采用双namenode节点,多datanode节点配置。
在新版本HDFS的配置中,所有节点的配置文件都是统一的(除ssh部分),不用单独配置NameNode和DataNode。
假设我们有三台服务器,主机名分别为fenbu01、fenbu02、fenbu03
fenbu01为namenode节点,fenbu02为datanode节点,fenbu03待用
1、更改各节点hosts文件
vi /etc/hosts
127.0.0.0 localhost localhost
172.xx.xx.10 fenbu01 fenbu01
172.xx.xx.11 fenbu02 fenbu02
172.xx.xx.12 fenbu03 fenbu03
2、创建dbrg用户
useradd -u 500 -g 500 -p 123456 -d /home/dbrg dbrg
在/home/dbrg/下创建hadoopinstall目录
mkdir /home/dbrg/hadoopinstall
3、解压hadoop包
下载地址 /dyn/closer.cgi/hadoop/common/
ftp hadoop到/home/dbrg/hadoopinstall
gzip -d hadoop-0.23.1.tar.gz
tar -xvf hadoop-0.23.1.tar
ln -s hadoop-0.23.1 hadoop
mkdir /home/dbrg/hadoopinstall/hadoop-config
4、SSH配置
在namenode节点上对dbrg用户创建公钥(datanode节点无需操作此步骤)
su dbrg
$ssh-keygen -t rsa
这个命令将为fenbu01上的用户dbrg生成其密钥对,询问其保存路径时直接回车采用默认路径,
当提示要为生成的密钥输入passphrase的时候,直接回车,也就是将其设定为空密码。 $cp id_rsa.pub authorized_keys
$chmod 644 authorized_keys
$scp authorized_keys fenbu02:/home/dbrg/.ssh/
目录结构应该是这样的
[dbrg@fenbu01 .ssh]$ ls -la
drwx------ 2 dbrg dbrg 4096 04-01 15:30 .
drwx------ 5 dbrg dbrg 4096 04-01 15:37 ..
-rw-r--r-- 1 dbrg dbrg 394 04-01 15:32 authorized_keys
-rw------- 1 dbrg dbrg 1675 04-01 15:24 id_rsa
-rw-r--r-- 1 dbrg dbrg 394 04-01 15:24 id_rsa.pub
-rw-r--r-- 1 dbrg dbrg 1192 04-01 15:34 known_hosts
root权限下修改文件/etc/ssh/sshd_config
#去除密码认证
PubkeyAuthentication yes
PasswordAuthentication no
AuthorizedKeyFile .ssh/authorized_keys
service sshd restart
这时候namenode ssh无法直接登陆了,换用xmanager
然后到datanode节点操作
scp到datanode节点的文件记得赋予权限
保证authorized_keys只对其所有者有读写权限,其他人不允许有写的权限,否则SSH是不会工作的。
$chmod 644 authorized_keys
5、配置集群环境
在vi /home/dbrg/.bashrc文件内添加
#hadoop 0.23 required settings
export HADOOP_DEV_HOME=/home/dbrg/hadoopinstall/hadoop #设置你hadoop的路径,需要修改一下
export HADOOP_MAPRED_HOME=${HADOOP_DEV_HOME}
export HADOOP_COMMON_HOME=${HADOOP_DEV_HOME}
export HADOOP_HDFS_HOME=${HADOOP_DEV_HOME}
export YARN_HOME=${HADOOP_DEV_HOME}
export HADOOP_CONF_DIR=/opt/dbrg/hdfs/conf #conf目录也可以按照Hadoop-0.20.*版本的特点设置在${HADOOP_DEV_HOME}/conf文件夹下。
export HDFS_CONF_DIR==/opt/dbrg/hdfs/conf #可单独设置路径
export YARN_CONF_DIR=${HADOOP_DEV_HOME}/conf #可单独设置路径
cd /opt
mkdir dbrg
cd dbrg
mkdir hdfs
cd hdfs
mkdir conf
然后进入hadoop
cd /home/dbrg/hadoopinstall/hadoop
mkdir conf
cp share/hadoop/common/templates/conf/* /home/dbrg/hadoopinstall/hadoop/conf/
cp share/hadoop/common/templates/conf/* /opt/dbrg/hdfs/conf
6、JAVA环境配置
先查看下java的版本情况,要求jdk1.6以上。
#rpm -qa|grep java
如果有安装就会出现安装的jdk的相关信息,太低的java(系统自带)要删除
yum remove java
下载jdk1.6.bin,安装下 /javase/downloads/
vi /etc/profile -------打开profile文件
vi /home/dbrg/.bash_profile
假设jdk的安装目录为:/usr/lib/jvm/java-1.4.2-gcj-1.4.2.0/jre
然后在文件的末尾加上以下三句话
export JAVA_HOME=/usr/java/jdk1.6.0_31/
export
CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin
7、配置hadoop内部环境
1)修改dbrg用户的/home/dbrg/hadoopinstall/hadoop/conf/hadoop-env.sh中的JAVA_HOME路径
export JAVA_HOME=/usr/java/jdk1.6.0_31/
export
CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin
2)修改/home/dbrg/hadoopinstall/hadoop/conf/core-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.trash.interval</name>
<value>360</value>
<description>Number of minutes between trash checkpoints.
