新钢铁行业套期保值效果研究拟案
一、 研究背景与研究目的
企业使用套期保值是否能够帮助提升企业价值一直是存在争议的。早期的MM定理认为,公司的资本结构与公司价值无关的,企业无论以负债筹资还是以权益资本筹资都不影响企业的市场总价值。总之,企业的价值,投资决策都与是否使用金融衍生工具无关。但是,MM定理是以完美资本市场假定为前提的。完美资本市场主要包括了以下假定:
1. 无市场交易成本,可自由交易,且所有证券都是无限可分的
2. 没有税收,既不存在企业所得税,也不存在个人所得税
3. 公司的经营不存在信息不对称问题
4. 企业永续经营,不存在破产成本
5. 投资者可以进行各种套利活动,均无套利成本
显然,这些假设是不符合任何现实中市场情况的,此后许多研究人员逐渐放宽这些假设条件,提出各种理论为企业运用衍生金融衍生工具能够提升企业价值提供理由。现代学者认为企业使用衍生品进行风险管理能够提升企业价值的主要原因有:
1. 降低收益波动率,从而降低外部融资成本
2. 降低资本成本,加强资金使用效率
3. 降低现金流波动性,使企业接受净现值为正的投资项目,通过这些项目获取更多的利润
4. 降低财务困境成本,降低预期财务困境成本
有色行业借助金融衍生品进行套期保值已有较长历史,针对有色行业套期保值有效性的研究报告已有很多,同样的不少研究者也对航空行业使用原油期货提升企业价值,农产品行业的相关报告也有不少。对于钢铁行业来说,期货是比较新的概念,钢材期货品种上市才5年而已,在商品衍生品中属于历史较短品种。本次报告将以我国钢铁行业为例,实证分析钢铁企业使用金融衍生品进行风险管理对企业价值的影响。
二、 实证研究
本文将分成两个部分进行研究。第一部分以20##-20##年我国钢铁行业沪、深两市20家上市公司作为研究样本,通过收集相应财务数据来检验套期保值对于企业价值的影响。第一部分的数据主要从上交所、深交所公布的企业年报和WIND数据库获取。第二部分则是针对非上市企业和中小型企业的调查,由于搜集相关财务数据较为困难,本文将通过调查问卷的方式来检测套期保值与企业价值之间的关系。(调查问卷式样见附件)
第一部分:我国上市钢铁企业使用钢材期货对企业价值影响的实证检验
检验假设:
企业价值的最大化就是为企业、为股东创造财富最大化,这是目前比较被认同的财务管理的根本目的。金融衍生品的使用对于企业价值是否会产生影响,这是这一部分的主要研究目标。
首先我们提出的假设是:上市钢铁企业使用金融衍生品套期保值能够提升企业的价值,即金融衍生品的使用与企业价值正相关。衡量上市企业价值学术界比较认可的指标为托宾Q值和经济附加值(EVA)等,本文将使用前者作为衡量依据,托宾Q值近几年在国内市场得到了广泛的应用。
模型的选择:
为发现一个变量对于另一个变量的影响情况,最简单的方式就是通过使用线性回归来验证。在实际问题中,由于一个变量往往是受到多个变量的影响,多元线性回归模型是最常用的模型之一。本文中我们将要使用的是多元线性回归模型的描述三个维度的面板数据模型(Panel Data Model)。考虑用此模型的原因很简单,首先我们分别在时间维度(20##-20##年)和个体维度(20家上市钢铁企业)拥有样本,其次单在时间序列上的样本量是明显不足的,面板数据模型是最佳选择。面板数据模型又能分为混成模型、个体固定效应模型、时间固体效应模型、个体时间固定效应模型、随机效应模型等多种形式,具体哪一种模型是最适合的,本文将在随后的“模型使用”环节进行深入分析。
变量的选择:
1. 被解释变量(因变量Y)
第一部分被解释变量选取的是TOBINQ值,以反映上市钢铁企业的价值。经济学家James Tobin对TOBINQ值定义为企业的市场价值与资本重置成本之比,即企业利用已有资源区创造价值的能力。当TOBINQ值大于1时,表明企业用其已有资源创造了新的价值。当该值小于1时,意味着企业的市值小于重置成本,企业的资产增长对企业价值产生负影响。理论上从长期来看,企业的市值将恢复至与资产重置成本相近的水平,即TOBINQ值趋向于1。TOBINQ的计算公式为:
