1.普通最小二乘法(Ordinary Least Squares,OLS):已知一组样本观测值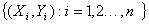 ,普通最小二乘法要求样本回归函数尽可以好地拟合这组值,即样本回归线上的点
,普通最小二乘法要求样本回归函数尽可以好地拟合这组值,即样本回归线上的点 与真实观测点Yt的“总体误差”尽可能地小。普通最小二乘法给出的判断标准是:被解释变量的估计值与实际观测值之差的平方和最小。
与真实观测点Yt的“总体误差”尽可能地小。普通最小二乘法给出的判断标准是:被解释变量的估计值与实际观测值之差的平方和最小。
2.广义最小二乘法GLS:加权最小二乘法具有比普通最小二乘法更普遍的意义,或者说普通最小二乘法只是加权最小二乘法中权恒取1时的一种特殊情况。从此意义看,加权最小二乘法也称为广义最小二乘法。
3.加权最小二乘法WLS:加权最小二乘法是对原模型加权,使之变成一个新的不存在异方差性的模型,然后采用普通最小二乘法估计其参数。
4.工具变量法IV:工具变量法是克服解释变量与随机干扰项相关影响的一种参数估计方法。
5.两阶段最小二乘法2SLS, Two Stage Least Squares:两阶段最小二乘法是一种既适用于恰好识别的结构方程,以适用于过度识别的结构方程的单方程估计方法。
6.间接最小二乘法ILS:间接最小二乘法是先对关于内生解释变量的简化式方程采用普通小最二乘法估计简化式参数,得到简化式参数估计量,然后过通参数关系体系,计算得到结构式参数的估计量的一种方法。
7.异方差性Heteroskedasticity:对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,则认为出现了异方差性。
8.序列相关性Serial Correlation:多元线性回归模型的基本假设之一是模型的随机干扰项相互独立或不相关。如果模型的随机干扰项违背了相互独立的基本假设,称为存在序列相关性。
9.多重共线性Multicollinearity:对于模型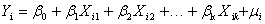 ,其基本假设之一是解释变量X1,X2,…,Xk是相互独立的。如果某两个或多个解释变量之间出现了相关性,则称为存在多重共线性。
,其基本假设之一是解释变量X1,X2,…,Xk是相互独立的。如果某两个或多个解释变量之间出现了相关性,则称为存在多重共线性。
10.时间序列数据:时间序列数据是一批按照时间先后排列的统计数据。
11.截面数据:截面数所是一批发生在同一时间截面上调查数据。
12.虚拟数据:也称为二进制数据,一般取0或1.
13.内生变量Endogenous Variables:内生变量是具有某种概率分布的随机变量,它的参数是联立方程系统估计的元素。内生变量是由模型系统决定的,同时也对模型系统产生影响。内生变量一般都是经济变量。
14.外生变量Exogenous Variables:外生变量一般是确定性变量,或者是具有临界概率分布的随机变量,其参数不是模型系统研究的元素。外生变量影响系统,但本身不受系统的影响。外生变量一般是经济变量、条件变量、政策变量、虚变量。
15.先决变量Predetermined Variables:外生变量与滞后内生变量(Lagged Endogenous Variables)统称为先决变量。
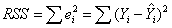
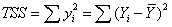 16.总离差平方和: 称为总离差平方和,反映样本观测值总体离差的大小。
16.总离差平方和: 称为总离差平方和,反映样本观测值总体离差的大小。
17.残差平方和: 称为残差平方和,反映样本观测值与估计值偏离的大小,也是模型中解释变量未解释的那部分离差的大小。
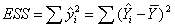 18.回归平方和: 反映由模型中解释变量所解释的那部分离差的大小。
18.回归平方和: 反映由模型中解释变量所解释的那部分离差的大小。
19.可决系数coefficient of determination :可决系数R2是检验模型拟合优度的指标,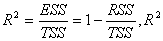 越接近于1,模型的拟合优度越高。
越接近于1,模型的拟合优度越高。
 20.随机干扰项stochastic disturbance:
20.随机干扰项stochastic disturbance: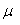 称为观察值Y围绕它的期望值E(Y X)的离差(deviation),记
称为观察值Y围绕它的期望值E(Y X)的离差(deviation),记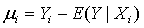 ,它是一个不可观测的随机变量,称为随机误差项(stochastic error),通常又不加区别地称为随机干扰项()。
,它是一个不可观测的随机变量,称为随机误差项(stochastic error),通常又不加区别地称为随机干扰项()。
21.结构式模型Structural Model:根据经济理论和行为规律建立的描述经济变量之间直接结构关系的计量经济学方程系统称为结构式模型。
22.简化式模型Reduced-Form Model:将联立方程计量经济学模型的每个内生变量表示成所有先决变量和随机干扰项的函数,即用所有先决变量作为每个内生变量的解释变量,所形成的模型称为简化式模型。
23.恰好识别Just Identification:如果某一个随机方程具有一组参数估计量,称其为恰好识别。
24.过度识别Over identification:如果某一个随机方程具有多组参数估计量,称其为过度识别。
15.格兰杰因果检验
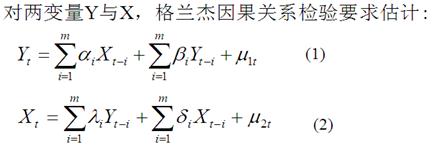
可能存在有四种检验结果:
(1)X对Y有单向影响,表现为(1)式X各滞后项前的参数整体不为零,而(2)式Y各滞后项前的参数整体为零;
(2)Y对X有单向影响,表现为(2)式Y各滞后项前的参数整体不为零,而(1)式X各滞后项前的参数整体为零;
(3)Y与X间存在双向影响,表现为Y与X各滞后项前的参数整体不为零;
(4)Y与X间不存在影响,表现为Y与X各滞后项前的参数整体为零。
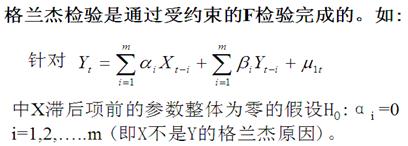
分别做包含与不包含X滞后项的回归,记前者与后者的残差平方和分别为RSSU、RSSR;再计算F统计量:
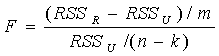
k为无约束回归模型的待估参数的个数。
如果: F>Fa (m, n-k) ,则拒绝原假设,认为X是Y的格兰杰原因。
21、DW检验
假设条件:(1)解释变量X非随机;
(2)随机误差项mi为一阶自回归形式:mi=mri-1+ei
(3)回归模型中不应含有滞后应变量作为解释变量,即不应出现下列形式:
Yi=b0+b1X1i+……bkXki+gYi-1+mi
(4)回归含有截距项
针对原假设:H0: r=0, 构如下造统计量:
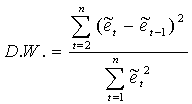
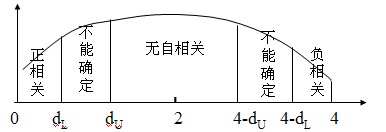
计算DW值,给定a,由样本容量n和解释变量个数k的大小查DW分布表,得临界值dL和dU
比较、判断,若 0<D.W.<dL 存在正自相关
dL<D.W.<dU 不能确定
dU <D.W.<4-dU 无自相关
4-dU <D.W.<4- dL 不能确定
4-dL <D.W.<4 存在负自相关
当D.W.值在2左右时,模型不存在一阶自相关。
22、White检验 见11题
怀特检验不需要排序,且适合任何形式的异方差。其基本思想与步骤:
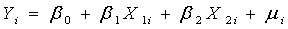
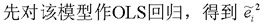 然后做辅助回归:
然后做辅助回归: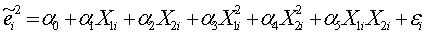
可以证明,在同方差性假设下,从该辅助回归得到的可决系数R2与样本容量n的乘积,渐近地服从自由度为辅助回归方程中解释变量个数的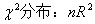 ~
~ ,则可在大样本下,对统计量
,则可在大样本下,对统计量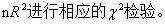
23、F检验
即检验模型 Yi=b0+b1X1i+b2X2i+ ¼ +bkXki+mi i=1,2, ¼,n中的参数bj是否显著不为0。
H0: b0=b1=b2= ¼ =bk=0
H1: bj不全为0
在原假设H0成立的条件下,统计量
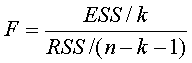 服从自由度为(k , n-k-1)的F分布。
服从自由度为(k , n-k-1)的F分布。
给定显著性水平a,可得到临界值Fa(k,n-k-1),由样本求出统计量F的数值,通过
F> Fa(k,n-k-1) 或 F≤Fa(k,n-k-1)
来拒绝或接受原假设H0,以判定原方程总体上的线性关系是否显著成立。
24、t检验

