人工智能第二次实验报告
一.实验题目:
遗传算法的设计与实现
二.实验目的:
通过人工智能课程的学习,熟悉遗传算法的简单应用。
三.实验内容
用遗传算法求解f (x) = x2 的最大值,x∈ [0,31],x取整数。
可以看出该函数比较简单,只要是为了体现遗传算法的思想,在问题选择上,选了一个比较容易实现的,把主要精力放在遗传算法的实现,以及核心思想体会上。
四. 实验过程:
1.实现过程
(1)编码
使用二进制编码,随机产生一个初始种群。L 表示编码长度,通常由对问题的求解精度决定,编码长度L 越长,可期望的最优解的精度也就越高,过大的L 会增大运算量。针对该问题进行了简化,因为题设中x∈ [0,31],所以将二进制长度定为5就够用了;
(2)生成初始群体
种群规模表示每一代种群中所含个体数目。随机产生N个初始串结构数据,每个串结构数据成为一个个体,N个个体组成一个初始群体,N表示种群规模的大小。当N取值较小时,可提高遗传算法的运算速度,但却降低种群的多样性,容易引起遗传算法早熟,出现假收敛;而N当取值较大时,又会使得遗传算法效率降低。一般建议的取值范围是20—100。
(3)适应度检测
根据实际标准计算个体的适应度,评判个体的优劣,即该个体所代表的可行解的优劣。本例中适应度即为所求的目标函数;
(4)选择
从当前群体中选择优良(适应度高的)个体,使它们有机会被选中进入下一次迭代过程,舍弃适应度低的个体。本例中采用轮盘赌的选择方法,即个体被选择的几率与其适应度值大小成正比;
(5)交叉
遗传操作,根据设置的交叉概率对交配池中个体进行基因交叉操作,形成新一代的种群,新一代中间个体的信息来自父辈个体,体现了信息交换的原则。交叉概率控制着交叉操作的频率,由于交叉操作是遗传算法中产生新个体的主要方法,所以交叉概率通常应取较大值;但若过大的话,又可能破坏群体的优良模式。一般取0.4到0.99。
(6)变异
随机选择中间群体中的某个个体,以变异概率大小改变个体某位基因的值。变异为产生新个体提供了机会。变异概率也是影响新个体产生的一个因素,变异概率小,产生新个体少;变异概率太大,又会使遗传算法变成随机搜索。一般取变异概率为0.0001—0.1。
(7)结束条件
当得到的解大于等于900时,结束。从而观看遗传的效率问题。
五. 代码及结果:
/*遗传算法设计最大值*/
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <time.h>
#define C 0 //测试
#define CFLAG 4 //测试标记
#define JIAOCHA_RATE 0.5 //交叉概率一般取0.4到0.99
#define BIANYI_RATE 0.09 //变异概率为0.0001-0.1
#define ITER_NUM 1000 //迭代次数
#define POP_NUM 20 //染色体个数
#define GENE_NUM 5 //基因位数
#define FEXP(x) ((x)*(x)) //y=x^2
typedef unsigned int UINT;
//染色体
typedef struct{
char geneBit[GENE_NUM]; //基因位
UINT fitValue; //适应值
}Chromosome;
//将二进制的基因位转化为十进制
UINT toDec(Chromosome pop){
UINT i;
UINT radix = 1;
UINT result = 0;
for(i=0; i<GENE_NUM; i++)
{
result += (pop.geneBit[i]-'0')*radix;
radix *= 2;
}
return result;
}
UINT calcFitValue(UINT x) {
return FEXP(x);
}
void test(Chromosome *pop) {
int i;
int j;
for(i=0; i<POP_NUM; i++)
{
printf("%d: ", i+1);
for(j=0; j<GENE_NUM; j++)
printf("%c", pop[i].geneBit[j]);
printf(" %4d", toDec(pop[i]));
printf(" fixValue=%d\n", calcFitValue(toDec(pop[i])));
}
}
//变异得到新个体:随机改变基因
void mutation(Chromosome *pop) {
UINT randRow, randCol;
UINT randValue;
randValue=rand()%100;