TOBINQ = 
2. 解释变量(自变量X)
第一部分的解释变量主要包括以下几项
(i) 是否使用期货进行套期保值----YN
此变量为支持我们假设的解释变量,”1”代表参与了套期保值,“0”表示未参与套期保值。
(ii) 资产负债率----DR
资产负债率被选为代表公司资本结构的解释变量。按照企业风险控制的理念,通过降低股利支付率、发行可转换债券等表内方法实行风险控制,故企业的资本结构也是会影响到企业风险以及企业的价值。
(iii) 总资产收益率----ROA
总资产收益率被选作代表企业盈利能力的解释变量。盈利能力强的企业通常会给市场传递正面信号,从而提升企业价值。
(iv) 流动比率----LI
流动比率是流动资产对流动负债的比率,用来衡量企业流动资产在短期债务到期以前,可以变为现金用于偿还负债的能力。通常我们认为流动性较高的企业偿债能力较强,给予投资者更高的信心,但许多企业被自身所处行业所局限,流动比率普遍不高。
(v) 公司规模----CS
从规模经济的角度来看,规模较大的企业通常掌握资源、人才和低成本优势,有能力创造更大的价值。但也有说法认为,规模大的企业运营灵活度较低,会给企业造成负面影响。
(vi) 固定资产占比----FR
固定资产与总资产的比值被用作表示公司资产结构的解释变量。资产结构的不同会导致企业面临不同的经营风险,从而影响其自身价值。通常来讲,固定资产比例较高的企业的经营风险较大,因而会对企业价值带来负面影响。
模型的使用
面板数据:
时间序列数据或截面数据都是一维数据;截面数据是变量在界面空间上的数据。面板数据则是同时在时间和截面空间上取得的二维数据,故面板数据又称时间序列截面数据。用我们的数据举例:20##-20##年20家上市钢铁企业。固定在某一年份上,它是由20家钢铁企业的相关财务数据组成的截面;固定在某一家企业上,它是由4年数据组成的一个时间序列。我们的面板数据由20个个体组成。共80个观测值,并且由于从横截面上看,每个变量都有观测值,从纵剖面上看,每一期都有观测值,我们的面板数据属于“平衡面板数据”。
面板模型:
用面板数据建立的模型通常有三种。即混合模型、固定效应模型和随机效应模型。面板模型的基本公式为:
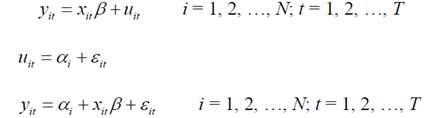
当模型中的参数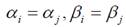 ,即斜率和截距系数不变时,模型将不考虑个体和时间的影响,称为混合模型。
,即斜率和截距系数不变时,模型将不考虑个体和时间的影响,称为混合模型。
当模型参数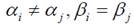 ,即截距系数不等,斜率系数相等时,此时模型为变截距模型。并且当ai为常数,此时的模型为固定效应模型。固定效应模型又可分为个体固定效应模型、时间固定效应模型和个体时间固定效应模型。而当ai为随机变量时,面板数据模型被称为随机效应模型。
,即截距系数不等,斜率系数相等时,此时模型为变截距模型。并且当ai为常数,此时的模型为固定效应模型。固定效应模型又可分为个体固定效应模型、时间固定效应模型和个体时间固定效应模型。而当ai为随机变量时,面板数据模型被称为随机效应模型。
模型的选择:
本报告的第一部分所有模型测试将借助R语言软件执行。
(1)混合模型
首先当我们不考虑个体(钢铁企业)和时间轴对于数据组产生影响,即使用混合模型进行回归。以下为模型检验结果:
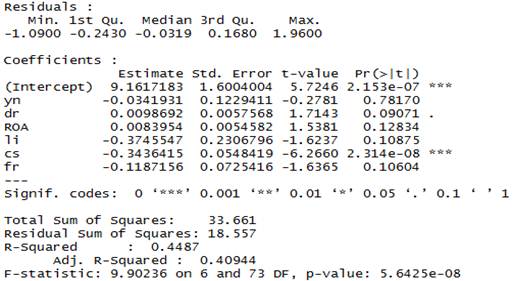
从以上回归结果可以看出,R^2=40.94(调整后),F=9.9,表明模型拟合度一般。自变量中只有企业规模这一个变量对企业价值有影响,在1%的水平下是显著的,其它变量均无显著相关性。所以当我们不考虑个体与时间对于数据的不同影响时,似乎模型拟合存在存在一定问题。
