SPSS实验操作指导手册(2015版)
2.SPSS数据整理
2.1 SPSS数据文件的建立
SPSS数据文件的建立可以利用【File(文件)】菜单中的命令来实现。具体来说,SPSS提供了四种创建数据文件的方法:
● 新建数据文件【File(文件)】→【New(新建)】→【Data(数据)】命令;
● 直接打开已有数据文件【File(文件)】→【Open (打开)】→【Data(数据)】命令;
● 使用数据库查询;
【File(文件)】→【Open Database(打开数据库)】→【New Query(新建查询)】命令,弹出【Database Wizard(数据库向导)】对话框
● 从文本向导导入数据文件。
【File(文件)】→【Read Text Data(打开文本 数据)】命令,弹出【Open Data(打开数据)】对话框
实例分析:股票指数的导入
文件2-1.xls是上证指数从20##年1月4日至20##年10月16 日的数据资料,包括了开盘价、当日最高价、当日最低价和收盘价等选项,请将该数据导入至SPSS中。
2.2 SPSS数据文件的属性
一个完整的SPSS文件结构包括变量名称、变量类型、变量名标签、变量值标签等内容。
注意:SPSS数据文件中的一列数据称为一个变量,每个变量都应有一个变量名。SPSS数据文件中的一行数据称为一条个案或观测量(Case)
2.2.1 实例分析:员工满意度调查表的数据属性设计
1.实例内容
为了提高员工的工作积极性,完善公司各方面管理制度,并达到有的放矢的目的,某公司决定对本公司员工进行不记名调查,希望了解员工对公司的满意情况。请根据该公司设计的员工满意度调查题目(行政人事管理部分)的特点,设计该调查表数据在SPSS的数据属性。
2.实例操作
具体步骤如下文件(2-2.sav.)
Step01:打开SPSS中的Data View窗口,录入或导入原始调查数据。
Step02:选择菜单栏中的【File(文件)】→【Save (保存)】命令,保存数据文件,以免丢失。
Step03:单击SPSS中的【Variable View(变量视图)】选项卡,按窗口提示进行数据属性的定义,如变量名称、标签、标签值等。
2.3 SPSS数据文件的整理
【Data(数据)】菜单中的命令主要用于实现数据文件的整理功能。
2.3.1 观测量排序:地区生产总值分析
1.操作详解
Step01:打开观测量排序对话框【File(文件)】→ 【Data(数据)】→【Sort Cases(排序个案)】命令
Step02:选择排序变量
Step03:选择排序类型
Step04:单击【OK】按钮,此时操作结束。
2.实例内容:地区生产总值分析
数据2-3.sav列出了20##年我国部分省份的地区生产总值及第一产业、第二产业和第三产业的生产总值,请根据这些数据分析不同省份经济发展状况的差异性。
2.3.2数据的转置: 国家财政分项目收入
1.操作详解
Step01:打开转置对话框
【File(文件)】→ Data(数据)】→【Transpose(转置)】命令
Step02:选择转置变量
Step03:新变量命名
Step04:单击【OK】按钮,操作结束。
注意:数据文件转置后,数据属性的定义都会丢失,因此用户要慎重选择本功能。
2.实例内容:国家财政分项目收入数据(2-4.sav)
2.3.3文件合并:固定资产投资
【data(数据)】→【Merge Files(合并文件)】菜单中有两个命令选项:【Add Cases(添加个案)】和【Add Variables(添加变量)】。
1. 观测量合并的SPSS操作详解
Step01:打开观测量合并对话框
【File(文件)】→【Data(数据)】→ 【Merge Files(合并文件)】→【Add Cases(添加个案)】命令
Step02:选择合并文件
点选【An external SPSS Statistics data file(外部SPSS Statistics数据文件)】单选钮,同时单击【Browse】按钮,选中需要合并的文件,并指定文件路径,然后单击【Continue】按钮。
Step03:选择合并方法。
Step04:单击【OK】按钮,操作结束。
2.变量合并的SPSS操作详解
Step01:打开变量合并对话框。
Step02:选择合并文件。
Step03:选择合并方法。
Step04:单击【OK】按钮,操作结束。
3. 实例内容:固定资产投资文件的合并
已知2-5-1.sav、2-5-2.sav和2-5-3.sav中的数据是北京、天津、河北等省市在20##年部分行业的固定投资额(亿元)数据,请完成以下问题。
问题一:将2-5-1.sav和2-5-2.sav的数据文件纵向合并(观测量合并)。
问题二:将2-5-1.sav和2-5-3.sav的数据文件横向合并(变量合并)。
2.3.4 数据分类汇总:城乡居民储蓄存款
对数据进行分类汇总就是按指定的分类变量值对所有的观测量进行分组,对每组观测量的变量求描述统计量,并生成分组数据文件。例如,将一个工厂的数据资料,按照该工厂的各个部门进行分组,并统计各个部门的人员年龄均值、方差等,这些工作就属于数据分类汇总的范畴。
1.数据分类汇总的SPSS操作详解
Step01:打开数据汇总对话框
【File(文件)】→【Data(数据)】→【Aggregate(分类汇总)】命令
Step02:选择分类变量; Step03:选择汇总变量