25、估计联立方程的参数常用哪几种方法?特点?
联立方程计量经济学模型的估计方法分为两大类:单方程估计方法与系统估计方法。
单方程估计方法按其方法原理又分为两类。
一类以最小二乘为原理,例如间接最小二乘法(ILS, Indirect Least Square)、两阶段最小二乘法(2SLS, Two Stage Least Squares)、工具变量法(IV, Instrumental Variables)等,称其为经典方法;
一类不以最小二乘为原理,或者不直接从最小二乘原理出发,例如以最大或然为原理的有限信息最大或然法(LIML, Limited Information Maximum Likelihood),以及仍然应用最小二乘原理、但并不以残差平方和最小为判断标准的最小方差比方法(LVR, Least Variable Ration)等。
工具变量法(IV,Instrumental Variables)
工具变量法只适用于恰好识别的结构方程的估计
间接最小二乘法只适用于恰好识别的结构方程的参数估计,因为只有恰好识别的结构方程,才能从参数关系体系中得到唯一一组结构参数的估计量。
间接最小二乘法也是一种工具变量方法
2SLS是一种既适用于恰好识别的结构方程,又适用于过度识别的结构方程的单方程估计方法。二阶段最小二乘法也是一种工具变量方法
26、联立方程计量经济学(结构式、简化式、参数关系体系、结构识别)
结构式模型:根据经济理论和行为规律建立的描述经济变量之间直接结构关系的计量经济学方程系统称为结构式模型。具有g个内生变量、k个先决变量、g个结构方程的模型被称为完备的结构式模型。在完备的结构式模型中,独立的结构方程的数目等于内生变量的数目,每个内生变量都分别由一个方程来描述。
完备的结构式模型的矩阵表示
习惯上用Y表示内生变量,X表示先决变量,μ表示随机项,β表示内生变量的结构参数,γ表示先决变量的结构参数,如果模型中有常数项,可以看成为一个外生的虚变量,它的观测值始终取1。