if(randValue >= (int)(BIANYI_RATE*100))
{
#if (C==1) && (CFLAG==4)
printf("\n种群个体没有基因变异\n");
#endif
return ;
}
randCol = rand()%GENE_NUM; // 随机产生将要变异的基因位
randRow = rand()%POP_NUM; // 随机产生将要变异的染色体位
#if (C==1) && (CFLAG==4)
printf("\n变异前\n");
test(pop);
printf("\n变异的位置为:染色体号=%d 基因位号=%d\n", randRow+1, randCol);
#endif
pop[randRow].geneBit[randCol] = (pop[randRow].geneBit[randCol]=='0') ? '1':'0'; //1变为0, 0变为1
pop[randRow].fitValue = calcFitValue( toDec(pop[randRow]) );
#if (C==1) && (CFLAG==4)
printf("\n变异后\n");
test(pop);
#endif
}
//创建初始群体
void createPop(Chromosome *pop){
UINT i,j;
UINT randValue;
UINT value;
srand((unsigned)time(NULL));
for(i=0; i<POP_NUM; i++)
{
for(j=0; j<GENE_NUM; j++)
{
randValue = rand()%2;
pop[i].geneBit[j] = randValue+'0'; // 将随机数0或1赋给基因
}
value= toDec(pop[i]);
pop[i].fitValue = calcFitValue(value);
}
#if (C==1) && (CFLAG==1)
printf("\n随机分配的种群如下:\n");
test(pop);
#endif
}
//更新种群
void updatePop(Chromosome *newPop, Chromosome *oldPop){
UINT i;
for(i=0; i<POP_NUM; i++){
oldPop[i]=newPop[i];
}
}
//选择优良个体:根据适应度选择最优解,即最优个体
void select(Chromosome *pop){
UINT i,j;
UINT sumFitValue; //总适应值
UINT aFitValue; //平均适应值
float choice[POP_NUM]; //选择
Chromosome tempPop; //交换变量
#if (C==1) && (CFLAG==2) //测试
printf("\n没有选择前的种群如下:\n");
test(pop);
#endif
// 根据个体适应度冒泡降序排序
for(i=POP_NUM; i>0; i--)
{
for(j=0; j<(i-1); j++)
{
if(pop[j+1].fitValue > pop[j].fitValue)
{
tempPop = pop[j+1];
pop[j+1] = pop[j];
pop[j] = tempPop;
}
}
}
//计算总适应值
sumFitValue = 0;
for(i=0; i<POP_NUM; i++)
{
sumFitValue += pop[i].fitValue;
}
aFitValue = (UINT)(((float)sumFitValue/POP_NUM)+0.5); //计算平均适应值
//计算出每个群体选择机会,群体的概率=群体适应值/总适应值,平均概率= 平均适应值/总适应值,群体选择机会 = (群体的概率/平均概率)
for(i=0; i<POP_NUM; i++)
{
choice[i] = ((float)pop[i].fitValue/sumFitValue)/((float)aFitValue/sumFitValue);
choice[i] = (float)((int)(choice[i]*100+0.5)/100.0);//保留到小数点后2位
}
//根据选择概率来繁殖优良个体,并淘汰较差个体
for(i=0; i<POP_NUM; i++)
{
if(((int)(choice[i]+0.55)) == 0) //如果choice[i]==0淘汰繁殖一次最优的群体
pop[POP_NUM-1] = pop[0];
}
#if (C==1) && (CFLAG==2)