Step04:选择汇总函数; Step05:添加变量标签
Step06:选择汇总结果保存方式
Step07:大规模数据的排序选择
Step08:完成上述操作后,单击【OK】按钮,操作结束
2. 实例内容:城乡居民人民币储蓄存款
我国部分省份20##年度城乡居民的人民币储蓄存款金额(年底余额,单位:亿元)
2.3.5 数据文件的拆分Split
1.数据分类汇总的SPSS操作详解
Step01:打开数据拆分对话框
【File(文件)】→ 【Data(数据)】→【Split File(拆分文件)】命令
Step02:选择数据拆分方式。
Step03:选择拆分变量。
Step04:单击【OK】按钮,操作结束。
2. 实例内容:分行业职工平均工资
20##年我国部分按细行业划分的职工平均工资,请根据不同的行业类型,对原始数据进行拆分,数据详见2-7.sav。
2.3.6 选择数据:城市设施水平
1.操作详解
Step01:打开数据选择对话框
【File(文件)】→【Data(数据)】→【Select Cases(选择个案)】命令
Step02:选择数据选择方式
单击【If】按钮——单击【Sample】按钮——单击【Range】按钮
Step03:选择输出方式
Step04:单击【OK】按钮,操作结束
2. 实例内容:城市设施水平
数据文件2-8.sav中是20##年我国部分地区城市设施水平指标,包括城市用水普及率、城市燃气普及率等。请根据这些原始数据,按照以下条件选择数据。
条件一:选择城市用水普及率和城市燃气普及率都大于90%的地区。
条件二:随机选取10个地区。
条件二属于随机选择的问题,因此需要点选【Random samples of cases(随机个案样本)】单选钮,同时在弹出的【Select Cases:Random Sample(选择个案:随机样本)】对话框的“Exactly cases form the fiirst cases”文本框中分别输入10和31,表示从31个观测量中选择10个观测量。最后,单击【Continue】按钮返回主对话框,随机选取的样本结果如下页所示。
2.3.7 数据加权:蔬菜的平均价格
权重是数据分析中的一个重要概念,它是一个相对的概念。权重的大小描述了该指标在整体评价中的相对重要程度。在数据处理中,常需要对数据进行加权处理。
1. 数据加权的SPSS操作详解
Step01:打开数据加权对话框
【File(文件)】→【Data(数据)】→【Weight cases(加权个案)】命令
2. 实例内容:蔬菜的平均价格
某经销商希望掌握菜市场的蔬菜销销售的平均价格,收集数据见数据文件2-9.sav。现请利用这些数据,求出这些蔬菜的平均价格。
Step1:以蔬菜的销售量 为权重计算各种蔬菜销售的平均价格更为合适。
选择“销售量”变量作为权重变量,将其放入【Frequencies Variable(频率变量)】列表框中
Step02:选择变量是否加权, 用户首先选择是否对观测量进行加权。
Step03:单击【OK】按钮,操作结束。
2.4 SPSS数据的计算和变换
2.4.1 变量计算:国内生产总值的产业构成
1. SPSS操作详解
【File(文件)】→ 【Transform转换】→【Compute(计算)】命令
Step02:定义新变量及其类型
在【Target Variable(目标变量)】文本框中用户需要定义目标函数名,它可以是一个新变量名,也可以是已经定义的变量名。
Step03:输入计算表达式
Step04:条件样本选择
2.实例内容:国内生产总值的产业构成
数据文件2-10.sav为我国1978-20##年国内生产总值、第一产业国内生产总值、第二产业国内生产总值和第三产业国内生产总值,请分析不同产业所占国内生产总值的变动情况。
Step01:打开对话框
Step02:定义第一产业比重变量
Step03:计算第一产业生产总值所占比重
Step04:完成操作
2.4.2 变量重新赋值:空气质量等级划分
SPSS的【Transform(转换)】菜单中有【Recode into Same Variable(重新编码为相同变量)】和【Recode into Different Variable(重新编码为不同变量)】两个命令可以实现重新赋值功能。
1. SPSS操作详解
Step01:打开重新赋值对话框
【File(文件)】→【Transform(转换)】→【Recode into Different Variable】
Step02:选择重新赋值变量和输出变量
Step03:设置重新赋值规则
Step04:选择样本赋值
Step05:最后单击【OK】按钮,此时操作结束
2.实例内容:空气质量等级的划分
我国部分城市20##年空气质量的指标数据(见数据文件2-11.sav),请利用这个规则对不同城市的空气质量等级进行划分。
2.4.3 变量值计数: 消费价格指数的上涨项目
1.SPSS操作详解
Step01:打开重新赋值对话框
【File(文件)】→【Transform(转换)】→【Count Values within Cases(对个案内的值计数)】命令
Step02:输入目标计数变量
Step03:选择计数变量
Step04:设置计数规则
Step05:选择样本计数
Step06:最后单击【OK】按钮,此时操作结束
2.实例内容:消费价格指数的上涨项目