(2)固定效应模型
我们分别对数据做出个体固定效应模型、时间固定效应模型,发现两者模型都有较好的效果,意味着时间与个体的维度都会对数据产生影响,于是我们考虑使用个体时间固定双效应模型。但固定效应模型是否真的优于混合模型,需要通过F检测进行进一步测试,以下为检测结果:

此处的F检验原假设为不同横截面,不同序列,模型截距项都是相同的,检验结果告诉我们拒绝原假设,即我们应该要考虑建立时间个体固定效应模型。
(3)随机效应模型
通过卡方检验发现,P值在10%的显著性水平下都是不显著的,意味着我们的数据不存在个体随机效应,故没有必要进行进一步建模与检验,以下为检验结果:

模型结果:
通过以上的一系列分析,最终我们将选用个体时间固定效应模型作为最终模型,该模型的结果如下:
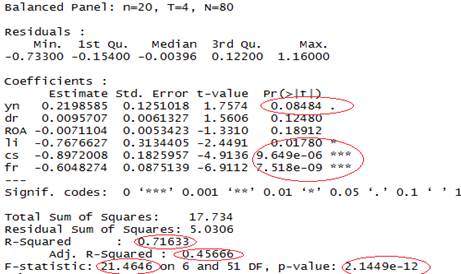
从回归结果上来看,R^2值高达71.2%,调整后45.6%,F值为21.47,P值在1%水平下是显著的,以上指标表明模型的拟合程度较好。解释变量YN的系数大于0,并且它的P值在10%水平下显著,表明我们一开始的假设是成立的,即上市钢铁企业运用钢材期货进行套期保值对企业价值有正面效应。通过原始数据发现,虽然许多企业是从20##年才开始使用钢材衍生品,企业风险控制管理水平有限,但使用后的效果确实是对于企业价值有提升作用的。
此外,回归结果显示:流动比率(LI)与企业价值呈现负相关性,流动比率是流动资产和流动负债之比,通常与企业价值关系为正相关,因为流动比率高的企业意味着其有较强的偿债能力与变现能力。本文对于出现负相关关系的理解是,钢铁企业的偿债能力本身就较弱,企业的财务负担压力较大,资金风险较高。企业需要通过投资高成本固定资产来创造价值;企业规模(CS)与企业价值呈现负相关性;固定资产占比(FR)较高与企业价值呈负相关性。固定资产比重较高的企业调整资产结构的难度相对较大,对于企业自身的经营会带来更大的风险,企业价值也会打折扣。
第二部分:我国非上市钢铁企业使用套期保值工具对企业价值的影响
我国多数参与钢材期货市场进行套期保值的企业并非为上市企业,而是中小型钢铁生产企业和贸易企业。这些企业较大型上市公司参与期货市场具备更高的灵活性。报告第二部分将对这部分企业参与期货交易与提升价值之间的关系进行检验。
由于无法直接获取相应企业的财务数据,本文将以调查问卷方式,将收集到的定性的数据转为定量数据进行分析并得出结论。这部分将使用到二元离散模型Logit模型。
检验假设:
这部分中我们将同样假设使用套期保值将对企业价值产生正面影响。不过我们不再使用某一个指标来反应企业的价值,而是直接使用调查问卷参与者的主观意见,即“20##年企业价值有所提升”或“20##年企业价值没有提升”。
模型的选择:
为了使二元选择问题的研究成为可能,我们必须首先建立随机效用模型,这里我们假设方程的残值符合逻辑分布(Logistic),并使用Logit二元离散模型。
变量的选择:
模型的因变量是虚拟变量,企业价值得到提升设为1,企业价值没有得到提升为0。模型的自变量设定与第一部分的相似,主要包括:公司总资产,主营业务收入,资产负债率,主营业务增长率和企业参与期货市场套期保值的频率。前四个变量分别用-4到4八档来表示,而套期保值频率分为1-4个档位。
模型结果:
通过使用对数极大似然估计,我们分别计算出各个自变量的系数为:

进一步计算LOGIT模型的信息矩阵,我们得到对应自变量的T估计量
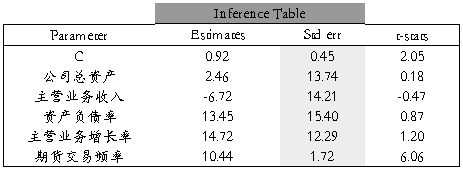
分析检验结果发现,主营业务增长率和期货交易频率的T估计量分别在10%和1%的水平下呈显著效应,故我们得出结论:主营业务增长率的上升对非上市钢铁企业的价值有正面作用;参与套期保值频率较高的企业,其价值也相应更高,符合我们期初的假设。