printf("\n经过选择以后的种群:\n");
test(pop);
#endif
}
//交叉:基因交换
void cross(Chromosome *pop) {
char tmpStr[GENE_NUM]="";
UINT i;
UINT randPos;
UINT randValue;
randValue=rand()%100;
if(randValue >= (int)(JIAOCHA_RATE*100)) {
#if (C==1) && (CFLAG==3)
printf("\n种群没有进行交叉.\n");
#endif
return ; }
#if (C==1) && (CFLAG==3)
printf("\n交叉前,种群如下:\n");
test(pop);
printf("\n交叉的位置依次为:");
#endif
//染色体两两交叉
for(i=0; i<POP_NUM; i+=2) {
randPos = (rand()%(GENE_NUM-1)+1); // 产生随机交叉点,范围是1到GENE_NUM-1
strncpy(tmpStr, pop[i].geneBit+randPos, GENE_NUM-randPos);
strncpy(pop[i].geneBit+randPos, pop[i+1].geneBit+randPos, GENE_NUM-randPos);
strncpy(pop[i+1].geneBit+randPos, tmpStr, GENE_NUM-randPos);
#if (C==1) && (CFLAG==3)
printf(" %d", randPos);
#endif
}
// 对个体计算适应度
for(i=0; i<POP_NUM; i++){
pop[i].fitValue = calcFitValue(toDec(pop[i]) );
}
#if (C==1) && (CFLAG==3)
printf("\n交叉后,种群如下:\n");
test(pop);
#endif
}
//输出结果
void result(Chromosome *pop){
UINT i;
UINT x = 0;
UINT maxValue = 0; // 函数的最大值
for(i=0; i<POP_NUM; i++)
{
if(pop[i].fitValue > maxValue) {
maxValue = pop[i].fitValue;
x = toDec(pop[i]);
}
}
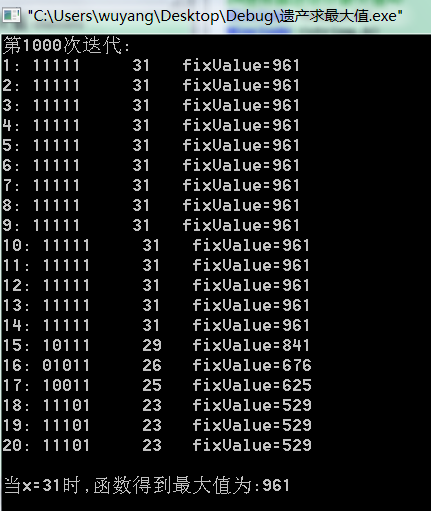
printf("\n当x=%d时,函数得到最大值为:%d\n\n", x, maxValue);
}
int main(int argc, char *argv[]){
int count; //迭代次数
Chromosome curPop[POP_NUM]; //初始种群或者当前总群
Chromosome nextPop[POP_NUM]; //变异后种群
createPop(curPop);
for(count=1; count<(ITER_NUM+1); count++) {
updatePop(curPop, nextPop); // 更新种群
select(nextPop); //选择
cross(nextPop); //交叉
mutation(nextPop); //变异
updatePop(nextPop, curPop); //更新
printf("\n第%d次迭代:\n", count);
test(curPop);
}
result(curPop);
return 0;
}
实验结果:
实验小结:
经过本次实验对遗传算法有了深刻的了解,充分体会到遗传算法对优缺点
,了解了演化算法的基本思想,虽然过程中出现了很多小问题,比如大小写什么的还有就是逻辑错误,但是最终在理解的基础上成功实现了功能,认真分析后,提高了解决问题的能力。
第二篇:人工智能课内实验报告1
人工智能课内实验报告(一)
----主观贝叶斯
一、实验目的
1. 学习了解编程语言,掌握基本的算法实现;
2. 深入理解贝叶斯理论和不确定性推理理论;
3. 学习运用主观贝叶斯公式进行不确定推理的原理和过程。
二、实验内容
在证据不确定的情况下,根据充分性量度LS、必要性量度LN、E的先验概率P(E)和H的先验概率P(H)作为前提条件,分析P(H/S)和P(E/S)的关系。
具体要求如下:
(1) 充分考虑各种证据情况:证据肯定存在、证据肯定不存在、观察与证据
无关、其他情况;
(2) 考虑EH公式和CP公式两种计算后验概率的方法;
(3) 给出EH公式的分段线性插值图。