我国城市和农村居民消费价格分类指数数据见数据文件2-12.sav。由于不同产品的价格涨跌不同,请找出城市和农村居民消费价格指数都较去年上涨超过1%的项目。
3.SPSS描述性统计分析
【Descriptive Statistics 】菜单中。最常用的是列在最前面的四个过程。
● Frequencies:产生频数表。
● Descriptives:进行基本的统计描述分析。
● Explore:探索性分析。
● Crosstabs:列联表分析。
3.1 SPSS在频数分析中的应用
3.1.2 频数分析的SPSS操作详解
Step01:打开主窗口
选择菜单栏中的【Analyze(分析)】→【Descriptive Statistics(描述性统计)】→ 【Frequencies(频率)】命令
Step02:选择分析变量
Step03:输出频数分析表
勾选【Display frequency tables(显示频率表格)】复选框
Step04:其他基本统计分析
还可以单击【Statistics(统计量)】和【Charts(图表)】等按钮
Step05:输出格式选择
单击【Format】按钮
Step06: 完成操作
单击【OK】按钮,结束操作,SPSS软件自动输出结果。
3.1.3 实例图文分析:产品的销售量(见数据文件3-1.sav)
假设某公司每周大约卖出2000万件产品,但市场的需求不稳定,该公司的生产经理想更好的掌握近期该产品的分布情况。假设下面给出的销售数字(单位:百万)代表近期公司该产品每周的销售数据。利用频数分析你能得到什么有助于生产及销售的信息?
24 18 18 26 24 23 16 18 21 20 21 24 19 19 14 22 21 26 27
15 19 17 20 20 19 22 23 16 23 21 15 19 21 20 22 15 24 19
3.2 SPSS在描述统计分析中的应用
3.2.2 描述统计分析的SPSS操作详解
Step01:打开主窗口
【Analyze(分析)】→ 【Descriptive Statistics(描述性统计)】→【Descriptives(描述)】命令
Step02:选择分析变量
Step03:计算基本描述性统计量
Step04:保存标准化变量
勾选【Save standardized values as variables(保存标准化变量值)】复选框
Step05: 完成操作
单击【OK】按钮,结束操作,SPSS软件自动输出结果。
3.2.3 实例图文分析:奥斯卡获奖者的年龄(见数据文件3-2.sav)
请你分析不同性别演员获得奥斯卡奖的年龄差异性。
男演员:32 37 36 32 51 53 33 61 35 45 55 39 76 37 42 40 32 60 38 56 48 48 40 43 62 43 42 44 41 56 39 46 31 47 45 60
女演员:50 44 35 80 26 28 41 21 61 38 49 33 74 30 33 41 31 35 41 42 37 26 34 34 35 26 61 60 34 24 30 37 31 27 39 34
3.3 SPSS在探索性分析中的应用
1.使用目的:探索性数据分析(Exploratary Data Analysis,简称EDA)的基本思想是从数据本身出发,不拘泥于模型的假设而采用非常灵活的方法来探讨数据分布的大致情况,也可以为进一步结合模型的研究提供线索,为传统的统计推断提供良好的基础和减少盲目性。
2.主要内容:检查数据是否有错、获得数据分布特征、对数据的初步观察,发现一些内在规律。
3.3.2 探索性分析的SPSS操作详解
SPSS中的Explore过程用于计算指定变量的探索性统计量和有关的图形。它既可以对观测量整体分析,也可以进行分组分析。从这个过程可以获得箱线图、茎叶图、直方图、各种正态检验图、频数表、方差齐性检验等结果,以及对非正态或正态非齐性数据进行变换,并表明和检验连续变量的数值分布情况。
Step01 打开主窗口
【Analyze(分析)】→ 【Descriptive Statistics(描述性统计)】→【Explore(探索)】命令
Step02 选择分析变量
Step03 选取分组变量
Step04 选择标签值
Step05 选择输出类型
Step06 描述性统计量结果输出
Step07 统计图形结果输出
Step08 选择缺失值的处理方式
Step09 操作完成
3.3.3 实例图文分析:中国南北城市的温度差异
Step01:打开对话框
打开数据文件3-3.sav,其中增加变量“地域”表示所在城市的区域位置,“1”表示南方城市,“2”表示北方城市。选择菜单栏中的【Analyze(分析)】→【Descriptive Statistics(描述性统计)】→【Explore(探索)】命令,弹出【Explore(探索)】对话框。
3.4 SPSS在列联表分析中的应用
3.4.2 列联表分析的SPSS操作详解
Step01 打开主窗口
选择菜单栏中的【Analyze(分析)】→【Descriptive Statistics(描述性统计)】→【Crosstabs(列联表)】命令
Step02 选择行、列变量
Step03 选择层变量
Step04 列联表输出格式的选择
Step05 行、列变量相关程度的度量
Step06 选择列联表单元格的输出类型
Step07 选择列联表单元格的输出排列顺序