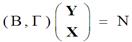
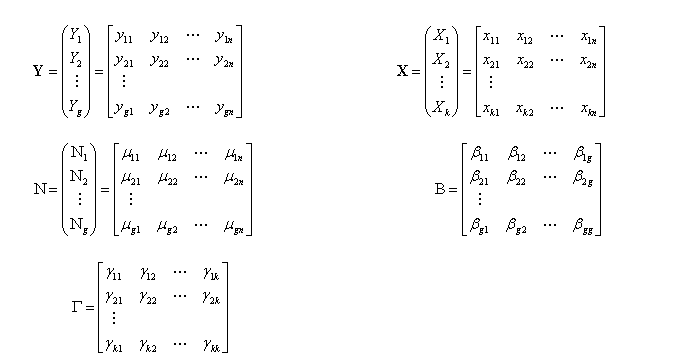
简化式模型:用所有先决变量作为每个内生变量的解释变量,所形成的模型称为简化式模型。
如P195式(6.2.8)

参数关系体系:P195式(6.2.9)
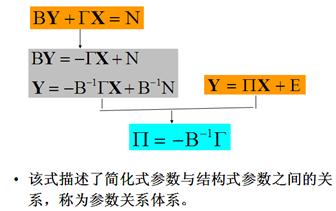
结构式识别条件P201


27、计量经济学常用的数据有哪几类?
时间序列数据:时间序列数据是一批按照时间先后排列的统计数据。
截面数据:截面数所是一批发生在同一时间截面上调查数据。
虚拟数据:也称为二进制数据,一般取0或1.
28、多远线性回归OLS,WLS,GLS,IV这几种方法的参数估计矩阵表达式
普通最小二乘估计量OLS P65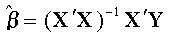
加权最小二乘估计量WLS

广义最小二乘估计量 GLS P127
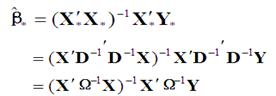
IV 工具变量法 P148
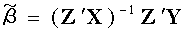
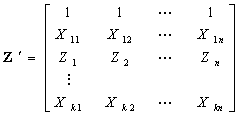 称为工具变量矩阵
称为工具变量矩阵
29、联立方程IV,ILS,2SLS这几种方法的参数估计矩阵表达式 及适用
IV 狭义的工具变量法(IV,Instrumental Variables)
工具变量法只适用于恰好识别的结构方程的估计

ILS 间接最小二乘法(ILS, Indirect Least Squares)
间接最小二乘法只适用于恰好识别的结构方程的参数估计,因为只有恰好识别的结构方程,才能从参数关系体系中得到唯一一组结构参数的估计量。
参数估计矩阵表达式:P210