</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/dbrg/hadoop</value>
<description>A base for other temporary directories.</description>
</property>
请注意在多个NameNode情况下,core-site.xml不需要设置fs.defaultFS,只需在下面hdfs-site.xml设置对应内容即可。
3)/home/dbrg/hadoopinstall/hadoop/conf/hdfs-site.xml
重新建立/home/dbrg/hadoopinstall/hadoop/conf/hdfs-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name> dfs.namenode.name.dir</name>
<value>/opt/dbrg/hdfs/name</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>/opt/dbrg/hdfs/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/opt/dbrg/hdfs/checkpoint</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>/opt/dbrg/hdfs/checkpoint_edits</value>
</property>
<property>
<name> dfs.datanode.data.dir</name>
<value>/opt/dbrg/hdfs/data</value> </property>
<property>
<name>dfs.federation.nameservices</name> <value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name> <value>fenbu01:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name> <value>fenbu01:50070</value>
</property>
mkdir /opt/dbrg/hdfs/name
mkdir /opt/dbrg/hdfs/edits
mkdir /opt/dbrg/hdfs/checkpoint
mkdir /opt/dbrg/hdfs/checkpoint_edits mkdir /opt/dbrg/hadoop
然后全部chmod 777
4)说明datanode节点
vi /home/dbrg/hadoopinstall/hadoop/conf/slaves fenbu02
同步conf
cp /home/dbrg/hadoopinstall/hadoop/conf/* /opt/dbrg/hdfs/conf/
mkdir /dbrg
chmod 777 /dbrg
有一点注意事项:
把slaves跟这个hadoop-env都移动到/etc/hadoop里面去
8、启动HDFS Federation
1)执行Format
/home/dbrg/hadoopinstall/hadoop/bin/hdfs namenode -format -clusterid hadoop
重新格式化namenode,注意:格式化之前必须删除namenode及datanode上的name、data、tmp文件,防止格式化造成的namespaceID不一致,不过格式化后hdfs上的数据会丢失。
2)启动sbin/start-dfs.sh
/home/dbrg/hadoopinstall/hadoop/sbin/start-dfs.sh
ssh到各个节点上,使用jps命令查看对应的NameNode或者DataNode Daemon是否启动。
9、查看UI界面
浏览器中键入:
http://fenbu01:50070
第二篇:每周学习总结10 hadoop管理命令
1.Hadoop管理命令实践报告:
Dfsamin是一个用来获取HDFS文件系统实时状态信息的多任务工作,具有对于HDFS文件系统管理操作的功能。在拥有超级用户权限的前提下,管理员可以在终端中通过Hadoop dfsadmin对于其进行功能方法的调用。主要命令如下:
-report 主要用来获取文件系统的基本信息和统计信息
-safemode enter!leave!get!wait 安全模式的维护命令。安全模式是NameNode的一种状态。在安全模式状态下:
1) 不接受对于空间名字的更改
2) 无法对数据块进行删除以及复制操作
NameNode会在Hadoop系统启动之后自动开启安全模式,一旦当配置块满足最小百分比的副本数条件时,Hadoop系统会自动关闭安全模式。同时根据用户的需要也可以手动关闭安全模式或者选择手动开启安全模式。
-refreshNode 重新读取hosts和exclude,以实现在添加新的节点后可以使系统直接进行识别。
-finalizeUpgrade 用于终结HDFS文件系统的升级操作。DataNode会删除上一个版本的工作目录。在DataNode完成操作之后,NameNode也会执行这个操作。
-upgradeProgress status!details!force 分别实现获取当前系统升级的状态,升级状态过程中的细节,强制进行系统的升级。
-metasave filename 将hadoop系统中的管理节点的数据结构中的主要部分保存到hadoop.log.dir文件中提前预设好的属性中指定的的对应文件名的目录上。
在此文件中的主要内容如下:
1) 管理节点接收到的数据节点的正常工作的心跳
2) 被复制的数据块的等待状态
3) 被复制的数据块的执行状态
4) 确定要被删除的数据块的等待状态
-setQuota <quota> <dirname>…<dirname> 主要用作为每个指定路径下的文件目录设
定指定的配额。目的是为了强制设定文件目录的名字的字节数。如果出现以下情况将会对Hadoop系统报出错误信息:
1) 文件目录的名字不是一个正整数
2) 当前的操作用户不具有管理员权限
3) 文件目录不存在或者此路径指向的是一个文件而非目录
4) 当设定好的目录生效时会超出新设定的配额
-clrQuota <dirname>….<dirname> 为每个已经分配好的指定路径上的文件目录清除已经设定好的配额。当出现以下情况将会对Hadoop系统报出错误信息:
1) 此目录指定的目录不存在或者该目录为一个文件
2) 当前的操作用户不具有管理员权限
另外一种情况为如果此文件目录如果先前没有设定配额,则使用此操作不会向系统报错
-help [cmd] 显示对于在参数中给定的命令相关的帮主信息,如果在参数中没有给出指定的命令,将会显示出所有命令的帮主信息。
1.1 文件系统验证
在Hadoop系统中提供了一个用于验证HDFS文件系统中的文件是否可以完整读取的的验证命令fsck。主要用于检测文件是否在数据节点的文件中丢失,以及检测对于副本本身的要求过高还是过低。
1.1.1 Fsck的工作机理
Fsck是一款基于Hadoop的SHELL编程命令,通过参数来指定检查的文件以。
Fsck会递归检查整个HDFS文件系统的命名空间,首先从文件系统的root目录开始检测然后检测可以找到的所有文件,并且在验证完毕后对于这个查找到的文件进行一个标记。FSCK对于一个文件的检测主要从可用性和一致性入手。
下面为Fsck的输出属性图:
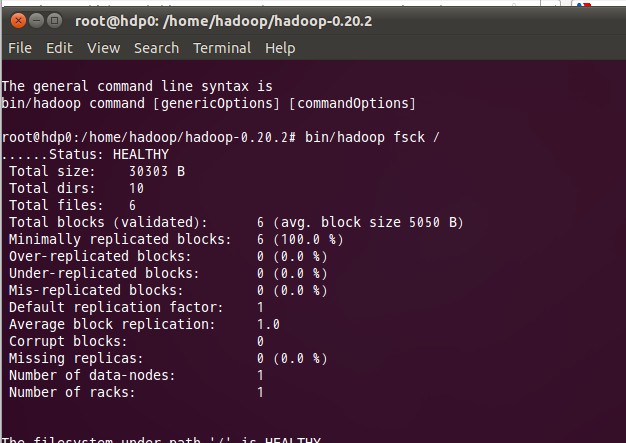
1.1.2 Fsck输出参数说明:
(1)Over-replicated blocks:用来标识所拥有的副本块数已经超出自身所属文件的副本数配额限定的文件。HDFS文件系统在出现这种情况后系统会根据自身副本删除机制对多余的副本进行删除。
(2)Under-replicated blocks: 用来标识所拥有的副本块数未达到自身所属文件的副本数要求的文件。HDFS文件系统在出现这种情况后系统会根据自身副本创建机制自动创建副本直到到达文件要求的副本数。可以通过执行dfsadmin –metasave SHELL命令来获取当前正在被复制的块的信息。
(3)Misrepilcated blocks:用来标识云存储系统中不符合存储位置策略的块。比如说副本因子为3,则代表至少拥有2个副本不在同一个机架上。而如果出现了一个数据块的3个副本都在同一个机架上则此块将被标识。HDFS系统不会自动处理这种标识,需要我们手动设这副本因子的个数。
(4)Corrupt blocks:用来标识所有副本不可用的数据块,只要数据块的副本可用,它就不会被标识。Namenode将会使用没有被Corrupt blocks标识的数据块来进行复制。以达到目标值。
(5)Missing replicas:用来标识机群中没有副本存在的数据块。Corrupt blocks 和Missing replicas是普遍受到最多关注的输出参数。出现以上标识则表明出现了数据不一致性和可用性的问题。
HDFS系统在遇见以上2种问题后可以通过使用如下SHELL脚本命令进行处理。
-move 将被标识的文件放入HDFS文件系统的/lost+found文件夹中。
-delete 将被标识的文件直接进行删除。