论文的主要创新之处
FP-growth算法提出利用了高效的数据结构FP-tree,使得一个大数据库能够被有效地压缩成比原数据库小很多的高密度结构,只需要两次扫描数据库,减少大量扫描数据库的I/O时间。
该算法基于FP-Tree的挖掘采取模式增长的递归策略,创造性地提出了无候选项目集的挖掘方法,在进行长频繁项集的挖掘时效率较好。
采用基于划分的分而治之的方法,大大降低了后续条件模式基和条件FP树的大小。它使用最不频繁的模式后缀,提供了好的选择性,显著的降低了搜索开销。
二、实验评价:
(1)实验数据集
论文中报告了两个合成数据集上的实验结果。第一个是包括1000个物品的合成数据集。在这组数据中,平均交易规模和平均最大潜在的频繁项集的大小分别设置为10和4,而在数据集中交易的数量设置为100 K。这是一个短频繁项集的稀疏数据集。
第二合成数据集,包括10000项的物品。平均交易规模和平均最大潜在的频繁项集的大小分别设置为25和20。它是一个长频繁项集和短频繁模式混合的稠密数据集。
在长模式数据集的FP-growth算法的性能测试中,使用的是从Connect-4游戏状态信息编译的真实数据集。它包含67,557笔交易,是一个长频繁项集的稠密数据集。
(2)评价指标和性能分析
FP-growth在密集的数据集上,一个大数据库能够被有效地压缩成比原数据库小很多的高密度结构。在FP树的分支共享程度较高,对交易频繁的预测之间共享收益大大超过开销,从而使FP树的空间在很多情况下更高效。 对于稀疏数据集,FP树的分支共享程度较低,大大降低了FP-growth的性能,因此我们应该构建投影数据库来提高性能。
(3)本文方法的优点总结
1、紧凑性,非频繁的项被删除,减少了不相关的信息;按频率递减排列,使得更频繁地项更容易在树结构中被共享;数据量比原数据库要小,一个大数据库能够被有效地压缩成比原数据库小很多的高密度结构。只需要两次扫描数据库,减少大量扫描数据库的I/O时间。
2、该算法基于FP-Tree的挖掘采取模式增长的递归策略,创造性地提出了无候选项目集的挖掘方法,在进行长频繁项集的挖掘时效率较好。
3、挖掘过程中采取了分治策略,将这种压缩后的数据库DB分成一组条件数据库Dn,每个条件数据库关联一个频繁项,并分别挖掘每一个条件数据库。而这些条件数据库Dn要远远小于数据库DB。
4、完整性,不会打破任何事务数据中的长模式,为频繁模式的挖掘保留了完整信息。
(4)本文方法的缺点和局限性
1、该算法采取增长模式的递归策略,虽然避免了候选项目集的产生。但在挖掘过程,如果一项大项集的数量很多,并且由原数据库得到的FP-Tree的分枝很多,而且分枝长度又很长时,该算法需要构造出数量巨大的条件 FP-Tree,不仅费时而且要占用大量的空间,挖掘效率不好,而且采用递归算法本身效率也较低。
2、由于海量的事物集合存放在大型数据库中,经典的FP-Growth算法在生成新的FP-Tree时每次都要遍历调减模式基两次,导致系统需要反复申请本地以及数据库服务器的资源查询相同内容的海量数据,一方面降低了算法的效率,另一方面给数据库服务器产生高负荷,不利于数据库服务器正常运作。
3、绝对的分而治之,没有考虑不同子问题中存在的内在联系,重复遍历、计数等操作。
4、不适合用于事务平均长度较短且稀疏的数据集
第二篇:数据挖掘 FP-Growth算法实验报告
FP-Growth算法实验报告
一、算法介绍
数据挖掘是从数据库中提取隐含的、未知的和潜在的有用信息的过程,是数据库及相关领域研究中的一个极其重要而又具有广阔应用前景的新领域. 目前,对数据挖掘的研究主要集中在分类、聚类、关联规则挖掘、序列模式发现、异常和趋势发现等方面,其中关联规则挖掘在商业等领域中的成功应用使它成为数据挖掘中最重要、最活跃和最成熟的研究方向. 现有的大多数算法均是以Apriori 先验算法为基础的,产生关联规则时需要生成大量的候选项目集. 为了避免生成候选项目集,Han等提出了基于FP 树频繁增长模式(Frequent-Pattern Growth,FP-Growth)算法。