三、实验原理
1. 知识不确定性的表示:
在主观贝叶斯方法中,知识是产生式规则表示的,具体形式为:
IF E THEN (LS,LN) H(P(H))
LS是充分性度量,用于指出E对H的支持程度。其定义为:
LS=P(E|H)/P(E|¬H)。
LN是必要性度量,用于指出¬E对H的支持程度。其定义为:
LN=P(¬E|H)/P(¬E|¬H)=(1-P(E|H))/(1-P(E|¬H))
2. 证据不确定性的表示
在证据不确定的情况下,用户观察到的证据具有不确定性,即0<P(E/S)<1。此时就不能再用上面的公式计算后验概率了。而要用杜达等人在1976年证明过的如下公式来计算后验概率P(H/S):
P(H/S)=P(H/E)*P(E/S)+P(H/~E)*P(~E/S) (2-1)
下面分四种情况对这个公式进行讨论。
(1) P(E/S)=1
当P(E/S)=1时,P(~E/S)=0。此时,式(2-1)变成
P(H/S)=P(H/E)=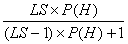 (2-2)
(2-2)
这就是证据肯定存在的情况。
(2) P(E/S)=0
当P(E/S)=0时,P(~E/S)=1。此时,式(2-1)变成
P(H/S)=P(H/~E)=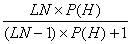 (2-3)
(2-3)
这就是证据肯定不存在的情况。
(3) P(E/S)=P(E)
当P(E/S)=P(E)时,表示E与S无关,则利用全概率公式可知:
P(H/S)=P(H/E)*P(E)+P(H/~E)*P(~E)=P(H) (2-4)
即观察与证据无关,观察与结论无关。也就是说,该观察不影响结论,所以在该观察下,结论的概率没有变,还是原来的先验概率。
(4) 其他情况
当P(E/S)为其他值时,通过分段线性插值可计算出P(H/S)。具体公式如下:
P(H/S)=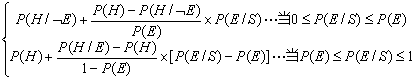 (2-5)
(2-5)
该公式称为EH公式或者UED公式。
3. LS和LN的性质
(1) LS>1: 表明证据E是对H有利的证据。
LN>1: 表明证据¬E是对H有利的证据。
所以:不能出现LS>1且LN>1的取值。
(2) LS<1: 表明证据E是对H不利的证据。
LN<1:表明证据¬E是对H不利的证据。
所以:不能出现LS<1且LN<1的取值
(3) 一般情况下,取LS>1, LN<1。
四、实验程序及运行结果
程序如下:
#include<stdio.h>
#include<graphics.h>
#include<conio.h>
float ls,ln,ph,pe,phs,pes,phne,phe;
int main()
{
printf("please input the value:");
scanf("%f/n",&ls);
scanf("%f/n",&ln);
scanf("%f/n",&ph);
scanf("%f/n",&pe);
initgraph(1000, 600);
if((pes>=0)&&(pes<=pe))
{
phne=(ln*ph)/((ln-1)*ph+1);
phs=phne+((ph-phne)*pes/pe);
initgraph(1000, 600);
line(1000,500,0,500);
line(0,600,0,0);
line(0,phne*500,pe*500,ph*500);
}
if((pes>=pe)&&(pes<=1))
{
phe=(ls*ph)/((ls-1)*ph+1);
phs=ph+(phe-ph)*(pes-pe)/(1-pe);
initgraph(1000, 600);
line(1000,500,0,500);
line(0,600,0,0);
line(pe*500,ph*500,1*500,phe*500);
}
getch();
closegraph();
}
程序运行截图如下:
输入 ls=100 ln=0.1 ph=0.6 pe=0.4
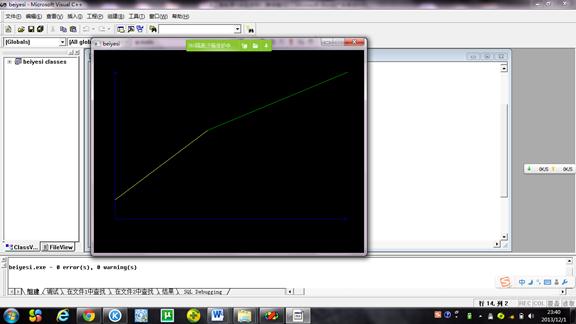
五、实验体会和感想
通过输入自己定的LS、LN、P(E)、P(H)等值,经程序计算判断出属于证据不确定的哪种情况,就可以画出EH公式的分段线性插值图。
通过这个实验,初步了解了人工智能理论中关于不确定性算法的知识。通过分类各个情况,了解了不同情况下的的计算方法。我也更加深入地理解了主观Bayes方法的实质及其特点,根据先验概率的条件不同来分析后验概率,利用它们之间的关系,更好的了解不确定性推理方法。