Step08 完成操作
3.4.3 实例图文分析:大学生身体素质调查
在一次上海大学生身体素质的实际调查中,选择了部分大专院校的学生进行实际问卷调查,收集的数据见3-4.sav。调查内容主要 包括:性别、出生日期、身高、体重、血型、教育背景、学科、男女身高级别和男女体重级别等内容。请根据调查数据分析下面问题:
(1)进行“性别”和“体重级别”双因素交叉作用下的列联表分析,并研究“性别”对“体重级别”有无显著性影响。
(2)进行“教育背景”和“身高级别”双因素交叉作用下的列联表分析,并研究“教育背景”对“身高级别”有无显著性影响。
4.SPSS的均值比较过程
SPSS主要有以下模块实现均值比较过程。
● One-Sample T Test:单样本t检验。
● Independent-Sample T Test:两个独立样本均值的t检验。
● Paired-Sample T Test:两个配对样本均值的t检验。
4.1 SPSS在单样本t检验的应用
单样本t检验的目的是利用来自某总体的样本数据,推断该总体的均值是否与指定的检验值之间存在明显的差异。它是对总体均值的假设检验。
如果概率P值小于或等于显著性水平,则拒绝零假设;
如果概率P值大于显著性水平,则接受零假设。
4.1.2 单样本t检验的SPSS操作详解
Step01:打开单样本t检验对话框
【Analyze(分析)】→【Compare Means(比较均值)】→【One-Sample T Test(单样本T检验)】命令
Step02:选择检验变量
Step03:选择样本检验值
Step04:其他选项设置
Step05:单击【OK】按钮结束操作,SPSS软件自动输出结果
4.1.3 实例图文分析:交通通勤时间(见数据文件4-1.sav)
1. 实例内容
根据一份公共交通调查报告显示,对于那些在一个城市乘车上下班的人来说,平均通勤时间为19分钟,其人数总量为100万—300万。假设一个研究者居住在一个人口为240万的城市里,想通过验证以确定通勤时间是否和其他城市平均水平是否一致。他随机选取了26名通勤者作为样本,收集的数据如下所示。假设通勤时间服从正态分布,这位研究者能得到什么结论?
19 16 20 23 23 24 13 19 23 16 17 15 14
27 17 23 18 18 20 18 18 18 23 19 19 28
2.实例操作(略)
4.2 SPSS在两独立样本t检验的应用
4.2.2 两独立样本t检验的SPSS操作步骤
Step01:打开两独立样本t检验对话框。
【Analyze(分析)】→【Compare Means(比较均值)】→【Independent- Samples T Test(独立样本T检验)】命令
Step02:选择检验变量
Step03:选择分组变量
Step04:定义组别名称
Step05:单击【OK】按钮,结束操作,SPSS软件自动输出相关结果
4.2.3 实例图文分析:机场等级分数比较(见数据文件4-3.sav)
1. 实例内容
国际航空运输协会(The International Air Tran sport Association)对商务旅游人员进行了一项调查,以便确定多个国际机场的等级分数。最高可能分数是10分,分数越高说明其等级也越高。假设有一个由50名商务旅行人员组成的简单随机样本,要求这些人给迈阿密机场打分。另外有一个由50名商务旅行人员组成的样本,要求这些人给洛杉矶机场打分。这两个组人员打出的等级分数如表4-5所示。请你判断迈阿密机场和洛杉矶机场的等级评分是否相同?

4.3 SPSS在两配对样本t检验的应用
在现实中,总体或样本之间不仅仅表现为独立的关系,很多情况下,总体之间存在着一定的相关性。当分析这些相关总体之间的均值关系时,就涉及到两配对样本的t检验。配对样本主要包括下列一些情况:
(1)同一实验对象处理前后的数据。例如对患肝病的病人实施某种药物治疗后,检验病人在服药前后的差异性。
(2)同一实验对象两个部位的数据。例如研究汽车左右轮胎耐磨性有无显著差异。
(3)同一样品用两种方法检验的结果。例如对人造纤维在60度和80度的水中分别作实验,检验温度对这 种材料缩水率的影响性。
(4)配对的两个实验对象分别接受不同处理后的数据。例如对双胞胎兄弟实施不同的教育方案,检验他们在学习能力上的差异性。
进行配对样本检验时,通常要满足以下三个要求。
(1)两组样本的样本容量要相同;
(2)两组样本的观察值顺序不能随意调换,要保持一一对应关系;
(3)样本来自的总体要服从正态分布。
4.3.2 两配对样本t检验的SPSS操作详解
Step01:打开两配对样本t检验对话框
【Analyze(分析)】→【Compare Means(比较均值)】→【Paired-Samples T Test(配对样本T检验)】命令
Step02:选择配对变量
Step03:其他选项选择
Step04:单击图【OK】按钮,结束操作,SPSS软件自动输出结果
4.3.3 实例图文分析:看电视和读书的时间(见数据文件4-5.sav)
1. 实例内容
“每月读书俱乐部”的成员进行了一项调查,以确信其成员用于看电视的时间是否比读书的时间多。假定抽取15个人组成的样本,得到了下列有关他们每周观看电视的小时数和每周读书时间的小时数的数据,见表4-11所示。你能够得到结论:“每月读书俱乐部”的成员每周观看电视的时间比读书的时间更好吗?