FP 树的构造过程可描述为: 首先创建树的根结点, 用“null”标记. 扫描交易数据集DB ,每个事务中的项目按照支持度递减排序,并对每个事务创建一个分枝. 一般地,当为一个事务考虑增加分枝时,沿共同前缀上的每个结点的计数值增加1 ,为跟随在前缀之后的项目创建结点并链接. 为方便树的遍历,创建一个频繁项目列表,使得每个项目通过一个结点头指针指向它在树中的位置. FP 树挖掘过程可描述为:由长度为1 的频繁项目开始,构造它的条件项目基和条件FP树,并递归地在该树上进行挖掘. 项目增长通过后缀项目与条件FP 树产生的频繁项目连接实现. FP-Growth 算法将发现大频繁项目集的问题转换成递归地发现一些小频繁项目,然后连接后缀.它使用最不频繁的项目后缀,提供了好的选择性。
算法:FP-Growth。使用FP树,通过模式增长挖掘频繁模式。
输入:
n D:事物数据库
n min_sup:最小支持度阈值
输出:频繁模式的完全集。
方法:
1. 按一下步骤构造FP树:
(a)扫描数据库D一次。手机频繁项的集合F和它们的支持度计数。对F按支持度计数降序排序,结果为频繁项列表L。
(b)创建FP树的根节点,以“null”标记它。对于D中每个事物Trans,执行:
选择Trans中的频繁项,并按L中的次序排序。设Trans排序后的频繁项列表为[p|P],其中p是第一个元素,而P是剩下的元素列表。调用insert_tree([p|P],T)。该过程执行情况如下。如果T有子女N使得N.item-name=p.item-name,则N的计数增加1;否则,创建一个新节点N,将其计数设置为1,链接到它的父节点T,并且通过节点链结构将其链接到具有相同item-name的结点。如果P非空,则递归地调用insert_tree(P,N)。
2. FP树的挖掘通过调用FP-growth(FP_tree,null)实现。该过程实现如下。
Procedure FP_growth(Tree,α)
(1)if Tree包含单个路径P then
(2)for 路径P中结点的每个组合(记作β)
(3)产生模式β∪α,其中支持度计数support_count等于β中结点的最小支持度计数;
(4)else for Tree的表头中的每一个αi{
(5)产生一个模式β=α∪αi,其中支持度计数support_count=αi.support_count;
(6)构造β的调减模式基然后构造β的条件FP树Treeβ;
(7)if Treeβ≠? then
(8)调用FP_growth(Treeβ,β);}
二、算法实现及实验结果
本实验有两个测试集合:
小数据集A:50条事物集,10个不同的项
大数据集合B:5670事物集,100个不同项
1.对数据集合A进行min_sup=8%计数产生的频繁项集结果如下:
表1. 频繁一项集

表2. 频繁二项集

表3. 频繁三项集
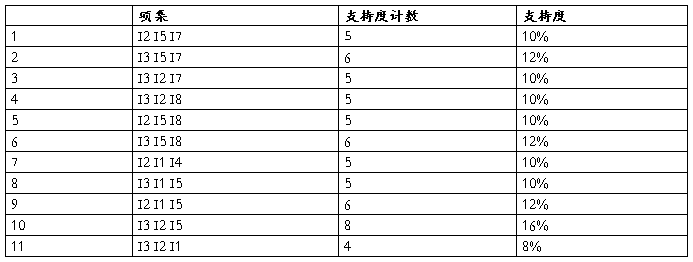
表4. 频繁四项集

2.对数据集B进行不同支持度实验时间消耗结果如下:

图1.数据集B消耗时间
三、算法的优缺点分析
1. FP-Growth算法的优点:
(1)一个大数据库能够被有效地压缩成比原数据库小很多的高密度结构,避免了重复扫描数据库的开销
(2)该算法基于FP-Tree的挖掘采取模式增长的递归策略,创造性地提出了无候选项目集的挖掘方法,在进行长频繁项集的挖掘时效率较好。
(3)挖掘过程中采取了分治策略,将这种压缩后的数据库DB分成一组条件数据库Dn,每个条件数据库关联一个频繁项,并分别挖掘每一个条件数据库。而这些条件数据库Dn要远远小于数据库DB。
2. FP-Growth算法的缺点及改进方法