2SLS 二阶段最小二乘法(2SLS, Two Stage Least Squares)
2SLS是一种既适用于恰好识别的结构方程,又适用于过度识别的结构方程的单方程估计方法
步骤及表达式:P211-P212
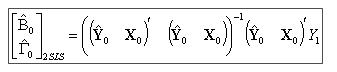
30、回归模型中引入虚变量的作用?有两个转折点的虚变量回归模型
作用:许多经济变量是可以定量度量的,但也有一些影响经济变量的因素无法定量度量,引入“虚拟变量” 将它们“量化”, 从而反映这些因素的影响,并提高模型的精度。
第二篇:计量经济学知识
建模是计量的灵魂,所以就从建模开始。
一、
建模步骤:A,理论模型的设计: a,选择变量b,确定变量关系c,拟定参数范围
B,样本数据的收集: a,数据的类型b,数据的质量
C,样本参数的估计: a,模型的识别b,估价方法选择
D,模型的检验
a,经济意义的检验1正相关
2反相关等等
b,统计检验:1检验样本回归函数和样本的拟合优度,R的平方即其修正检验
2样本回归函数和总体回归函数的接近程度:单个解释变量显著性即t检验,函数显著性即F检验,接近程度的区间检验
c,模型预测检验1解释变量条件条件均值与个值的预测
2预测置信空间变化
d,参数的线性约束检验:1参数线性约束的检验
2模型增加或减少变量的检验
3参数的稳定性检验:邹氏参数稳定性检验,邹氏预测检验----------主要方法是以F检验受约束前后模型的差异
e,参数的非线性约束检验:1最大似然比检验
2沃尔德检验
3拉格朗日乘数检验---------主要方法使用 X平方分布检验统计量分布特征
f,计量经济学检验
1,异方差性问题:特征:无偏,一致但标准差偏误。检测方法:图示法,Park与Gleiser检验法,Goldfeld-Quandt检验法,White检验法-------用WLS修正异方差
2,序列相关性问题:特征:无偏,一致,但检验不可靠,预测无效。检测方法:图示法,回归检验法,Durbin-Waston检验法,Lagrange乘子检验法-------用GLS或广义差分法修正序列相关性
3,多重共线性问题:特征:无偏,一致但标准差过大,t减小,正负号混乱。检测方法:先检验多重共线性是否存在,再检验多重共线性的范围-------------用逐步回归法,差分法或使用额外信息,增大样本容量可以修正。
4,随机解释变量问题:随机解释变量与随机干扰项独立----------对OLS没有坏影响。随机变量与随机干扰项同期相关:有偏但一致-----扩大样本容量可以克服。随机变量与随机干扰项同期相关:有偏且非一致--------工具变量法可以克服
二、
参数估计量性质的分析:a小样本和大样本性质
b无偏性
c有效性
d一致性
e Gauss-Markov定理
三、
A虚拟解释变量问题
a,加法方式:定性因素对截距的影响
b,乘法方式:定性因素对斜率项产生的影响
c,加法与乘法结合方式:定性应诉对截距和斜率项同时产生影响
B滞后变量问题
a,分布滞后模型:经验加权法,Almon多项式法,Koyck方法---来减少滞后项的数目
b,自回归模型:工具变量法,OLS法
C模型设定偏误问题
a,解释变量选取偏误1漏选相关变量:OLS在小样本下有偏,大样本下不一致
2多选无关变量:OLS估计量无偏且一致,但无效
b,模型函数形式选取偏误:OLS有偏非一致且无效
c,1用t检验和f检验检验无关变量
2用RESET检验是否遗漏相关变量或模型函数选取错误
四、
联立方程计量经济学模型的单方程估计
a,工具变量法IV
b,ILS-----ab适用于恰好识别
c,2SLS---适用于恰好识别和过度识别
五、
二元离散选择模型
a,Probit离散选择模型:将随机干扰项的概率分布设定为标准正态分布----用最大似然估计法或GLS
b,Logit离散选择模型:将随机干扰项的概率分布设定为logistic分布得到---用最大似然估计法或GLS
六、
随机时间序列模型:
a,纯自回归AR模型----用Yule-Walker方程或OLS估计
b,纯移动平均MA模型
c,自回归移动平均ARMA模型----bc可以用矩估计法,对非平稳的时间序列检验协整性可用Engle-Granger两步法或直接估计法。
注:此文只是小弟开学读书笔记的总结 只能当个工程表,让大家知道所学阶段和所用罢了
另:据小弟开学后了解的教材方面
最初入门书首推古扎拉蒂的《计量经济学基础》,上下两本,想很快对计量经济学有全方位认识的弟兄可以看这本书的精写版《经济计量学精要》,机械工业出版社,世纪馆书店就有第二版卖,好几十块---想要免费电子版的姐妹们可以联系我==。
伍德里奇的《计量经济学导论》真是讨论风格的啊,适合于中级使用,高级的书最经典的莫过于格林的《计量经济学分析》 ,还有《Econometrics Introduction》,中国人写的书还是李子奈的《计量经济学》比较清楚,难度中级偏高级。
研究的方面,微观注意面板数据,宏观注意时间序列,面板数据推荐伍德里奇的《横截面与面板数据的经济计量分析》,68元,人大出版社,时间序列推荐汉米尔顿的《时间序列分析》,传说中的经典教材。在此小弟加一句,尽量对照着英文看中文,因为翻译的很难==。
Stata方面,咱们人大图书馆三层英文借阅室有本《Using Stata》开头的书,据说,所有的stata的书都是以它为模本,在以F222开头的书架好像。