表4-11 每天观看电视和读书时间(单位:小时)

5.SPSS 的方差分析
多个总体均值是否相等的假设检验问题了,所采用的方法是方差分析。
方差分析中有以下几个重要概念:因素、水平、单元、元素、交互作用
5.1.2 方差分析的基本思想
表5-1 某公司产品销售方式所对应的销售量
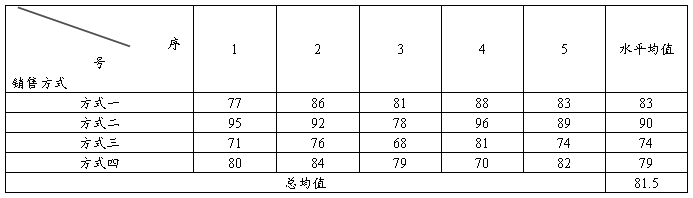
在表5-1中,要研究不同推销方式的效果,其实就归结为一个检验问题,设为第i(i=1,2,3,4)种推销方式的平均销售量,即检验原假设是否为真。从数值上观察,四个均值都不相等,方式二的销售量明显较大。
从表5-1可以看到,20个数据各不相同,这种差异可能是由以下两方面的原因引起的。
一是推销方式的影响,不同的方式会使人们产生不同消费冲动和购买欲望,从而产生不同的购买行动。 这种由不同水平造成的差异,称之为系统性差异。
二是随机因素的影响。同一种推销方式在不同的工作日销量也会不同,因为来商店的人群数量不一,经济收入不一,当班服务员态度不一,这种由随机因素造成的差异,我们称之为随机性差异。
两个方面产生的差异用两个方差来计量:
一是变量之间的总体差异,即水平之间的方差。
二是水平内部的方差。前者既包括系统性差异,也包括随机性差异;后者仅包括随机性差异。
5.1.3 方差分析的基本假设
(1)各样本的独立性。即各组观察数据,是从相互独立的总体中抽取的。
(2)要求所有观察值都是从正态总体中抽取,且方差相等。在实际应用中能够严格满足这些假定条件的客观现象是很少的,在社会经济现象中更是如此。但一般应近似地符合上述要求。
水平之间的方差(也称为组间方差)与水平内部的方差(也称组内方差)之间的比值是一个服从F分布的统计量
F = 水平间方差/ 水平内方差 = 组间方差 / 组内方差
5.2 SPSS在单因素方差分析中的应用
用来研究一个因素的不同水平是否对观测变量产生了显著影响
应用方差分析时,数据应当满足以下几个条件:在各个水平之下观察对象是独立随机抽样,即独立性;
各个水平的因变量服从正态分布,即正态性;各个水平下的总体具有相同的方差,即方差齐;
2.基本原理
方差分析认为:SST(总的离差平方和)=SSA(组间离差平方和)+SS E(组内离差平方和)
如果在总的离差平方和中,组间离差平方和所占比例较大,说明观测变量的变动主要是由因素的不同水平引起的,可以主要由因素的变动来解释,系统性差异给观测变量带来了显著影响;反之,如果组间离差平方和所占比例很小,说明观测变量的变动主要由随机变量因素引起的。
SPSS将自动计算检验统计量和相伴概率P值,若P值小于等于显著性水平α,则拒绝原假设,认为因素的不同水平对观测变量产生显著影响;反之,接受零假设,认为因素的不同水平没有对观测变量产生显著影响。
5.2.2 单因素方差分析的SPSS操作详解
Step01:打开主操作窗口
【Analyze(分析)】→【Compare Means(比较均值)】→【One-Way ANOVA(单因素ANOV A)】命令
Step02:选择因变量
Step03:选择因素变量
Step04:均值精细比较
Step05:均值多重比较
5.2.3 实例图文分析:信息来源与传播(见数据文件5-1.sav)
1. 实例内容
某机构的各个级别的管理人员需要足够的信息来完成各自的任务。最近,一项研究调查了信息来源对信息传播的影响。在这项特定的研究中,信息来源是上级、同级和下级。在每种情况下,对信息传播进行测度:数值越高,说明信息传播越广。检验信息来源是否对信息传播有显著影响?你的结论是什么?