(1)该算法采取增长模式的递归策略,虽然避免了候选项目集的产生。但在挖掘过程,如果一项大项集的数量很多,并且由原数据库得到的FP-Tree的分枝很多,而且分枝长度又很长时,该算法需要构造出数量巨大的conditional FP-Tree,不仅费时而且要占用大量的空间,挖掘效率不好,而且采用递归算法本身效率也较低。
改进策略:FA算法-FP-Growth算法与Apriori算法的结合
在原数据库得到的FP-Tree的基础上,采用Apriori算法的方法进行挖掘,挖掘过程中不构造conditional FP-Tree。挖掘过程仍然采用分治的策略,即将压缩后的数据库D分成一组条件数据库,每个条件数据库关联一个频繁项。假设有n个一项大项集,则数据库D可被分割成n个条件数据库Di(i=1,…,n),而数据库Di是关联一项大项集Ii的条件数据库。然后分别采用Apriori算法挖掘每一个条件数据库Di,得到所有以Ii为尾的大项集。实现方法是,仍然采用FP-Growth算法的方法构造一棵FP-Tree,不过在每个项前缀子树的节点中增加一个域:con-count。在对条件数据库Di进行挖掘时,该域记录了所在路径代表的交易(transaction)中达到此节点的并且包括Ii的交易个数。而为了找出所有包含Ii的大项集,首先沿着频繁项头表中项Ii的链域找到item-name为Ii的每个项前缀子树的节点Pi,再沿着每个Pi的父指针往上走直到根节点,使该路径上经过的每个项前缀子树节点的con-count域都增加Pi.count,根节点不增加。同时增加一个临时频繁项头表lTable,每个表项(entry)由三个域组成:(1)item-name;(2)node-link;(3) con-count。若某个项前缀子树节点的con-count域增加了Pi.count,另外假如lTable中没有一个表项的item-name与Pi.item-name相同,则在lTable中增加一个表项,使它的item-name,与con-count都与Pi的相同,同时node-link指向该项前缀子树节点的Pi的地址。如果lTable中存在一个表项,它的item-name与Pi.item-name相同,则只要对该表项的con-count域增加Pi. count就行了。然后再对lTable中的每一个表项的con-count域进行统计,若它的con-count域大于预先给定的最小支持度,则保留该表项,否则删除该表项[1]。
(2)由于海量的事物集合存放在大型数据库中,经典的FP-Growth算法在生成新的FP-Tree时每次都要遍历调减模式基两次,导致系统需要反复申请本地以及数据库服务器的资源查询相同内容的海量数据,一方面降低了算法的效率,另一方面给数据库服务器产生高负荷,不利于数据库服务器正常运作。
改进策略:针对 FP-Growth 算法的缺点,对经典算法进行改进,提出使用支持度计数二维表的方法,从而省去经典算法对条件模式基的第一次遍历,具体算法描述为:
① 在第一次遍历事务集合 T 的同时创建二维向量,记录每个事务中各个项两两组合出现的支持度计数。如有事务 “A,B,C,D”,则二维向量表中(A,B)、(A,C)、(A,D)、(B,C)、(B,D)、 (C,D)项都需要加 1。其中向量(C,B)和(B,C)是两个不同的向量。
② 利用递归方式创建 条件下(≠{Null})的条件 FP 子树时,无需两次遍历条件模式基(其中第一次遍历条件模式基可得到支持度计数列表,第二次遍历条件模式基可插入树节点从而创建 FP 树)。支持度计数列表可以从支持度计数二维向量列表中获得。抽取二维向量表中的与 Ei 相关的行、列值,将对应行列值相加即可得到条件 下,Ei与其它项的支持度计数。其中 Ei 为当前项。
③遍历条件模式基,创建 FP 子树的同时创建新的支持度计数二维向量表[2]。
[1]何忠胜,庄燕滨.基于Apriori & Fp-growth的频繁项集发现算法[J].计算机技术与发展,2008,18:45-46.
[2]杨云,罗艳霞.FP-Growth算法的改进[J].计算机工程与设计,2010,31,(7):1508.