三、 必要数据收集
*后文有详细介绍
四、 研究结果说明
五、 结论
模型的建立
第一部分使用模型:
多元回归模型将被使用来分析企业价值是否得到提升和企业风险是否有降低。一号企业价值模型的应变量是TOBIN Q, 是否期货代理变量(哑变量)将使用期货的设为1,否则为0.其他相关的控制变量为:
1. 公司规模(年末总资产自然对数)
2. 资产结构(固定资产/总资产)
3. 资本结构 (资产负债率)
4. 企业成长性(主营业务收入增长率)
5. 盈利能力(ROA)
6. 流动比率
二号风险检验模型的应变量为:外部风险/系统性风险(BETA),内部风险(现金流标准差)。是否使用期货变量与之前相同,其他控制变量为:
1. 资产自然对数
2. 资产负债率
3. 流动性比率
第二部分使用模型:
Y仍旧取您认为参与期货交易是对提升企业价值和利润有帮助??
Y取值应该为20##年企业利润是否上涨(但同时补充说明有一项问题是专门问使用套期保值是否增加企业利润率额外选项,补充说明,但不计入模型运算中)
第二部分由于包含了非上市公司作为样本,导致样本数据的搜集难度大大增强。所以我们考虑使用LOGISTIC模型来验证企业价值与套保理念之间的关系。应变量将使用期货设为1,非使用设为0。自变量的设定还将仔细的考虑一下,但主要还是围绕企业的“规格”与“质量”来定。具体设定将在调查问卷中体现。
模型数据收集
由于受时间方面限制,我们没有大量的时间序列上的数据,所以必须采用面板数据来实现建模。
第一部分数据:
企业价值模型所需要的因变量(Y):
TOBIN Q:公式为:Q=(流通股数量*年底收盘价+总负债+非流通股数量*每股净资产)/总资产
企业价值模型所需要的自变量(X):
1. 公司规模:我们用期末总资产的自然对数(Ln Asset)作为资产规模的代理变量。该数据从资产负债表中可获取。公司规模越大,拥有的经济资源越多,会创造的企业价值将会越大。
2. 资本结构:定义为负债总额/资产总额。负债率比作财务杠杆率,杠杆较高者更倾向于使用套保工具。该数据可从公司资产负债表中获取。企业的资本结构会影响到企业的风险以及企业的价值。多数研究表明资产负债率是与企业的价值负相关的。
3. 资产结构:定义为固定资产净额/资产总额。企业的固定资产比例越大,其经营风险就越大,从而对企业价值造成负面影响。我们预期此变量与我们的Y是负相关的。
4. 盈利能力:用资产收益率(ROA)作为变量,数据可从负债与利润表上获取。公式为净利润/总资产额。直观理解,盈利强,企业价值高。
5. 企业成长性:我们将使用主营业务收入增长率作为代表企业成长性的一个代理指标。(今年收入-去年收入)/去年收入。企业成长性越高,表明企业未来现金流入量将会增大。所以它应该是与企业价值正相关的。
6. 流动比率:(流动资产/流动负债)比例越高说明企业变现能力越强。但由于每个行业具体情况不同,针对钢铁行业来说比率不会太高。(11年是1.4左右,近几年有可能更低)
风险检验模型所需要的因变量(Y):
用市场的股票BETA值作为衡量系统性风险(因市场因素不可回避风险),和用企业自身现金流标准差(波动性)作为衡量企业内部风险。(个人认为用这个来衡量使用期货是否降低企业内部风险有些牵强,因为钢铁行业由于受到资金链不稳定等因素其现金流的波动往往有多重因素导致(如资金链断裂,去库存,固定资产投资等),不一定很受期货方面的影响)还有就是现金流波动性在数据取得上难度较大。
风险检验模型所需要的自变量(X):
与上一模型中的一些变量相同(主要是一些会影响现金流波动性的变量)
1. 是否使用期货
2. 资产规模
3. 负债率
4. 流动性
第二部分模型:
这个部分由于受到严重的信息不对称,样本数据难以取得以及精准度欠缺等因素。我们要用定量的方法来解决定性的问题,本文将要使用的最好的方法就是使用二元离散模型(LOGISTIC)模型来实现。
模型的因变量是虚拟变量,使用期货的设为1,否则为0.