2.实例操作
由于不同的信息来源可能导致信息传播测度不同。本案例中,信息来源是因素,“上级、同级和下级”是因素的三种不同水平,信息传播测度是因变量(观测变 量)。由于这里有三个水平,因此不能采用两样本的均值检验过程,故考虑采用单因素方差分析法。
进行如下假设检验:
H0:三种不同信息来源对信息传播测度平均值没有显著性影响;
H1:三种不同信息来源对信息传播测度平均值存在显著性影响。
5.3 SPSS在多因素方差分析中的应用
方法概述
多因素方差分析是对一个独立变量是否受一个或多个因素或变量影响而进行的方差分析。它不仅能够分析多个因素对观测变量的独立影响,更能够分析多个因素的交互作用能否对观测变量产生显著影响。
观测变量值的波动要受到多个控制变量独立作用、控制变量交互作用及随机因素等三方面的影响。
5.3.2 多因素方差分析的SPSS操作详解
Step01:打开主对话框
【Analyze(分析)】→【General Linear Model (一般线性模型)】→【Univariate(单变量)】命令
Step02:选择分析变量(因变量、因素变量、随机变量、协变量、权重变量)
Step03:模型选择
Step04:选择比较方法
Step05:选择轮廓图
Step06:选择多重比较
Step07:预测值保存
Step08:其他选项选择
5.3.3 实例图文分析:薪金的区别(见数据文件5-3.sav)
1 实例内容
假设某一杂志的记者要考察职业为财务管理、计算机程序员和药剂师的男女雇员其每周的薪金之间是否有显著性差异。从每种职业中分别选取了5名男性和5名女性组成样本,并且记录下来样本中每个人的周薪金(单位:美元)。所得数据见表5-11所示。请你分析职业和性别对薪金有无显著影响。
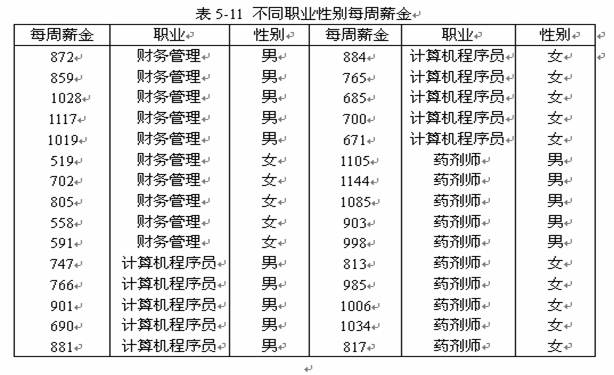
2 实例操作
由于薪金水平的高低和所从事的职业、性别等因素都有关系。因此这里要考虑两个因素水平下的薪金差异问题,即建立双因素的方差分析模型。本案例中,职业和性别是两个影响因素,而每周薪金是因变量。同时,我们也要考虑职业和性别这两个因素之间有无交互作用。
5.4 SPSS在协方差分析中的应用
协方差分析是将那些很难控制的因素作为协变量。在排除协变量影响的条件下,分析因素变量对观察变量的影响,从而更加准确地对因素变量进行评价。
在协方差分析中,将观察变量总的离差平方和分解为由因变量引起的、由因变量的交互作用引起的、由协变量引起的和由其他随机因 素引起的。
5.4.2 协方差分析的SPSS操作详解
1、确定是否存在协变量
2、“Univariate”过程中引入协变量
由于协方差分析也是采用【General Linear Model(一般线性模型)】中的【Univariate(单变量)】命令,因此它的基本操作和多因素方差分析的SPSS操作是相同的,这里就不再重复了
5.4.3 实例图文分析:人体的血清胆固醇(见数据文件5-4.sav)
1 实例内容
某医生欲了解成年人体重正常者与超重者的血清胆固醇是否不同。而胆固醇含量可能与年龄有关系,具体资料数据见表5-17所示。请建立模型分析体重对人体胆固醇含量的影响,同时也要兼顾年龄的因素。
表5-17 血清胆固醇含量

2 实例操作
案例中需要分析体重对人体的血清胆固醇有无直接影响,同时体重这个因素分为正常组和超重组两个水平,因此可以考虑单因素方差分析模型。但如果仅分析体重的影响作用,而不考虑实验对象 年龄的差异,那么得出的结论可能是不准确的。这是因为年龄的大小在一定程度上会影响人体的血清胆固醇含量的高低。因此,为了更准确描述体重对人体的血清胆固醇的影响,就应该尽量排除年龄因素对分析结果的影响。所以将年龄作为协变量引入模型,考虑建立协方差分析模型。在打开或建立数据文件5-4.sav后,具体操作步骤如下。
Step01:选择观测变量
选择菜单栏中的【Graphs(图形)】→【Legacy Dialogs(旧对话框)】→ 【Scatter/Dot(散点图/点图)】→【Simple/ Scatter(简单分布)】命令,弹出【Simple Scatter plot(简单分布图)】对话框
Step02:打开对话框
选择菜单栏中的【Analyze(分析)】→【General Linear Model (一般线性模型)】→【Univariate(单变量)】命令,弹出【Univariate(单变量)】对话框。
Step03:选择分析比较
在候选变量列表框中选择“chol”变量作为因变量,将其添加至【Dependent Variable(因变量)】列表框中。
选择“group”作为因素变量,将其添加至【Fixed Variable(s)(固定变量)】列表框中。
选择“age”作为协变量,将其添加至【Covariate(s)(对比)】列表框中。
Step05:其他选项选择
单击【Options】按钮,弹出【Options(选项)】对话框。勾选【Descriptive(描述性统计量)】复选框表示输出描述性统计量;勾选【Homogeneity-of-variance(方差同质性检验)】复选框表示输出方差齐性检验表。再单击【Continue按钮】,返回主对话框。
提示:根据数据特点及您的实验要求,选择不同的均值多重比较方法。
Step06:完成操作
最后,单击【OK(确定)】按钮,操作完成。
7.SPSS的相关分析
7.2 SPSS在简单相关分析中的应用
7.2.2 简单相关分析的SPSS操作详解
Step01:打开主菜单
【Analyze(分析)】→【Correlate(相关)】→【Bivariate(双变量)】命令
Step02:选择检验变量
Step03:选择相关系数类型
对于非等间距测度的连续变量,因为分布不明可以使用等级相关分析,也可以使用Pearson 相关分析;对于完全等级的离散变量必须使用等级相关分析相关性。当资料不服从双变量正态分布或总体分布型未知,或原始数据是用等级表示时,宜用Spearman 或Kendall相关。
Step04:假设检验类型选择
Step05:其他选项选择
Step06:单击【OK】按钮,结束操作,SPSS软件自动输出结果
7.2.3 实例分析:股票指数之间的联系(见数据文件7-1.sav)
1. 实例内容
道琼斯工业平均指数(DJIA)和标准普尔指数500(S&P 50 0)都被用做股市全面动态的测度。DJIA是基于30种股票的价格动态;S&P 500是由500种股票组成的指数。有人说S&P 500 是股票市场功能的一种更好的测度,因为它基于更多的股票。 表7-2显示了DJIA和S&P 500在1997年10周内的收盘价。请计算它们之间的样本相关系数。不仅如此,样本相关系数告诉我们 DJIA和S&P 500之间的关系是怎样的?
2. 实例操作
表给出了道琼斯工业平均指数和标准普尔指数在同一时间点的数值。由于这些数值都是连续型变量,同时根据两个股票指数的散点图,可见它们呈显著的线性相关,因此可以采用Pear son相关系数来测度它们之间的相关性。但为了比较,我们也计算了这两组变量的Kendall和Spearman相关系数。
7.3 SPSS在偏相关分析中的应用
偏相关分析就是在研究两个变量之间的线性相关关系时控制可能对其产生影响的变量。这种方法的目的就在于消除其他变量关联性的传递效应。
7.3.2 偏相关分析的SPSS操作详解
Step01:打开主菜单
【Analyze(分析)】→【Correlate(相关)】→ 【Partial(偏相关)】命令,弹出【Partial Correlations(偏相 关)】对话框
Step02:选择检验变量
Step03:选择控制变量
Step04:假设检验类型选择
Step05:其他选项选择
Step06:单击【OK】按钮,结束操作,SPSS软件自动输出结果
7.3.3 实例分析:股票市场和债券市场(见数据文件7-2.sav)
1. 实例内容
在我国的金融市场中,股票市场和债券市场都是其中的重要组成部分。研究它们之间的关系有利于我们弄清楚金融市场之间的关联特征。但是我国债券市场主要由银行间债券市场和证券交易所债券市场 组成,并且它们处于相对分割状态,在投资主体、交易方式等方面存在显著差异。数据文件列出了近几年我国股票市场、交易所 国债市场和银行间国债市场的综合指数,请利用相关分析研究这三个市场的关联特征。
8.SPSS的回归分析
8.1 SPSS 在一元线性回归分析中的应用
方法概述
线性回归模型侧重考察变量之间的数量变化规律,并通过线性表达式,即线性回归方程,来描述其关系,进而确定一个或几个变量的变化对另一个变量的影响程度,为预测提供科学依据。
一般线性回归的基本步骤如下。
① 确定回归方程中的自变量和因变量。
② 从收集到的样本数据出发确定自变量和因变量之间的数学关系式,即确定回归方程。
③ 建立回归方程,在一定统计拟合准则下估计出模型中的各个参数,得到一个确定的回归方程。
④ 对回归方程进行各种统计检验。
⑤ 利用回归方程进行预测。