模型的自变量设定主要在规模和质量两方面。
规模包括:企业规模,产量,市场占有率,销售量等
质量包括:盈利水平,负债率等
具体变量设定还需进一步分析
难点:此模型需要用到面板数据+二元离散模型,需要花费大量的时间来处理数据。还有就是通过调查问卷来获取的样本数量,采集率有限,需要时间来补充完整。
总结:第一部分将作为第二部分的一个类似于实验性质的模型检验。其优势是信息获取相对简易。重要性上我们可以选取一些对于期货市场参与度较高的上市钢企(比如那些拥有交割品牌的企业)作为样本来建模,看看效果如何。第二部分则是一个漫长的制作过程,需要对变量进行周全的考虑和设定。
附录:
第一部分R语言程序代码:
######钢铁套期保值效果与企业价值关系之面板数据
library(plm)
pdata=read.csv(file="gt.csv",header=T)
pdata
pdata=plm.data(pdata)
pdim(pdata)
####################混合模型(无视个体效应)
part1.1=plm(TOBINQ~yn+dr+ROA+li+cs+fr,data=pdata,model="pooling")
##个体固定效应模型
summary(part1.1)
part1.2=plm(TOBINQ~yn+dr+ROA+li+cs+fr,data=pdata,model="within",effect="individual")
summary(part1.2)
##时间固定效应模型
part1.3=plm(TOBINQ~yn+dr+ROA+li+cs+fr,data=pdata,model="within",effect="time")
summary(part1.3)
##分别比较个体与混合/时间与混合模型
pFtest(part1.2,part1.1)
pFtest(part1.3,part1.1)
##时间个体固定效应模型
part1.4=plm(TOBINQ~yn+dr+ROA+li+cs+fr,data=pdata,model="within",effect="twoways")
summary(part1.4)
##比较时间个体固定效应模型与混合模型的显著性
pFtest(part1.4,part1.1)
###################随机效应变截距模型(拒绝原假设)
##个体随机效应
random1.1=plm(TOBINQ~yn+dr+ROA+li+cs+fr,data=pdata,model="random",effect="individual")
summary(random1.1)
##检测是否存在个体随机效应
plmtest(TOBINQ~yn+dr+ROA+li+cs+fr,data=pdata,type="bp",effect="individual")
##时间随机效应
random1.2=plm(TOBINQ~yn+dr+ROA+li+cs+fr,data=pdata,model="random",effect="time")
summary(random1.2)
##检测是否存在时间随机效应
plmtest(TOBINQ~yn+dr+ROA+li+cs+fr,data=pdata,type="bp",effect="time")
##########################变系数模型
###固定影响模型
###个体固定效应变系数模型
vfix1=pvcm(TOBINQ~yn+dr+ROA+li+cs+fr,data=pdata,model="within",effect="individual")
##由于观察数据数量有限,无法测量随机效应
第二部分VBA程序代码:
Option Explicit
Function logit(P)
'logit 函数
logit = Log(P / (1 - P))
End Function
Function logistic(xb)
'logistic 函数, logit 链接函数g(u)的倒函数
logistic = Exp(xb) / (1 + Exp(xb))
End Function
Function logit_infmat(data As Range, beta As Range) As Variant
'logit 模型的信息测量
'x 数据的矩阵
'b 测量参变量
Dim Nobs, Nx, i, j, k As Integer
Dim x, xb, b, output As Variant
Dim s As Double
Nobs = data.Rows.Count '观察值数量
Nx = data.Columns.Count '自变量的个数
x = data.Value
b = beta.Value
ReDim output(1 To Nx, 1 To Nx)
ReDim pd(1 To Nobs, 1 To 1)
xb = WorksheetFunction.MMult(x, b) '测量 credit 得分
For i = 1 To Nobs '测量违约概率
pd(i, 1) = logistic(xb(i, 1))
Next i
'测量 logit模型的信息群
For j = 1 To Nx '以行为计算单位
For k = 1 To Nx
s = 0
For i = 1 To Nobs
s = s + pd(i, 1) * (1 - pd(i, 1)) * x(i, j) * x(i, k)
Next i
output(j, k) = s
Next k
Next j
logit_infmat = output
End Function