一元线性回归模型是在不考虑其他影响因素的条件下,或是在认为其他影响因素确定的情况下,分析某一个因素(自变量)是如何影响因变量的。
通常要进行各种统计检验,例如拟合优度检验、回归方程和回归系数的显著性检验和残差分析等。
8.1.2 一元线性回归的SPSS操作详解
Step01:打开对话框
【Analyze(分析)】→【Regression(回归)】→ 【Linear(线性)】
Step02:选择因变量
Step03:选择自变量
Step04:选择回归模型中自变量的进入方式
Step05:样本的筛选
Step06:选择个案标签
Step07:选择加权二乘法变量
Step08:单击【OK】按钮,结束操作,SPSS软件自动输出结果
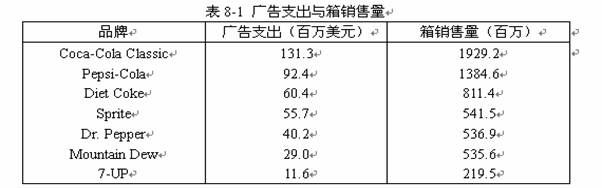
8.1.3 实例分析:广告支出与销售量(见数据文件8-1.sav)
1. 实例内容
表8-1中的数据是7大名牌饮料的广告支出(百万美元)与箱销售量(百万)的数据。请利用回归分析来分析广告支出与箱销售量的关系。
8.2 SPSS 在多元线性回归分析中的应用
8.2.2 多元线性回归的SPSS操作详解由于多元线性回归模型是一元回归模型的推广,因此两者在SPS S软件中的操作步骤是非常相似的。选择菜单栏中的【Analyze(分析)】→【Regression(回归)】→【Linear(线性)】命令,弹出 【Linear Regression(线性回归)】对话框。这既是一元线性回归 也是多元线性回归的主操作窗口。因此,读者可以参考8.1.2节的操作步骤。只不过由于多元回归模型涉及到多个自变量,因此在图8-1 中要在【Linear Regression(线性回归)】对话框左侧的候选变量列表框中选择多个变量,将其添加至【Independent(s)(自变量)】列表框中,即选择这些变量作为多元线性回归的自变量。
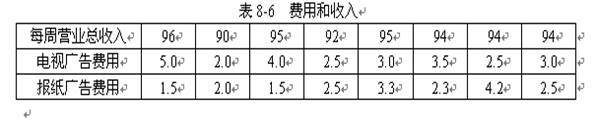
8.2.3 实例分析:电视广告和报纸广告(见数据文件8-2.sav)
1. 实例内容
娱乐时光影剧院公司的老板希望了解公司投放的电视广告费用和报纸广告费用对公司收入的影响。以往8周的样本数据如表8-6所示(单位:千美元)。请建立模型分析这两种广告形式对公司营业收入的影响。
8.3 SPSS在曲线拟合中的应用
为了决定选择的曲线类型,常用的方法是根据数据资 料绘制出散点图,通过图形的变化趋势特征并结合专业知识和经验分析来确定曲线的类型,即变量之间的函数关系。
可以采用变量变换的方法将曲线方程转化为线性方程来估计参数。
8.3.2 曲线拟合的SPSS操作详解
Step01:打开对话框
【Analyze(分析)】→【Regression(回归)】→【Curve Estimation(曲线估计)】命令,弹出【Curve Estimation(曲线估 计)】对话框
Step02:选择因变量
Step03:选择自变量
Step04:选择个案标签
Step05:选择曲线拟合模型
Step06:选择预测值和残差输出
单击【Save】按钮,弹出对话框
Step07:其他选项输出
8.3.3 实例分析:空置率和租金率(见数据文件8-3.sav)
1. 实例内容
某管理咨询公司采集了市场上办公用房的空置率和租金率的数据。对于13个选取的销售地区,表8-13是这些地区的中心商业区的综合空置率(%)和平均租金率(元/平方米)的统计数据。请尝试分析空置率对平均租金率的影响。
8.4 SPSS 在非线性回归分析中的应用
非线性回归可以估计因变量和自变量之间具有任意关系的模型,用户根据自身需要可随意设定估计方程的具体形式。因此,本方法在实际应用中有很大的实用价值。
8.4.2 非线性回归分析的SPSS操作详解
Step01:打开对话框
【Analyze(分析)】→【Regression(回归)】→ 【Nonlinear(非线性)】命令
Step02:选择因变量
Step03:设置参数变量和初始值
Step04:输入回归方程
Step05:迭代条件选择
Step06:参数取值范围选择
Step07:选择预测值和残差等输出
Step08:迭代方法选择
8.4.3 实例分析:股票价格的预测(见数据文件8-4.sav)
1. 实例内容
假定数据文件8-4中是三个公司股票在15个月期间的股市收盘价。一家投资公司希望建立一个回归模型用股票B和股票C的价格来预测股票A的价格。请建立回归模型分析。